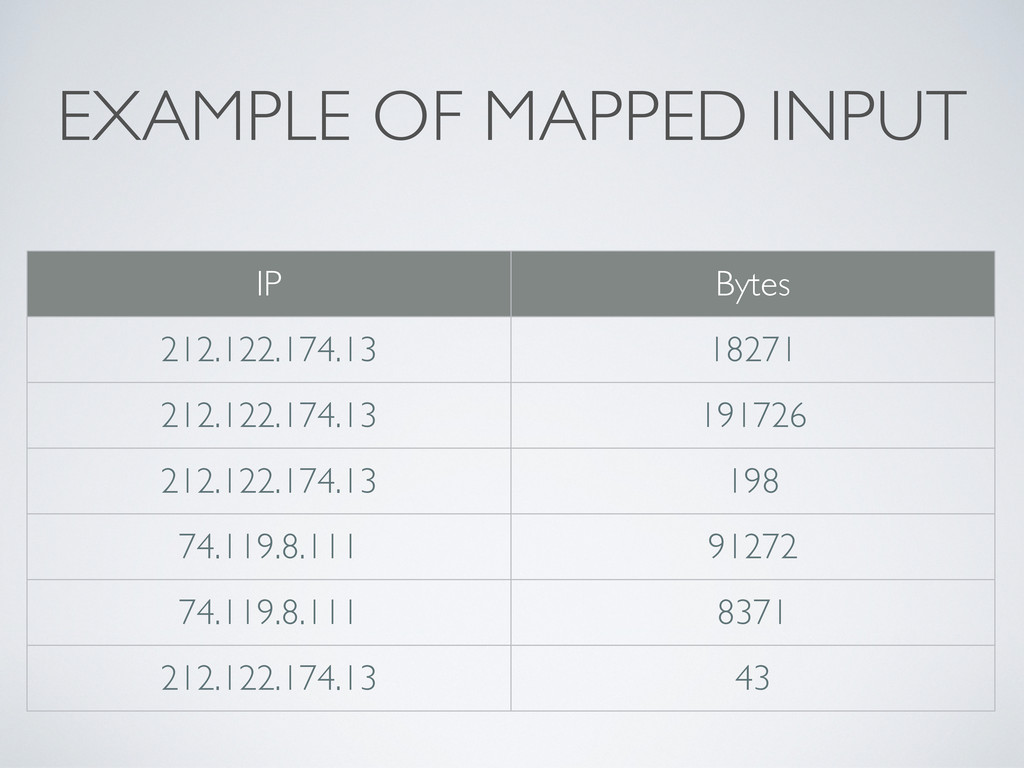
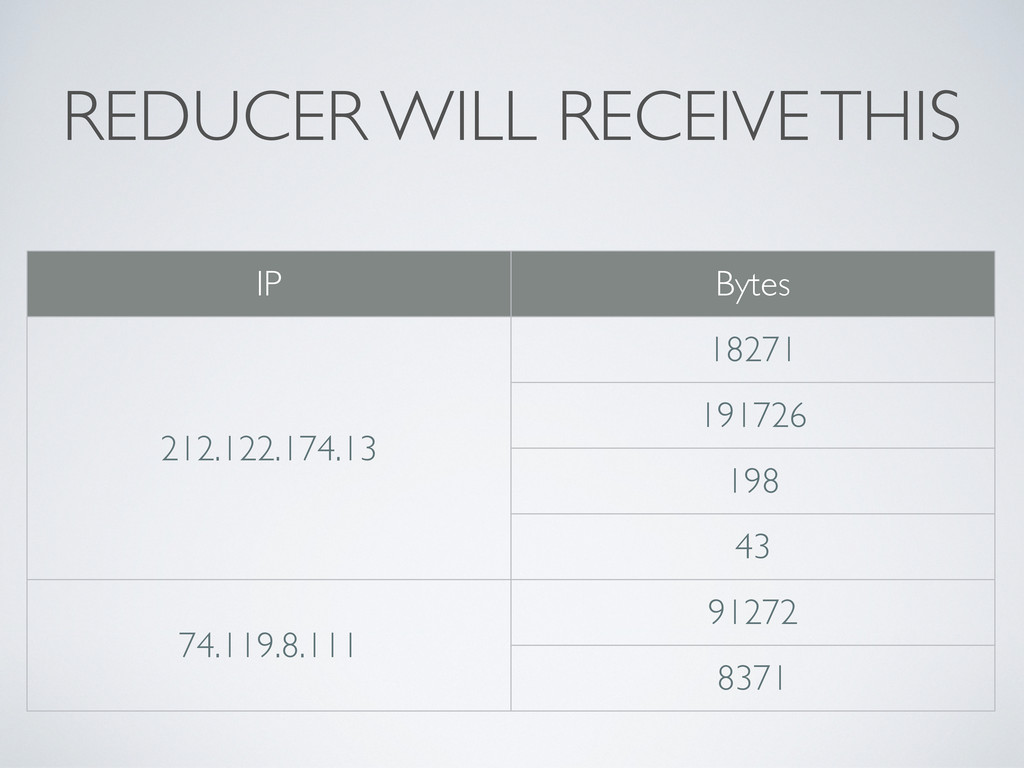
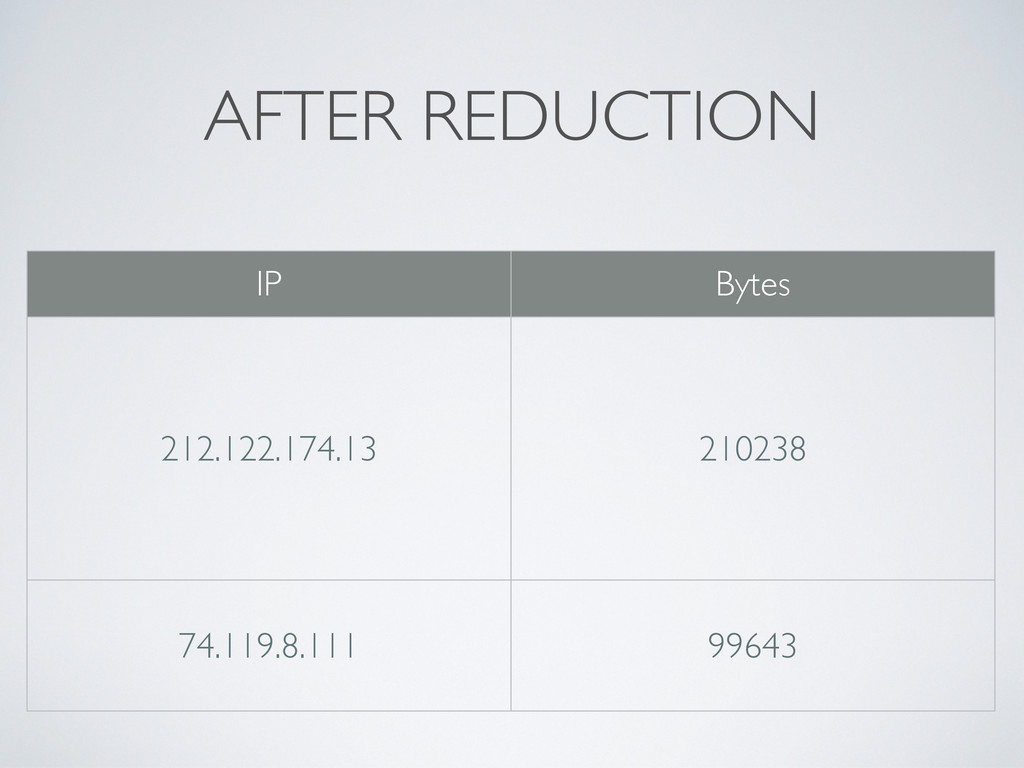
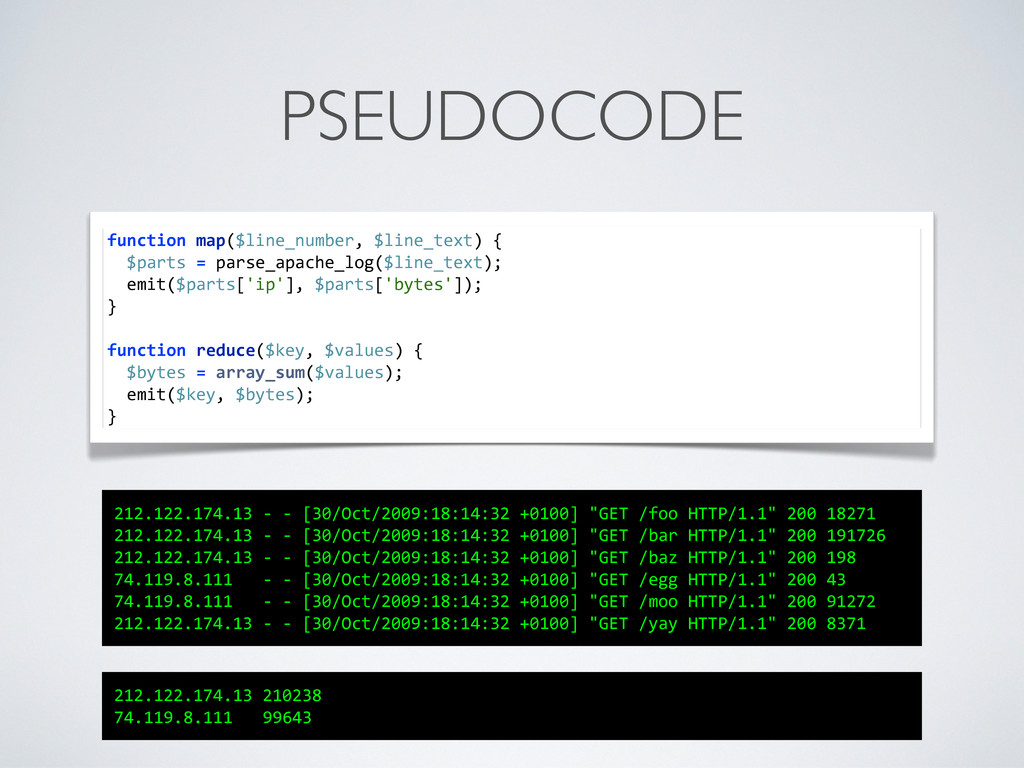
value> pairs 1.Input could be a web server log, with each line as a record 2.A Reducer is given a key and all values for this specific key 1.Even if there are many Mappers on many computers; the results are aggregated before they are handed to Reducers * In pratice, it’s a lot smarter than that
(~95%) • Largest cluster holds over 100 PB of data • Typically 8 cores, 12 TB storage and 32 GB RAM per node • 1x Gigabit Ethernet for each server in a rack • 4x Gigabit Ethernet from rack switch to core Hadoop is aware of racks and locality of nodes
of Pig) • Rackspace (log analysis; data pumped into Lucene/Solr) • LinkedIn (contact suggestions) • Last.fm (charts, log analysis, A/B testing) • The New York Times (converted 4 TB of scans using EC2)
data into single records • You can optimize using combiners to reduce locally on a node • Only possible in some cases, e.g. for max(), but not avg() • You can control partitioning of map output yourself • Rarely useful, the default partitioner (key hash) is enough • And a million other things that really don’t matter right now ;)
MB) • Designed for very large data sets • Designed for streaming rather than random reads • Write-once, read-many (although appending is possible) • Capable of compression and other cool things
throughput • Blocks are stored redundantly (3 replicas as default) • Aware of infrastructure characteristics (nodes, racks, ...) • Datanodes hold blocks • Namenode holds the metadata Critical component for an HDFS cluster (HA, SPOF)
jobs in PHP • Takes care of input splitting, can do basic decoding et cetera • Automatically detects and handles Hadoop settings such as key length or field separators • Packages jobs as one .phar archive to ease deployment • Also creates a ready-to-rock shell script to invoke the job
Central Nimbus service coordinates execution w/ ZooKeeper • A Storm cluster runs Topologies, processing continuously • Spouts produce streams: unbounded sequences of tuples • Bolts consume input streams, process, output again • Topologies can consist of many steps for complex tasks
• Uses STDIN/STDOUT like Hadoop Streaming, plus JSON • Storm can provide transactions for topologies and guarantee processing of messages • Architecture allows for non stream processing applications • e.g. Distributed RPC
Hadoop • Uses Hadoop v2 YARN infrastructure for distributed work • No MapReduce, no job setup overhead • Query data in HDFS or HBase • Hive compatible interface • Potential game changer for its performance characteristics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU! This was http://joind.in/8435 by @dzuelke. Questions: [email protected]](https://files.speakerdeck.com/presentations/18d89980b1960130cb445a60bc2046a1/slide_85.jpg){kind=link}