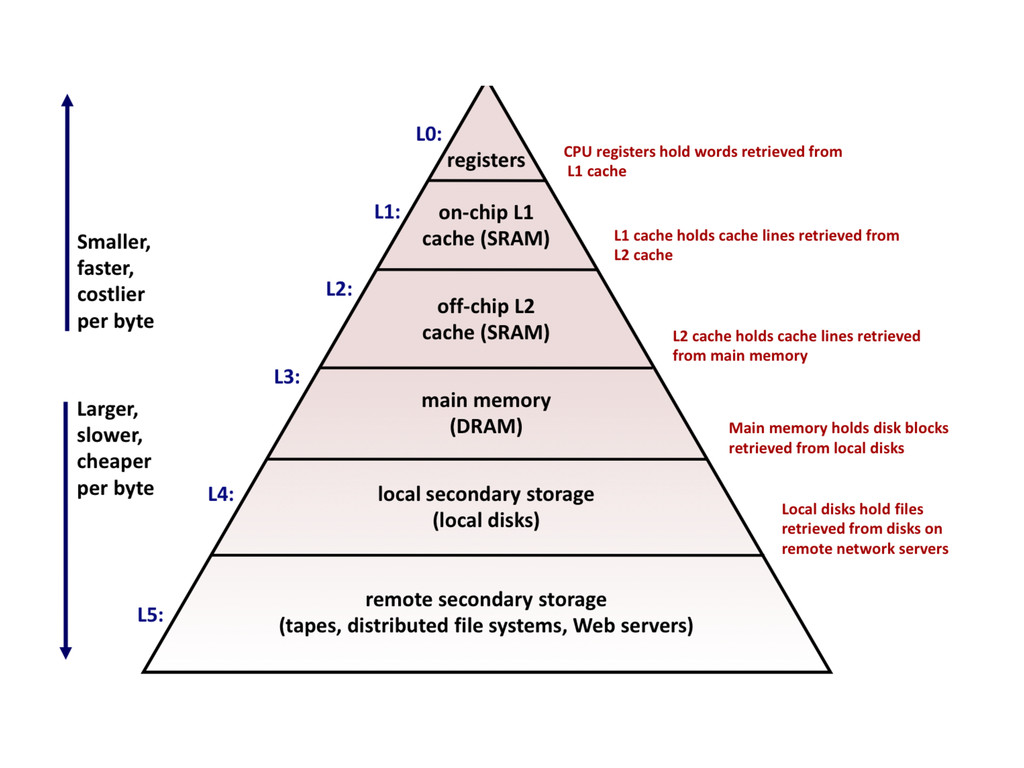
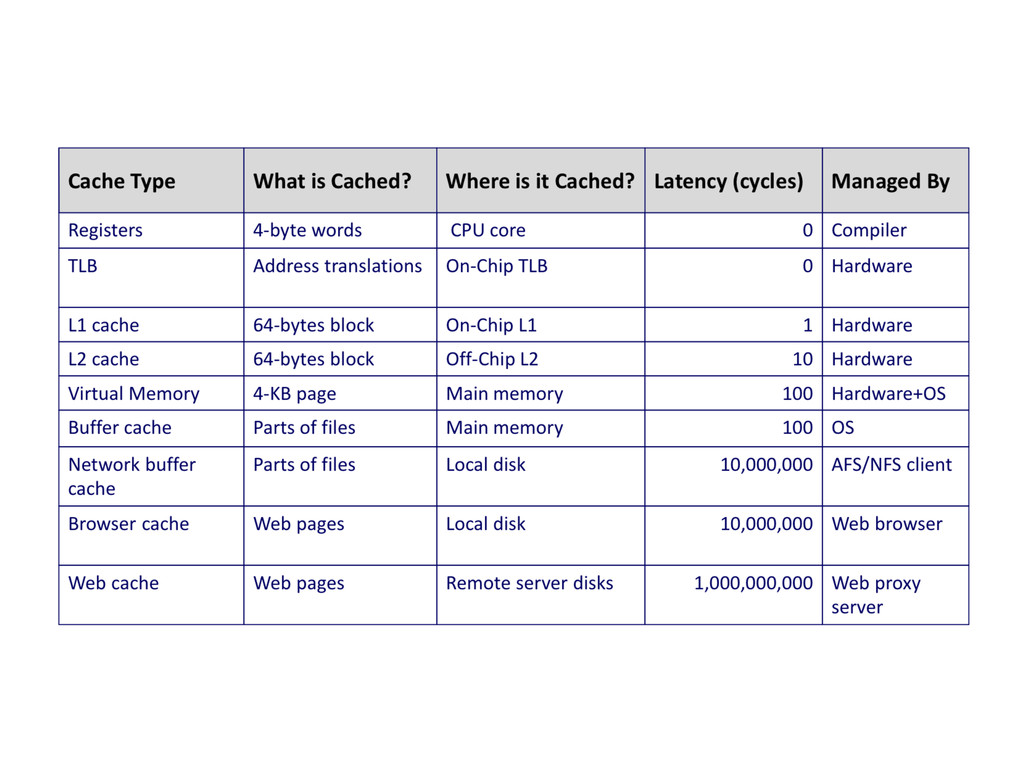
in the cache to the processors 1 - 2 clock cycle (L1), 5-20 clock cycle for (L2) Miss Penalty 50 - 200 clock cyles from the main memory Miss Rate Fraction of memory references not found in the cache (misses / accesses) 3-10 % (L1), less than 1%(L2)
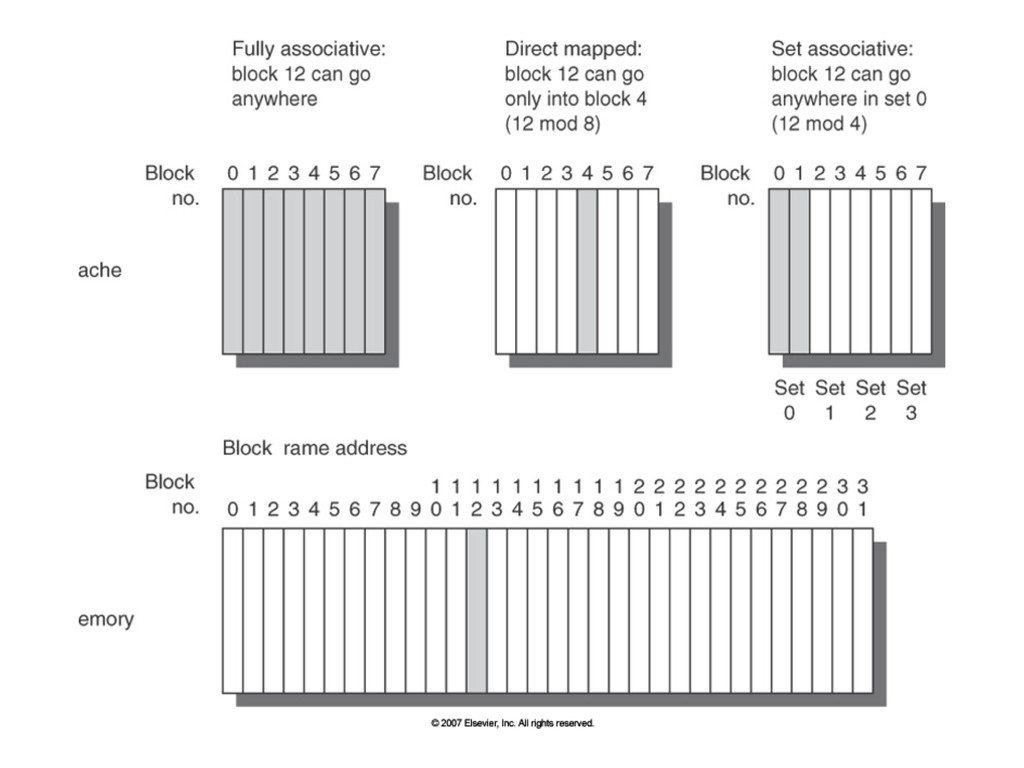
not in cache Cold start. First reference misses (misses in even an infinite cache) Capacity misses if the cache can not contain all needed blocks, due to discarded (misses in fully associative cache) Conflict misses Set associative or direct mapped: too many blocks in a set Collision (misses in n-way associative cache)
capacity is increased if upper level memory too small, too much time spend moving data between two levels. Trashing Conflict misses Set associative or direct mapped: too many blocks in a set Collision (misses in n-way associative cache)
2. Bigger cache to reduce miss rate 3. Higher associativity to reduce miss rate 4. Multilevel caches to reduce miss penalty 5. Giving priority to read misses over writes to reduce miss penalty
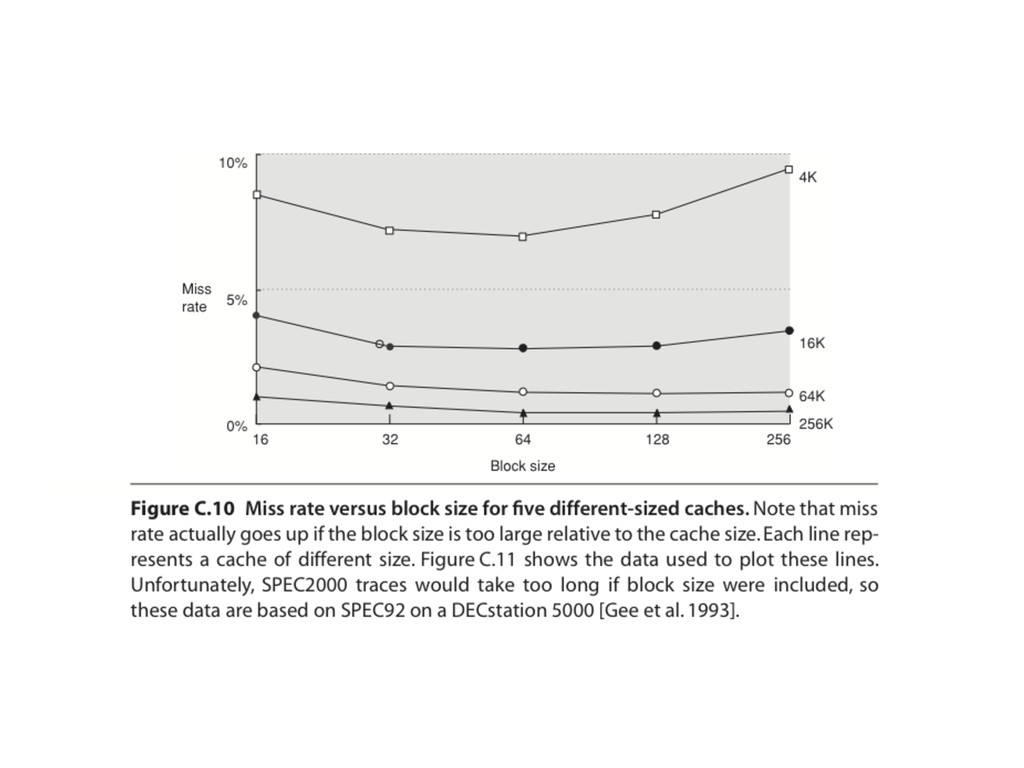
of spatial locality reduces compulsory misses Increases miss penalty (reduced number of blocks in the cache) increases conflict misses increases capacity misses if cache is small Miss penalty outweighs decreases in miss rate
reduces miss rate Increasing miss penalty, clock cycle increases Increasing hit time (larger MUX) Increasing hardware cost (comparator) Facts: Direct mapped cache with size of N has the same miss rate as two way set associative with N/2
penalty Improvement in miss rate More complicated measurement local miss rate = miss in a cache / memory accesses in this cache global miss rate = misses in the cache / total number of memory accesses by the processors Global cache miss rate should be used for measuring second level cache Speed of the first level => clock rate of the processor Speed of the second level => miss penalty of the first level First level cache design => fast hit, few misses Second level cache design => fewer hits, fewer misses, higher associativity, larger blocks
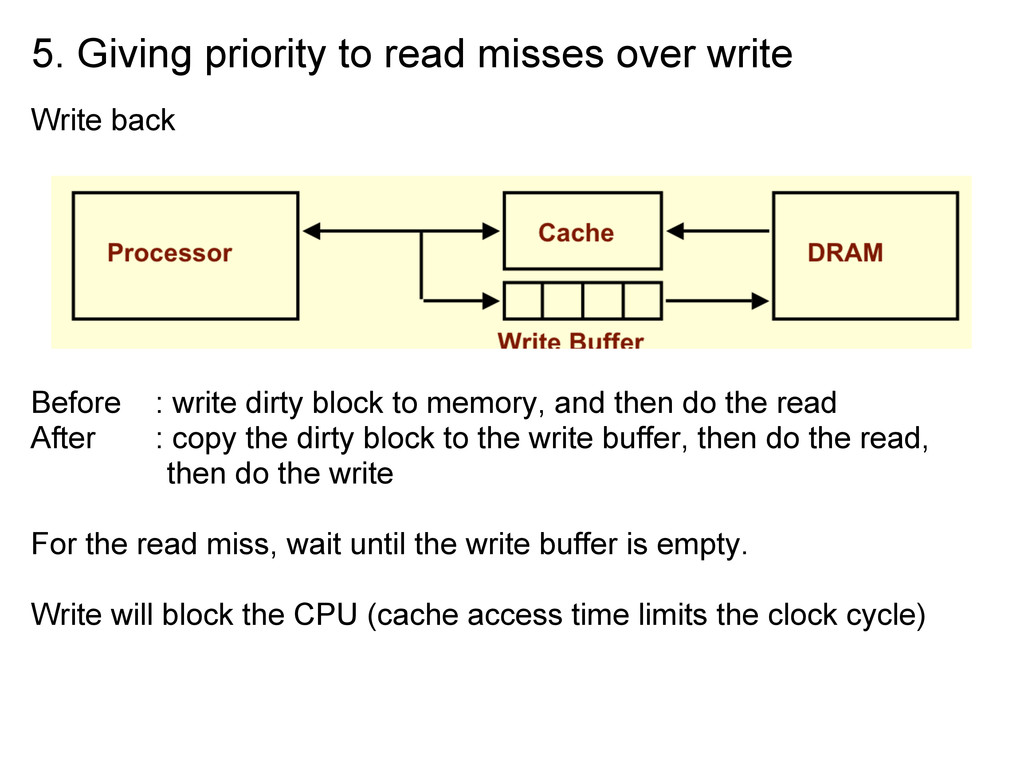
Before : write dirty block to memory, and then do the read After : copy the dirty block to the write buffer, then do the read, then do the write For the read miss, wait until the write buffer is empty. Write will block the CPU (cache access time limits the clock cycle)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}