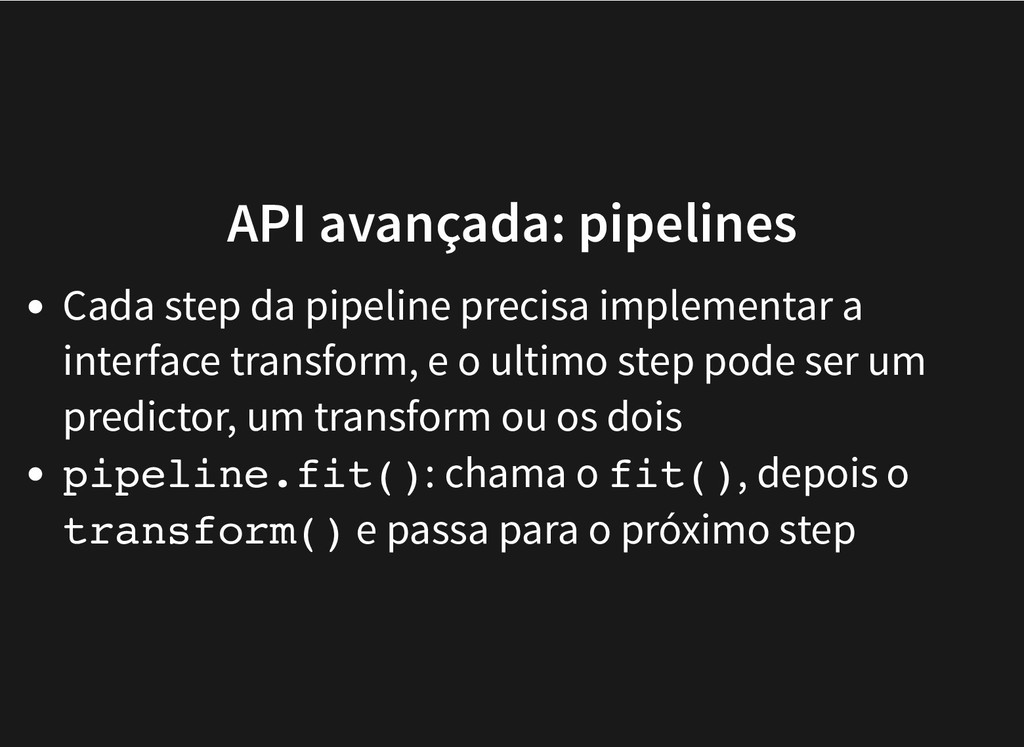
O Pipeline do Scikit-learn é um objeto da biblioteca que facilita bastante o processamento de dados, sendo possível tanto treinar quando fazer predições utilizando a mesma Pipeline. Usar os modelos no Jupyter Notebook é uma das tarefas que realizamos durante as análises, mas o objetivo final de muitas soluções é integrar os modelos com alguma aplicação (normalmente aplicações web). Nesta palestra vamos treinar um modelo usando o scikit-learn e usar o Flask para construir uma API REST capaz de disponibilizar o modelo como um serviço web.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}