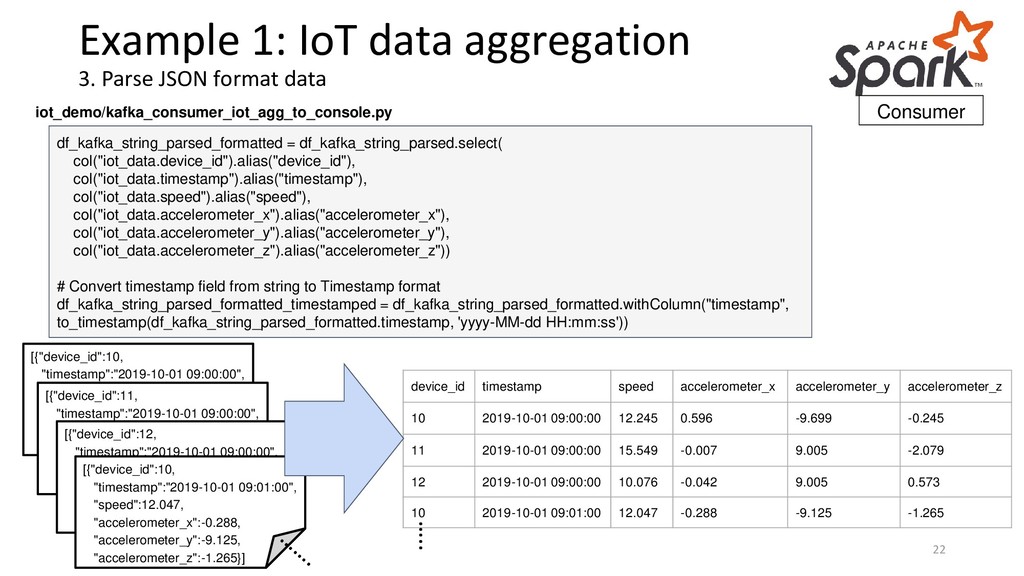
22 df_kafka_string_parsed_formatted = df_kafka_string_parsed.select( col("iot_data.device_id").alias("device_id"), col("iot_data.timestamp").alias("timestamp"), col("iot_data.speed").alias("speed"), col("iot_data.accelerometer_x").alias("accelerometer_x"), col("iot_data.accelerometer_y").alias("accelerometer_y"), col("iot_data.accelerometer_z").alias("accelerometer_z")) # Convert timestamp field from string to Timestamp format df_kafka_string_parsed_formatted_timestamped = df_kafka_string_parsed_formatted.withColumn("timestamp", to_timestamp(df_kafka_string_parsed_formatted.timestamp, 'yyyy-MM-dd HH:mm:ss')) [{"device_id":10, "timestamp":"2019-10-01 09:00:00", "speed":12.245, "accelerometer_x":0.596, "accelerometer_y":-9.699, "accelerometer_z":-0.245}] [{"device_id":11, "timestamp":"2019-10-01 09:00:00", "speed":15.549, "accelerometer_x":-0.007, "accelerometer_y":9.005, "accelerometer_z":-2.079}] device_id timestamp speed accelerometer_x accelerometer_y accelerometer_z 10 2019-10-01 09:00:00 12.245 0.596 -9.699 -0.245 11 2019-10-01 09:00:00 15.549 -0.007 9.005 -2.079 12 2019-10-01 09:00:00 10.076 -0.042 9.005 0.573 10 2019-10-01 09:01:00 12.047 -0.288 -9.125 -1.265 [{"device_id":12, "timestamp":"2019-10-01 09:00:00", "speed":10.076”, "accelerometer_x":-0.042, "accelerometer_y":9.005, "accelerometer_z":0.573}] [{"device_id":10, "timestamp":"2019-10-01 09:01:00", "speed":12.047, "accelerometer_x":-0.288, "accelerometer_y":-9.125, "accelerometer_z":-1.265}] iot_demo/kafka_consumer_iot_agg_to_console.py Consumer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
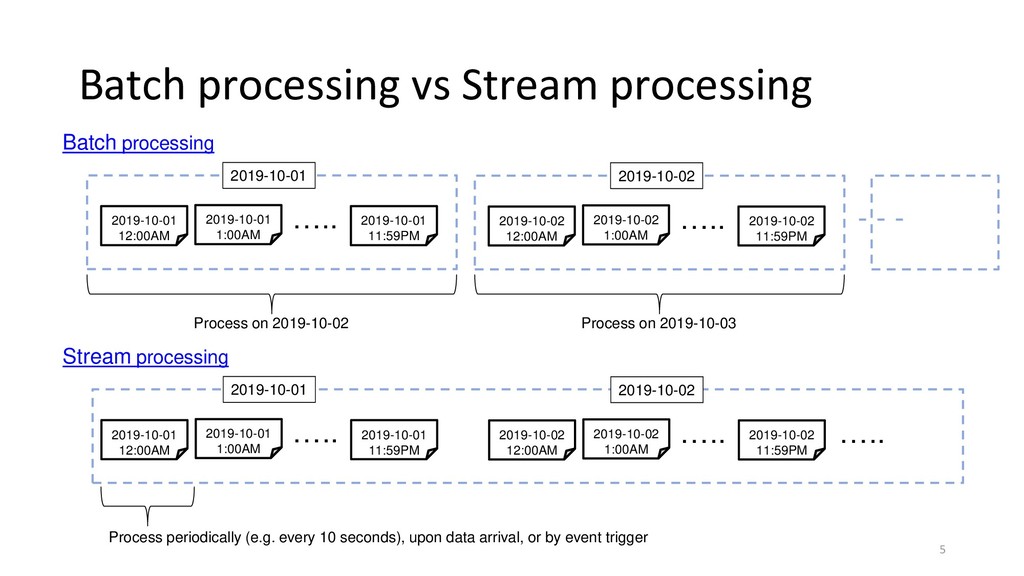{kind=link}
{kind=link}
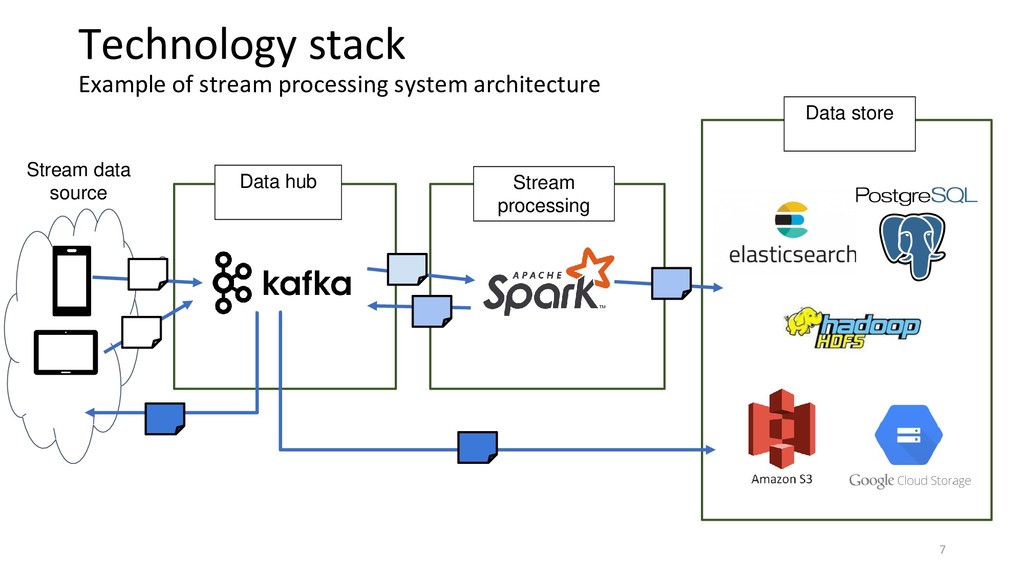{kind=link}
{kind=link}
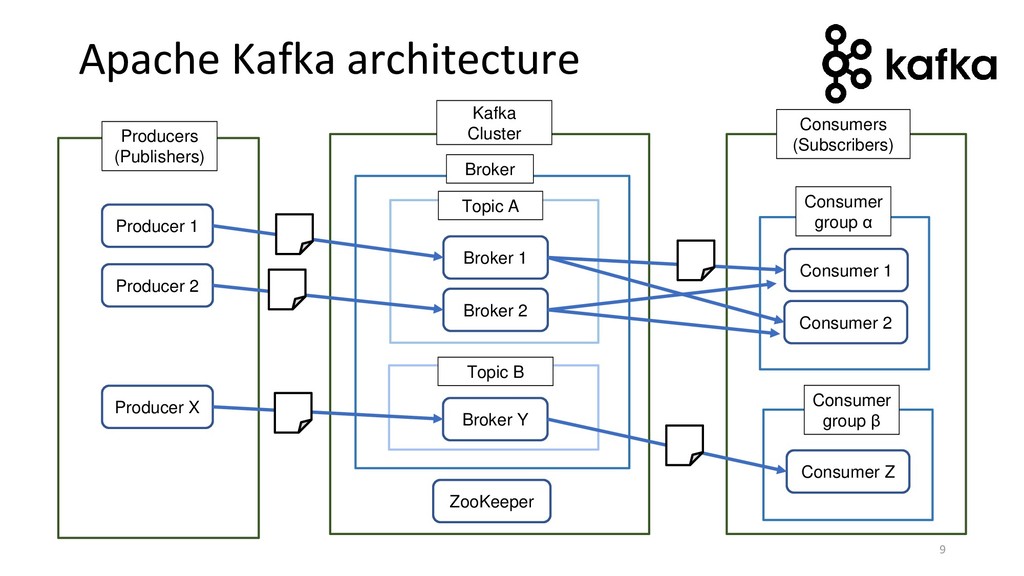{kind=link}
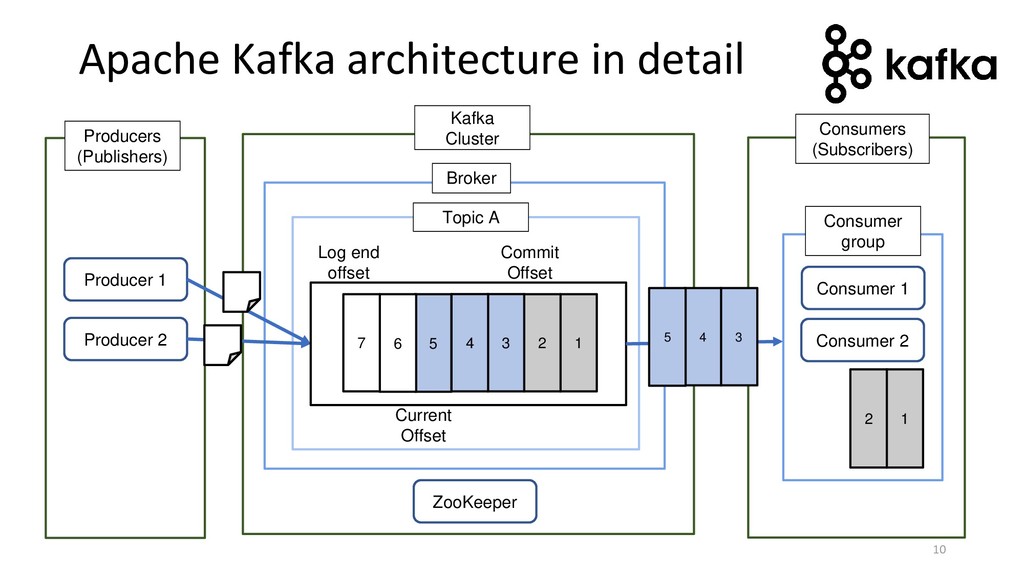{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}