Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「言語処理のための機械学習入門」#2
Search
DSnomura
December 11, 2016
Technology
270
0
Share
「言語処理のための機械学習入門」#2
言語処理のための機械学習入門 (自然言語処理シリーズ)
http://amzn.to/2f79qd9
の輪読会資料(第3章)です
DSnomura
December 11, 2016
Other Decks in Technology
See All in Technology
FASTでAIエージェントを作りまくろう!
yukiogawa
4
190
Oracle AI Database@Google Cloud:サービス概要のご紹介
oracle4engineer
PRO
5
1.3k
出版記念イベントin大阪「書籍紹介&私がよく使うMCPサーバー3選と社内で安全に活用する方法」
kintotechdev
0
140
サイボウズ 開発本部採用ピッチ / Cybozu Engineer Recruit
cybozuinsideout
PRO
10
77k
ハーネスエンジニアリング×AI適応開発
aictokamiya
3
1.4k
Oracle Cloud Infrastructure(OCI):Onboarding Session(はじめてのOCI/Oracle Supportご利⽤ガイド)
oracle4engineer
PRO
2
17k
第26回FA設備技術勉強会 - Claude/Claude_codeでデータ分析 -
happysamurai294
0
360
トイルを超えたCREは何屋になるのか
bengo4com
0
120
Databricks Lakehouse Federationで 運用負荷ゼロのデータ連携
nek0128
0
110
I ran an automated simulation of fake news spread using OpenClaw.
zzzzico
1
800
契約書からの情報抽出を行うLLMのスループットを、バッチ処理を用いて最大40%改善した話
sansantech
PRO
3
350
Oracle AI Database@AWS:サービス概要のご紹介
oracle4engineer
PRO
3
2.1k
Featured
See All Featured
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
880
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
250
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
780
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
0
260
Docker and Python
trallard
47
3.8k
Optimising Largest Contentful Paint
csswizardry
37
3.6k
Raft: Consensus for Rubyists
vanstee
141
7.4k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
1.9k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
230
How to Think Like a Performance Engineer
csswizardry
28
2.5k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
400
Design in an AI World
tapps
0
190
Transcript
「言語処理のための機械学習入門」 輪読会 #2 27 PAGES Shintaro Nomura 機 械 学
習 2016.12.11 @ Akiba Code
CAUTION! この資料は、「言語処理のための機械学 習入門(高村大地)」を読みながら作成 していますが、本が簡潔に書かれすぎて いてよく理解していないまま知ったかぶ りで作られている可能性があります。 2
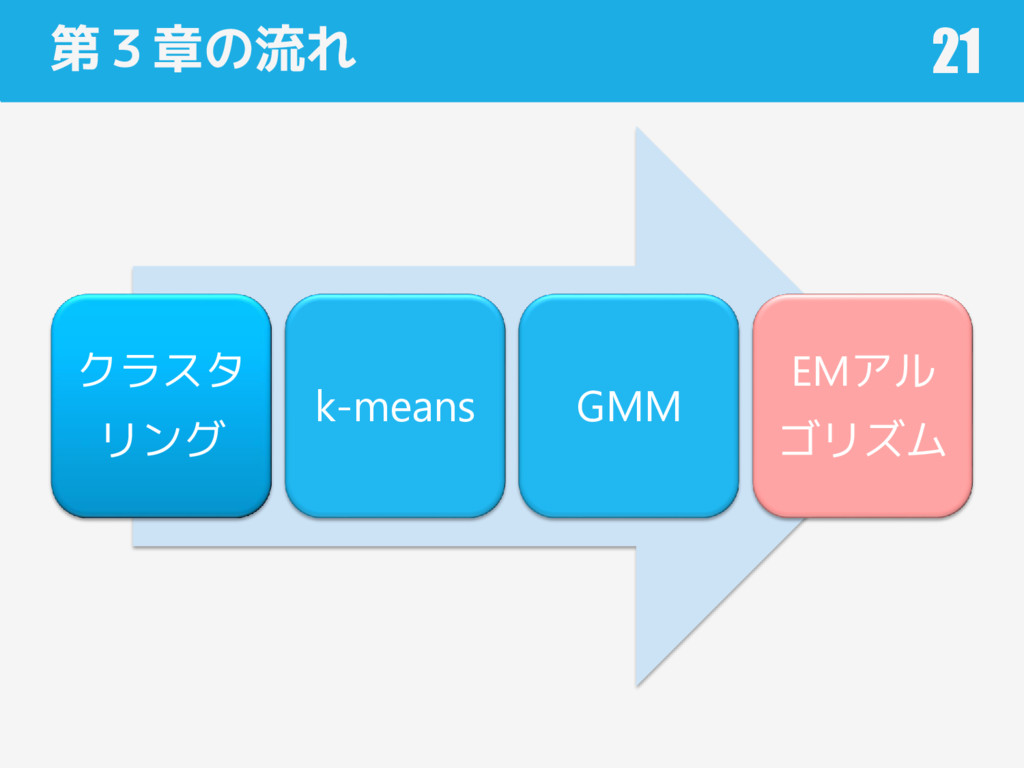
第3章の流れ クラスタ リング k-means GMM EMアル ゴリズム 3
クラスタリング 4 似ているもの(文書や単語)同士を 1つのグループにまとめる作業 データ:D D = { d1, d2,
… , d|D| } データDの ベクトル表現 x(1), x(2), … , x(|D|) ※文書ならbag-of-words表現や、単語なら文脈ベクトルなど sim( A, B ) A、B同士の似ている度合い。類似度(モデルに応じて定義)。 arg max/min 対象の関数値を最大/最小にする引数の集合を返す ex) arg max -(x – 1)2 = 1
凝集(ぎょうしゅう) 性クラスタリング 凝集性クラスタリングの概略 1.事例集合:Dを入力 D = {x(1) , x(2) ,
… , x(|D|) } 2.クラスタをまず|D|個用意し、 各事例x i を所属させる c1 = {x(1) }, c2 = {x(2) }, … c|D| = {x(|D|) } 3.クラスタ数が2個以上存在 する限り、似たクラスタ対を 融合(merge)し続ける (cm ,cn ) = arg max(ci , cj ) merge(cm ,cn ) 2.~3.をクラスタ数が1になるまでLoop 5 テキストではクラスタ同士の類似度(sim)を測る 方法として、単連結法・完全連結法・重心法など 3つの方法が示されている
重心法 6 なかでも一般的なクラスタリングでは、「重心法 (centroid method)」が活用されているのをよく見 る気がします 各クラスタが含む事例すべての「重心 (平均)ベクトル」間の類似度を、それらのクラ
スタの類似度とする方法 sim(ci , cj ) = sim(c i 内の全ベクトルの平均, c j 内の全ベクトルの平均)
第3章の流れ クラスタ リング k-means GMM EMアル ゴリズム 7
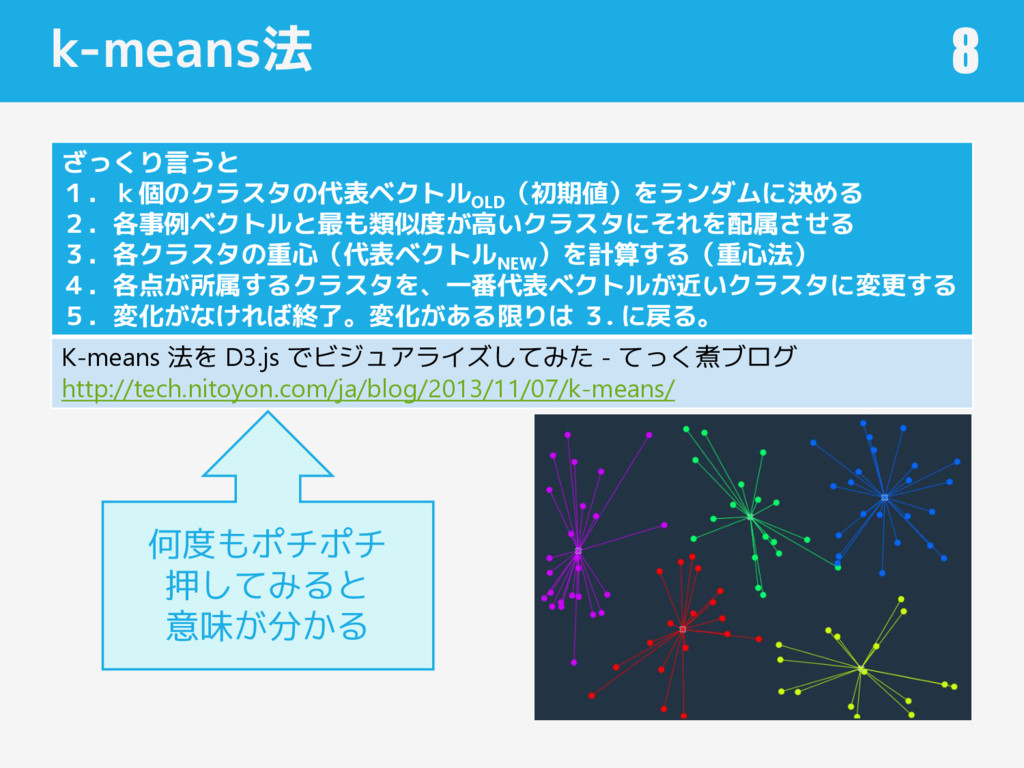
k-means法 8 ざっくり言うと 1.k個のクラスタの代表ベクトル OLD (初期値)をランダムに決める 2.各事例ベクトルと最も類似度が高いクラスタにそれを配属させる 3.各クラスタの重心(代表ベクトル NEW )を計算する(重心法)
4.各点が所属するクラスタを、一番代表ベクトルが近いクラスタに変更する 5.変化がなければ終了。変化がある限りは 3. に戻る。 K-means 法を D3.js でビジュアライズしてみた - てっく煮ブログ http://tech.nitoyon.com/ja/blog/2013/11/07/k-means/ 何度もポチポチ 押してみると 意味が分かる
k-means法の課題 9 ざっくり言うと 1.k個のクラスタの代表ベクトル(初期値)をランダムに決める 2.各事例ベクトルと最も類似度が高いクラスタにそれを配属させる 3.各クラスタの重心を計算する(重心法) 4.各点が所属するクラスタを、一番近い重心のクラスタに変更する 5.変化がなければ終了。変化がある限りは 3. に戻る。
初期値(最初の割当て)次第で 結果が変化する (対策) 凝集性クラスタリングの 結果を初期値とする ランダム配置を何度も繰り返して 平均的な結果を用いる 「k」はあなたが決める 【悲報】 kの数次第でアルゴリズムの挙動が全 く変わってしまう
第3章の流れ クラスタ リング k-means GMM EMアル ゴリズム 10
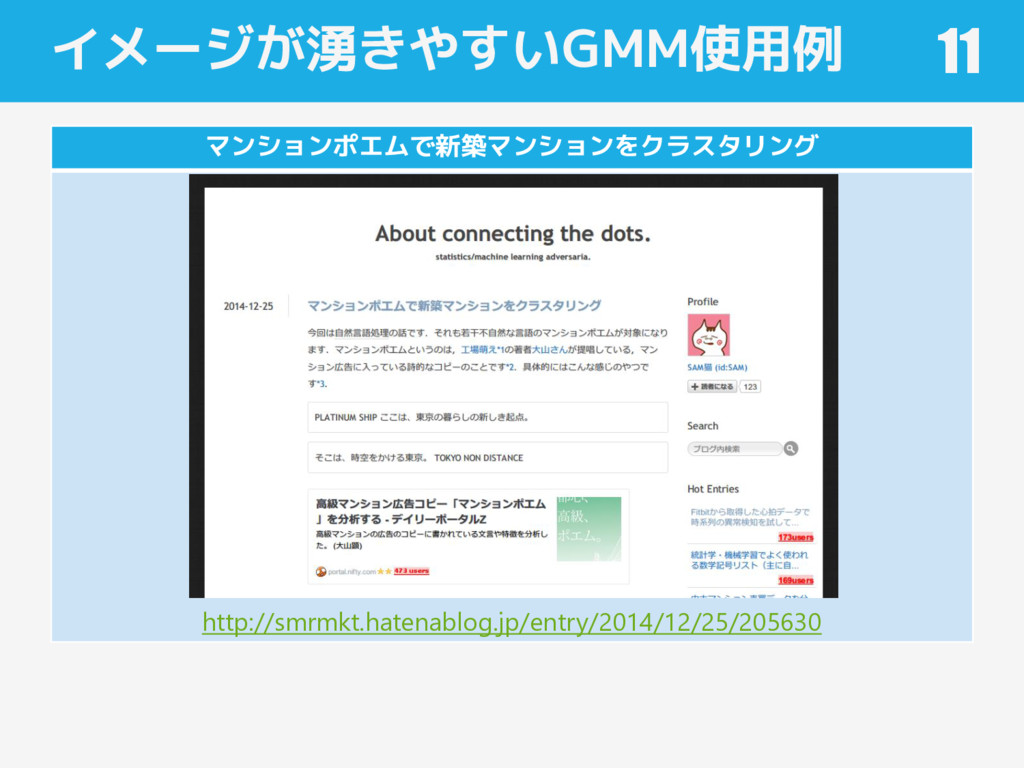
イメージが湧きやすいGMM使用例 マンションポエムで新築マンションをク 11 マンションポエムで新築マンションをクラスタリング http://smrmkt.hatenablog.jp/entry/2014/12/25/205630
マンションポエムのクラスタリング データの収集 Linkにあったので助かったそうです 辞書の作成 普通に形態素解析しちゃうと単語を刻み すぎるため、オリジナルの辞書を作成 形態素解析 MeCabを使って,ざっくりと形態素解析. 必要な品詞だけPythonで抽出. ストップワードの除去
GitHub参照 LDAによるトピックモデル作成 gensimパッケージを利用し、各文書間に 共通する、潜在的なトピックを抜き出す →1,700単語(1x1,700のベクトル)を20 個程度のトピック(1x20のベクトル)に 集約(次元縮約) GMMによるクラスタリング その20次元ベクトルを用いてクラスタリ ング。いくつか試したところ、クラスタ 数を4つにすると感じが良いことが判明 ワードクラウドを作成して可視化 次項参照 12
マンションポエム(2) 13 クラスタごとのワードクラウド(Tagxedo)による可視化 平均坪単価が高く,都心からの 距離が近いクラスタ 都心から距離が遠いクラスタ 坪単価が安いクラスタ バランスの良いクラスタ
GMMの理解に必要な統計知識 結合確率と条件付き確率(p.26) 独立性(p.29) (多変量)正規分布(p.38) 14
同時確率と条件付き確率 同時確率 コインXとダイスYがあるとき、Xがオモテとなり、かつ、Yが4となる(同 時)確率 P( X = “Heads”, Y =
4 ) = 1/2 ✕ 1/6 = 1 /12 15 条件付き確率 コインXとダイスYがある。Xがオモテとなったとき、Yが4となる(条件付 き)確率 P( Y = 4 | X = "Heads" ) = 1/6 この場合、コインの表裏とダイスの出目には何の関連もないと考えられる →それらは「独立事象」であると呼ばれる P( Y = 4 | X = “Heads” ) = P( Y = 4 ) # 条件なし確率と同じ値に
尤度(ゆうど) 尤度を表現する式と、同時確率を表現する式は、同じ形をしている 各データ(事例ベクトル、標本)がそれぞれ互いに独立であるとき、 尤度 L = P(x1 ) P(x2 )…P(xn
) . ・同時確率はあくまでも事象が起きる確率であるのに対し、尤度は「観察デー タの下での仮説の尤(もっと)もらしさ」の指標である ※「いぬど」と読むと尤度警察がやってきます (尤度は観測データはすべて出尽くしていて、それらのデータに対して、あるパラメー タの確率分布を当てはめた時、どれだけ尤もらしいかを意味している) ・実際の観測データを仮説上の確率分布に当てはめた際、あてはまりが悪いと 尤度は低く計算されてしまう →尤度を最大にするパラメータを求める(推定する)方法が最尤推定法 16
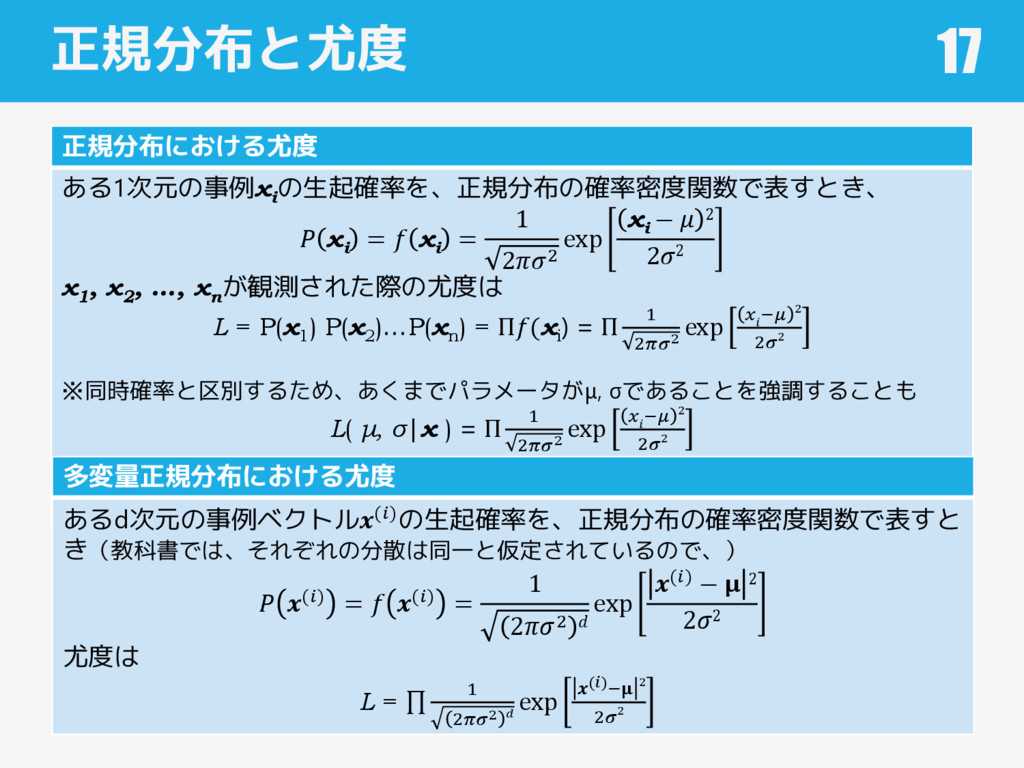
正規分布と尤度 正規分布における尤度 ある1次元の事例xi の生起確率を、正規分布の確率密度関数で表すとき、 xi = xi = 1 22
exp xi − 2 22 x1 , x2 , …, xn が観測された際の尤度は L = P(x1 ) P(x2 )…P(xn ) = Π(xi ) = Π 1 22 exp − 2 22 ※同時確率と区別するため、あくまでパラメータがμ, σであることを強調することも L( μ, σ|x ) = Π 1 22 exp − 2 22 17 多変量正規分布における尤度 あるd次元の事例ベクトル()の生起確率を、正規分布の確率密度関数で表すと き(教科書では、それぞれの分散は同一と仮定されているので、) () = () = 1 22 exp () − 2 22 尤度は L = 1 22 exp ()− 2 22
正規分布と対数尤度 18 多変量正規分布における尤度 尤度は(教科書では、それぞれの分散は同一と仮定されているので、) () = () = 1 22
exp () − 2 22 尤度は L = 1 22 exp ()− 2 22 積のカタチで表されている尤度は扱いにくいため、「対数尤度」が用いられる ことが多い。 対数尤度は logL =log 1 22 exp − 2 22 = log 1 22 exp ()− 2 22
k-means法(重心法)とGMMの違い テキストの表現が入門者に優しくない P(c) という概念(隠れ変数) が抽象的なため、理解がなかなか難しい 19 混合正規分布(Gaussian Mixture)によるクラスタリング ざっくり言わないと
1.k個のクラスタの代表ベクトルm’(初期値)をランダムに決める 2.各事例ベクトルxが、どのクラスタに、各々どの程度の確率で属 するか(P( c | x(i); mOLD )を、P( x | c )が正規分布に従うと仮定して 計算する(GMM) 3.各クラスタの代表ベクトルを単純な重心ではなく、先ほど計算さ れた確率の重み付きで計算し、m NEW へ置き換える 4.代表ベクトルの変化が十分小さければ終了。大きい限りは 2. に 戻る。
その意味を説明しようと思うけど GMMは次章の「EMアルゴリズム」の一例に すぎないので、仕組みは次で説明します 20
第3章の流れ クラスタ リング k-means GMM EMアル ゴリズム 21
EMアルゴリズム EMアルゴリズムは2つのステップからなる E(xpectation: 期待値)ステップ 対数尤度をその期待値で置き換えるステップ M(aximization: 最大化)ステップ その値を最大にするように未知のパラメータ を推定するステップ 22
一見、ただの最尤推定っぽいけど ・EMアルゴリズムは、不完全データにも使える ・不完全データとは、本来は観測されるべきだが観測できな かったデータ(欠損データ)を含むデータ ・欠損データを含むと、本来、尤度がパラメータθの関数として 定義できない ・対数尤度をその期待値で置き換えた関数「Q関数」の最大化を 通じてパラメータの最尤推定(的なもの?)を行う
P(C)を「隠れ変数」として扱う 今回は、各クラスタが含む事例の数(確率:P(c))が不明である そのようなクラスタに対応する確率変数を「隠れ変数」として扱い、 EMアルゴリズムの枠組みに基づいてパラメータ推定が可能になる 23 事例ベクトル 事例ベクトル 事例ベクトル
クラスタ1 クラスタ2 何個属すの? ?
EMアルゴリズムの利点・特徴 24 不完全データからの最尤推定が可能 (実際には、欠損データに関する周辺化を行って、観測データのみの周辺分布による最 尤推定を行っている:周辺分布密度関数に観測データを代入した尤度を最大にする) (対数)尤度を最大にする解を直接的に計算するのは 困難だが、Mステップで求めたパラメータθNEW をEス
テップ(Q関数)のθOLD に代入して…とEMステップを 繰り返すごとで、(対数)尤度が単調に増加すること が知られている ※この場合の単調増加は、「不変または増加」の意味。なので、変化率が一定程度 収束しても、真の意味では極大値を求めたにすぎないことも十分にあり得る
前ページの理論的背景が知りたい方は ・「確率的言語モデル」 北研二 See 2.6「EMアルゴリズム」 ・「これなら分かる最適化数学―基礎 原理から計算手法まで」金谷健一 See 5.4 「不完全データからの最尤推
定」 25
じゃあQ関数ってどう定義されてるの Q(θNEW ; θOLD )=∑ ∑ P(c , x(i); θOLD
) * log P( c, x(i); θNEW ) ※連続的な場合にはQ(θNEW ; θOLD )=∬P(c , x(i); θOLD ) * log P( c, x(i); θNEW ) →「はじめての 統計データ分析 ―ベイズ的〈ポストp値時代〉の統計学―」 (豊田秀樹)を読んだ方だと、左辺が事後分布、右辺が事前分布×尤度に対応 してそうなことが想起されそう •確認事項 ・f( ・ ; θ ) の右側のθがその関数のパラメータであることを明示 ・Q関数をθNEW について解く上では、θOLD は定数である 26 θOLD とθNEW の更新を繰り返し、パラメータθの 変化率が一定を下回ったら、最後のθNEW をパラ メータ値として採用 →そのθ値に基いてクラスタリングを行う (今回の場合、求めたθは代表ベクトルmC )
それでもこの課題からは逃れられない 27 初期値(最初の割当て)次第で 結果が変化する (対策) 凝集性クラスタリングの 結果を初期値とする ランダム配置を何度も繰り返して 平均的な結果を用いる クラスタ数「k」はあなたが決める
【悲報】 kの数次第でアルゴリズムの挙動が全 く変わってしまう
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}