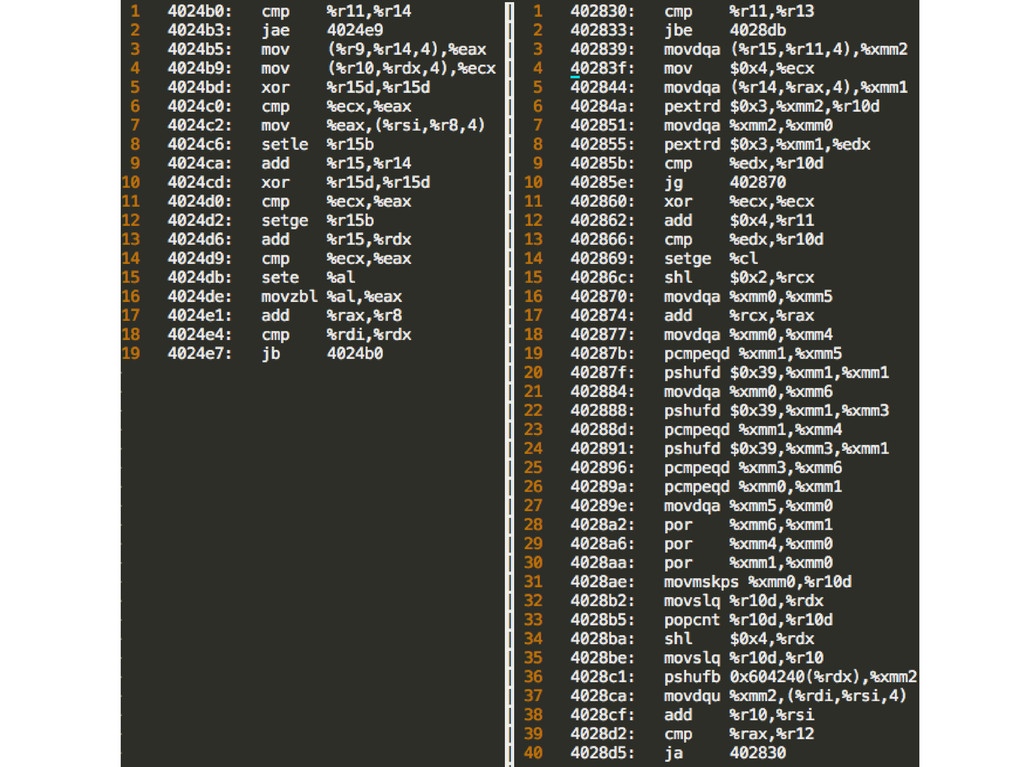
{ __m128i a16 = _mm_load_si128((__m128i*)&a[j]); __m128i b16 = _mm_load_si128((__m128i*)&b[j]); __m128i diff16 = _mm_sub_epi16(a16, b16); __m128i madd = _mm_madd_epi16(diff16, diff16); xsum = _mm_add_epi32(xsum, madd); j += 8; } __m128i shft = _mm_srli_si128(xsum, 8); xsum = _mm_add_epi32(xsum, shft); shft = _mm_srli_si128(xsum, 4); xsum = _mm_add_epi32(xsum, shft); sum = _mm_cvtsi128_si32(xsum); T = 0.384s
{kind=link}
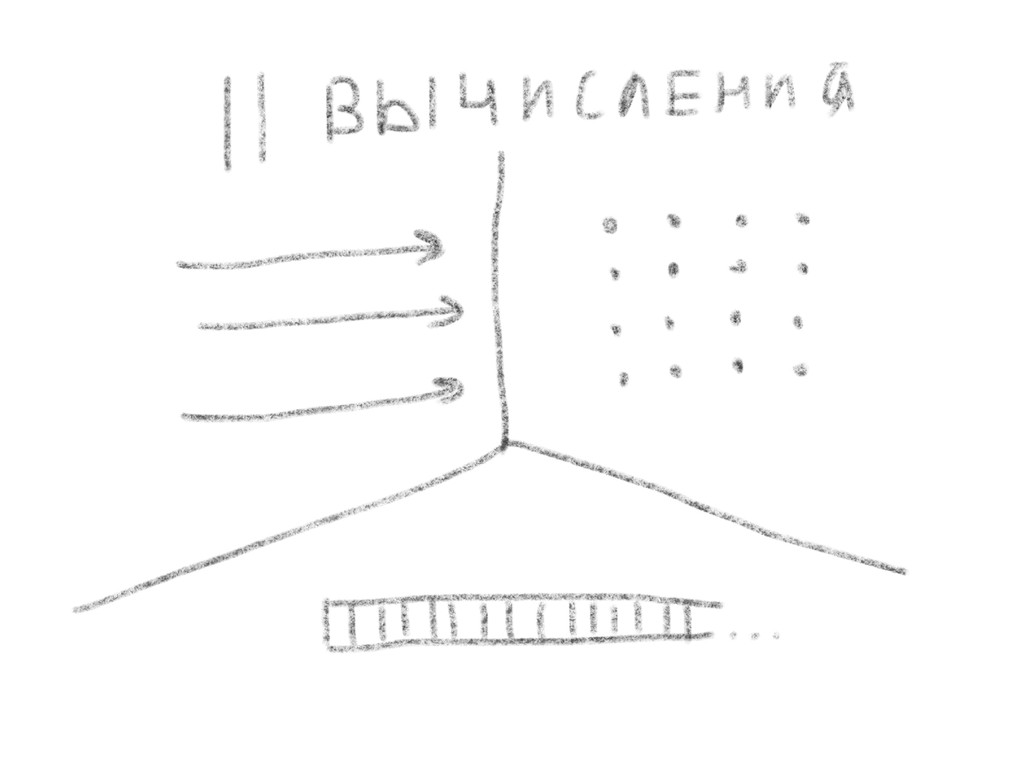{kind=link}
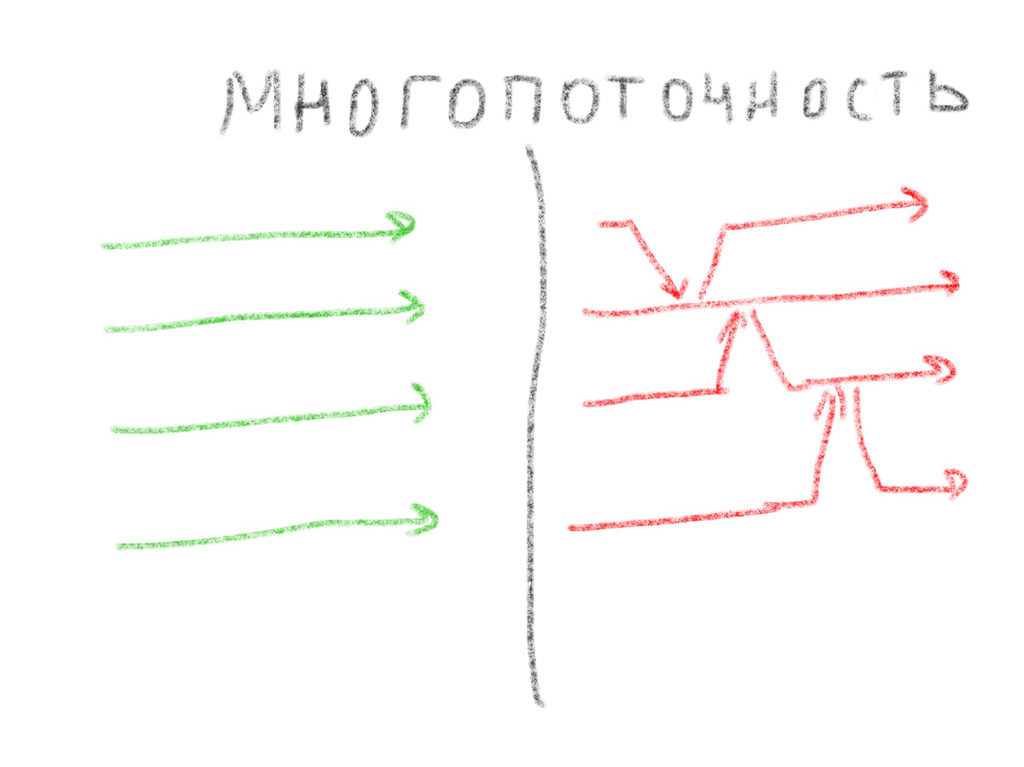{kind=link}
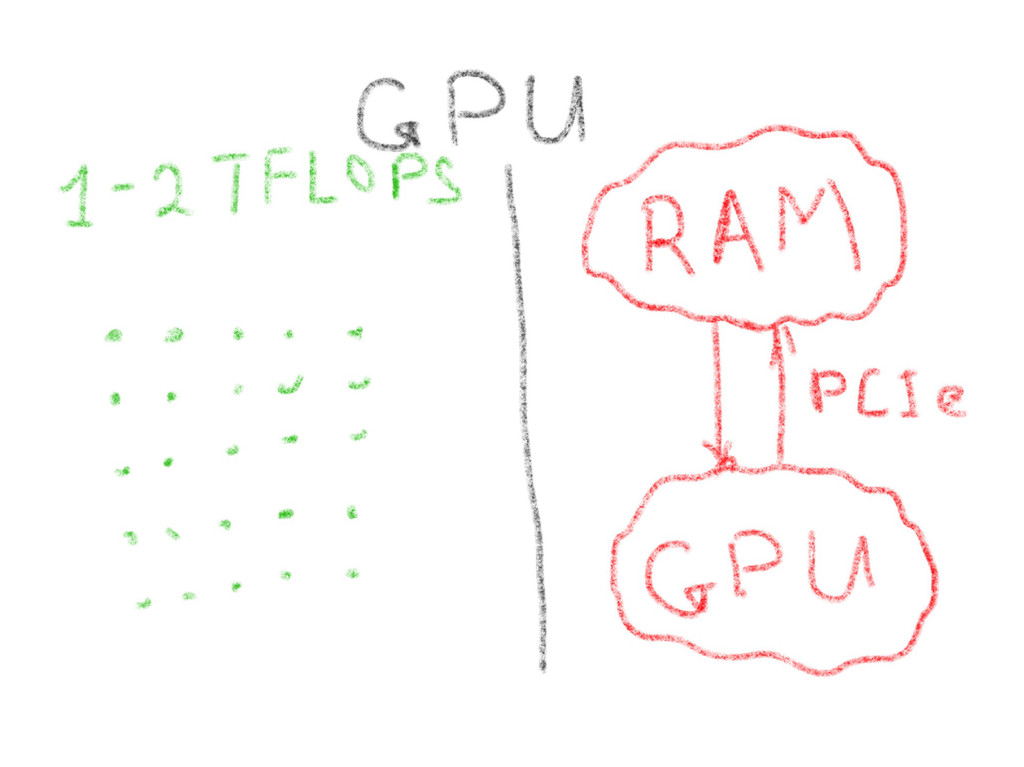{kind=link}
{kind=link}
{kind=link}
![Naive short a[256] __attribute__ ((aligned(16))); short b[256] __attribute__ ((aligned(16))); int](https://files.speakerdeck.com/presentations/85d93f402f8901318dff1626dba473f5/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
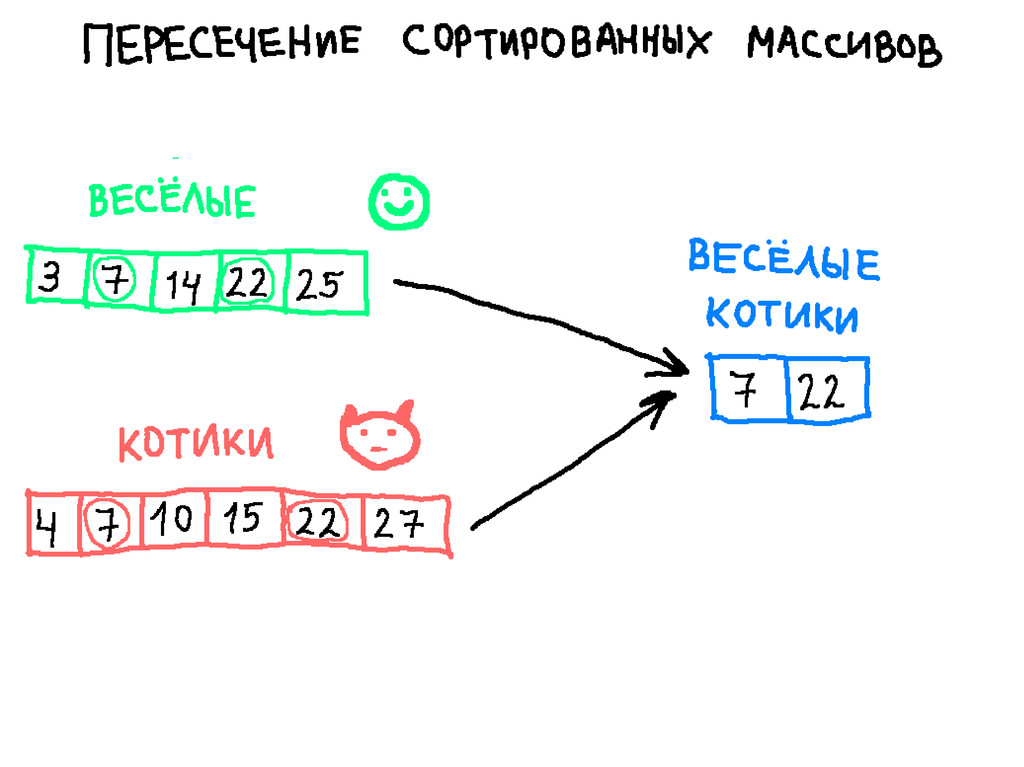{kind=link}
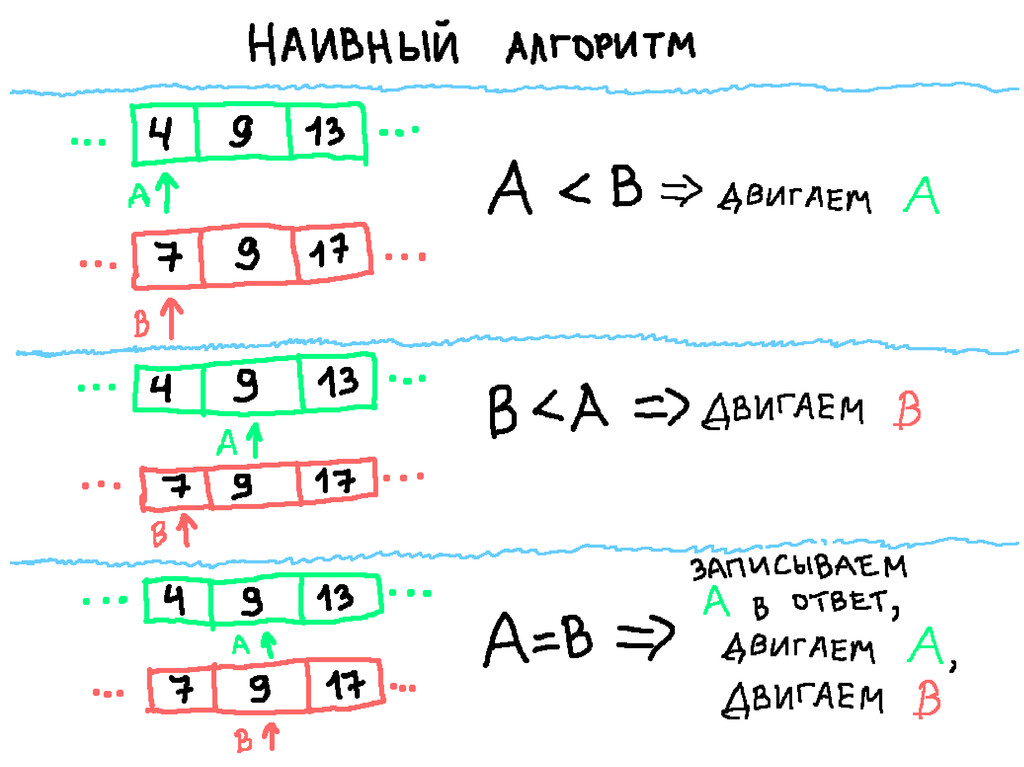{kind=link}
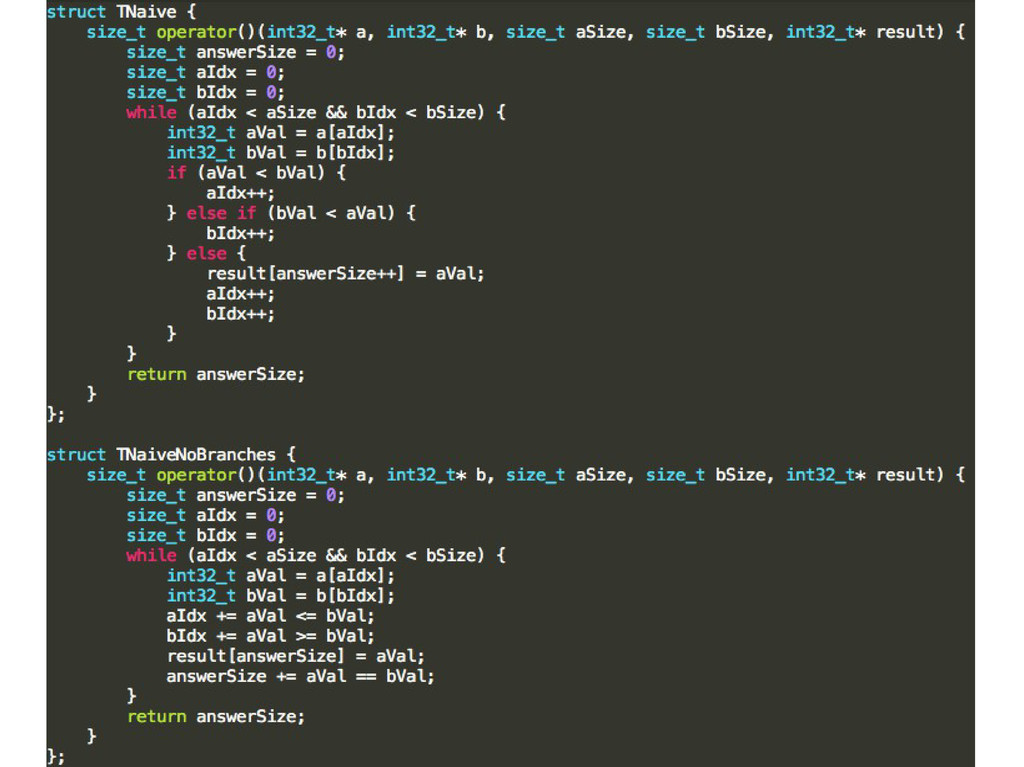{kind=link}
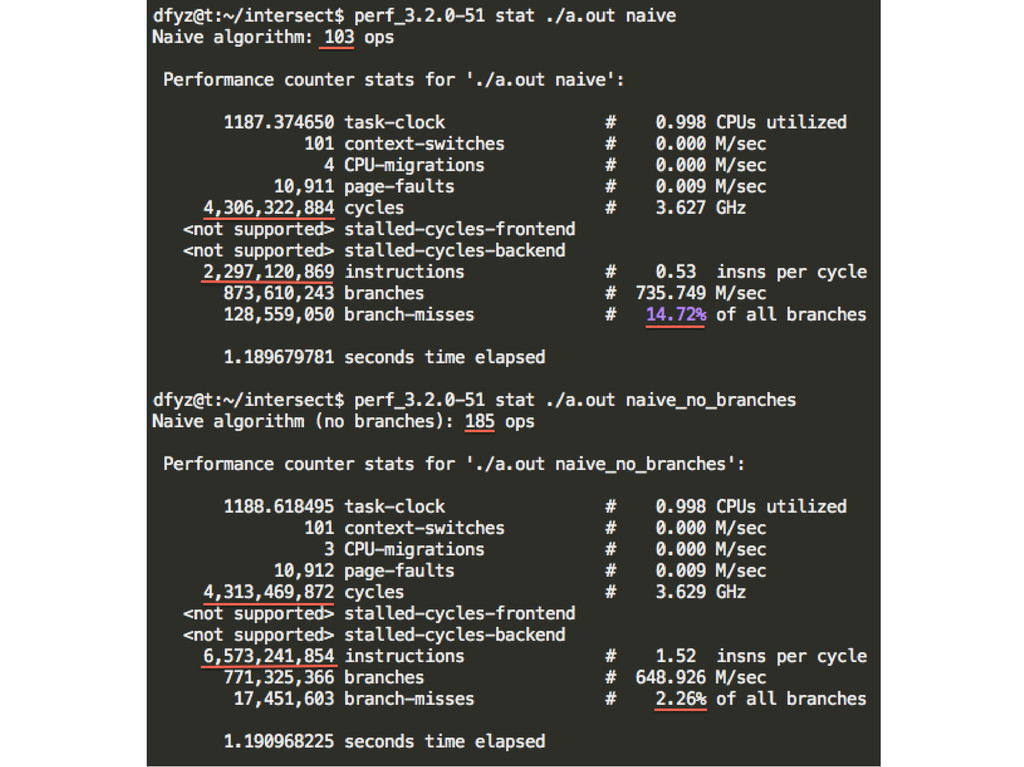{kind=link}
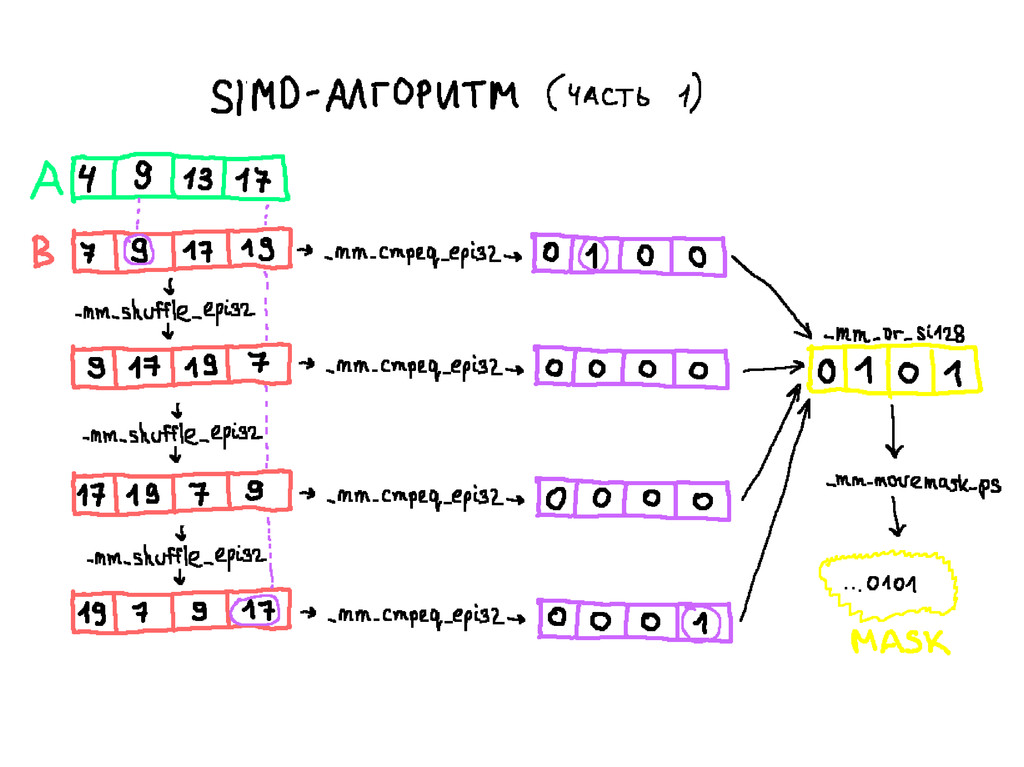{kind=link}
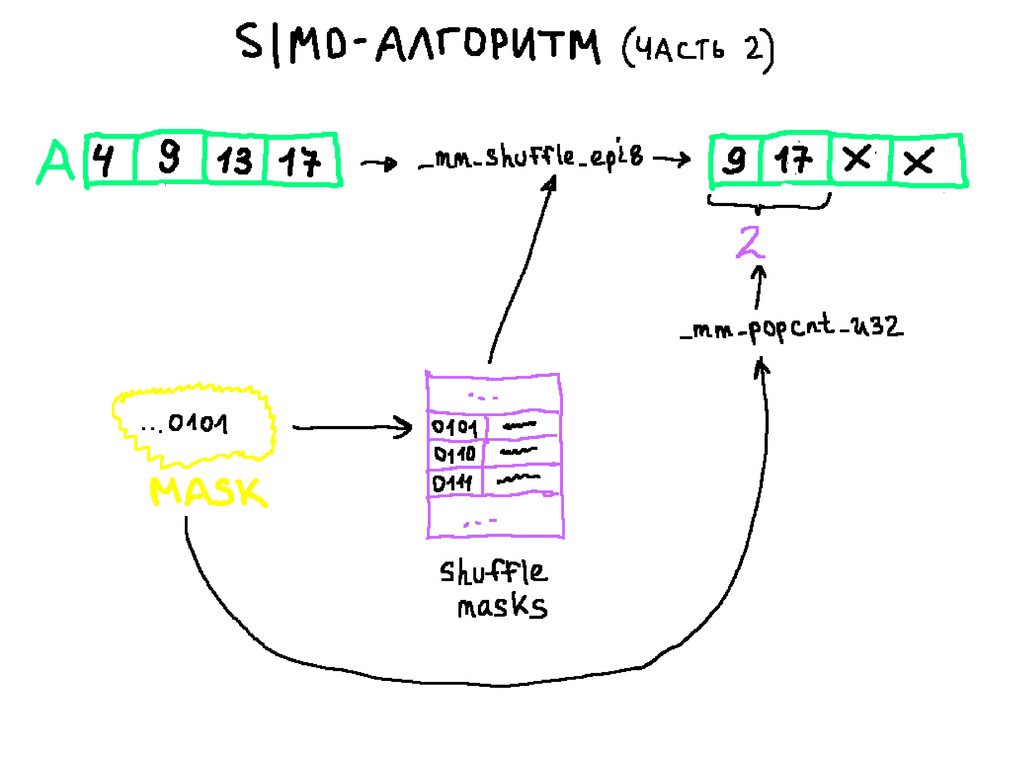{kind=link}
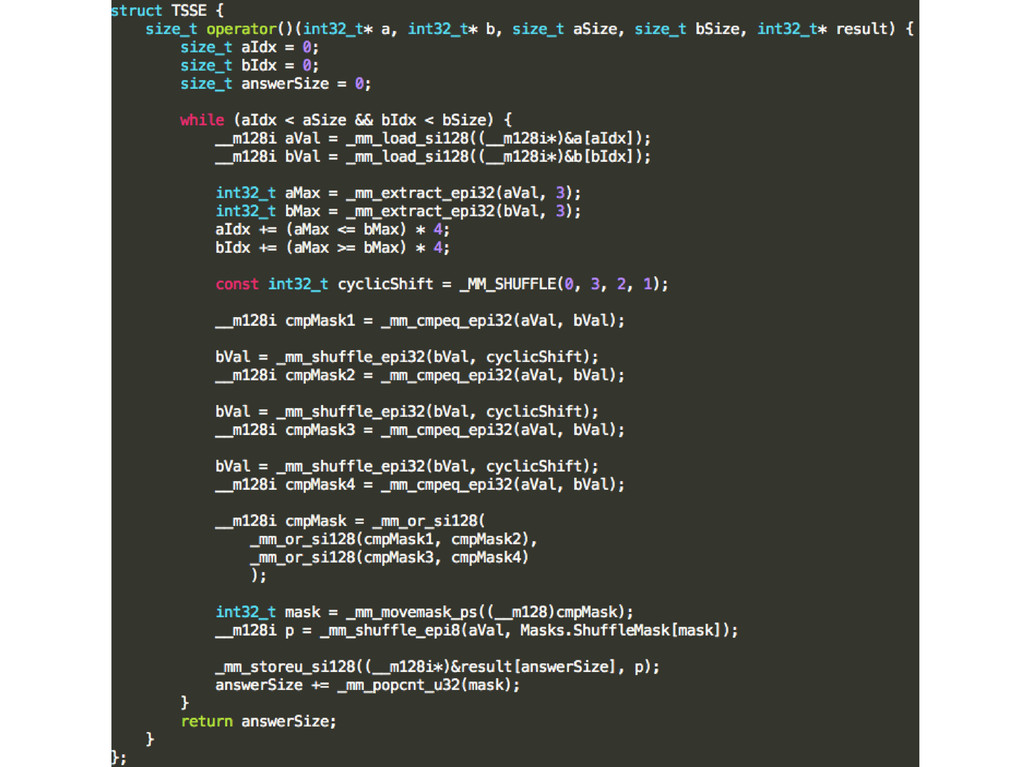{kind=link}
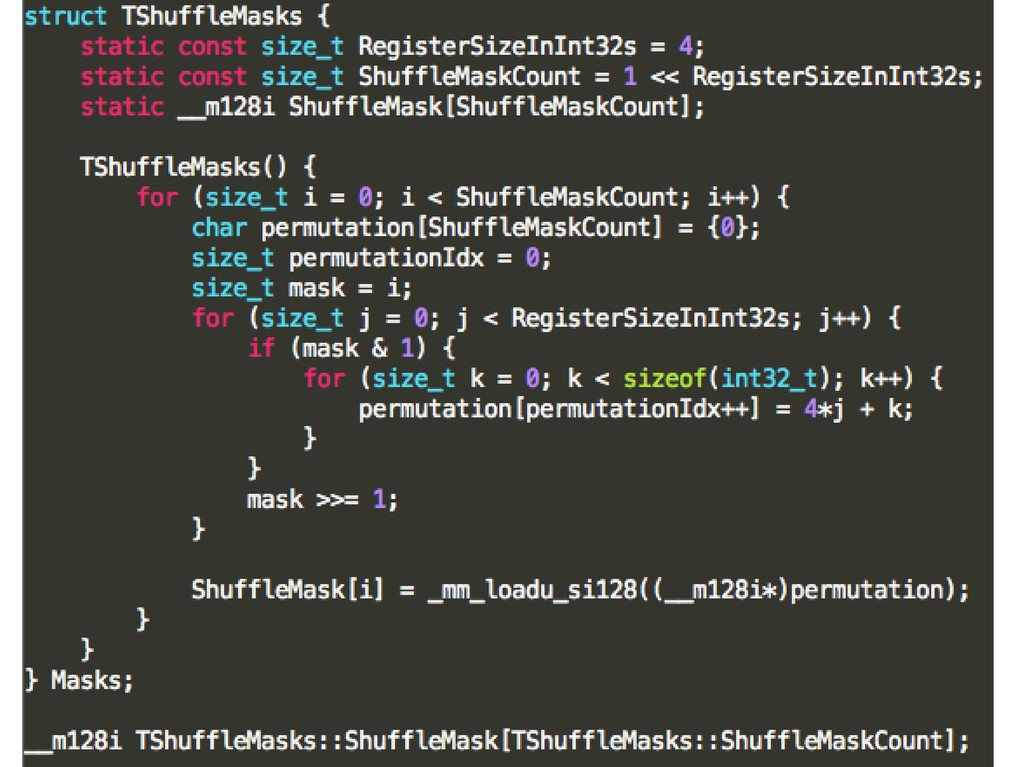{kind=link}
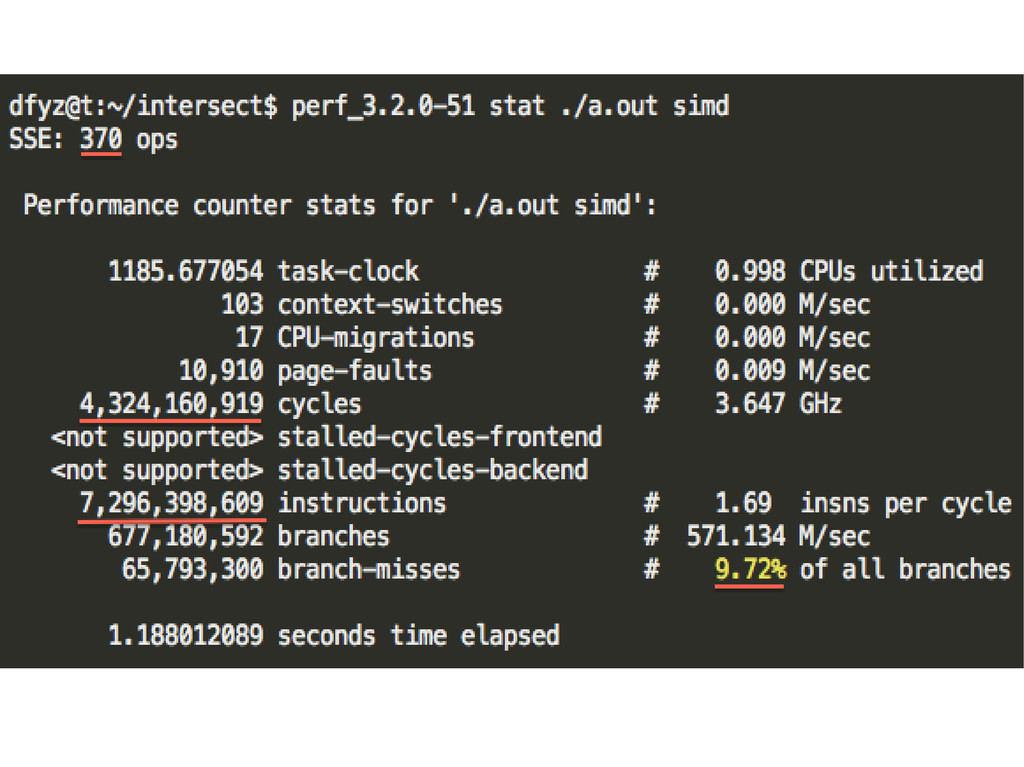{kind=link}
{kind=link}