Video: https://vimeo.com/130554527
What would happen to your system if one of your app servers died right now? What about your database server? What if they're just slow? Does your application handle it gracefully? Does your development team get paged? Are you sure?
Netflix famously uses their Simian Army to test these scenarios in production, but setting up that automation might be far down the priority list of a growing startup.
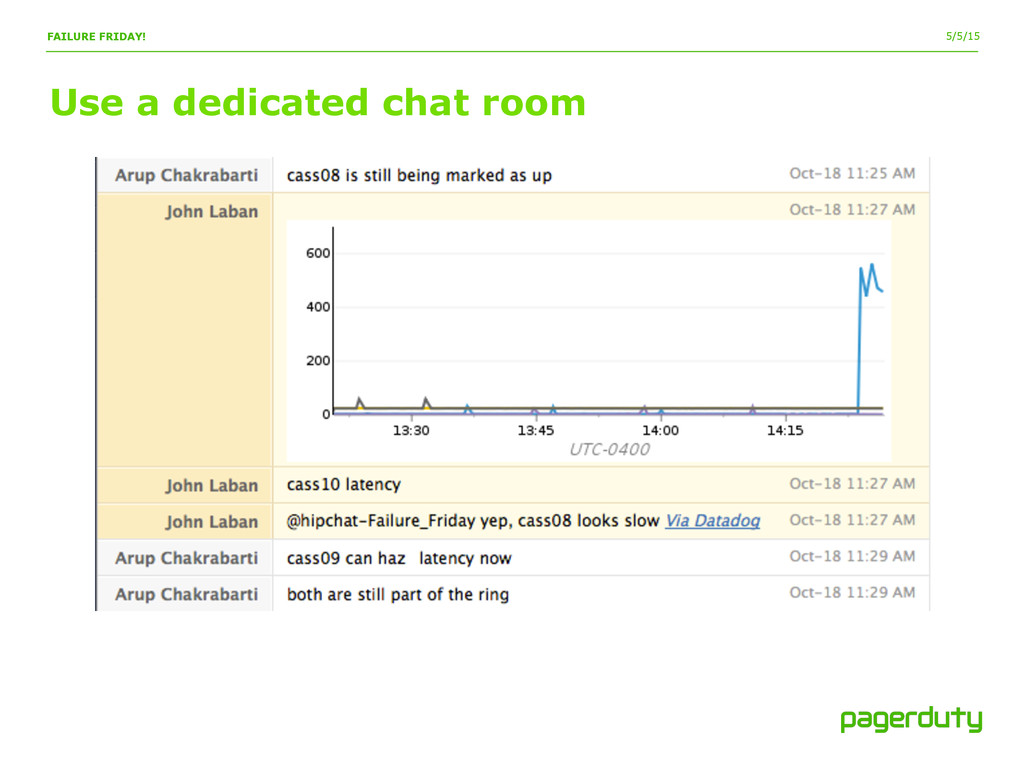
In this talk, we will discuss how PagerDuty started injecting failure into our production systems with minimal effort and the full support of the development teams. We will discuss why you should start proactively injecting failure and the exact steps you can take. We will go over the importance of setting an agenda, keeping a log of the actions taken, and todos that were uncovered. We will talk about why I think your metrics should be linkable, and why you should leave your alerts on during these planned failures. Finally, we will talk about the benefits your company will get from causing all this chaos. At the end of this talk, I hope to have inspired you to go start breaking your production systems, on purpose.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5/5/15 FAILURE FRIDAY! [email protected] PAGERDUTY.COM/JOBS](https://files.speakerdeck.com/presentations/0043ba0079a84ad189b202121bb66bc3/slide_32.jpg){kind=link}
{kind=link}