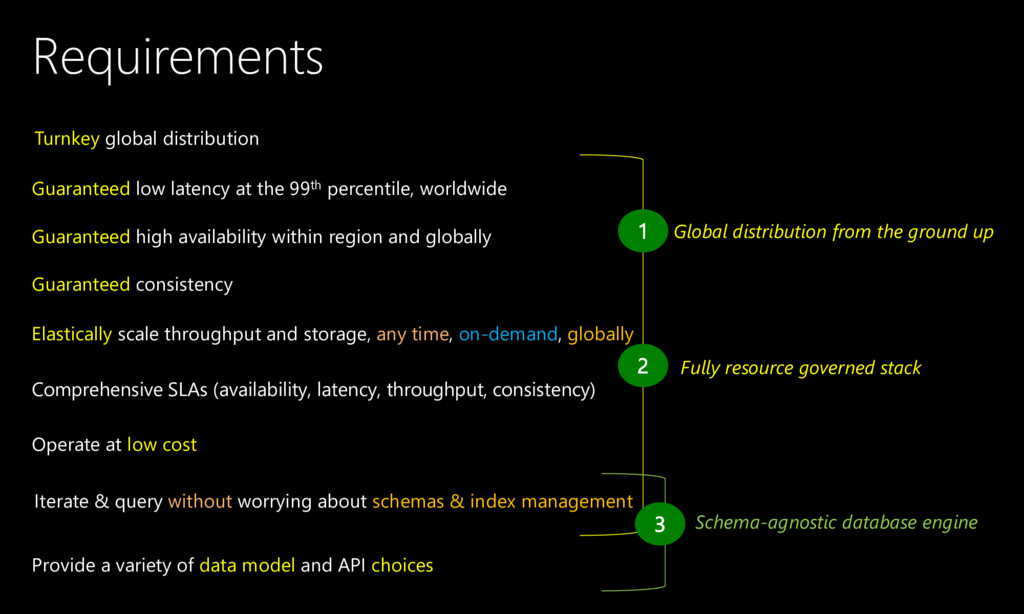
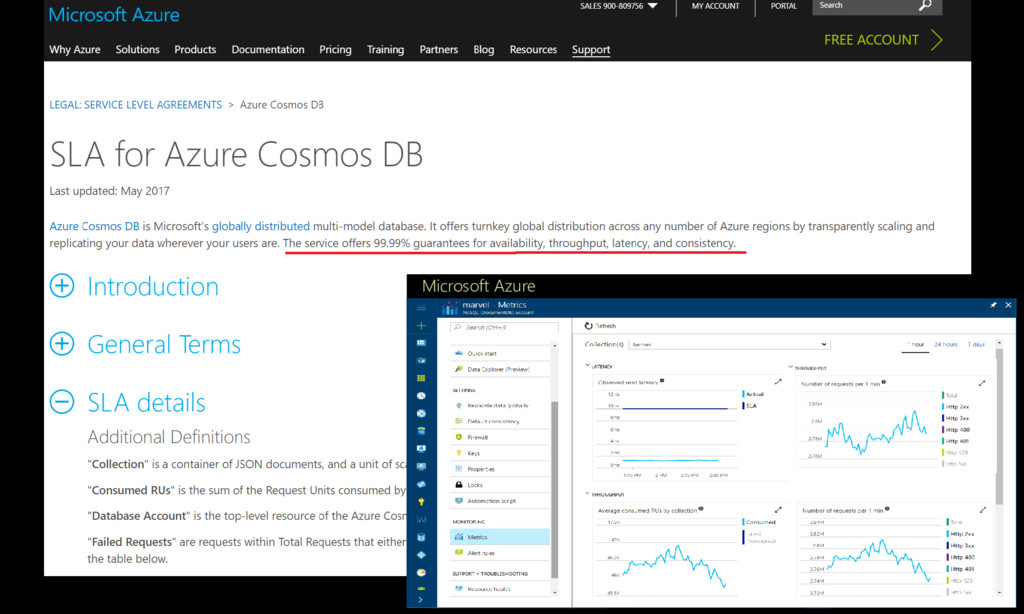
In this talk, I describe the key capabilities, system design and various design trade-offs we had to make in the process of building Cosmos DB (http://cosmosdb.com) service. I also share our experience from operating a globally distributed database service worldwide and maintaining comprehensive Service Level Agreements (SLAs).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}