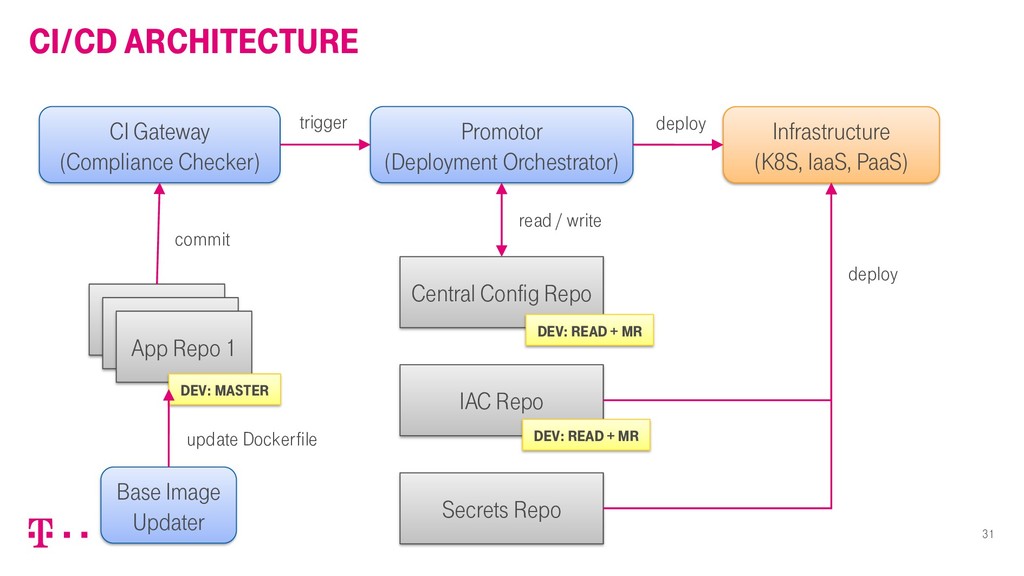
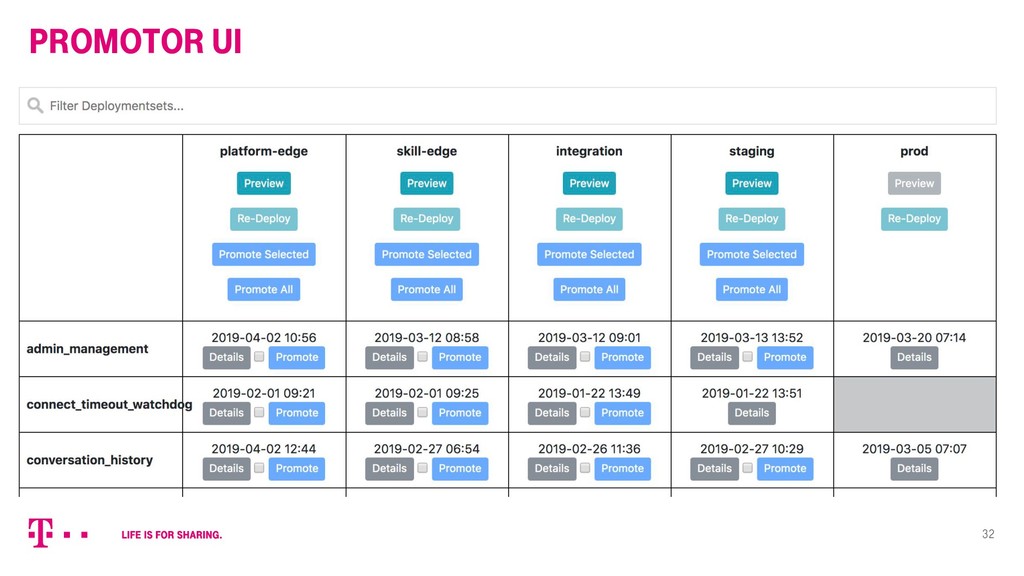
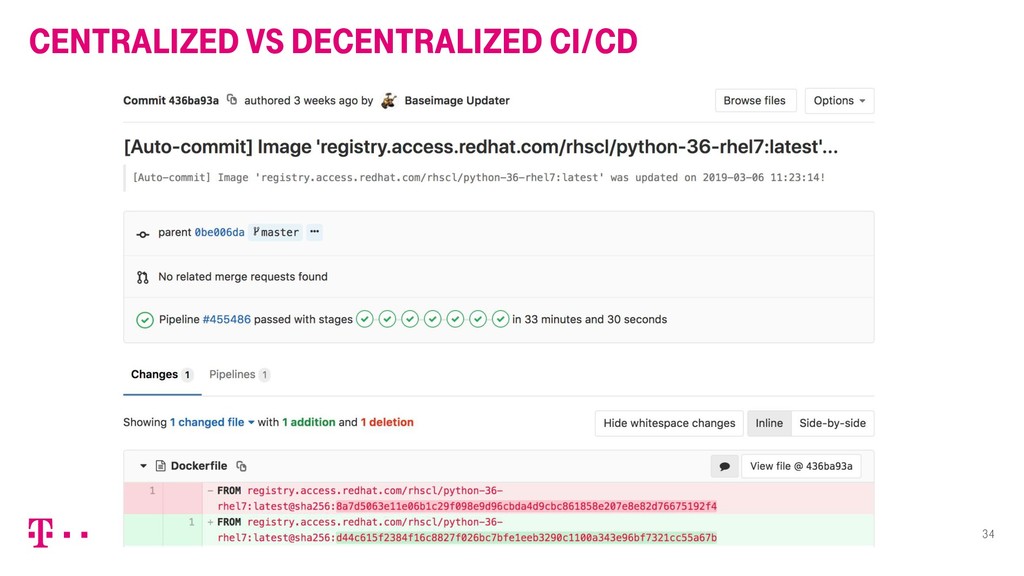
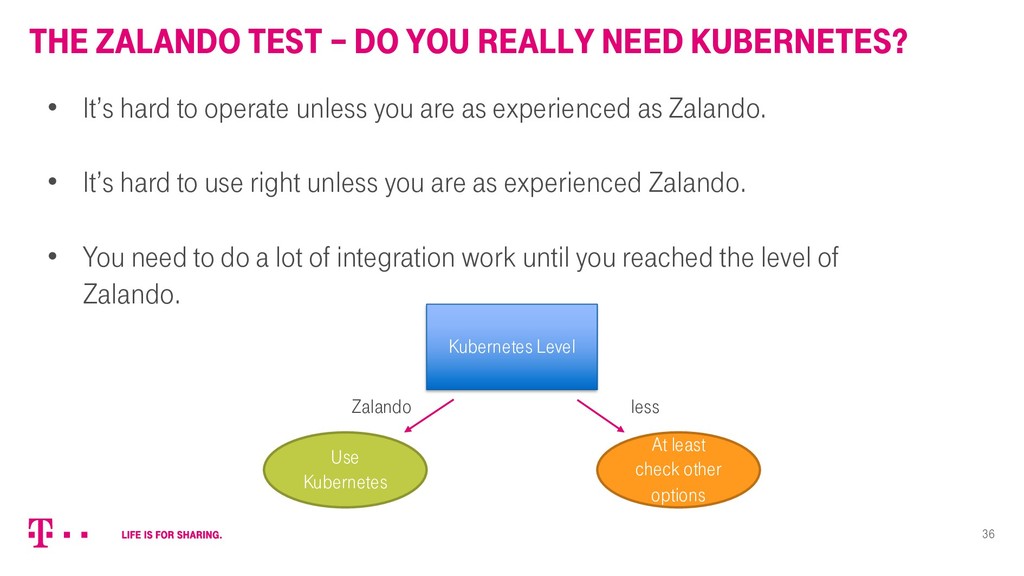
Die „Hallo Magenta“ Smart Speaker Plattform ist eines der ersten Endkundenprodukte der Deutschen Telekom, das von Beginn an „cloud native“ entwickelt wurde. Als technischer Product Manager der Plattform blickt Robert zurück und zieht Resümee: Wo haben sich Technik, Organisation und Ambition ergänzt? Und wo nicht?
{kind=link}
{kind=link}
{kind=link}
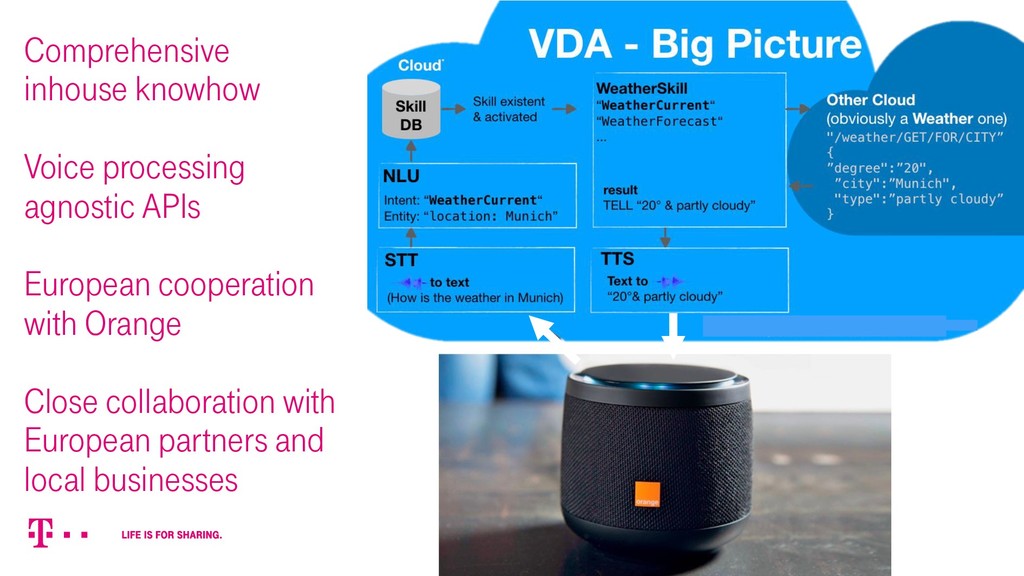{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
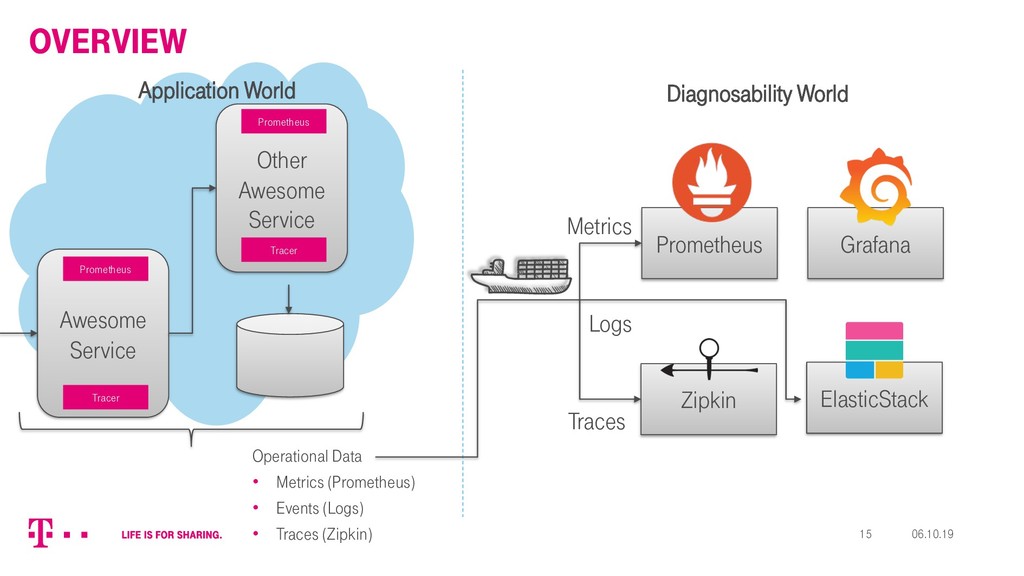{kind=link}
{kind=link}
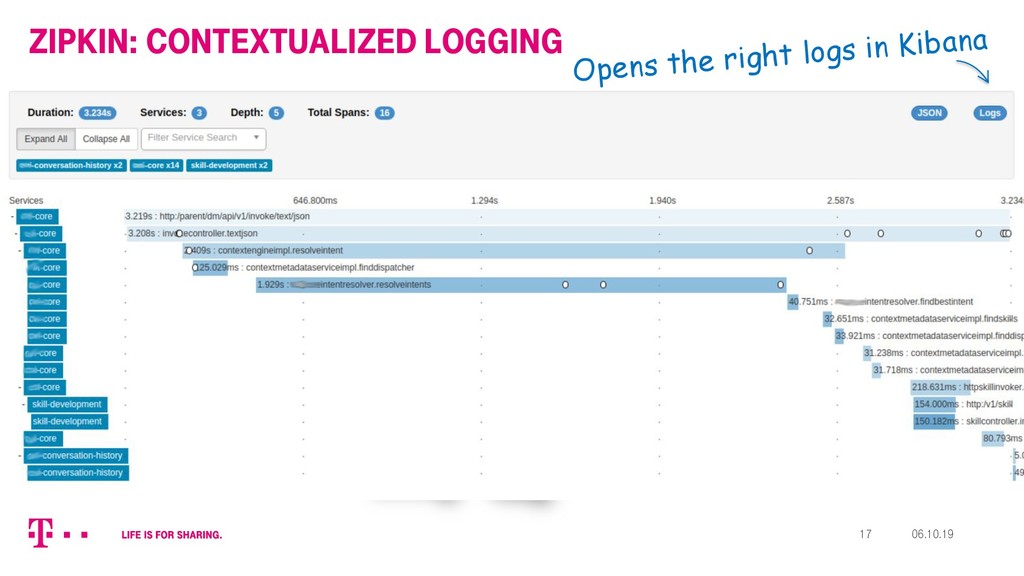{kind=link}
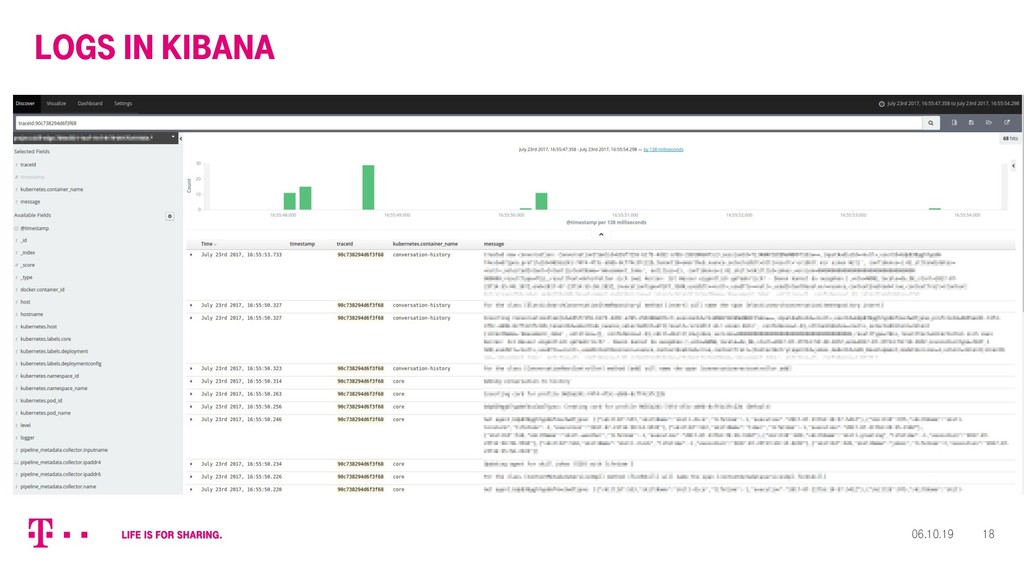{kind=link}
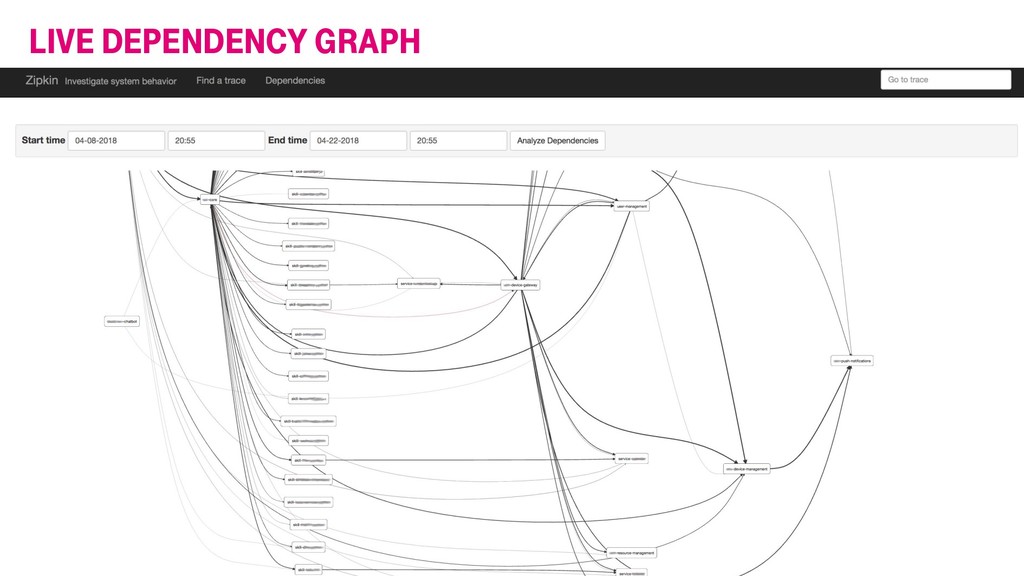{kind=link}
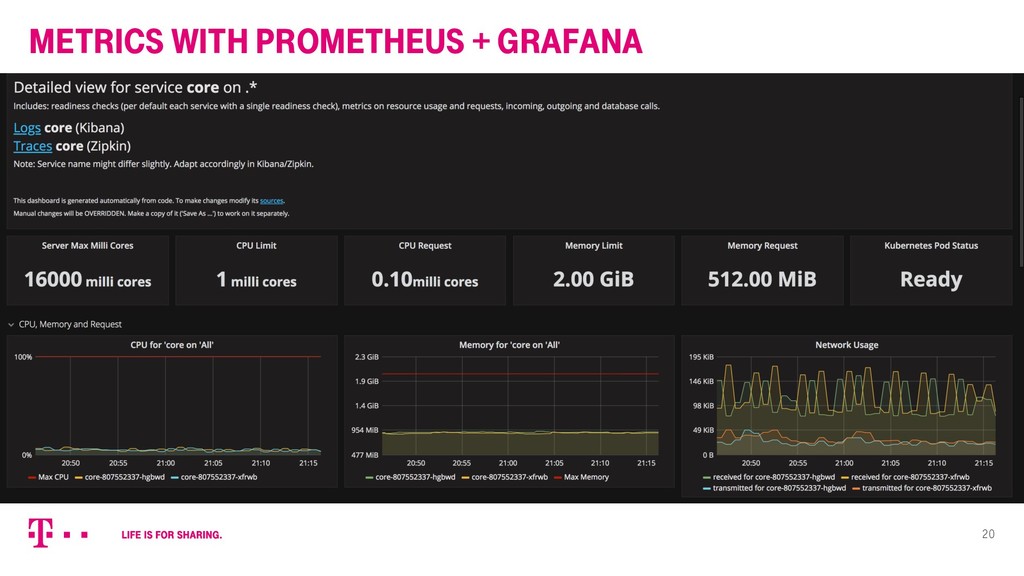{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}