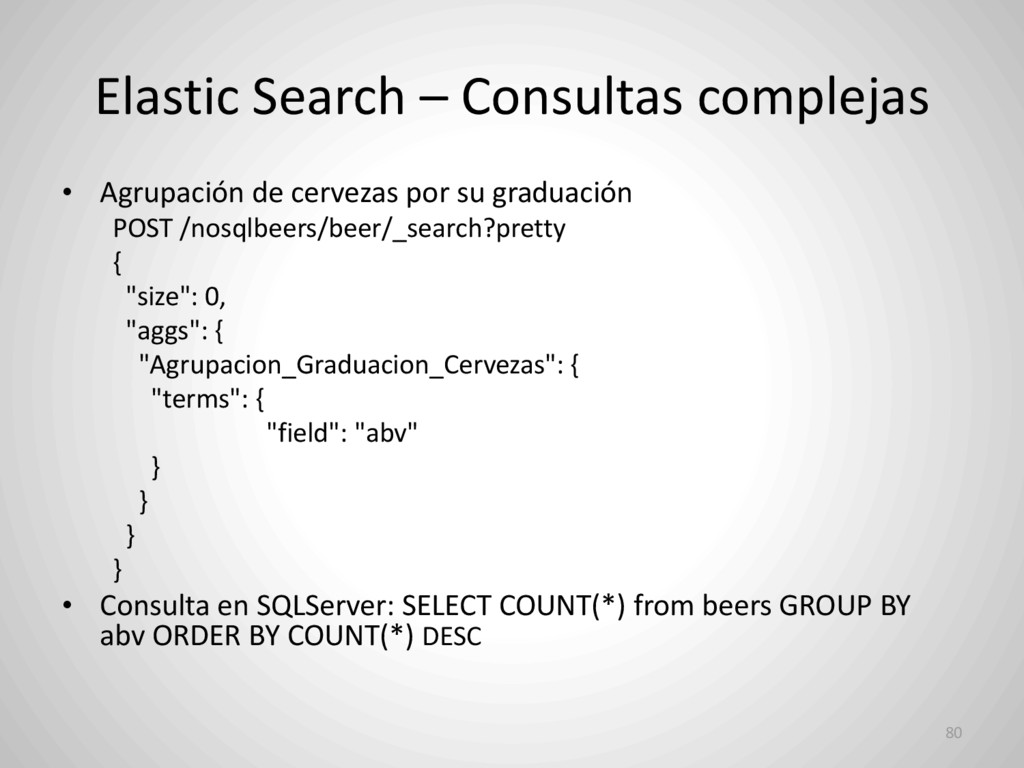
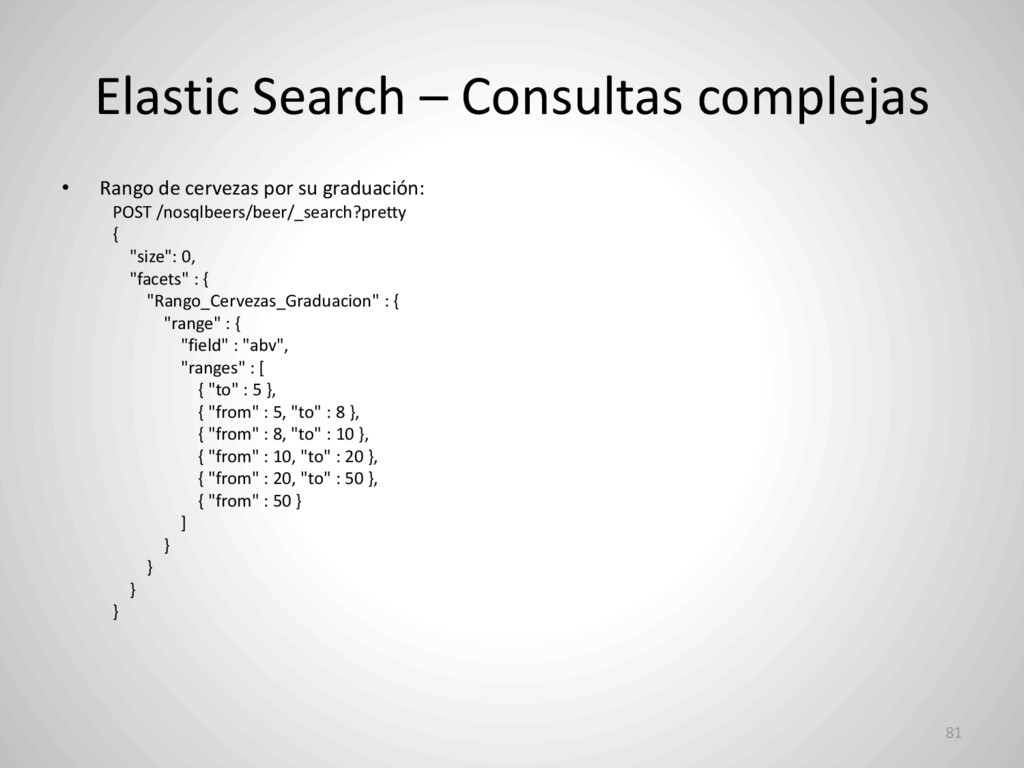
su graduación: POST /nosqlbeers/beer/_search?pretty { "size": 0, "facets" : { "Rango_Cervezas_Graduacion" : { "range" : { "field" : "abv", "ranges" : [ { "to" : 5 }, { "from" : 5, "to" : 8 }, { "from" : 8, "to" : 10 }, { "from" : 10, "to" : 20 }, { "from" : 20, "to" : 50 }, { "from" : 50 } ] } } } } 81
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
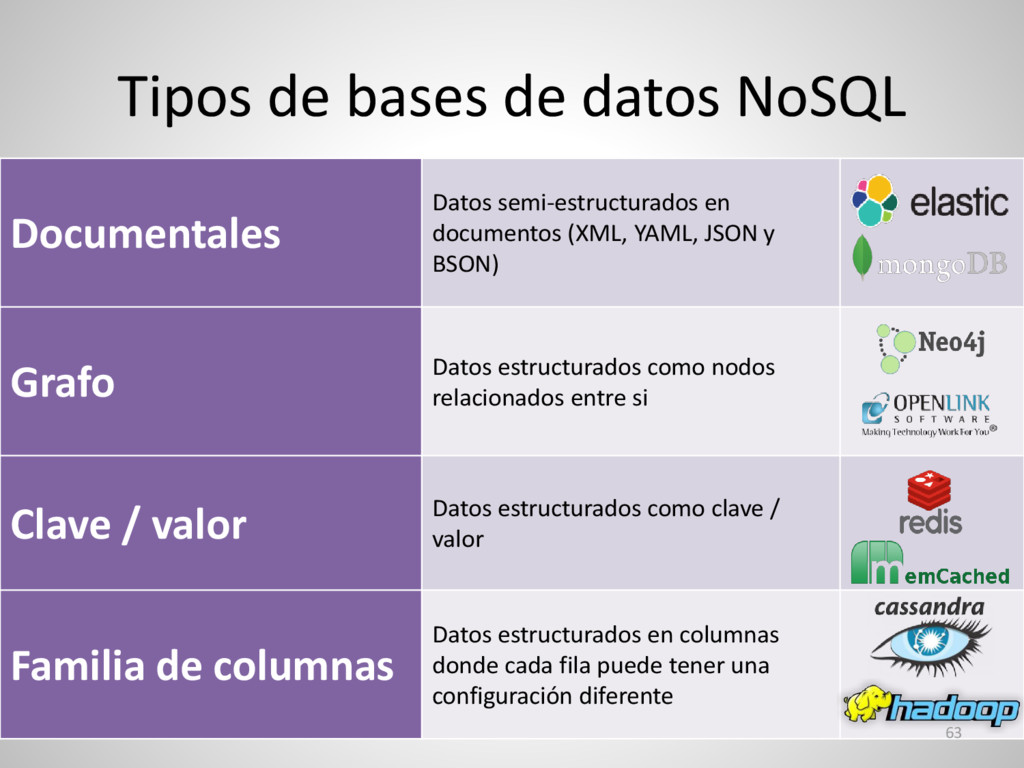{kind=link}
{kind=link}
{kind=link}
{kind=link}
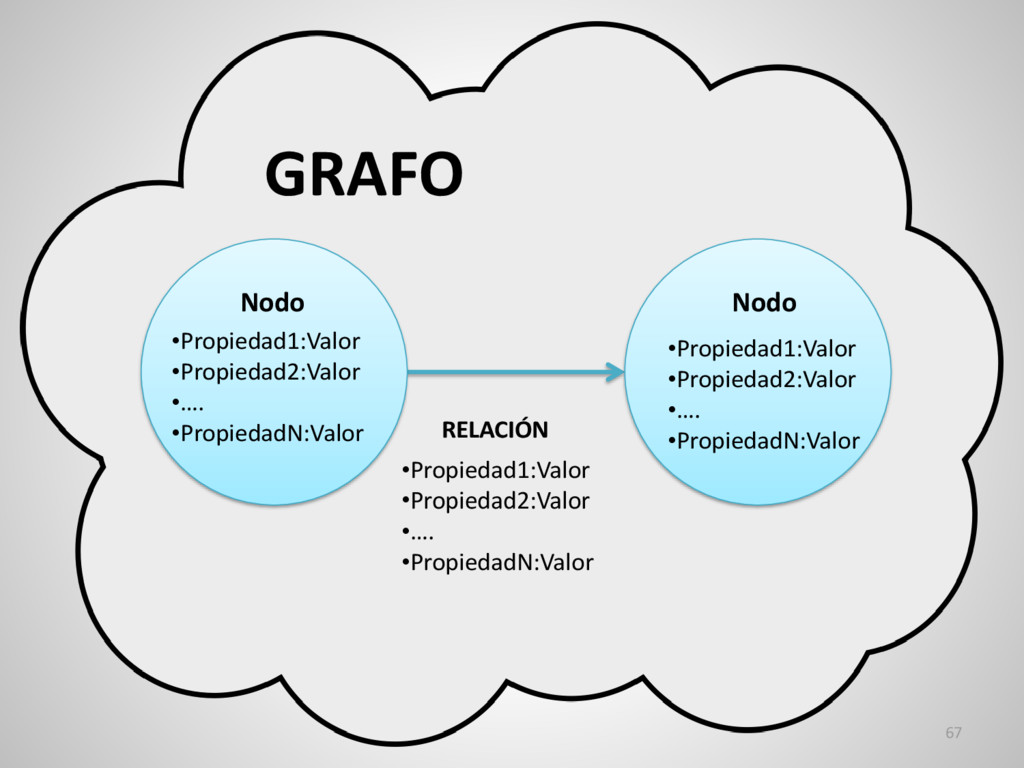{kind=link}
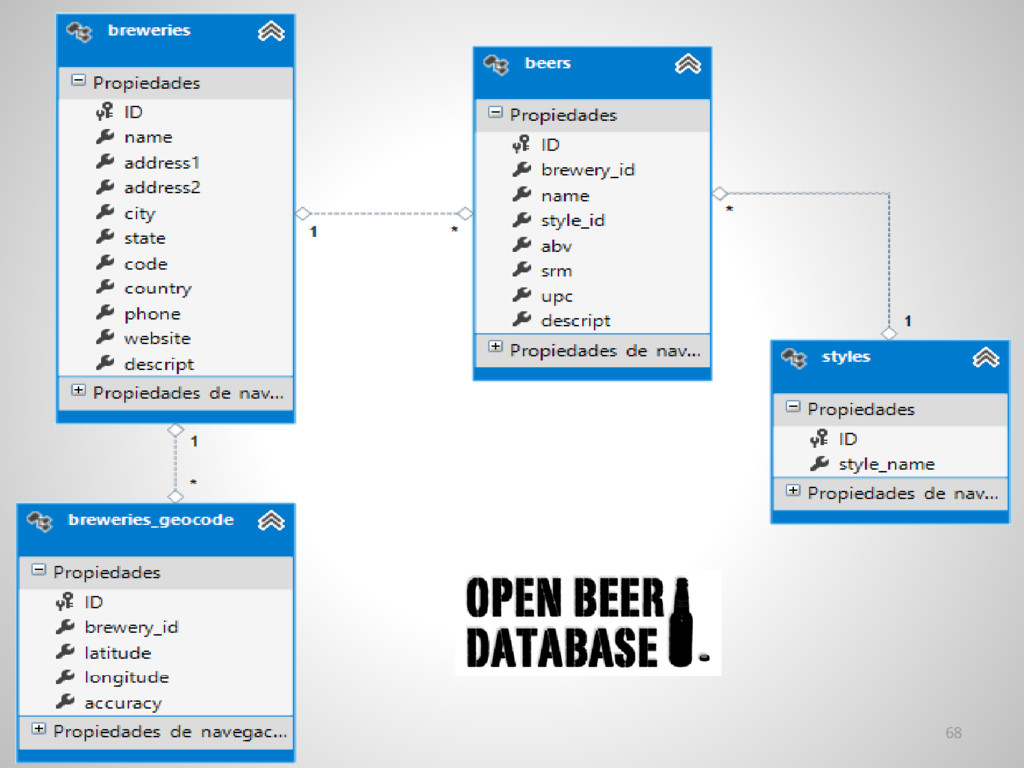{kind=link}
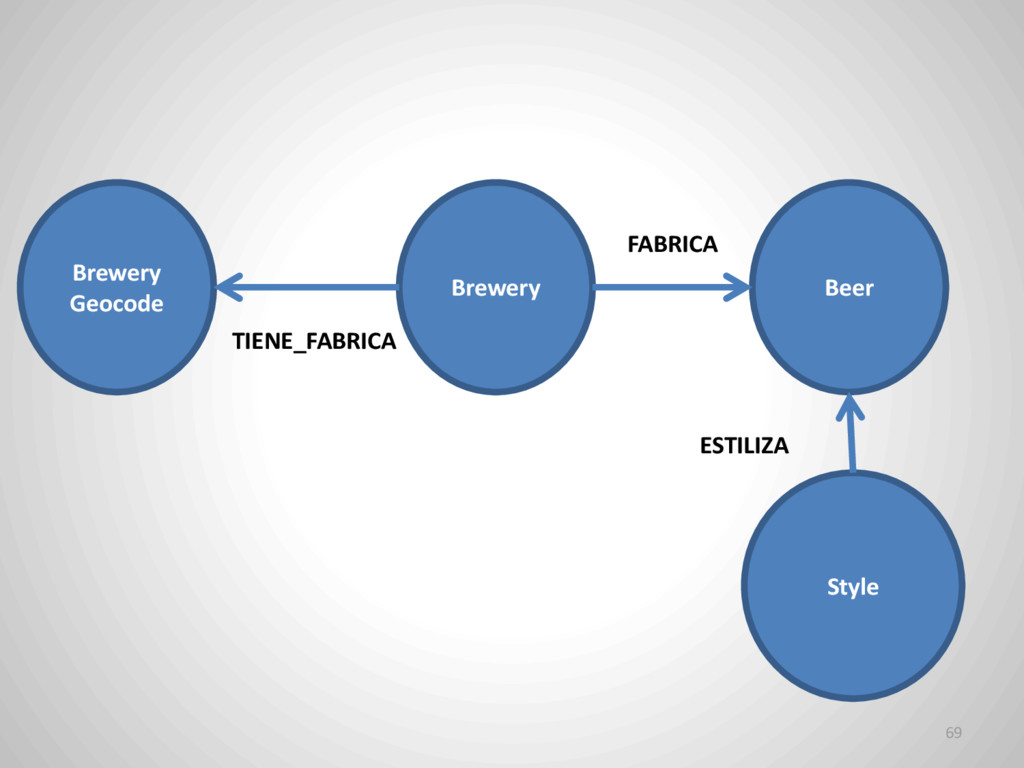{kind=link}
{kind=link}
{kind=link}
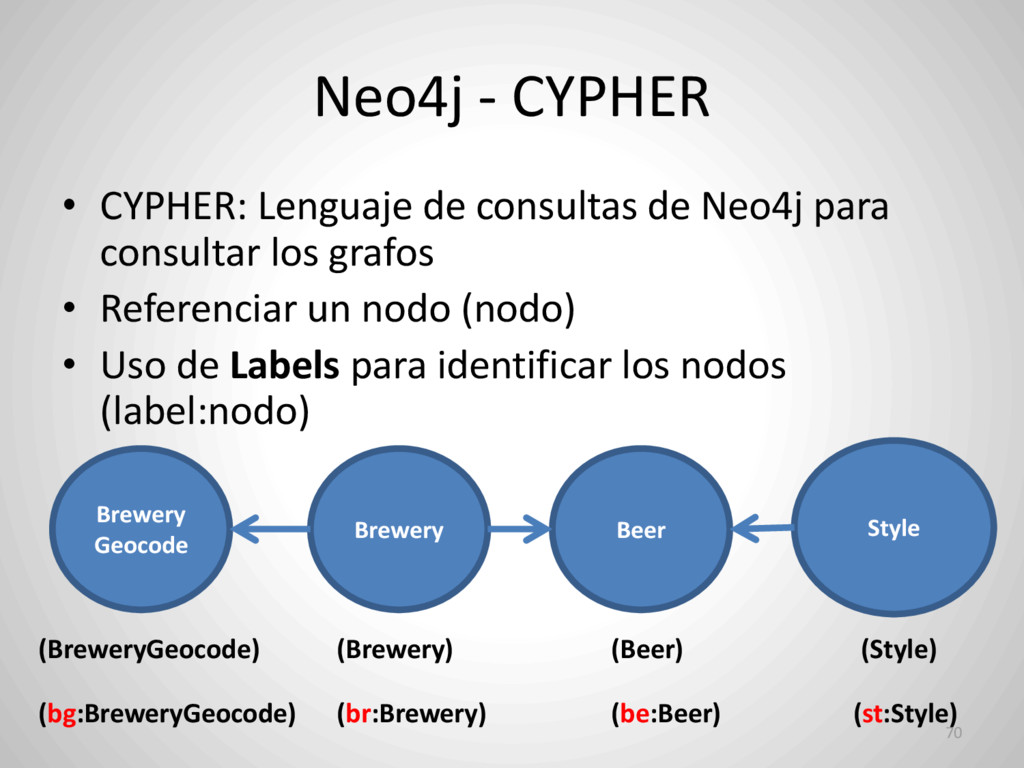
![Neo4j - CYPHER 72 (Brewery) –[: FABRICA]-> (Beer) (cerveceria:Brewery) -[relacion:](https://files.speakerdeck.com/presentations/42d1a41b15a44b38b23f6576d817ee15/slide_68.jpg){kind=link}
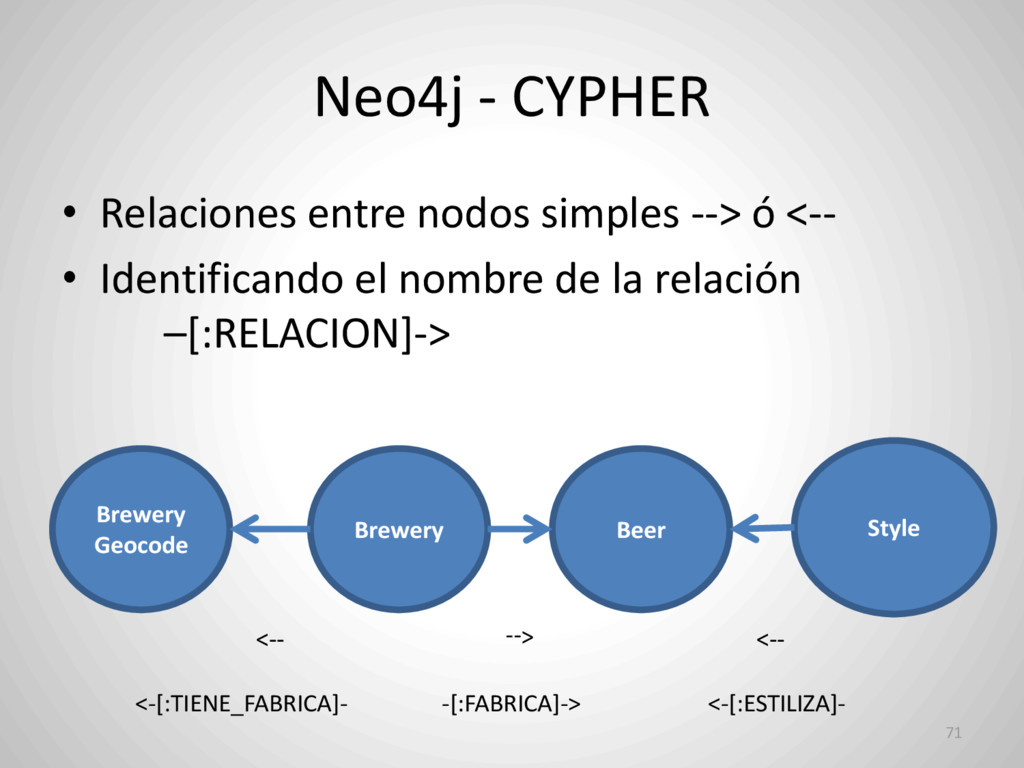
![Neo4j - CYPHER MATCH (style:Style) --> (beer:Beer) <-[:FABRICA]- (brewery:Brewery) -](https://files.speakerdeck.com/presentations/42d1a41b15a44b38b23f6576d817ee15/slide_69.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}