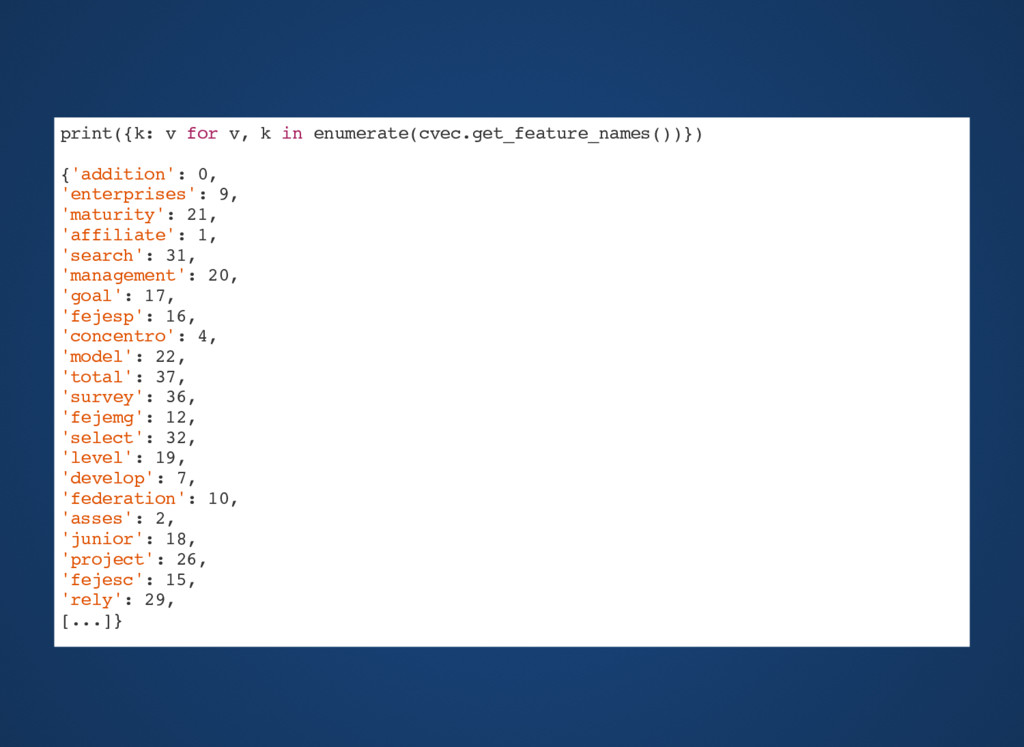
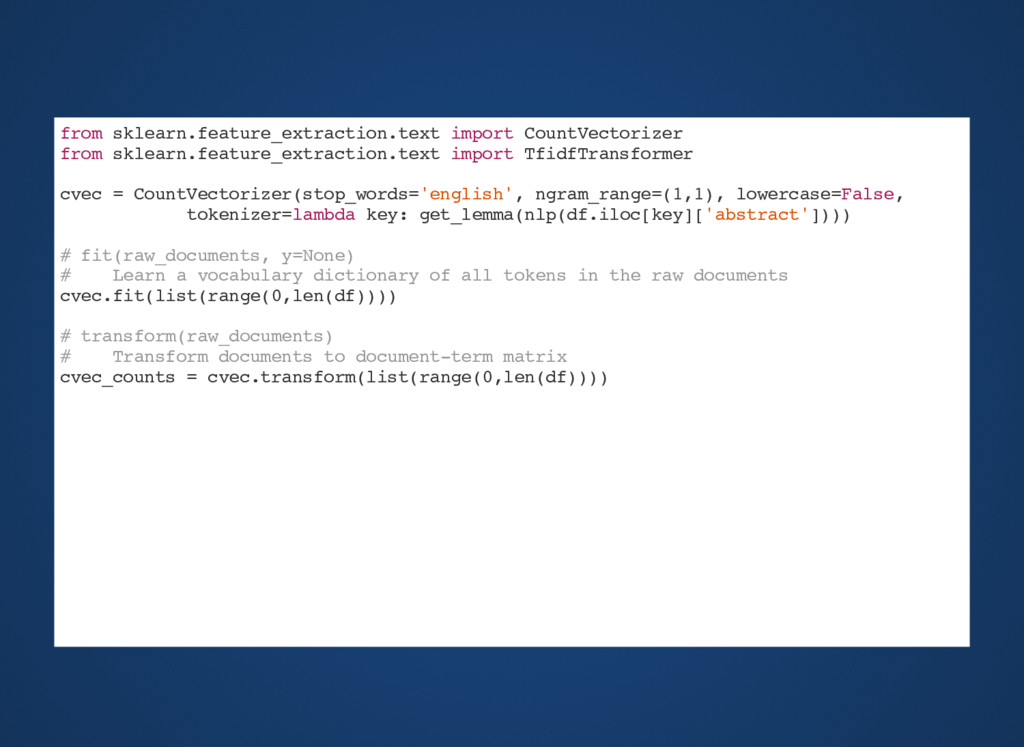
not token.is_punct and (not token.is_digit) and (not token.is_stop): if(len(token.lemma_) > 2): tokens.append(token.lemma_) return tokens lemmas = get_lemma(parsed_abstract) print(lemmas) >>> ['study', 'propose', 'develop', 'nationwide', 'survey', 'asses', 'level', 'maturity', 'project', 'management', 'junior', 'enterprise', 'brazil', 'rely', 'project', 'management', 'maturity', 'model', 'create', 'darci', 'prado', 'enterprise', 'survey', 'select', 'state', 'federation', 'junior', 'enterprises', 'affiliate', 'brazil', 'junior', 'fejece', 'fejepe', 'unijr', 'fejemg', 'fejesp', 'fejepar', 'fejesc', 'rio', 'concentro', 'addition', 'state', 'not', 'affiliate', 'paraíba', 'sergipe', 'total', 'state', 'search', 'goal', 'reach', 'junior', 'enterprise', 'brazil'] print("Number of words:",len(lemmas)) >>> Number of words: 54
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def get_lemma(doc): tokens = [] for token in doc: if](https://files.speakerdeck.com/presentations/69df8e2a048843b9a3ba312bd529e151/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
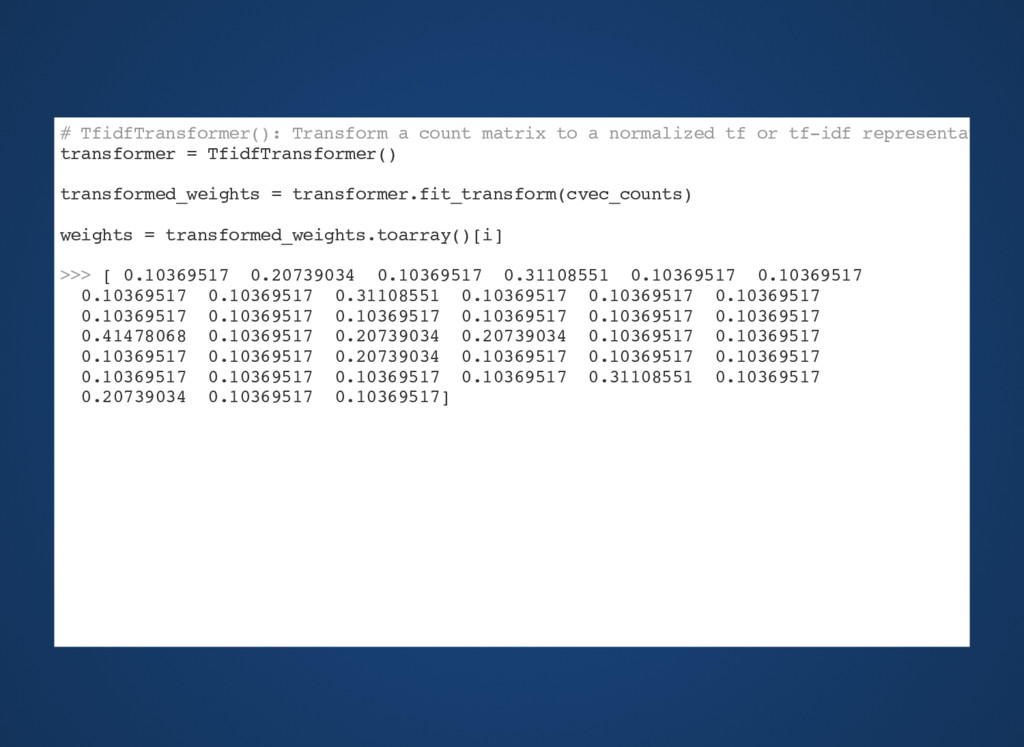{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Latent Semantic Indexing “ [...] palavras usados no mesmo contexto](https://files.speakerdeck.com/presentations/69df8e2a048843b9a3ba312bd529e151/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
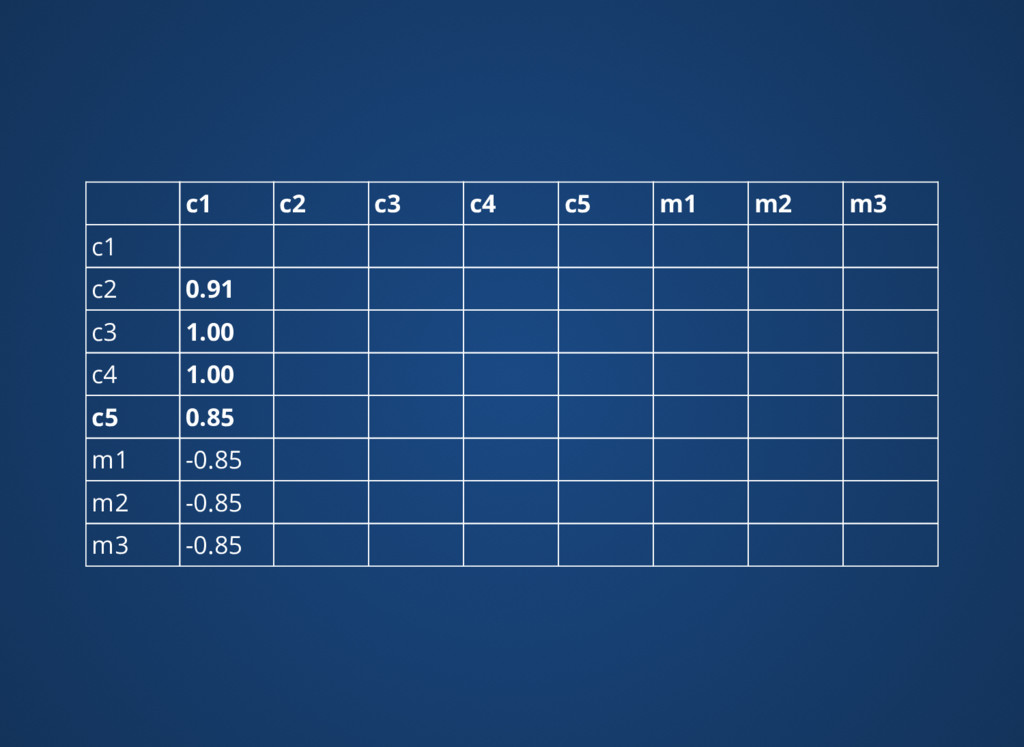{kind=link}
{kind=link}
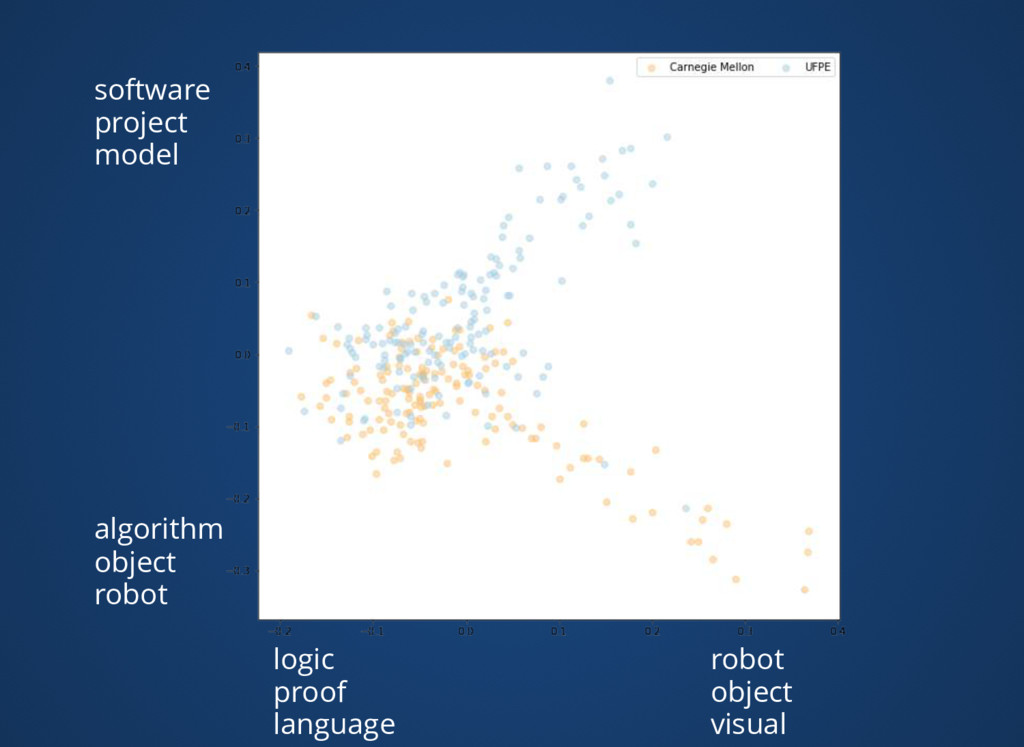{kind=link}
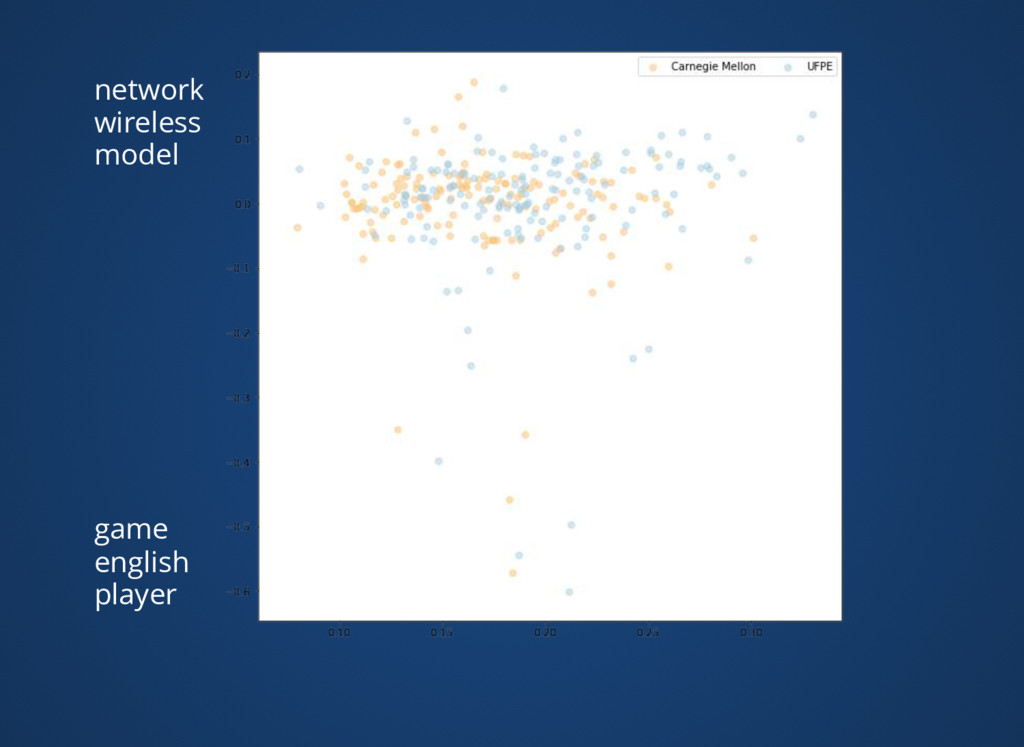{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}