ORC History Originally released as part of Hive – Released in Hive 0.11.0 (2013-05-16) – Included in each release before Hive 2.3.0 (2017-07-17) Factored out of Hive – Improve integration with other tools – Shrink the size of the dependencies – Releases faster than Hive – Added C++ reader and new C++ writer
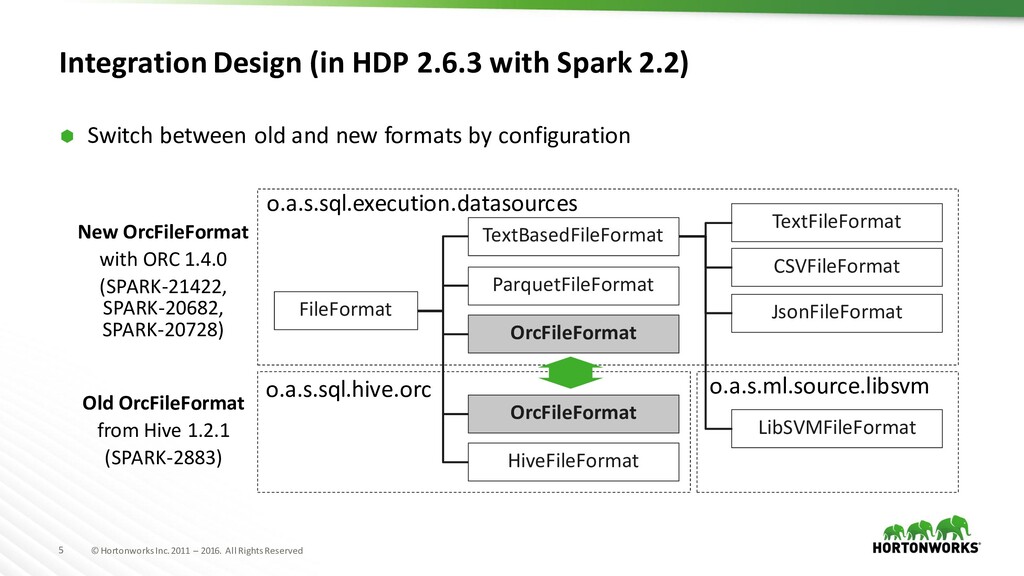
Integration Design (in HDP 2.6.3 with Spark 2.2) Switch between old and new formats by configuration FileFormat TextBasedFileFormat ParquetFileFormat OrcFileFormat HiveFileFormat JsonFileFormat LibSVMFileFormat CSVFileFormat TextFileFormat o.a.s.sql.execution.datasources o.a.s.ml.source.libsvm o.a.s.sql.hive.orc OrcFileFormat Old OrcFileFormat from Hive 1.2.1 (SPARK-2883) New OrcFileFormat with ORC 1.4.0 (SPARK-21422, SPARK-20682, SPARK-20728)
Benefit in Apache Spark Speed – Use both Spark ColumnarBatch and ORC RowBatch together more seamlessly Stability – Apache ORC 1.4.0 has many fixes and we can depend on ORC community more. Usability – User can use ORC data sources without hive module, i.e, -Phive. Maintainability – Reduce the Hive dependency and can remove old legacy code later.
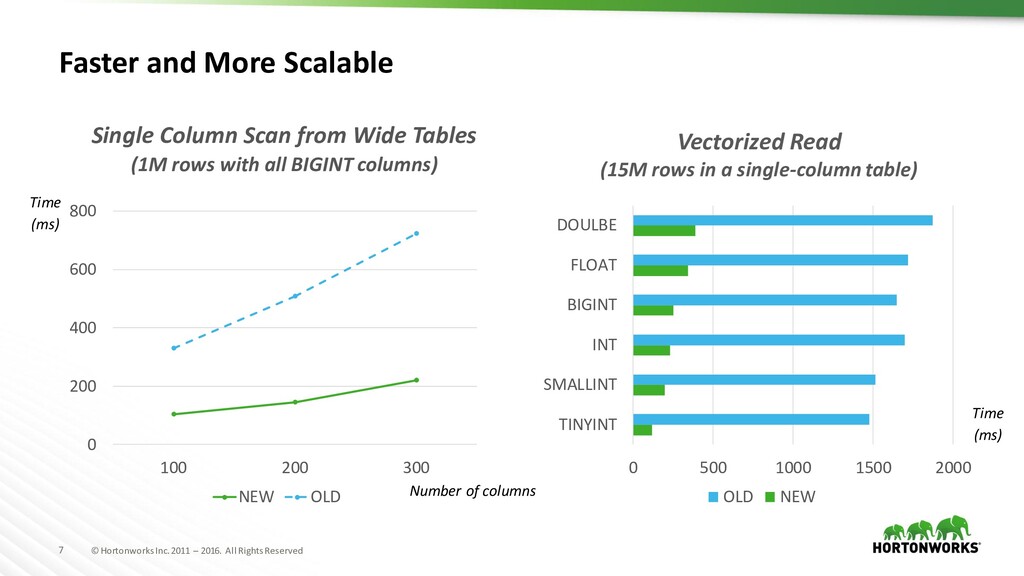
Faster and More Scalable Number of columns Time (ms) Single Column Scan from Wide Tables (1M rows with all BIGINT columns) 0 500 1000 1500 2000 TINYINT SMALLINT INT BIGINT FLOAT DOULBE OLD NEW Vectorized Read (15M rows in a single-column table) Time (ms) 0 200 400 600 800 100 200 300 NEW OLD
Support Matrix HDP 2.6.3 is going to add a new faster and stable ORC file format for ORC tables with the subset of limitations of Apache Spark 2.2. The followings are not supported yet – Zero-byte ORC File – Schema Evolution • Adding columns at the end • Changing types and deleting columns Please see the full JIRA issue list in next slides.
Done Tickets SPARK-20901 Feature parity for ORC with Parquet – The parent ticket of all ORC issues Done – SPARK-20566 ColumnVector should support `appendFloats` for array – SPARK-21422 Depend on Apache ORC 1.4.0 – SPARK-21831 Remove `spark.sql.hive.convertMetastoreOrc` config in HiveCompatibilitySuite – SPARK-21839 Support SQL config for ORC compression – SPARK-21884 Fix StackOverflowError on MetadataOnlyQuery – SPARK-21912 ORC/Parquet table should not create invalid column names
On-Going Tickets SPARK-20682 Support a new faster ORC data source based on Apache ORC SPARK-20728 Make ORCFileFormat configurable between sql/hive and sql/core SPARK-16060 Vectorized Orc reader SPARK-21791 ORC should support column names with dot SPARK-21787 Support for pushing down filters for DATE types in ORC SPARK-19809 Zero byte ORC file support SPARK-14387 Enable Hive-1.x ORC compatibility with spark.sql.hive.convertMetastoreOrc
To-do Tickets Configuration – SPARK-21783 Turn on ORC filter push-down by default Read – SPARK-11412 Support merge schema for ORC – SPARK-16628 OrcConversions should not convert an ORC table Alter – SPARK-21929 Support `ALTER TABLE ADD COLUMNS(..)` for ORC data source – SPARK-18355 Spark SQL fails to read from a ORC table with new column Write – SPARK-12417 Orc bloom filter options are not propagated during file write
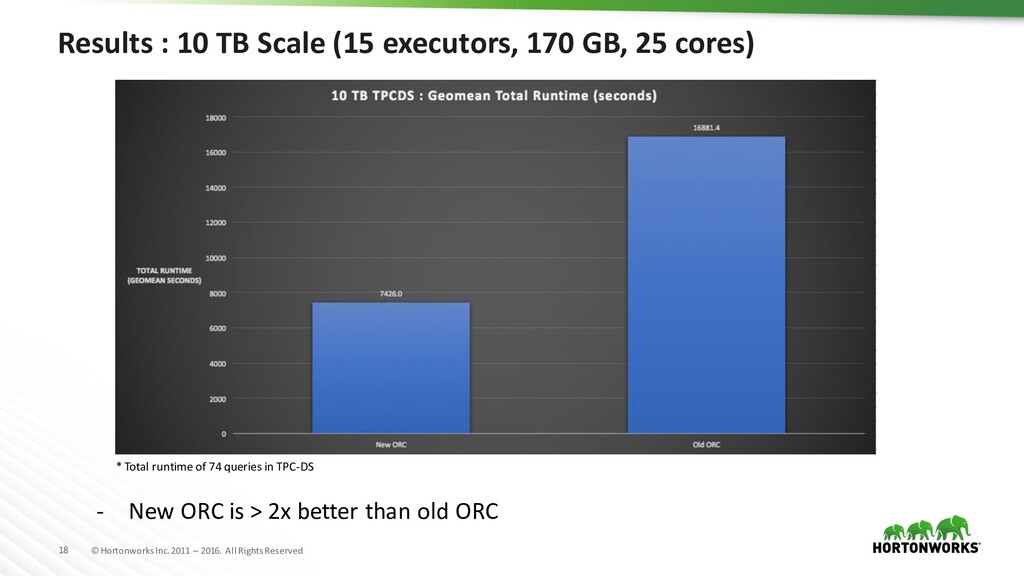
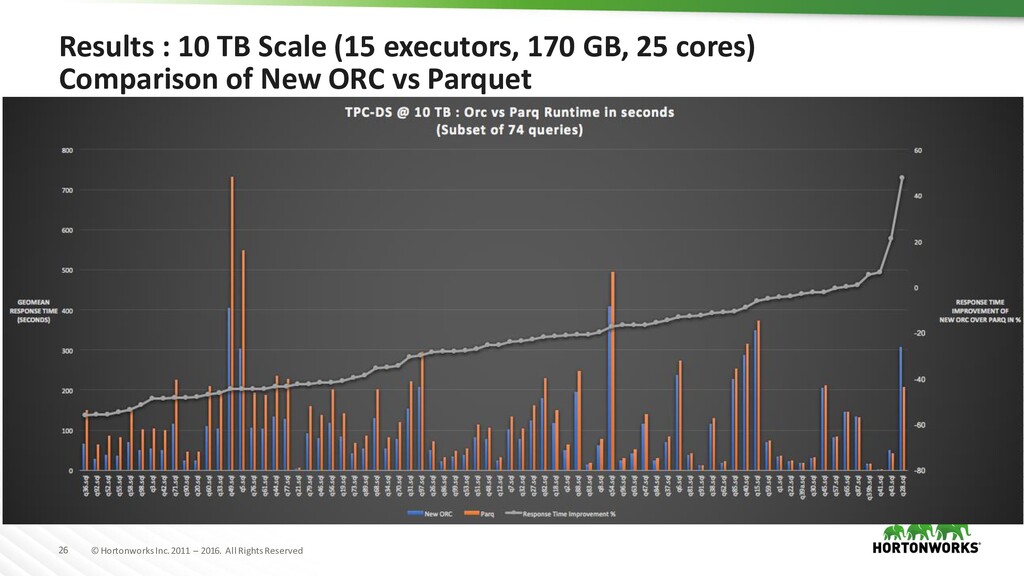
Software/Hardware/Cluster Details Software – Internal branch of Spark 2.2 (in HDP) Node Configuration – 32 CPU, Intel E5-2640, 2.00GHz – 256 GB RAM – 6 SATA Disks (~4 TB, 7200 rpm) – 10 Gbps network card Cluster – 10 nodes used for 1 TB – 15 nodes used for 10 TB – Double type used in data – TPC-DS (1.4) queries in Spark used for benchmarking
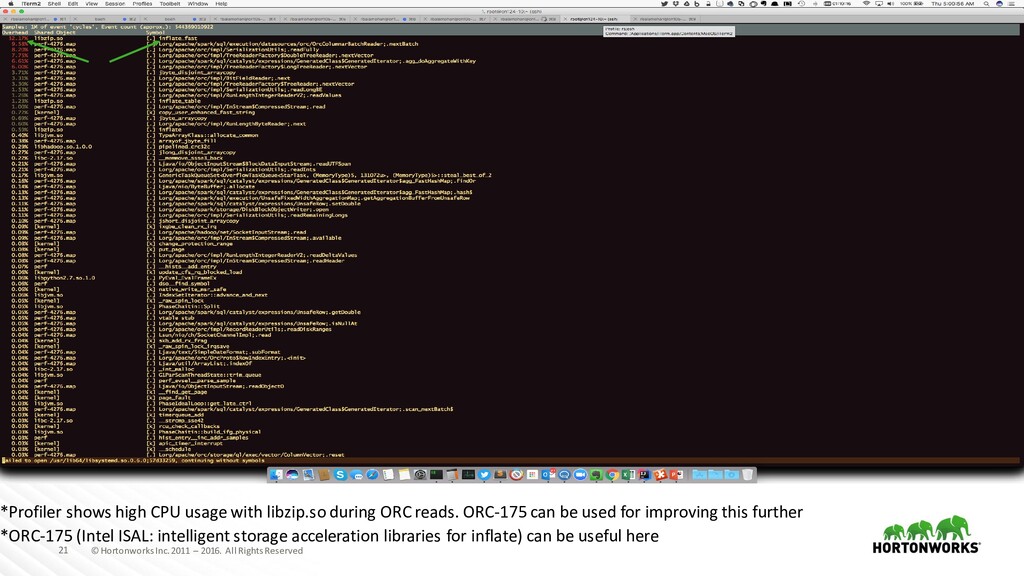
*Profiler shows high CPU usage with libzip.so during ORC reads. ORC-175 can be used for improving this further *ORC-175 (Intel ISAL: intelligent storage acceleration libraries for inflate) can be useful here
RoadMap Tune default ambari configs for spark based on these benchmark results to get better OOTB experience for end users Additional enhancements like parallel reading of footers in ORC Include ORC-175 (Intel ISAL) when complete Contribute back the fixes back to community
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}