The Devops philosophy has revolutionised software engineering. What inspires me most is the SRE paradigm in Devops. What was popularised by Google in their SRE handbook has gone on to inspire several devops teams to follow patterns like Observability which is built in the public cloud revolution of the last 5 years. Multiple inspirations drawn from the SRE workbook written by Google and AWS whitepapers on operational excellence.
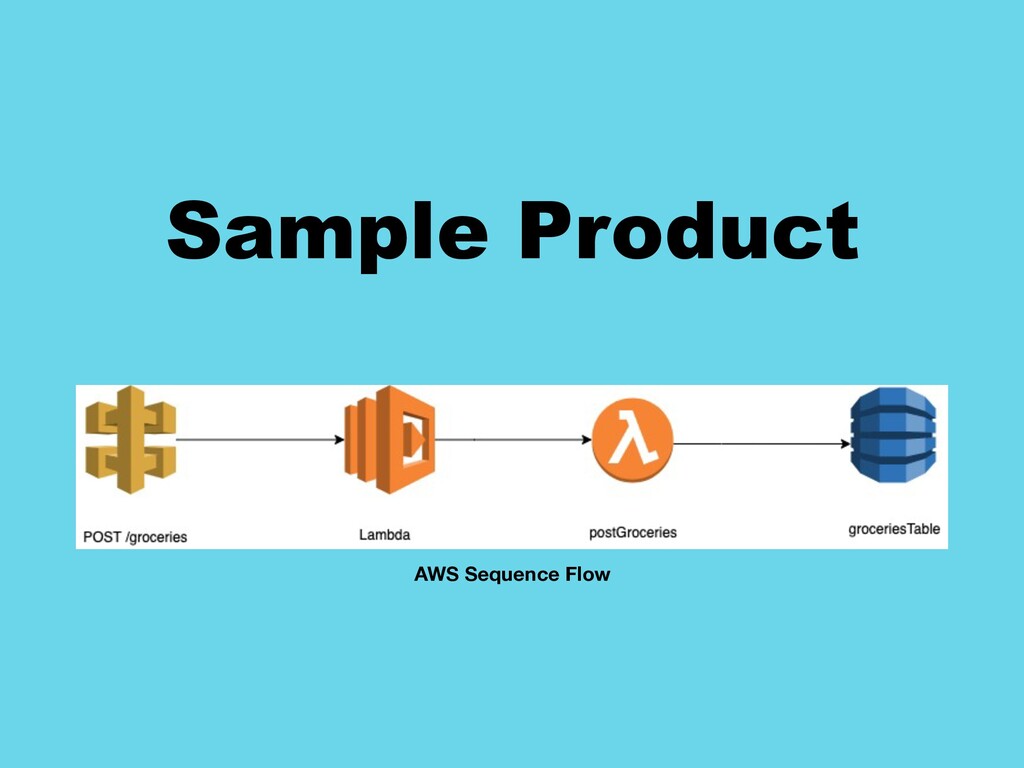
This talk introduces the audience to the role of Observability in Devops and SRE teams. It focuses most on metrics reporting. With the help of a sample serverless project hosted on AWS and examples of AWS Cloudwatch and AWS X-Ray, this talk will present both black box and white box monitoring and tracing. The demo will highlight the role of metrics and logs in the later phases of Observability - tracing, alerting and incident management.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}