End-to-end Adaptation with Backpropagation through WFST for On-device Speech Recognition System
Interspeech2019読み会向けの資料です。
Interspeech2019で発表した「End-to-end Adaptation with Backpropagation through WFST for On-device Speech Recognition System」についてです。
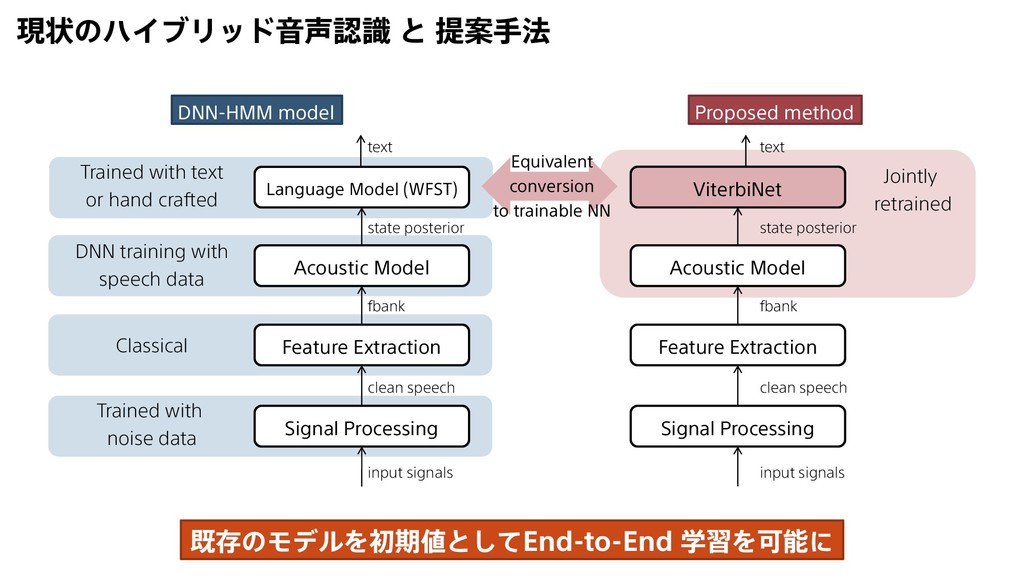
input signals clean speech fbank state posterior text Jointly retrained DNN-HMM model Language Model (WFST) Acoustic Model Feature Extraction Signal Processing input signals clean speech fbank state posterior text Trained with noise data Classical DNN training with speech data Trained with text or hand crafted Proposed method Equivalent conversion to trainable NN 既存のモデルを初期値としてEnd-to-End 学習を可能に
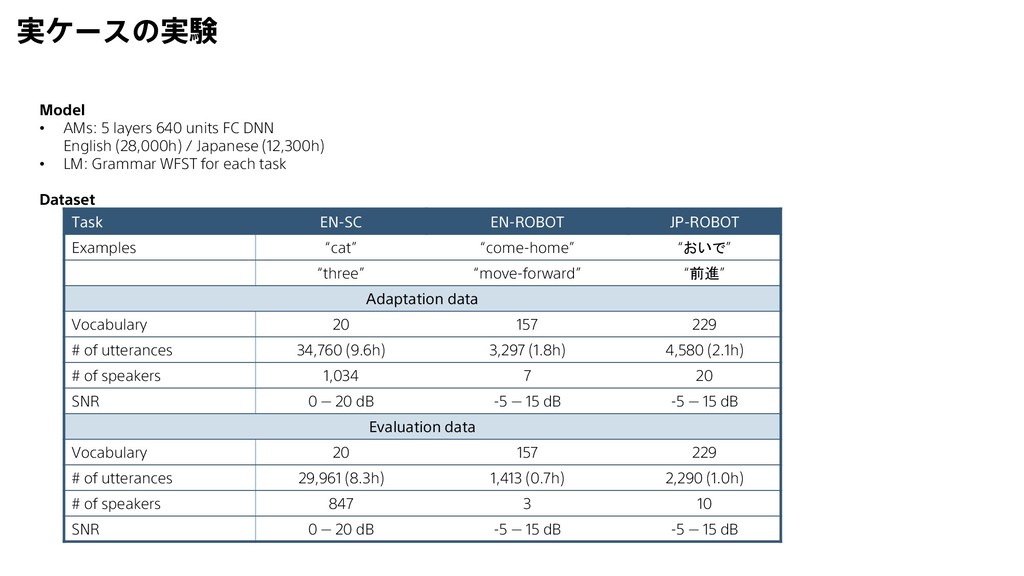
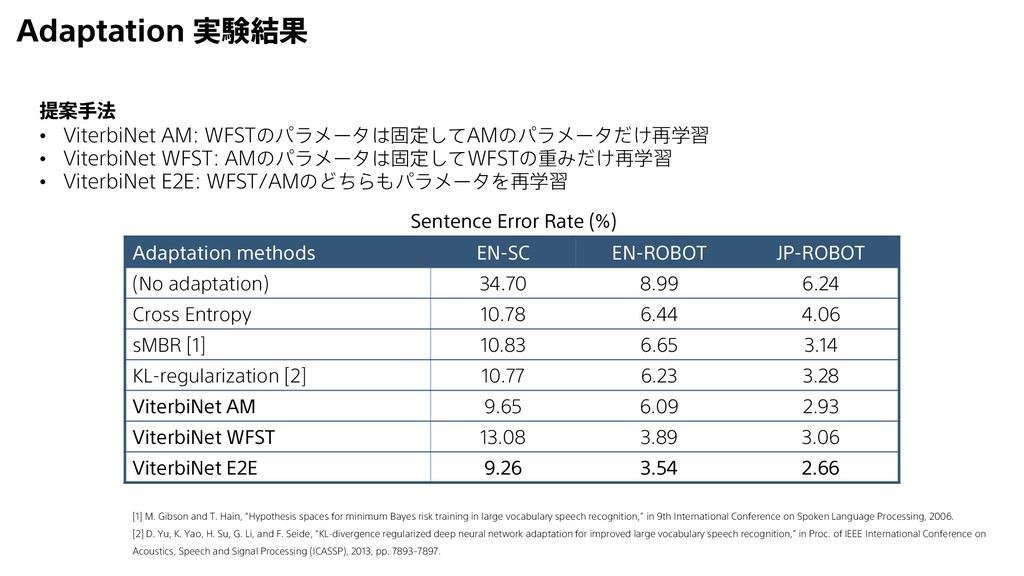
8.99 6.24 Cross Entropy 10.78 6.44 4.06 sMBR [1] 10.83 6.65 3.14 KL-regularization [2] 10.77 6.23 3.28 ViterbiNet AM 9.65 6.09 2.93 ViterbiNet WFST 13.08 3.89 3.06 ViterbiNet E2E 9.26 3.54 2.66 提案手法 • ViterbiNet AM: WFSTのパラメータは固定してAMのパラメータだけ再学習 • ViterbiNet WFST: AMのパラメータは固定してWFSTの重みだけ再学習 • ViterbiNet E2E: WFST/AMのどちらもパラメータを再学習 Sentence Error Rate (%) [1] M. Gibson and T. Hain, “Hypothesis spaces for minimum Bayes risk training in large vocabulary speech recognition,” in 9th International Conference on Spoken Language Processing, 2006. [2] D. Yu, K. Yao, H. Su, G. Li, and F. Seide, “KL-divergence regularized deep neural network adaptation for improved large vocabulary speech recognition,” in Proc. of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2013, pp. 7893–7897.
{kind=link}
{kind=link}
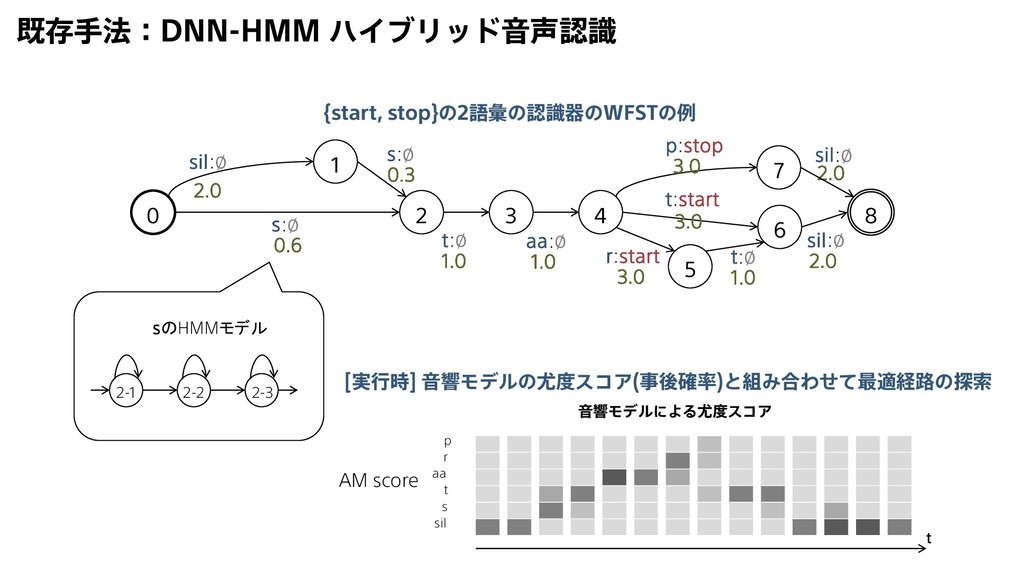
{kind=link}
{kind=link}
![[ViterbiNet] グラフ遷移を行列で表現 0 2 1 3 4 5 6 8](https://files.speakerdeck.com/presentations/a0e4415cfc884130bdbf4736954dd1f3/slide_4.jpg){kind=link}
![[ViterbiNet] 再帰的な前向き演算 sil s t aa r p initial state](https://files.speakerdeck.com/presentations/a0e4415cfc884130bdbf4736954dd1f3/slide_5.jpg){kind=link}
![[ViterbiNet] 出力層の演算 0 2 1 3 4 5 6 8](https://files.speakerdeck.com/presentations/a0e4415cfc884130bdbf4736954dd1f3/slide_6.jpg){kind=link}
![[ViterbiNet] ネットワーク構成 Sparse Affine Output Computation Maxpooling AM DNN mapping](https://files.speakerdeck.com/presentations/a0e4415cfc884130bdbf4736954dd1f3/slide_7.jpg){kind=link}
![[ViterbiNet] Backpropagaton backward forward Output sequence start stop 遷移行列Vの パラメータ更新](https://files.speakerdeck.com/presentations/a0e4415cfc884130bdbf4736954dd1f3/slide_8.jpg){kind=link}
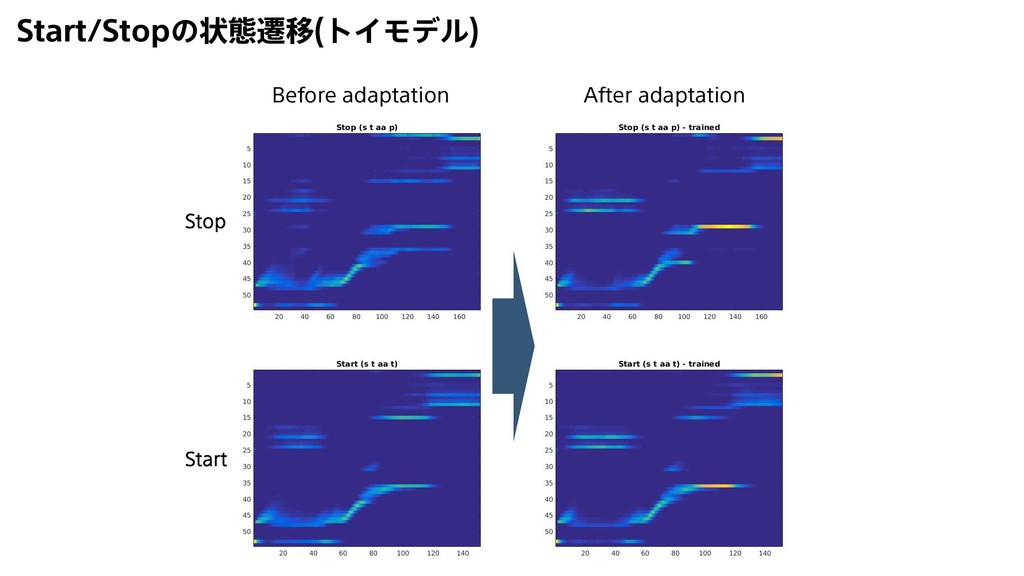{kind=link}
{kind=link}
{kind=link}
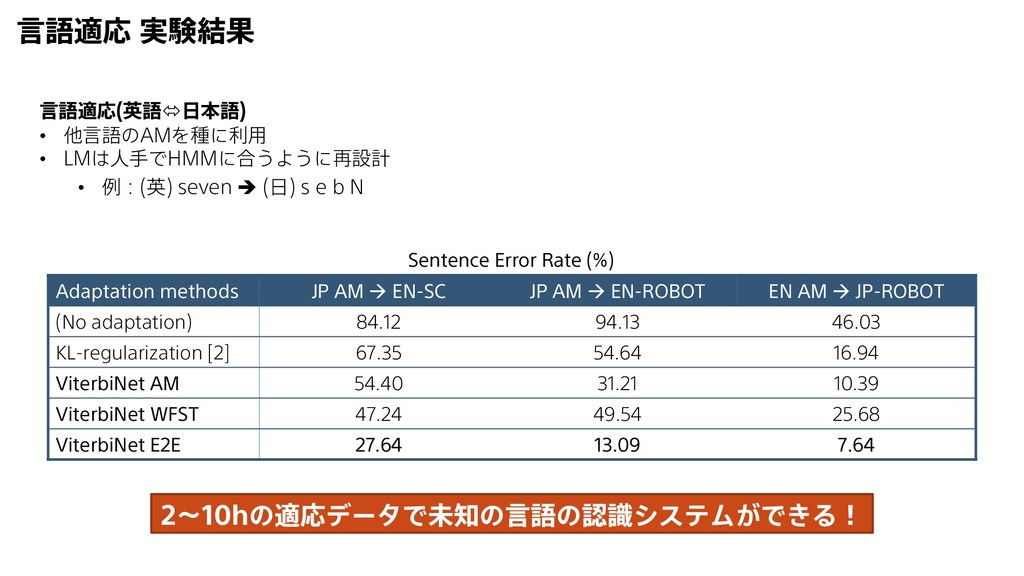{kind=link}
{kind=link}