ORC Reader • Structured Streaming with ORC • Schema evolution with ORC • PySpark Performance Enhancements with Apache Arrow and ORC • Structured stream-stream joins • Spark History Server V2 • Spark on Kubernetes • Data source API V2 • Streaming API V2 • Continuous Structured Streaming Processing Major Features Experimental Features Apache Spark 2.3.x Spark 2.3.0 (and 2.3.1) has 1409 (and 134) JIRA issues.
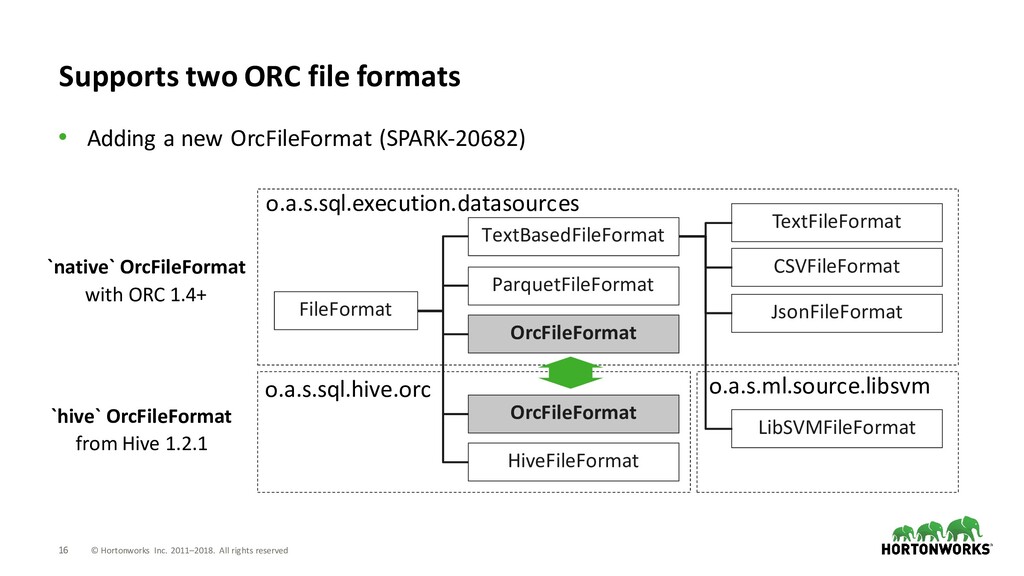
file-based data sources • TEXT The simplest one with one string column schema • CSV Popular for data science workloads • JSON The most flexible one for schema changes • PARQUET The only one with vectorized reader • ORC Storage-efficient and popular for shared Hive tables
TEXT The simplest one with one string column schema • CSV Popular for data science workloads • JSON The most flexible one for schema changes • PARQUET The only one with vectorized reader • ORC Storage-efficient and popular for shared Hive tables Fast Flexible Hive Table Access
– ORC Writer Versions • ORIGINAL • HIVE_8732 (2014) ORC string statistics are not merged correctly • HIVE_4243 (2015) Use real column names from Hive tables • HIVE_12055(2015) Vectorized Writer • HIVE_13083(2016) Decimals write present stream correctly • ORC_101 (2016) Correct the use of the default charset in bloomfilter • ORC_135 (2018) PPD for timestamp is wrong when reader/writer timezones are different
– Hive tables and schema evolution • Support `ALTER TABLE ADD COLUMNS` (SPARK-21929) − Introduced at Spark 2.2, but throws AnalysisException for ORC • Support column positional mismatch (SPARK-22267) − Return wrong result if ORC file schema is different from Hive MetaStore schema order • Support table properties during `convertMetastoreOrc/Parquet` (SPARK-23355, Spark 2.4) − For ORC/Parquet Hive tables, `convertMetastore` ignores table properties
– Four cases for ORC Reader/Writer `hive` Reader `native` Reader `hive` Writer `native` Writer • New Data • New Apps • Best performance (Vectorized Reader) • New Data • Old Apps • Improved performance (Non-vectorized Reader) • Old Data • New Apps • Improved performance (Vectorized Reader) • Old Data • Old Apps • As-Is performance (Non-vectorized Reader) 1 2 3 4
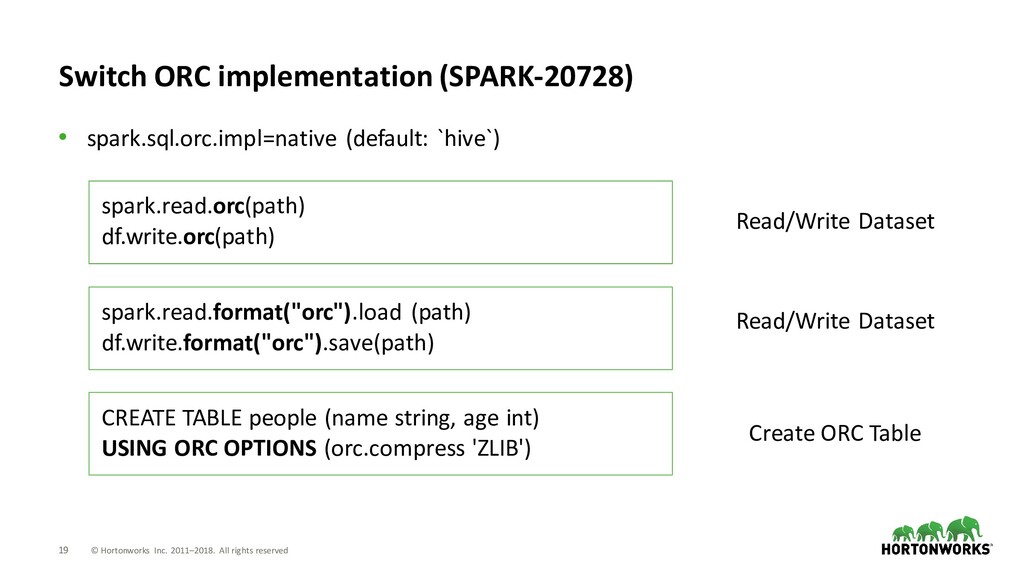
read on Hive ORC Tables • spark.sql.hive.convertMetastoreOrc=true (default: false) − `spark.sql.orc.impl=native` is required, too. CREATE TABLE people (name string, age int) STORED AS ORC CREATE TABLE people (name string, age int) USING HIVE OPTIONS (fileFormat 'ORC', orc.compress 'gzip')
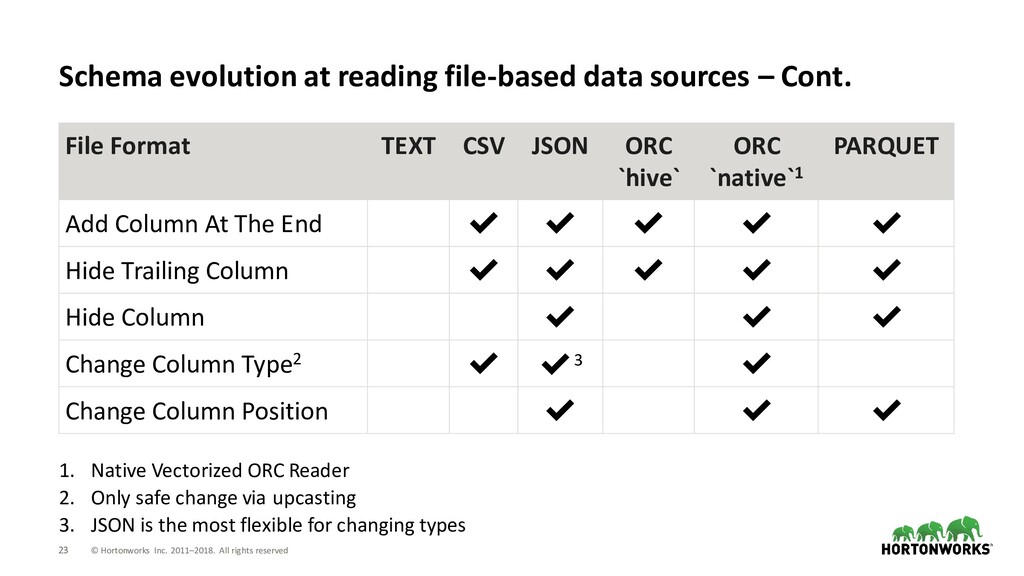
at reading file-based data sources • Frequently, new files can have wider column types or new columns − Before SPARK-21929, users drop and recreate ORC table with an updated schema. • User-defined schema reduces schema inference cost and handles upcasting − boolean -> byte -> short -> int -> long − float -> double spark.read.schema("col1 int").orc(path) spark.read.schema("col1 long, col2 long").orc(path) Old Data New Data
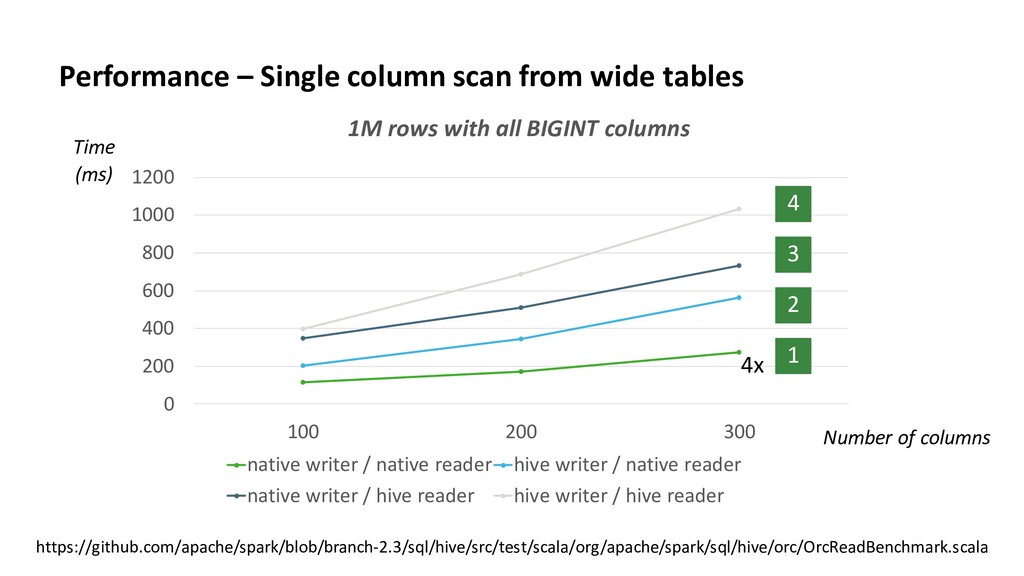
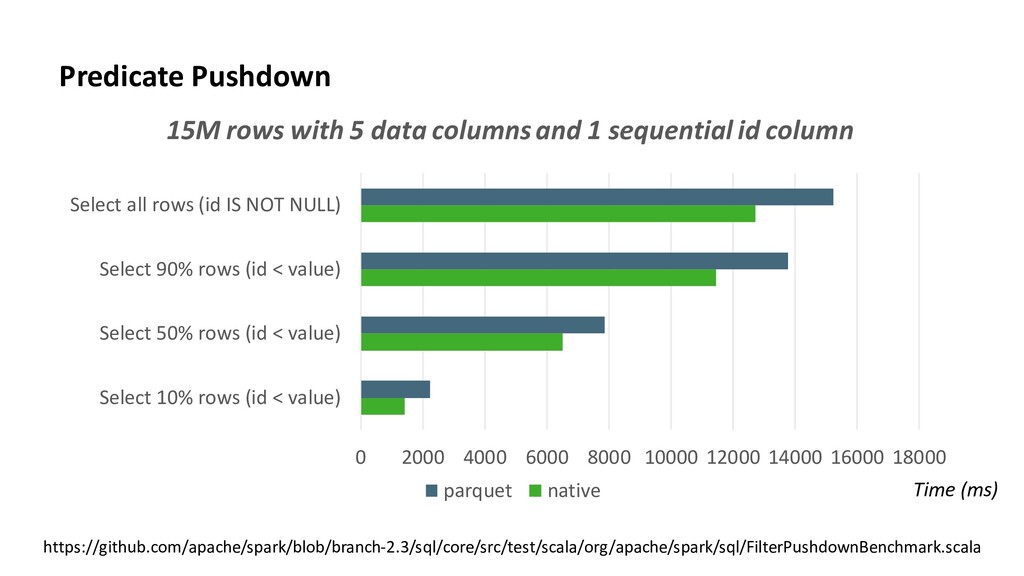
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 Select 10% rows (id < value) Select 50% rows (id < value) Select 90% rows (id < value) Select all rows (id IS NOT NULL) parquet native Time (ms) https://github.com/apache/spark/blob/branch-2.3/sql/core/src/test/scala/org/apache/spark/sql/FilterPushdownBenchmark.scala 15M rows with 5 data columns and 1 sequential id column
– Targeting Apache Spark 2.4 (2018 Fall) Umbrella Issue • Feature Parity for ORC with Parquet SPARK-20901 Sub issues • Upgrade Apache ORC to 1.5.1 SPARK-24576 • Use `native` ORC implementation by default SPARK-23456 • Use ORC predicate pushdown by default SPARK-21783 • Use `convertMetastoreOrc` by default SPARK-22279 • Support table properties with `convertMetastoreOrc/Parquet` SPARK-23355 • Test ORC as default data source format SPARK-23553 • Test and support Bloom Filters SPARK-12417
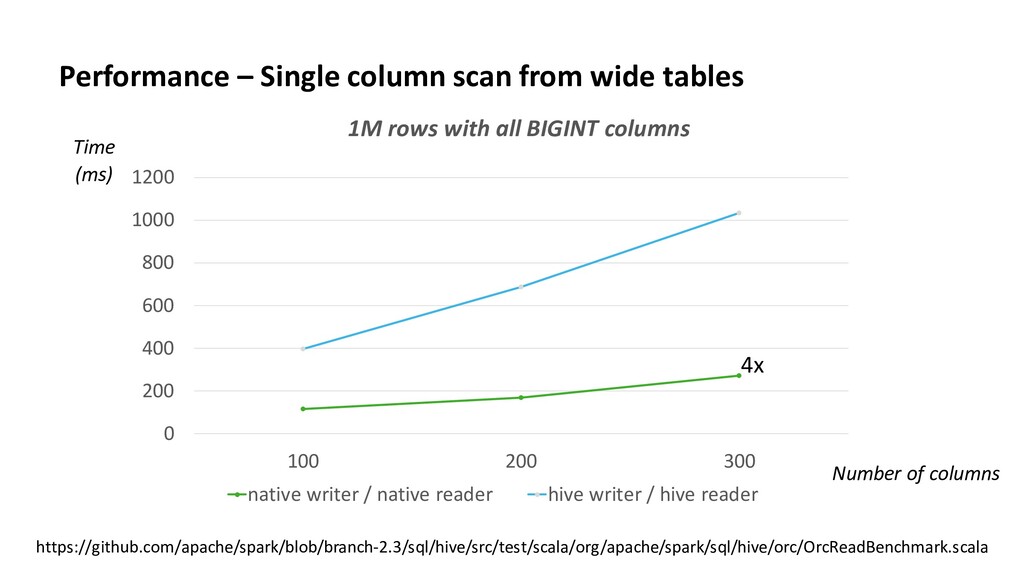
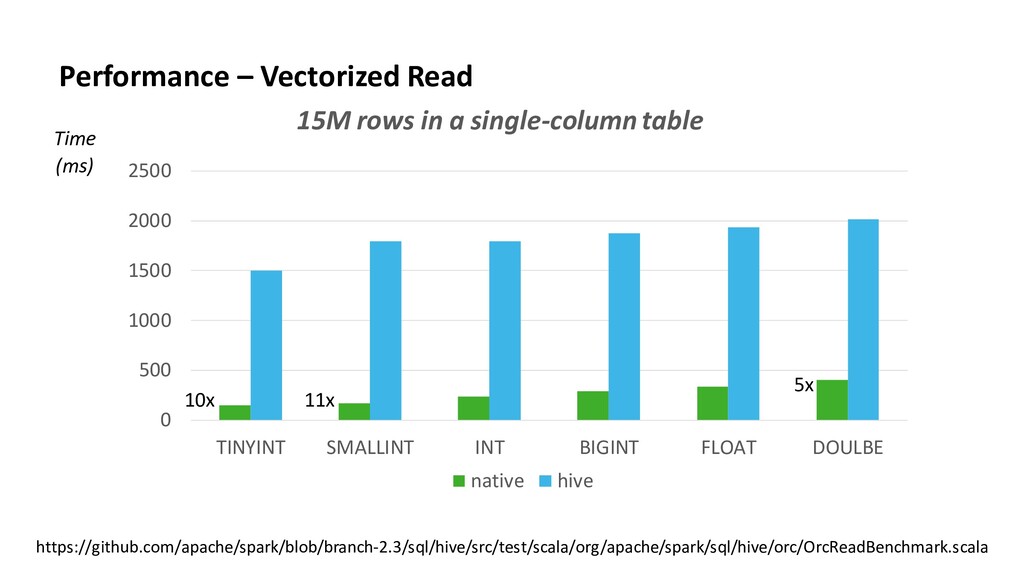
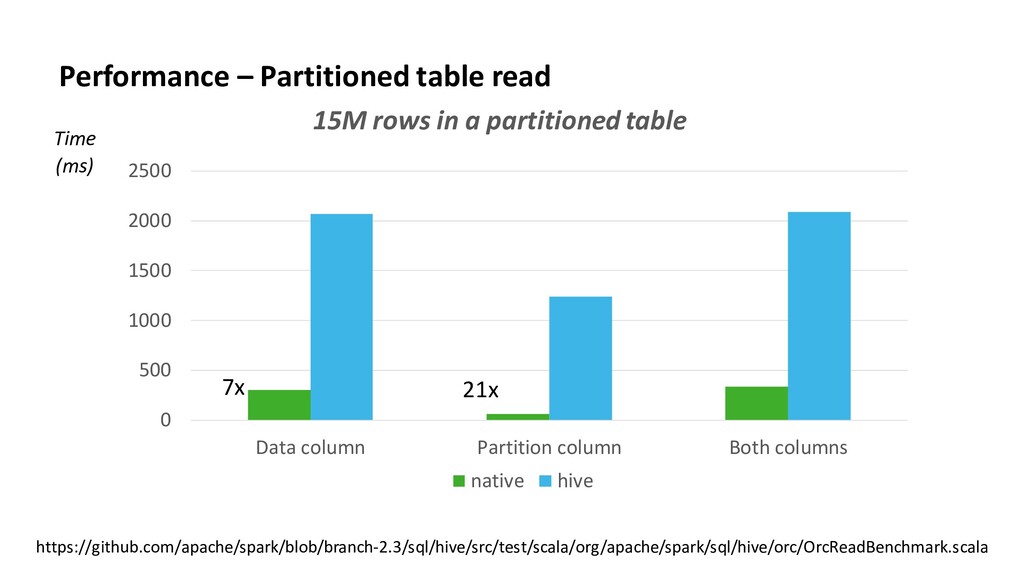
Like Hive, Apache Spark 2.3 starts to take advantage of Apache ORC − Improved feature parity between Spark and Hive • Native vectorized ORC reader − boosts Spark ORC performance − provides better schema evolution ability • Structured streaming starts to work with ORC (both reader/writer) • Spark is going to become faster and faster with ORC
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}