Lustre – RAID over storage boxes v Recovery time after a node failure was MASSIVE! (Entire server’s contents had to be copied, one to one) v When functional, reading/writing EXTREMELY fast v Used in heavily in HPC
NFS – Network File System v Does this really count as distributed? v Single large server v Full POSIX support, in kernel since…forever v Slow with even a moderate number of clients v Dead simple
Hadoop – Apache Project inspired by Google v Massive throughput v Throughput scales with attached HDs v Have seen VERY LARGE production clusters v Facebook, Yahoo… Nebraska v Doesn’t even pretend to be POSIX
GPFS(IBM) / Panasas – Propriety file systems v Requires closed source kernel driver v Not flexible with newest kernels / OS’s v Good: Good support and large communities v Can be treated as black box for administrators v HUGE Installments (Panasas at LANL is HUGE!!!!)
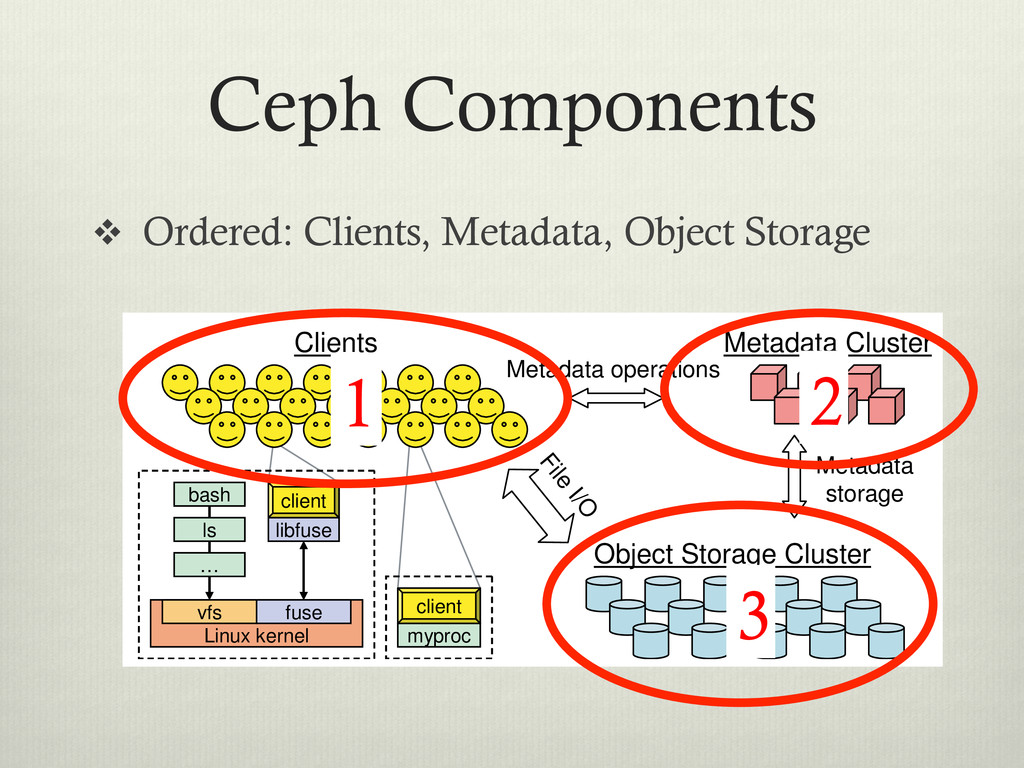
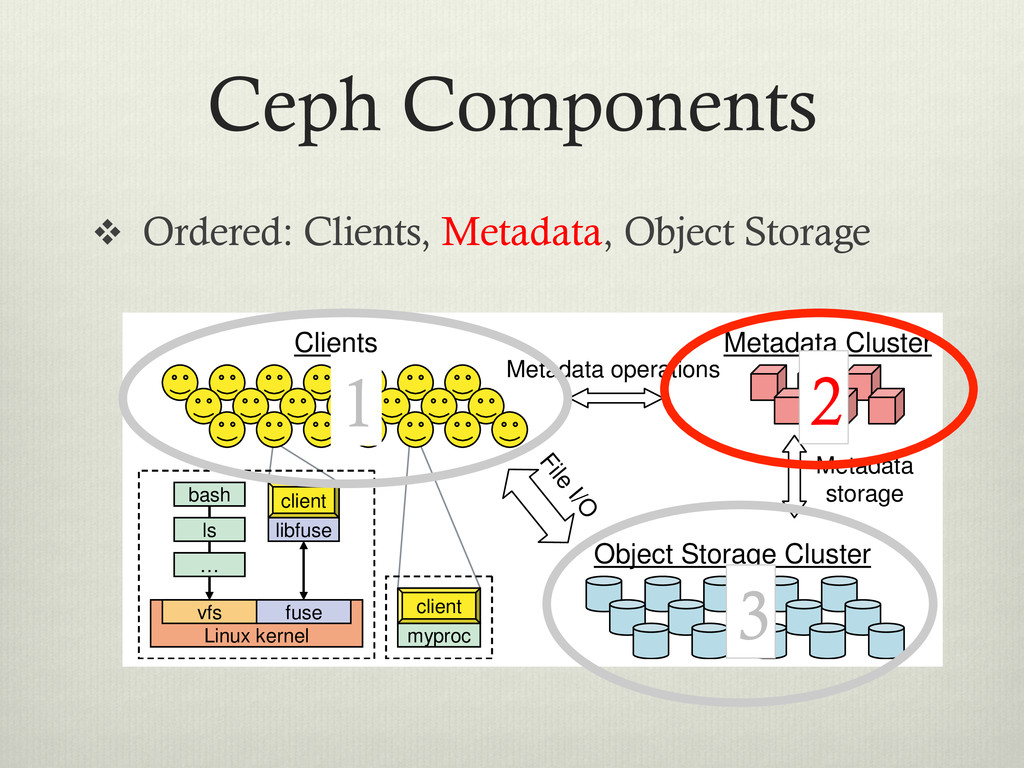
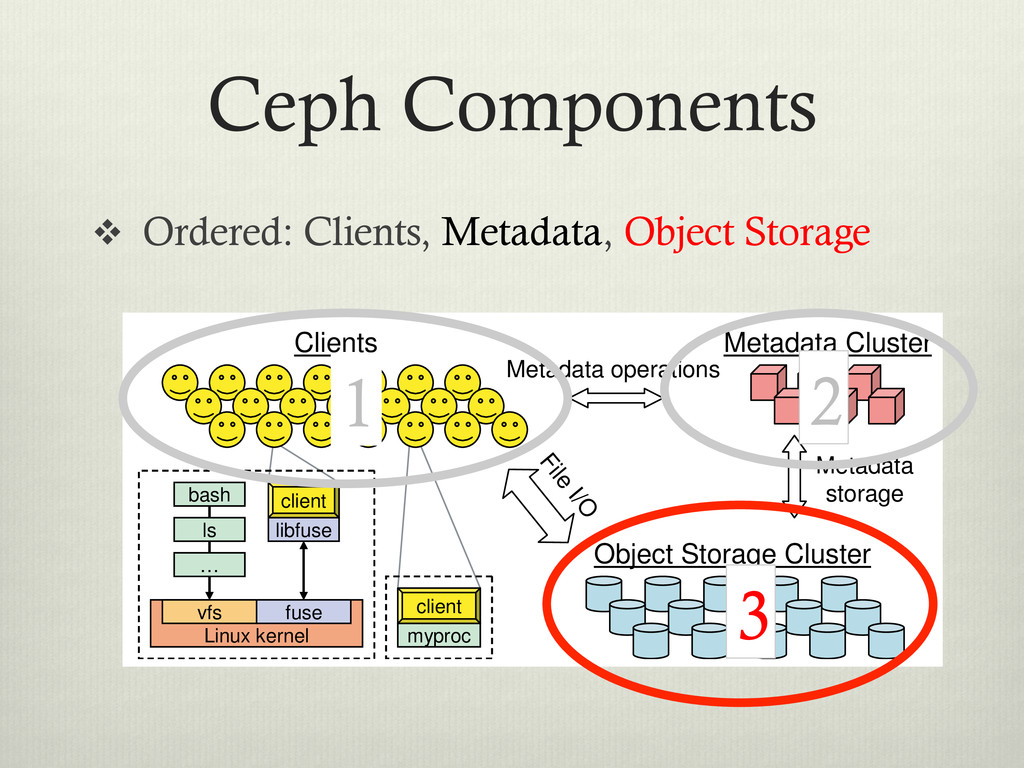
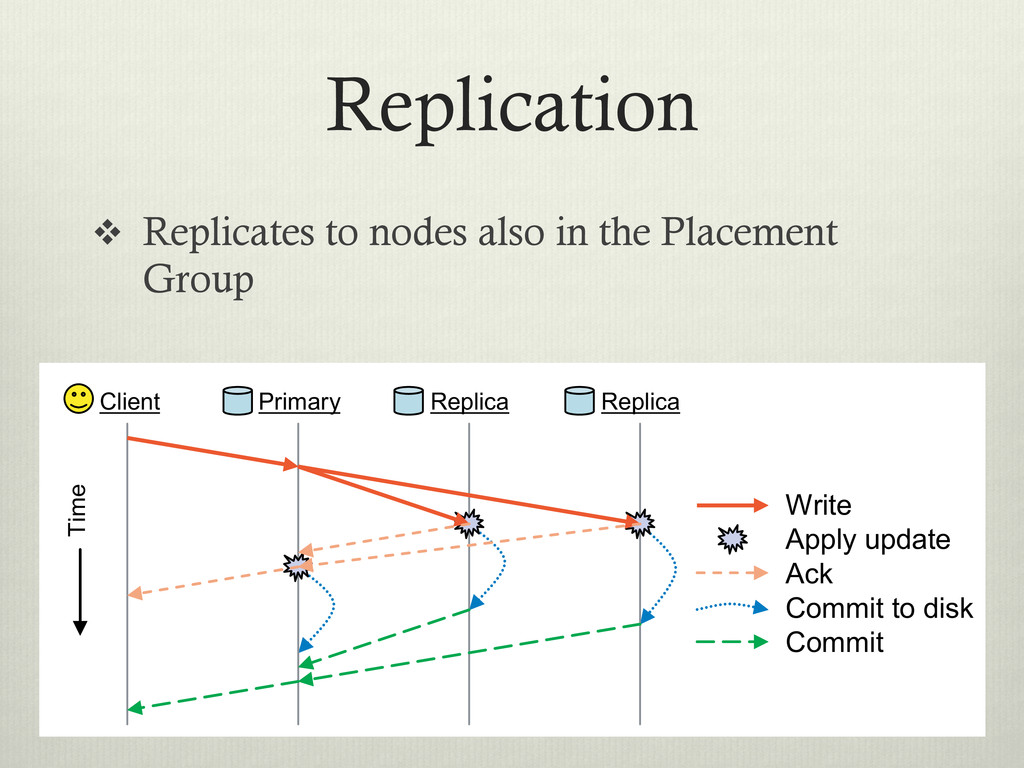
clustered environment v Designed for: v Performance – Striped data over data servers. v Reliability – No single point of failure v Scalability – Adaptable metadata cluster
Sage Weil earned PhD from Ceph (largely) v 2007 – 2010 Development continued, primarily for DreamHost v March 2010 – Linus merged Ceph client into mainline 2.6.34 kernel v No more patches needed for clients
lowered cost to deploy Ceph v For production environments, it was a little too late – 2.6.32 was the stable kernel used in RHEL 6 (CentOS 6, SL 6, Oracle 6).
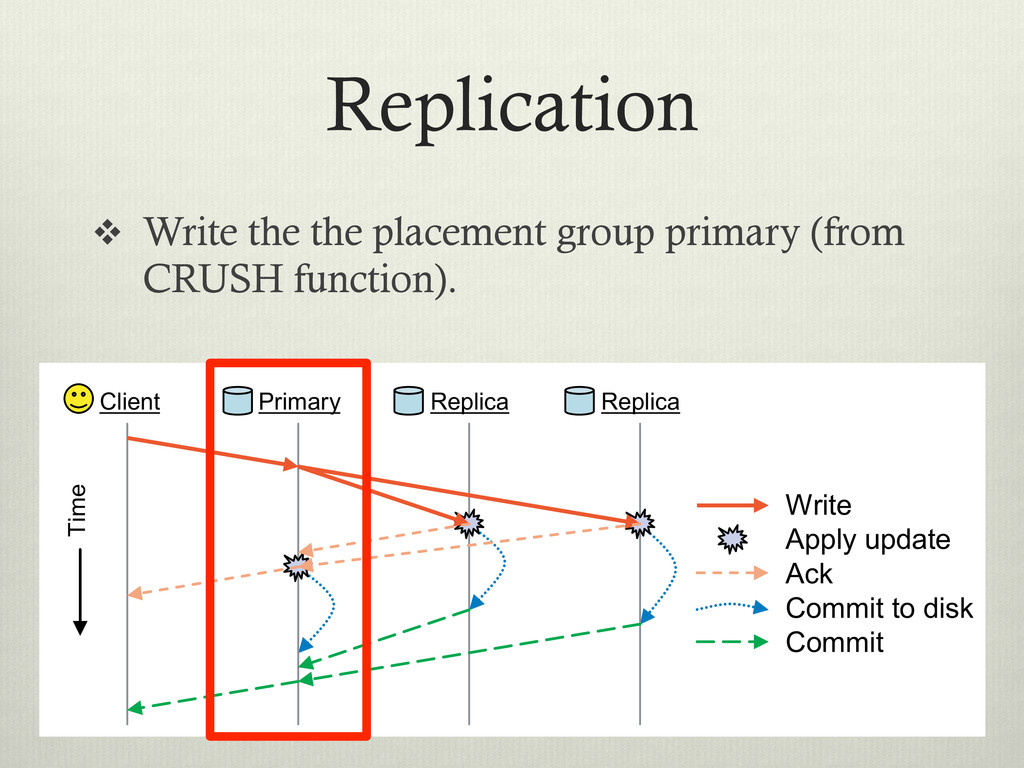
between clients and servers v Decoupling is common in distributed filesystems: Hadoop, Lustre, Panasas… v In contrast to other filesystems, CEPH uses a function to calculate the block locations
of servers v Distribution of metadata changes with the number of requests to even load among metadata servers v Metadata servers also can quickly recover from failures by taking over neighbors data v Improves performance by leveling metadata load
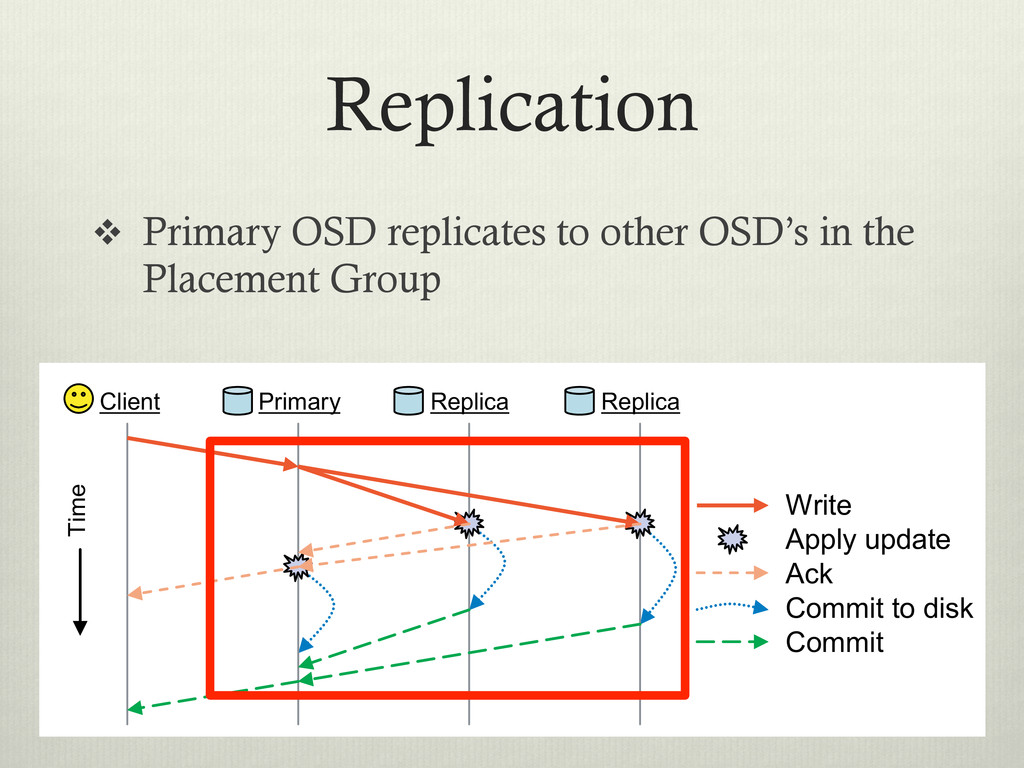
events by themselves v Initiates replication and v Improves performance by offloading decision making to the many data servers v Improves reliability by removing central control of the cluster (single point of failure)
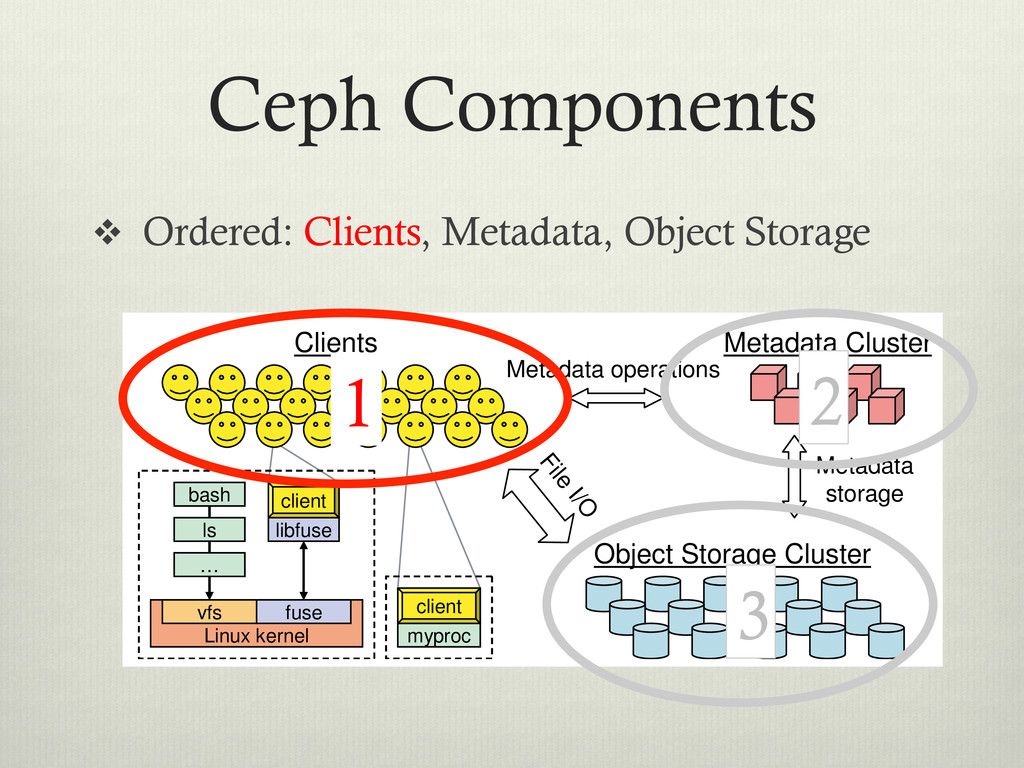
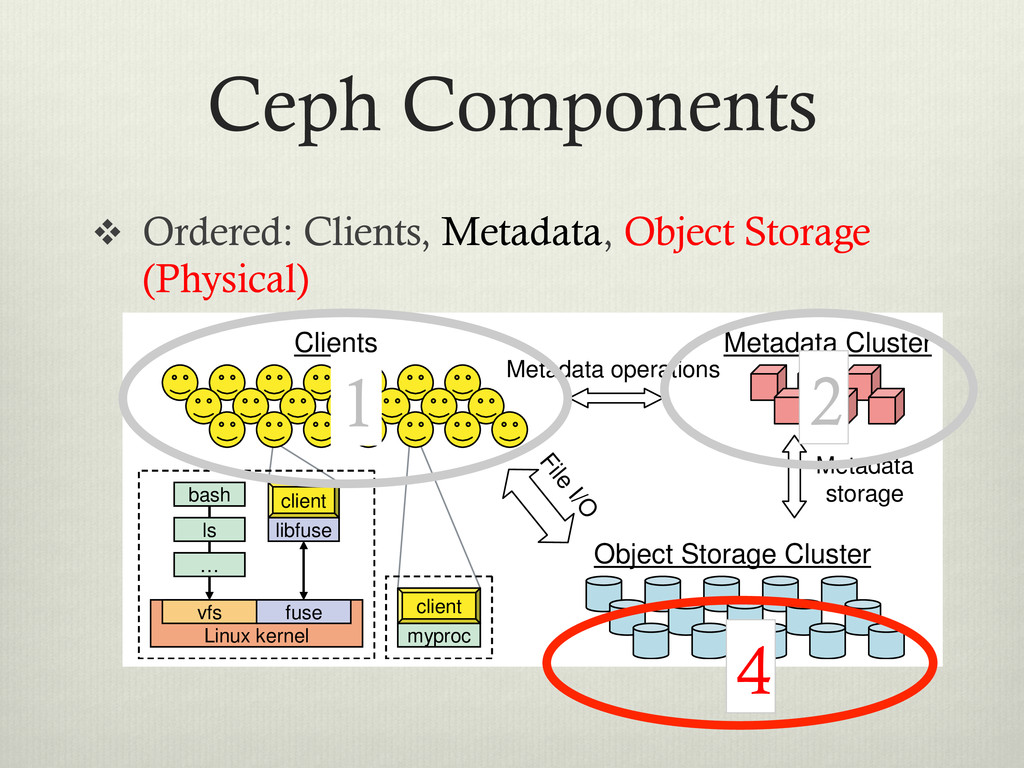
File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in 1 2 3
File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in 1 2 3
system in user space v Introduced so file systems can use a better interface than the Linux Kernel VFS (Virtual file system) v Can link directly to the Ceph Library v Built into newest OS’s.
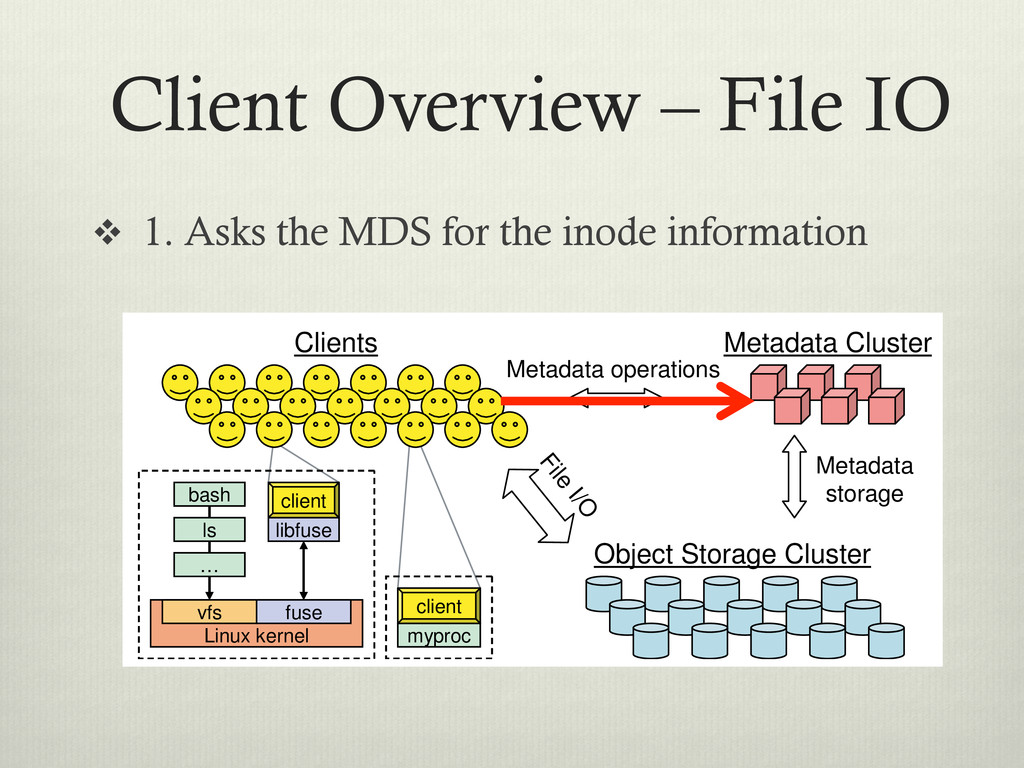
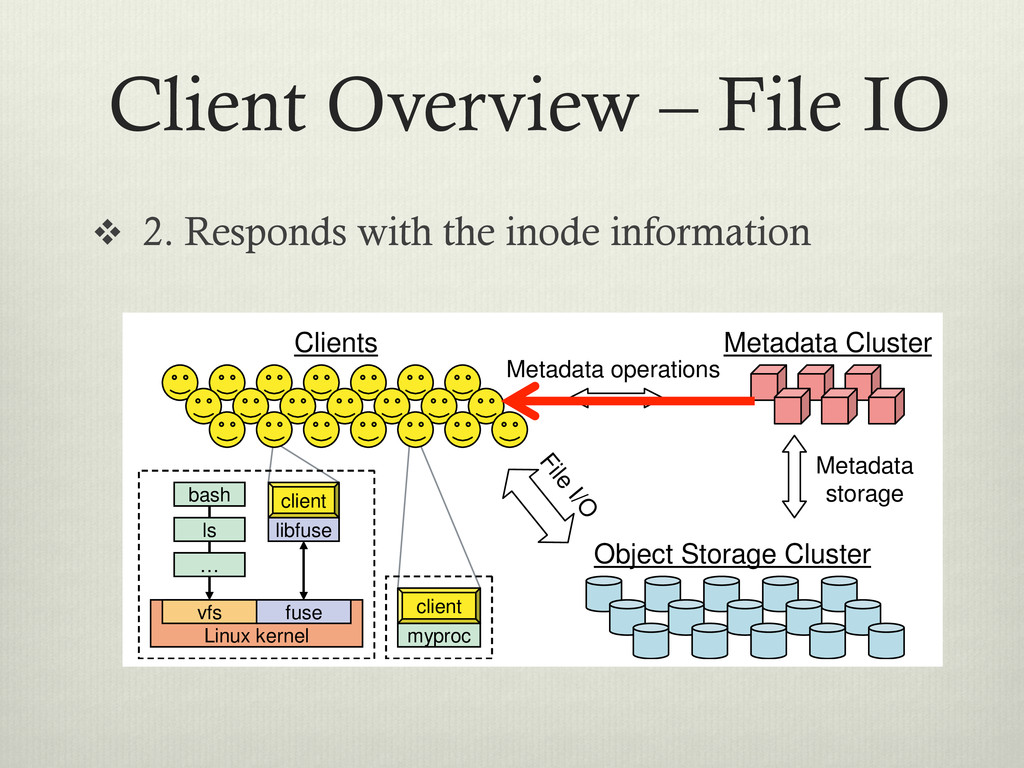
for the inode information Metadata storage File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in
inode information Metadata storage File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in
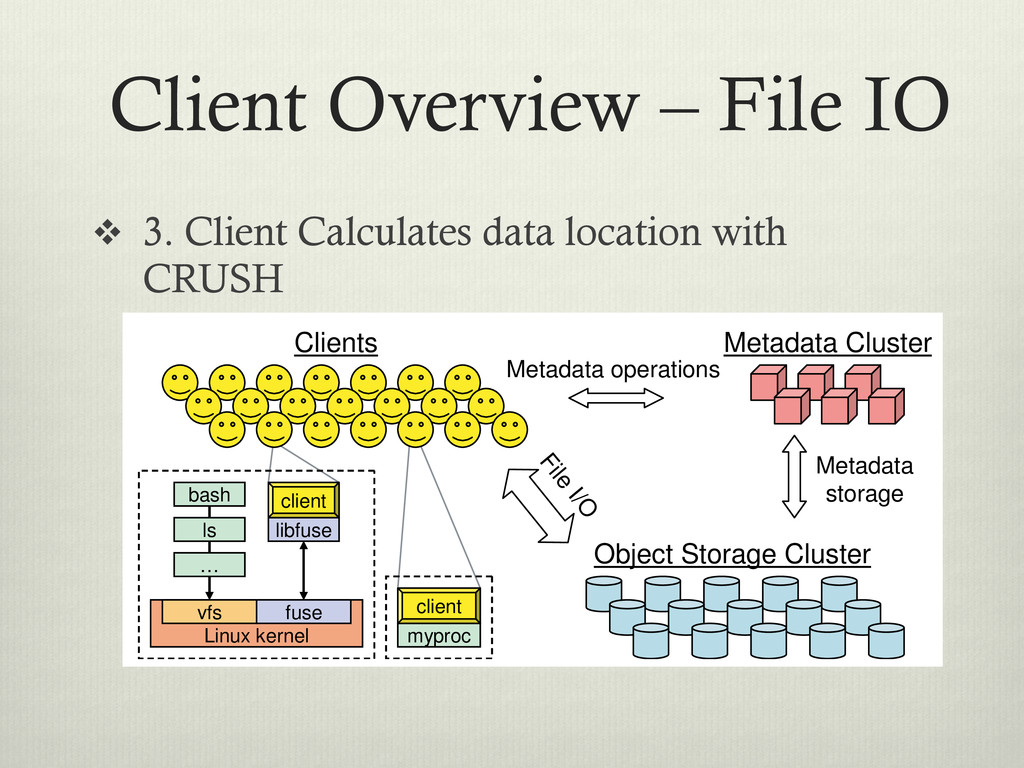
location with CRUSH Metadata storage File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in
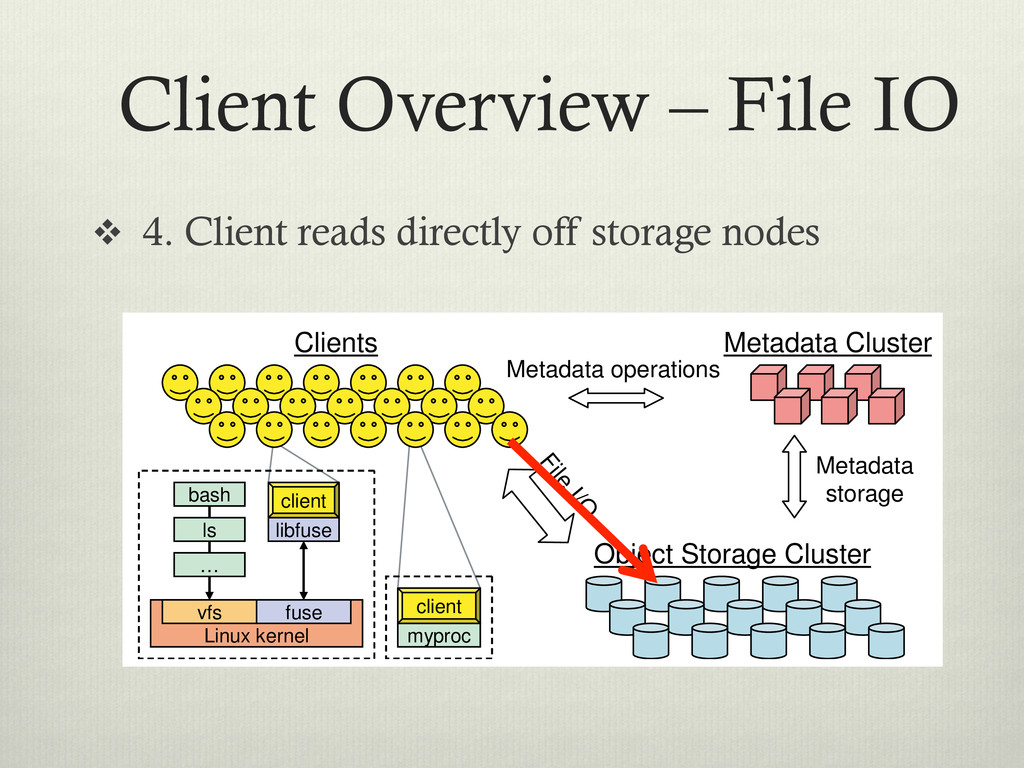
off storage nodes Metadata storage File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in
a small amount of information v Performance: Small bandwidth between client and MDS v Performance Small cache (memory) due to small data v Client calculates file location using function v Reliability: Saves the MDS from keeping block locations v Function described in data storage section
File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in 1 2 3
‘ls –l’ v Directory listing immediately followed by a stat of each file v Reading directory gives all inodes in the directory v Namespace covered in detail next! $ ls -l total 0 drwxr-xr-x 4 dweitzel swanson 63 Aug 15 2011 apache drwxr-xr-x 5 dweitzel swanson 42 Jan 18 11:15 argus-pep-api-java drwxr-xr-x 5 dweitzel swanson 42 Jan 18 11:15 argus-pep-common drwxr-xr-x 7 dweitzel swanson 103 Jan 18 16:37 bestman2 drwxr-xr-x 6 dweitzel swanson 75 Jan 18 12:25 buildsys-macros
system attributes and directory structure v Metadata is stored in the distributed filesystem beside the data v Compare this to Hadoop, where metadata is stored only on the head nodes v Updates are staged in a journal, flushed occasionally to the distributed file system
to have ‘hot’ metadata that is needed by many clients v In order to be scalable, Ceph needs to distributed metadata requests among many servers v MDS will monitor frequency of queries using special counters v MDS will compare the counters with each other and split the directory tree to evenly split the load
Clients will receive metadata partition data from the MDS during a request Root MDS 0 MDS 4 MDS 1 MDS 2 MDS 3 Busy directory hashed across many MDS’s (owner, number change, pendent of state ferent a content for the
will be hashed across multiple MDS’s Root MDS 0 MDS 4 MDS 1 MDS 2 MDS 3 Busy directory hashed across many MDS’s (owner, number change, pendent of state ferent a content for the
v Update to the primary MDS for the subtree Root MDS 0 MDS 4 MDS 1 MDS 2 MDS 3 Busy directory hashed across many MDS’s (owner, number change, pendent of state ferent a content for the
File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in 1 2 3
among storage devices (OSD) v Increased performance from even data distribution v Increased resiliency: Losing any node is minimally effects the status of the cluster if even distribution v Problem: Don’t want to keep data locations in the metadata servers v Requires lots of memory if lots of data blocks
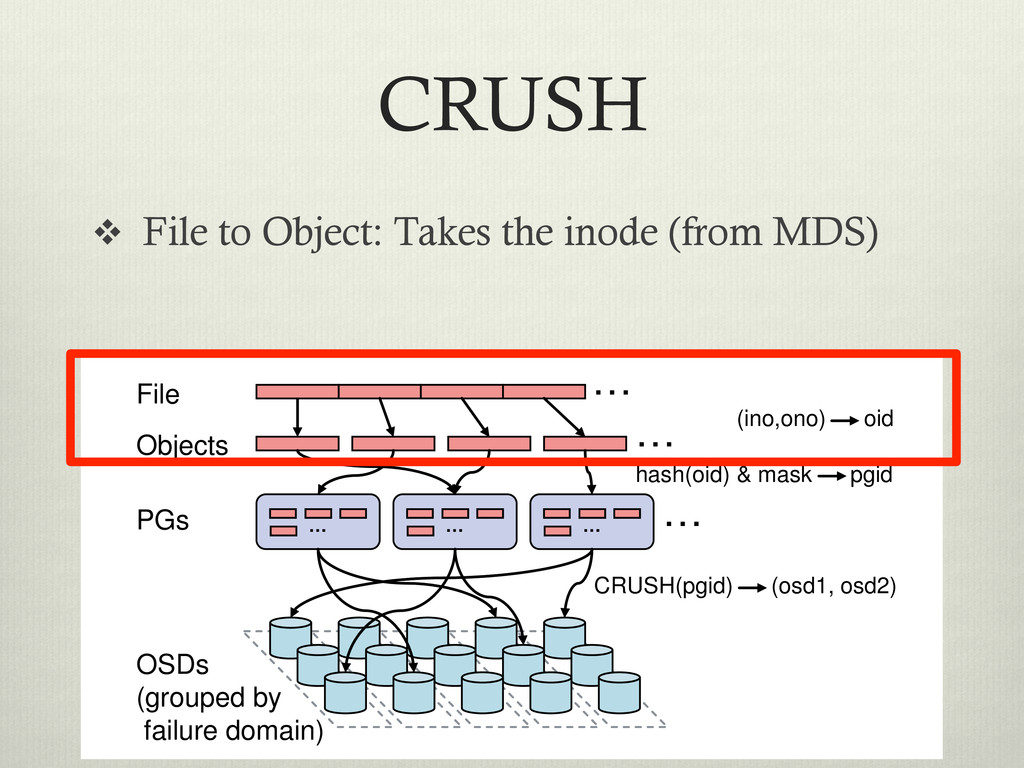
location of data in a distributed filesystem v Summary: Take a little information, plug into globally known function (hashing?) to find where the data is stored v Input data is: v inode number – From MDS v OSD Cluster Map (CRUSH map) – From OSD/ Monitors
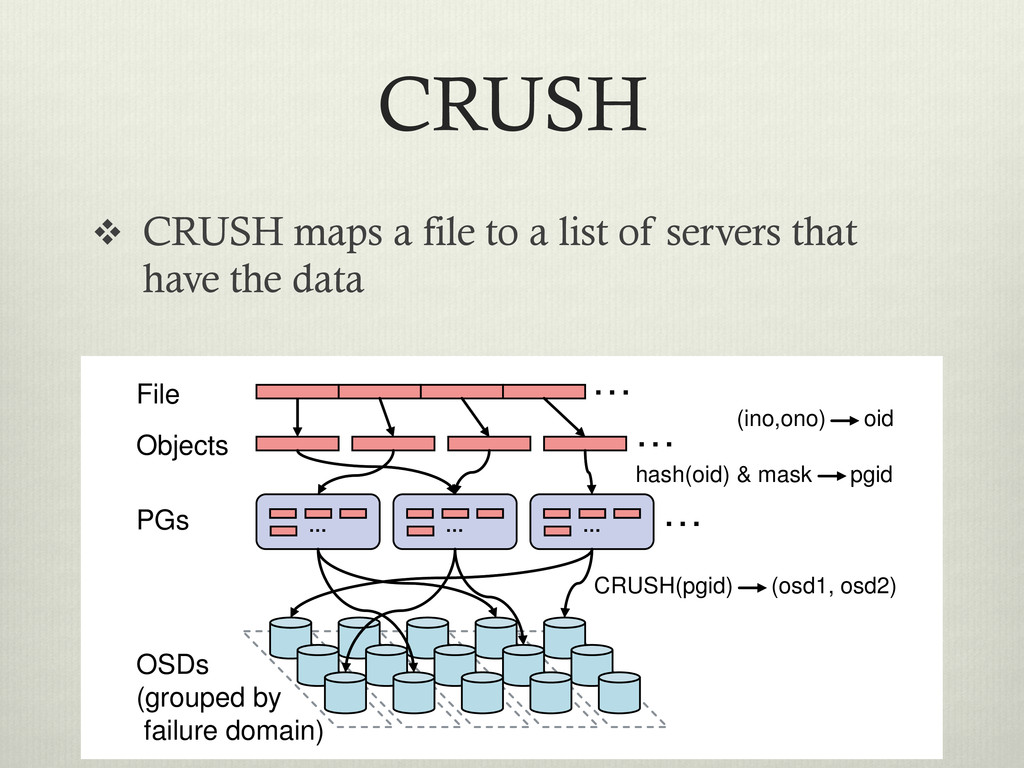
servers that have the data … … … … … … CRUSH(pgid) (osd1, osd2) OSDs (grouped by failure domain) File Objects hash(oid) & mask pgid PGs (ino,ono) oid to m u th so le fu c
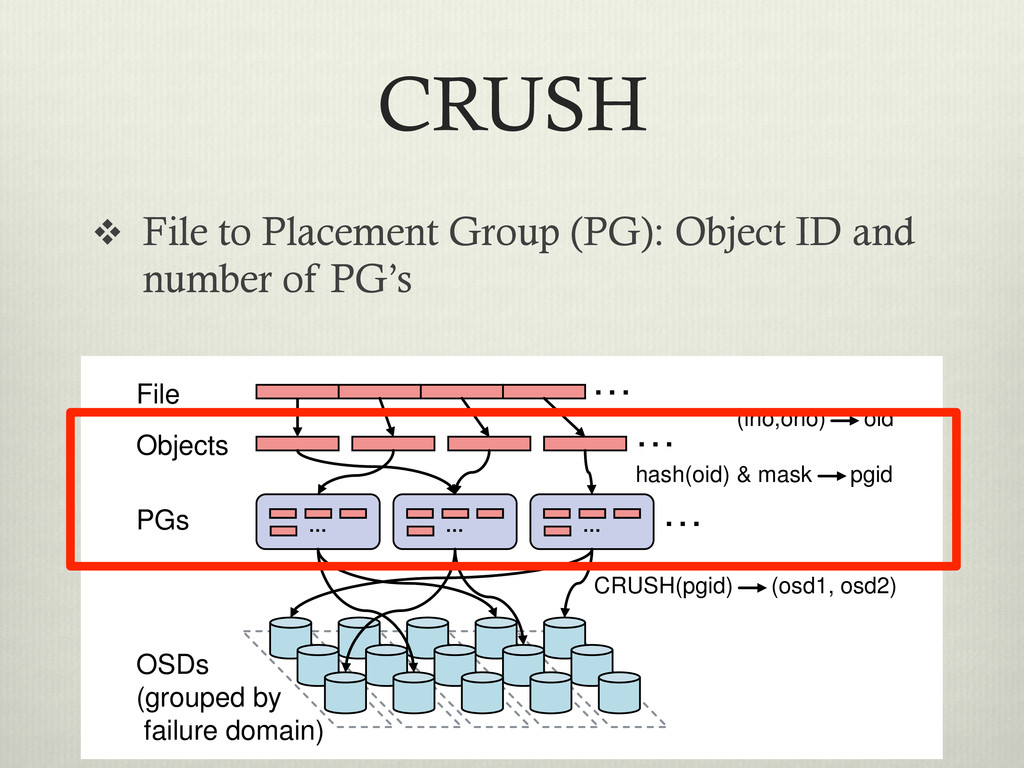
number of PG’s … … … … … … CRUSH(pgid) (osd1, osd2) OSDs (grouped by failure domain) File Objects hash(oid) & mask pgid PGs (ino,ono) oid to m u th so le fu c
of the objects v OSD’s will have many Placement Groups v Placement Groups will have R OSD’s, where R is number of replicas v An OSD will either be a Primary or Replica v Primary is in charge of accepting modification requests for the Placement Group v Clients will write to Primary, read from random member of Placement Group
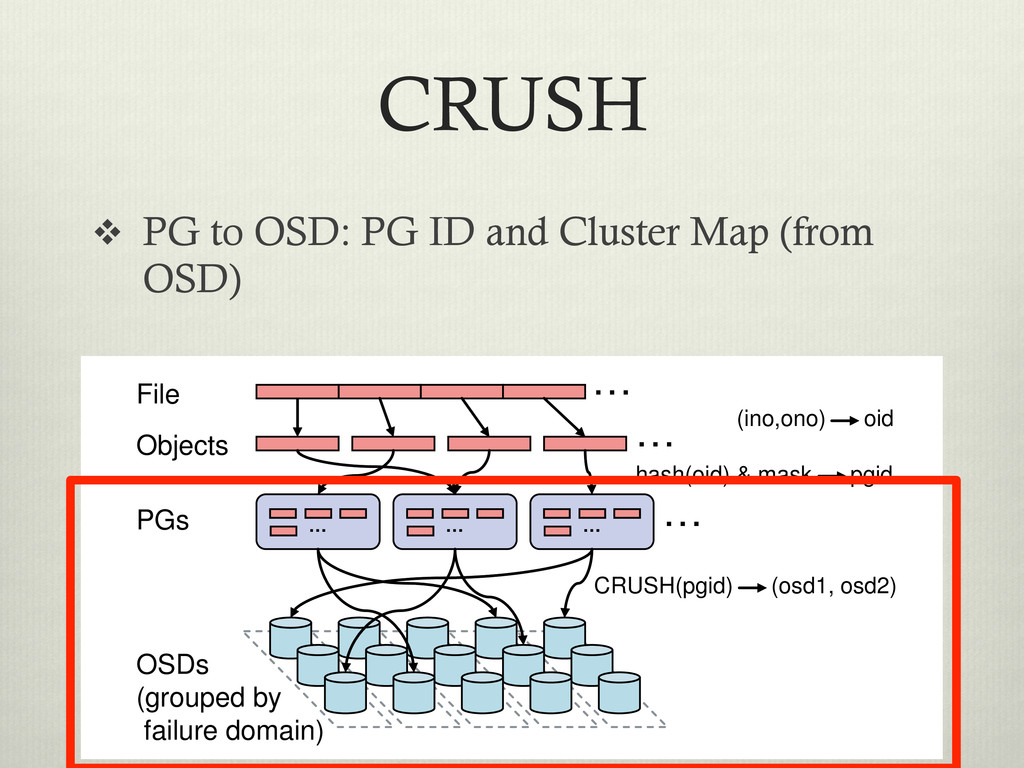
(from OSD) … … … … … … CRUSH(pgid) (osd1, osd2) OSDs (grouped by failure domain) File Objects hash(oid) & mask pgid PGs (ino,ono) oid to m u th so le fu c
OSD have two off modes, Down and Out. v Down is when the node could come back, Primary for a PG is handed off v Out is when a node will not come back, data is re- replicated.
storage File I/O Metadata Cluster Object Storage Cluster client bash Linux kernel fuse vfs libfuse ls … client bash Linux kernel fuse vfs libfuse ls … myproc client myproc client Clients Metadata operations Figure 1: System architecture. Clients perform file I/O by communicating directly with OSDs. Each process can de vi ba bl ca di tri sto th in 1 2 4
a distributed one v Filesystems have different characteristics v Example: RieserFS good at small files v XFS good at REALLY big files v Ceph keeps a lot of attributes on the inodes, needs a filesystem that can hanle attrs.
but slow v XFS, ext3/4, … v Created own Filesystem in order to handle special object requirements of Ceph v EBOFS – Extent and B-Tree based Object File System.
file system for Linux v Great Performance: Supports small files with fast lookup using B-Tree algorithm v Ceph Requirement: Supports unlimited chaining of attributes v Integrated into mainline kernel 2.6.29 v Considered next generation file system v Peer of ZFS from Sun v Child of ext3/4
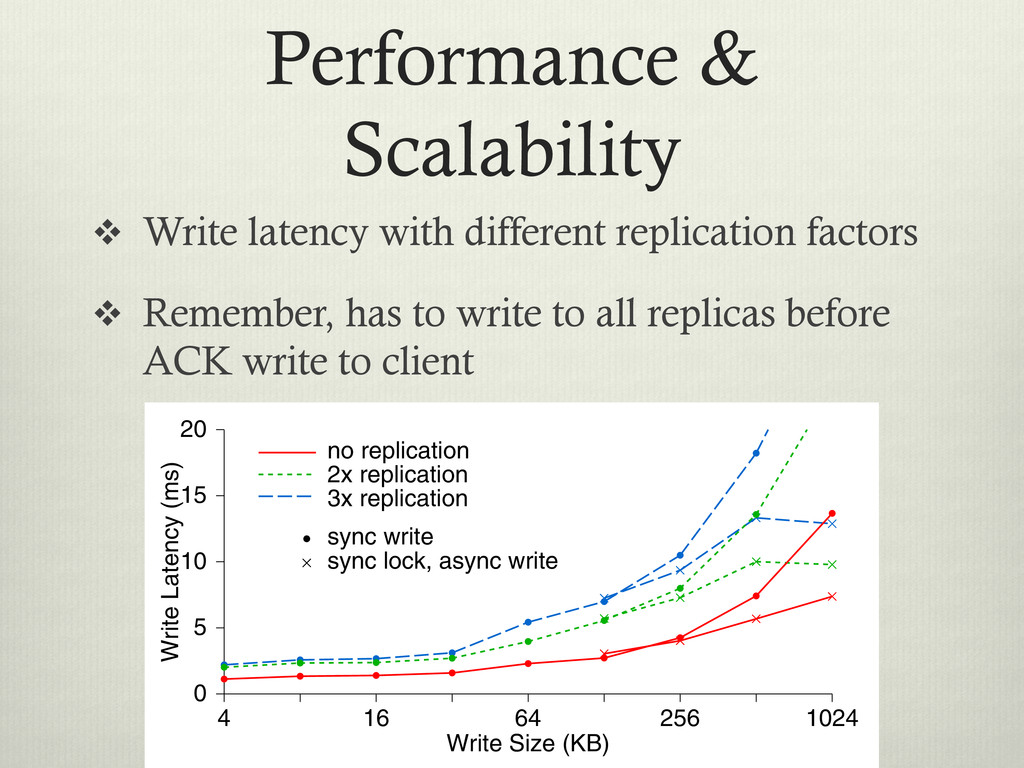
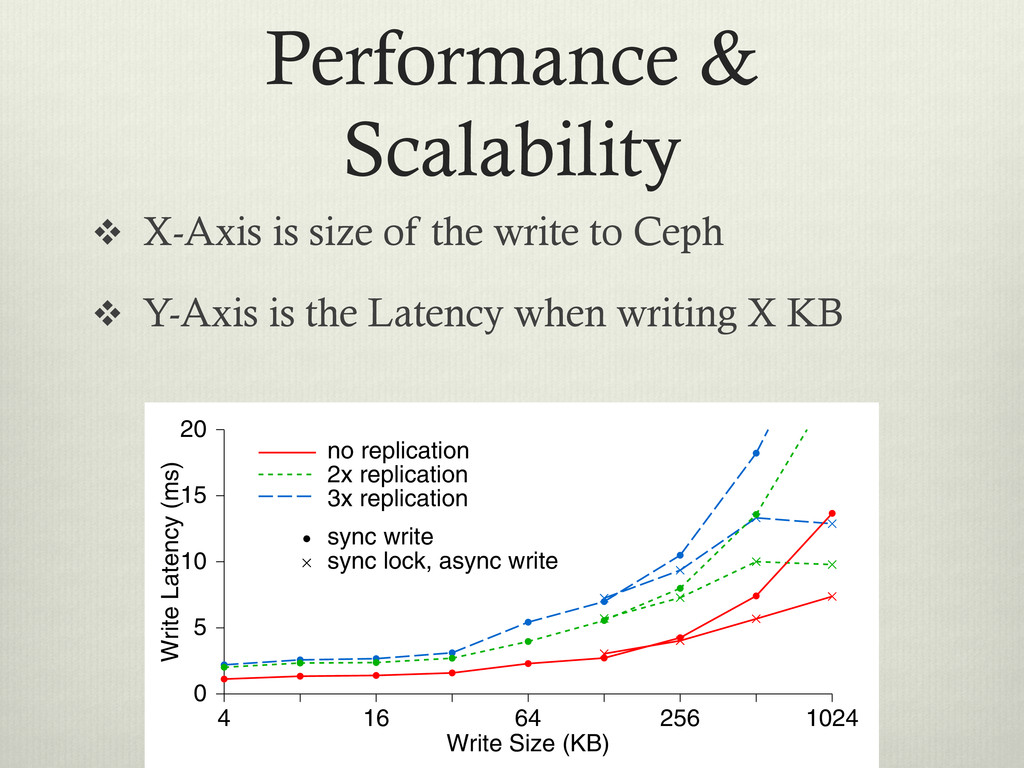
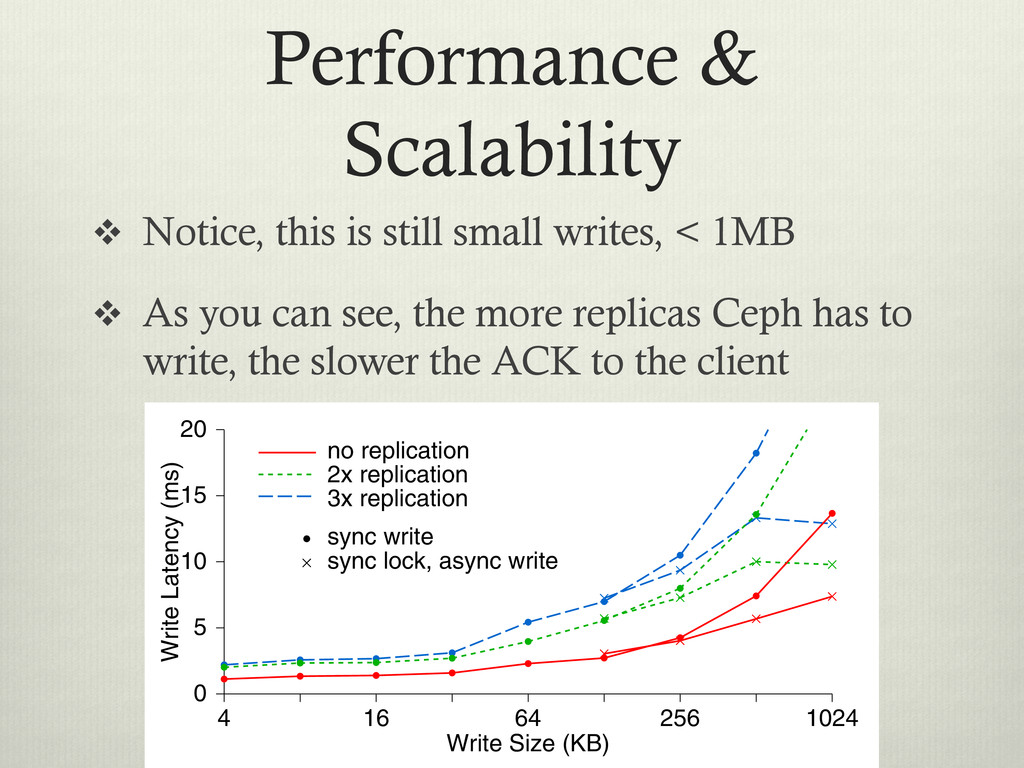
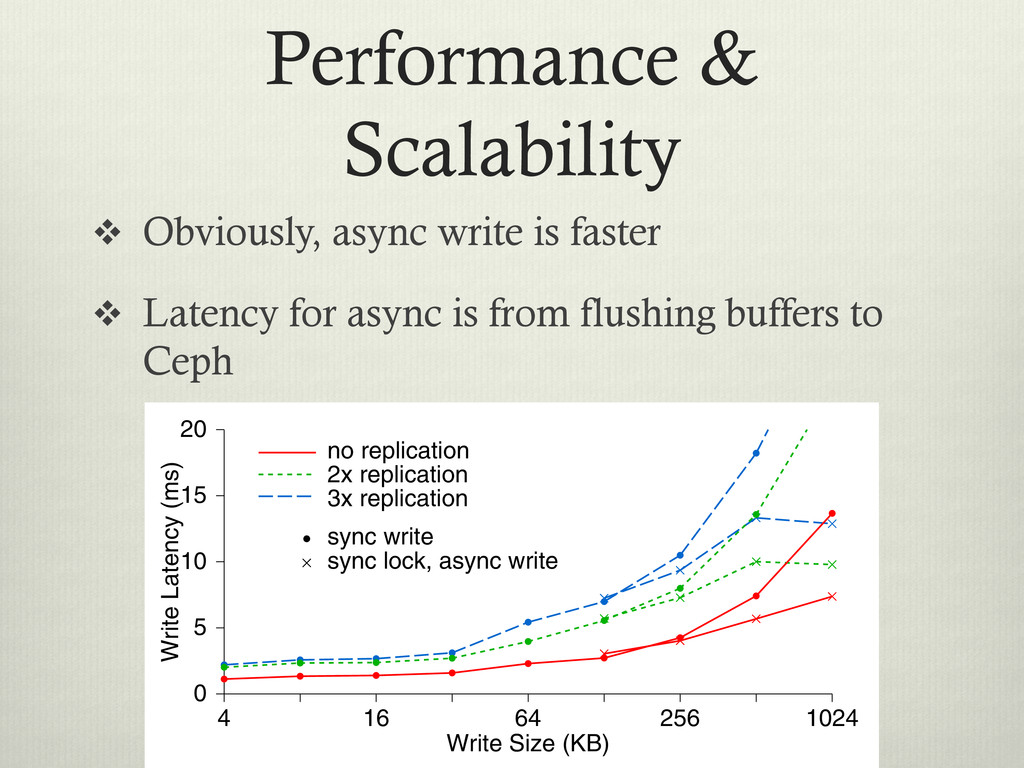
< 1MB v As you can see, the more replicas Ceph has to write, the slower the ACK to the client 4096 lication ication ication Write Size (KB) 4 16 64 256 1024 Write Latency (ms) 0 5 10 15 20 no replication 2x replication 3x replication sync write sync lock, async write
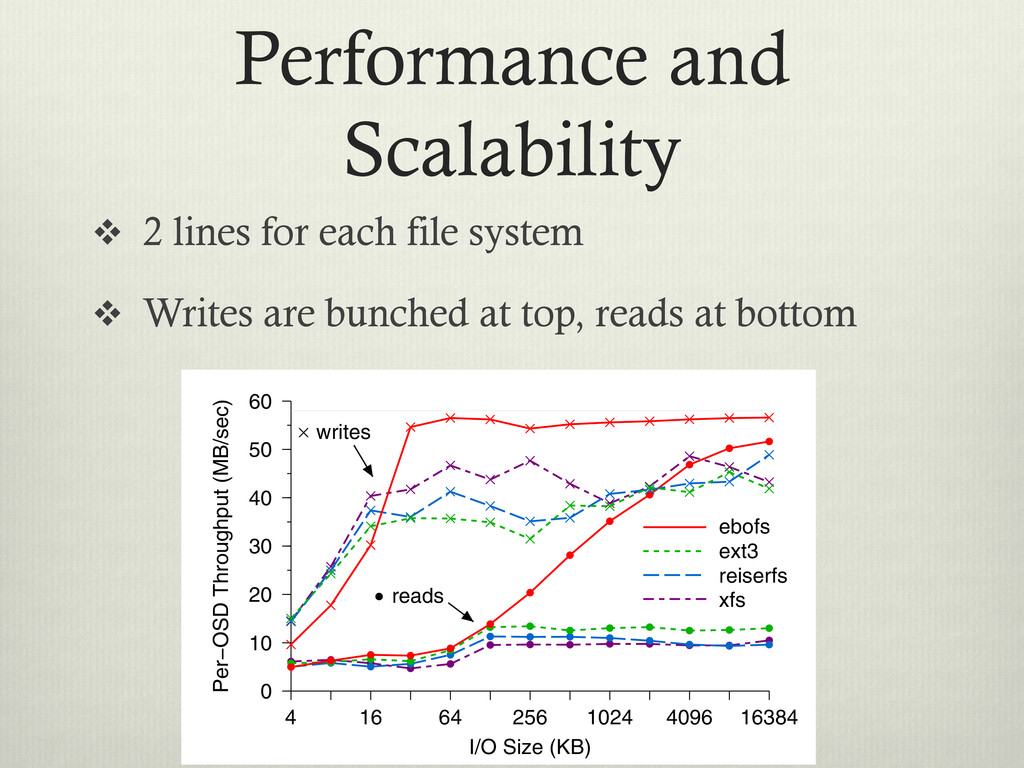
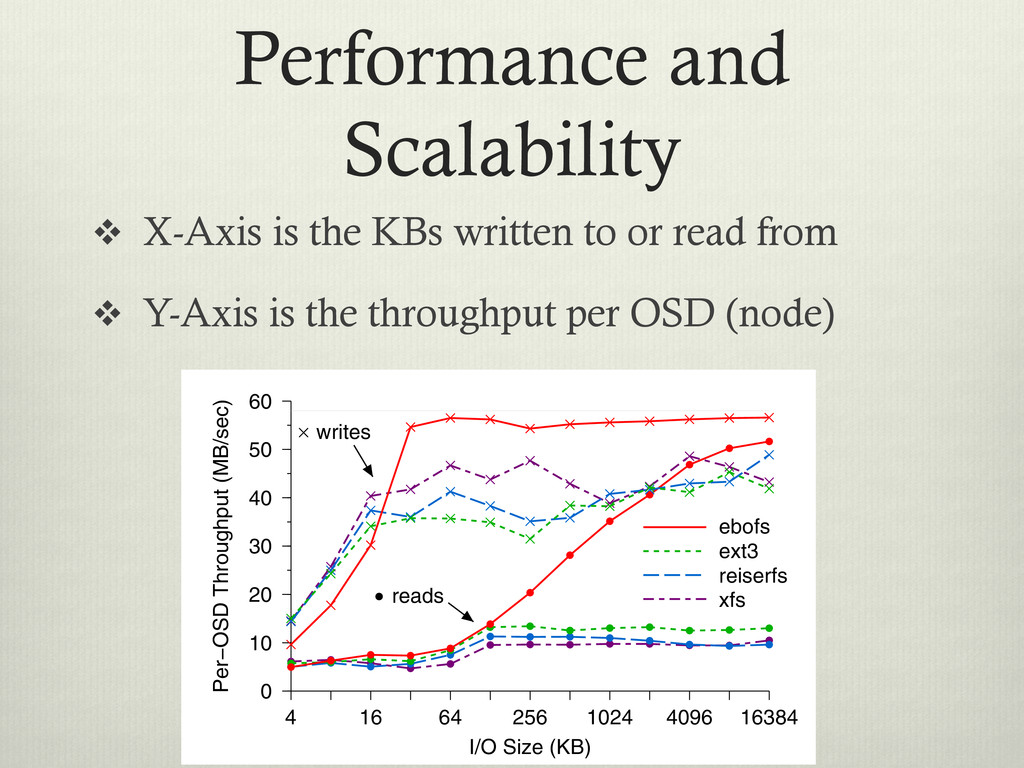
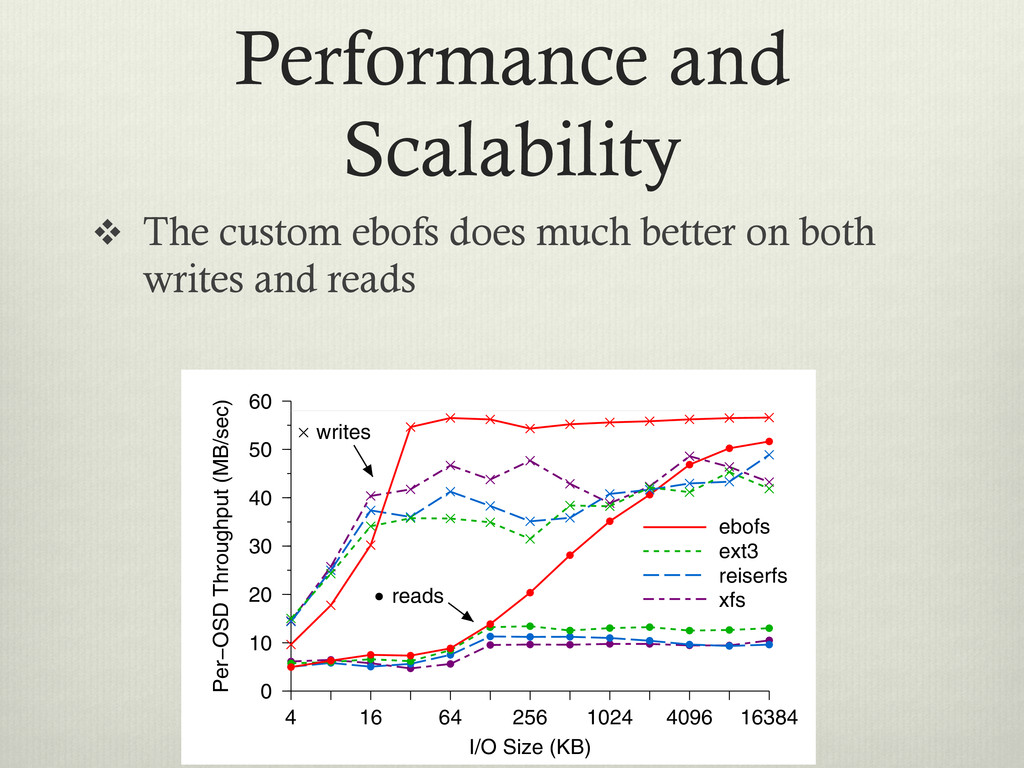
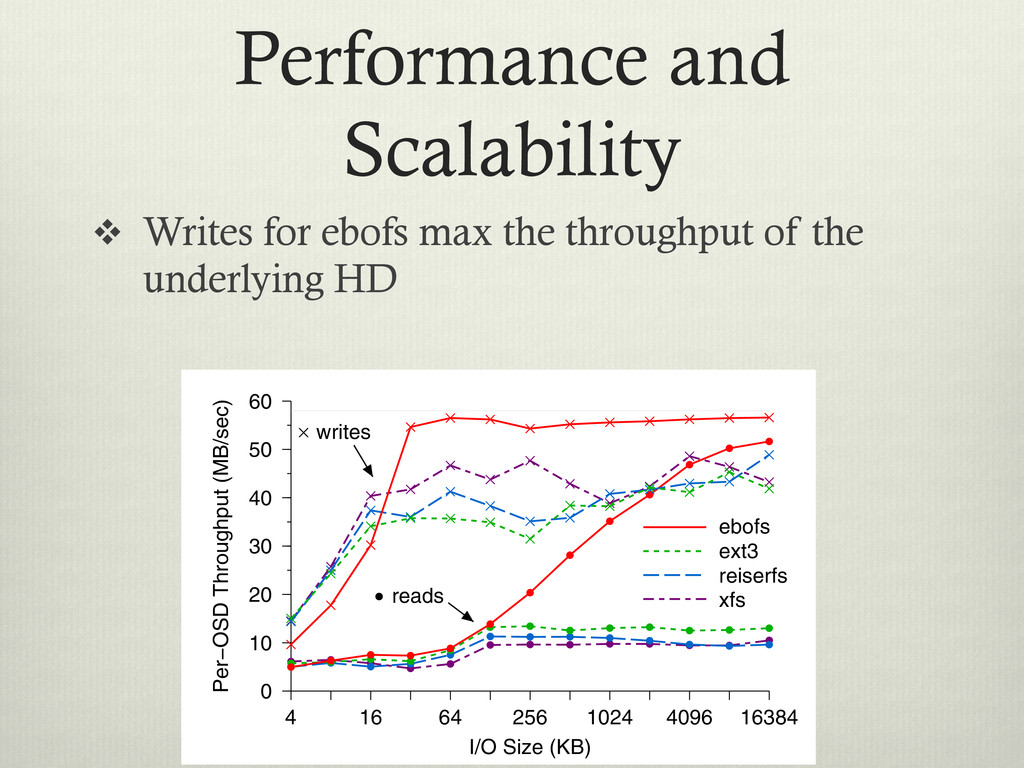
v Writes are bunched at top, reads at bottom Write Size (KB) 4 16 64 256 1024 4096 Per− 0 10 2x replication 3x replication Figure 5: Per-OSD write performance. The horizontal line indicates the upper limit imposed by the physical disk. Replication has minimal impact on OSD through- put, although if the number of OSDs is fixed, n-way replication reduces total effective throughput by a factor of n because replicated data must be written to n OSDs. I/O Size (KB) 4 16 64 256 1024 4096 16384 Per−OSD Throughput (MB/sec) 0 10 20 30 40 50 60 ebofs ext3 reiserfs xfs reads writes 4 Write 0 5 Figure 7: Write cation. More th cost for small concurrently. F sion times dom for writes over asynchronously 2 Per−OSD Throughput (MB/sec) 30 40 50 60 Figure 8: OSD
or read from v Y-Axis is the throughput per OSD (node) Write Size (KB) 4 16 64 256 1024 4096 Per− 0 10 2x replication 3x replication Figure 5: Per-OSD write performance. The horizontal line indicates the upper limit imposed by the physical disk. Replication has minimal impact on OSD through- put, although if the number of OSDs is fixed, n-way replication reduces total effective throughput by a factor of n because replicated data must be written to n OSDs. I/O Size (KB) 4 16 64 256 1024 4096 16384 Per−OSD Throughput (MB/sec) 0 10 20 30 40 50 60 ebofs ext3 reiserfs xfs reads writes 4 Write 0 5 Figure 7: Write cation. More th cost for small concurrently. F sion times dom for writes over asynchronously 2 Per−OSD Throughput (MB/sec) 30 40 50 60 Figure 8: OSD
on both writes and reads Write Size (KB) 4 16 64 256 1024 4096 Per− 0 10 2x replication 3x replication Figure 5: Per-OSD write performance. The horizontal line indicates the upper limit imposed by the physical disk. Replication has minimal impact on OSD through- put, although if the number of OSDs is fixed, n-way replication reduces total effective throughput by a factor of n because replicated data must be written to n OSDs. I/O Size (KB) 4 16 64 256 1024 4096 16384 Per−OSD Throughput (MB/sec) 0 10 20 30 40 50 60 ebofs ext3 reiserfs xfs reads writes 4 Write 0 5 Figure 7: Write cation. More th cost for small concurrently. F sion times dom for writes over asynchronously 2 Per−OSD Throughput (MB/sec) 30 40 50 60 Figure 8: OSD
of the underlying HD Write Size (KB) 4 16 64 256 1024 4096 Per− 0 10 2x replication 3x replication Figure 5: Per-OSD write performance. The horizontal line indicates the upper limit imposed by the physical disk. Replication has minimal impact on OSD through- put, although if the number of OSDs is fixed, n-way replication reduces total effective throughput by a factor of n because replicated data must be written to n OSDs. I/O Size (KB) 4 16 64 256 1024 4096 16384 Per−OSD Throughput (MB/sec) 0 10 20 30 40 50 60 ebofs ext3 reiserfs xfs reads writes 4 Write 0 5 Figure 7: Write cation. More th cost for small concurrently. F sion times dom for writes over asynchronously 2 Per−OSD Throughput (MB/sec) 30 40 50 60 Figure 8: OSD
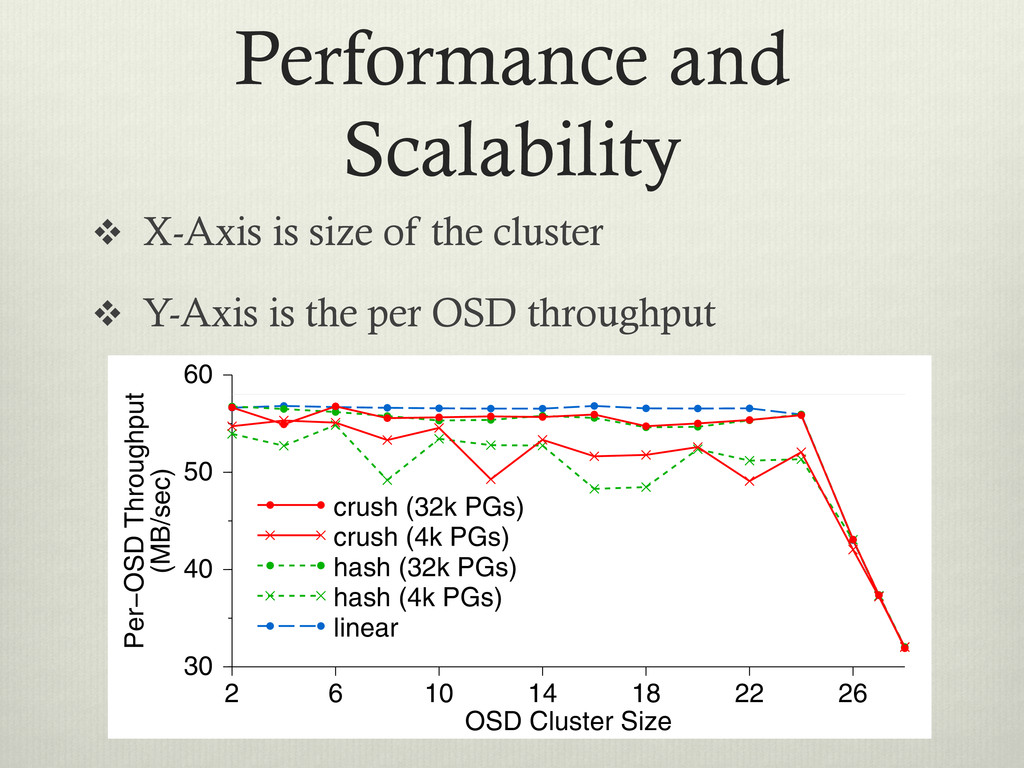
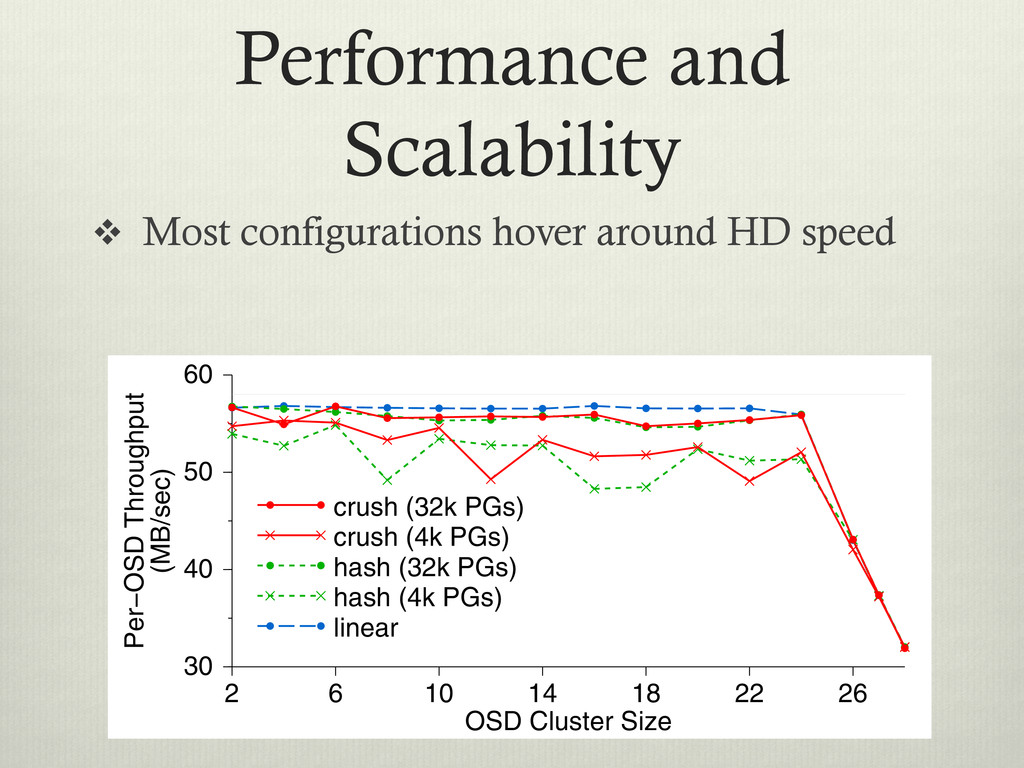
v Y-Axis is the per OSD throughput ical gh- way ctor Ds. 384 fs cation. More than two replicas incurs minimal additional cost for small writes because replicated updates occur concurrently. For large synchronous writes, transmis- sion times dominate. Clients partially mask that latency for writes over 128 KB by acquiring exclusive locks and asynchronously flushing the data. OSD Cluster Size 2 6 10 14 18 22 26 Per−OSD Throughput (MB/sec) 30 40 50 60 crush (32k PGs) crush (4k PGs) hash (32k PGs) hash (4k PGs) linear
ical gh- way ctor Ds. 384 fs cation. More than two replicas incurs minimal additional cost for small writes because replicated updates occur concurrently. For large synchronous writes, transmis- sion times dominate. Clients partially mask that latency for writes over 128 KB by acquiring exclusive locks and asynchronously flushing the data. OSD Cluster Size 2 6 10 14 18 22 26 Per−OSD Throughput (MB/sec) 30 40 50 60 crush (32k PGs) crush (4k PGs) hash (32k PGs) hash (4k PGs) linear
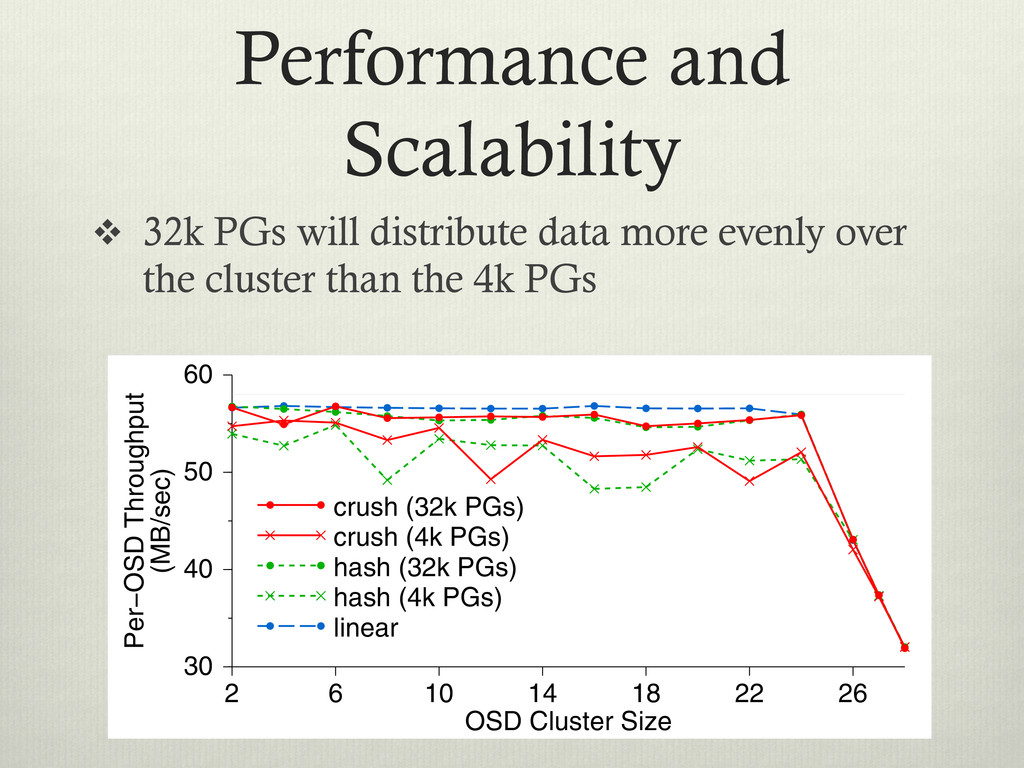
evenly over the cluster than the 4k PGs ical gh- way ctor Ds. 384 fs cation. More than two replicas incurs minimal additional cost for small writes because replicated updates occur concurrently. For large synchronous writes, transmis- sion times dominate. Clients partially mask that latency for writes over 128 KB by acquiring exclusive locks and asynchronously flushing the data. OSD Cluster Size 2 6 10 14 18 22 26 Per−OSD Throughput (MB/sec) 30 40 50 60 crush (32k PGs) crush (4k PGs) hash (32k PGs) hash (4k PGs) linear
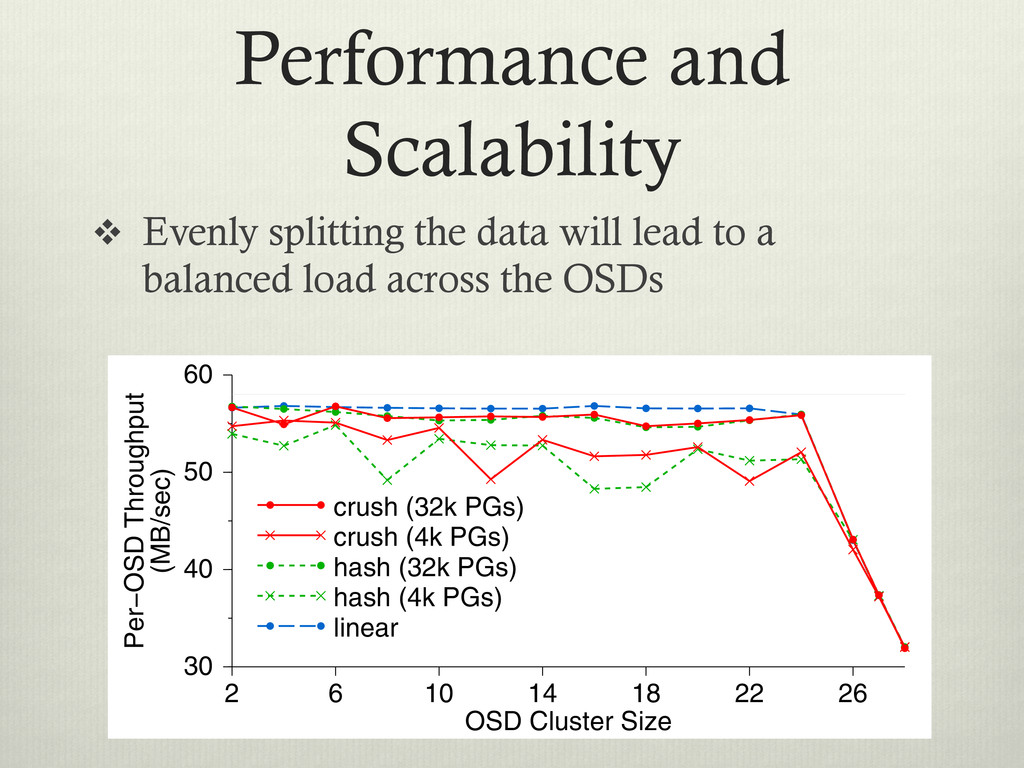
to a balanced load across the OSDs ical gh- way ctor Ds. 384 fs cation. More than two replicas incurs minimal additional cost for small writes because replicated updates occur concurrently. For large synchronous writes, transmis- sion times dominate. Clients partially mask that latency for writes over 128 KB by acquiring exclusive locks and asynchronously flushing the data. OSD Cluster Size 2 6 10 14 18 22 26 Per−OSD Throughput (MB/sec) 30 40 50 60 crush (32k PGs) crush (4k PGs) hash (32k PGs) hash (4k PGs) linear
enough for many applications v No single point of failure – Important for large data centers v Can handle HPC like applications (lots of metadata, small files)
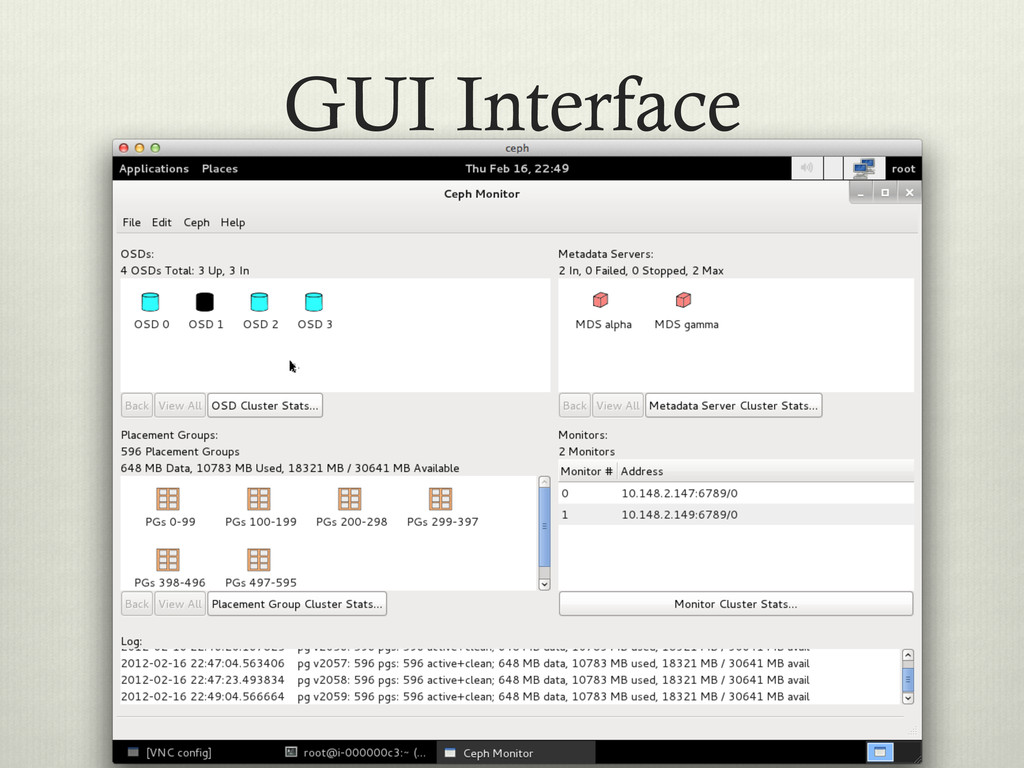
v http://ceph.newdream.net/ v Instruction on setting up CEPH can be found on the Ceph wiki: v http://ceph.newdream.net/wiki/ v Or my blog v http://derekweitzel.blogspot.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}