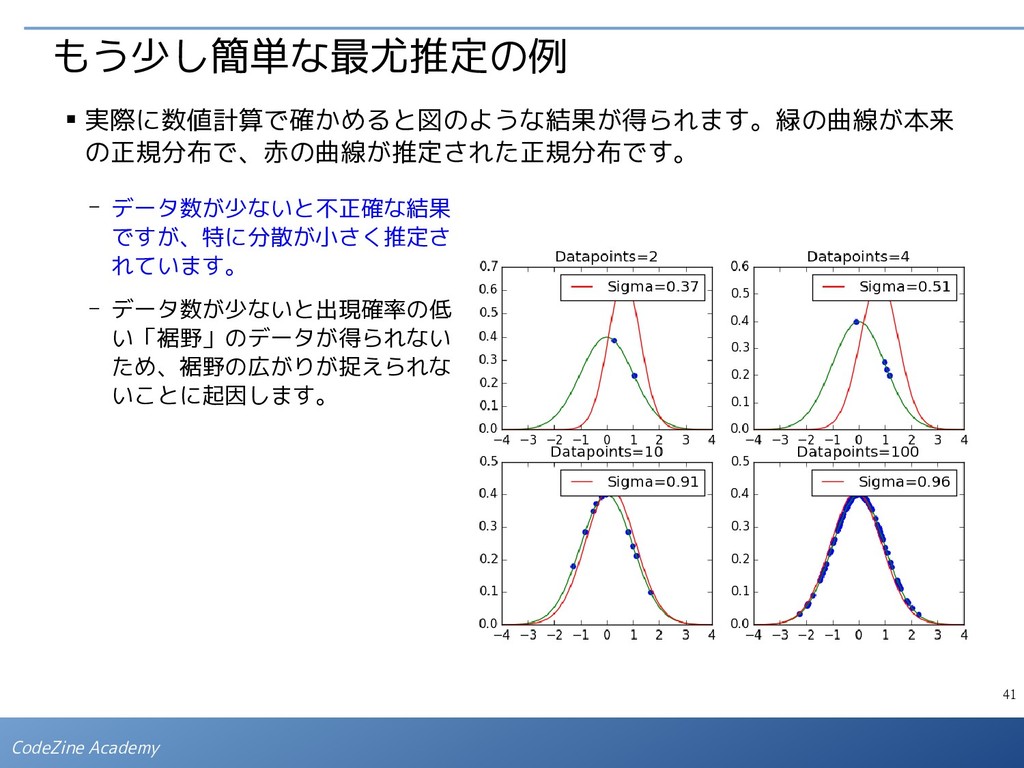
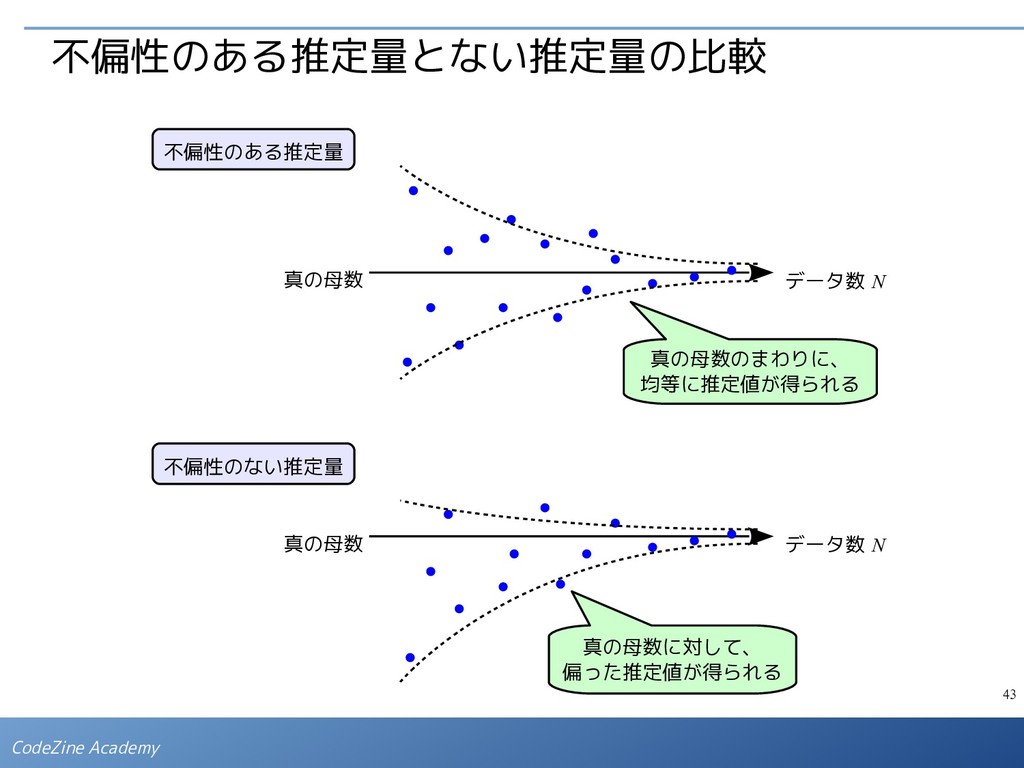
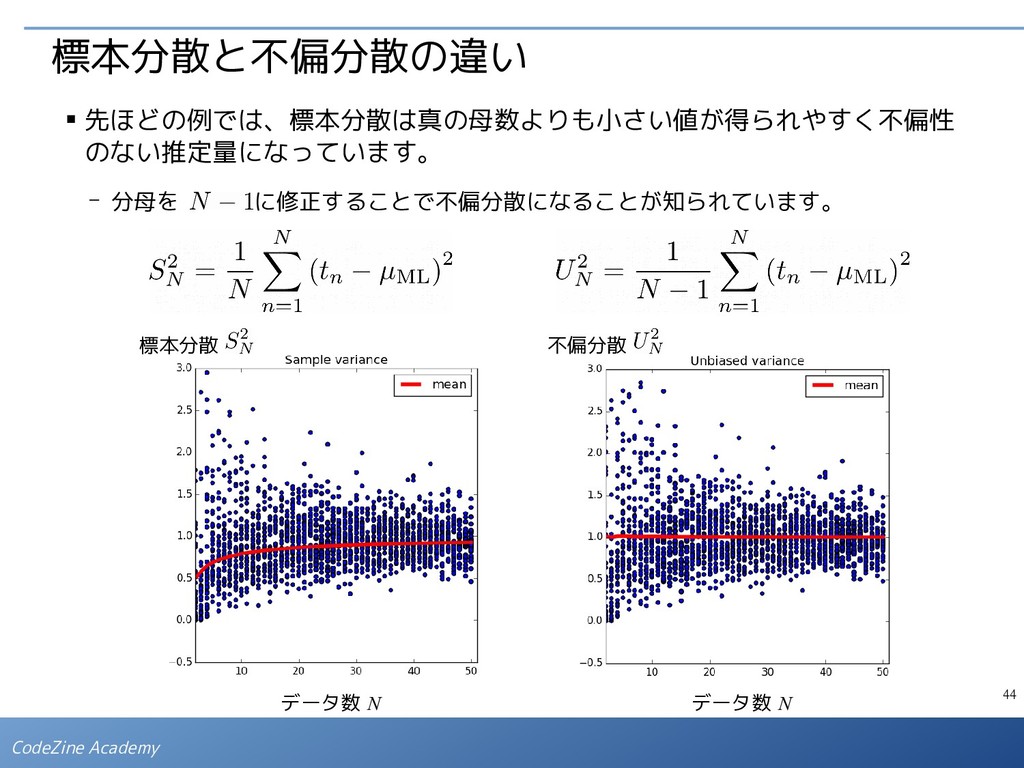
パラメータの過剰調整であり、 オーバーフィッティングの兆候と 考えられます。 Table of the coefficients M=0 M=1 M=3 M=9 0 -0.02844 0.498661 -0.575134 -0.528572 1 NaN -1.054202 12.210765 151.946893 2 NaN NaN -29.944028 -3569.939743 3 NaN NaN 17.917824 34234.907567 4 NaN NaN NaN -169228.812728 5 NaN NaN NaN 478363.615824 6 NaN NaN NaN -804309.985246 7 NaN NaN NaN 795239.975974 8 NaN NaN NaN -426702.757987 9 NaN NaN NaN 95821.189286 ▪ N = 10 の例で実際に計算された係数 の値を見ると下表のようにな ります。 ▪ そこで、適当な定数 λ を用いて、下記のように修正した誤差関数を最小にする という条件で係数を決めると、次数が高くでもオーバーフィッティングが発生 しにくくなります。 - 最適な λ の値は、試行錯誤で決める必要があります。
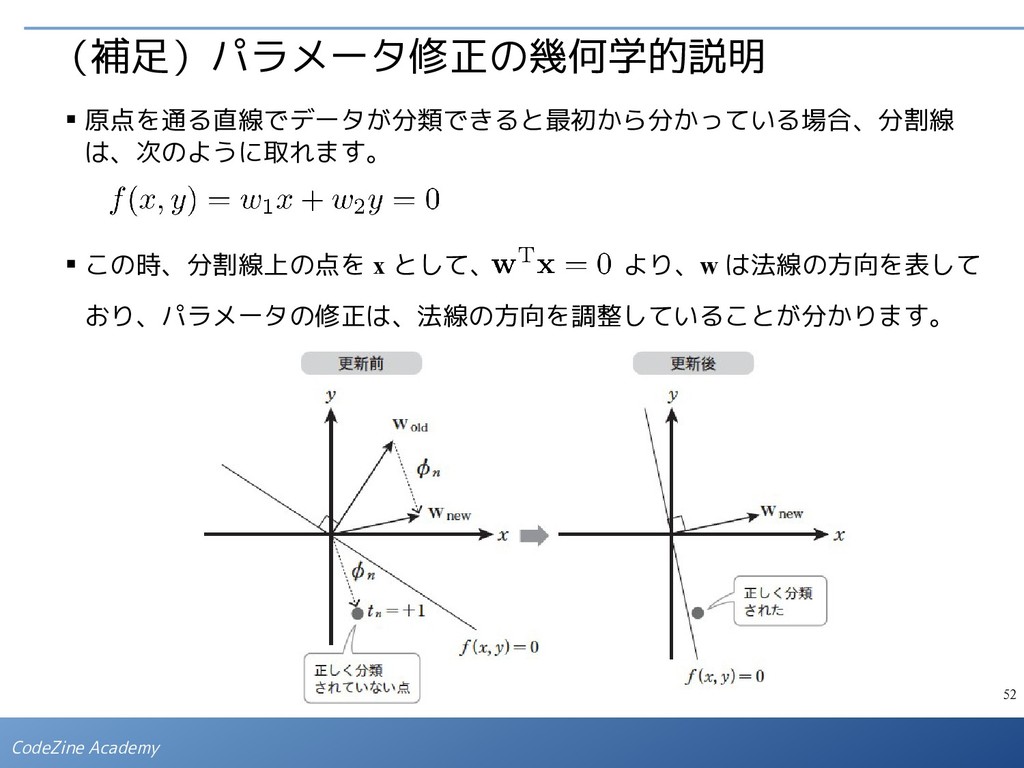
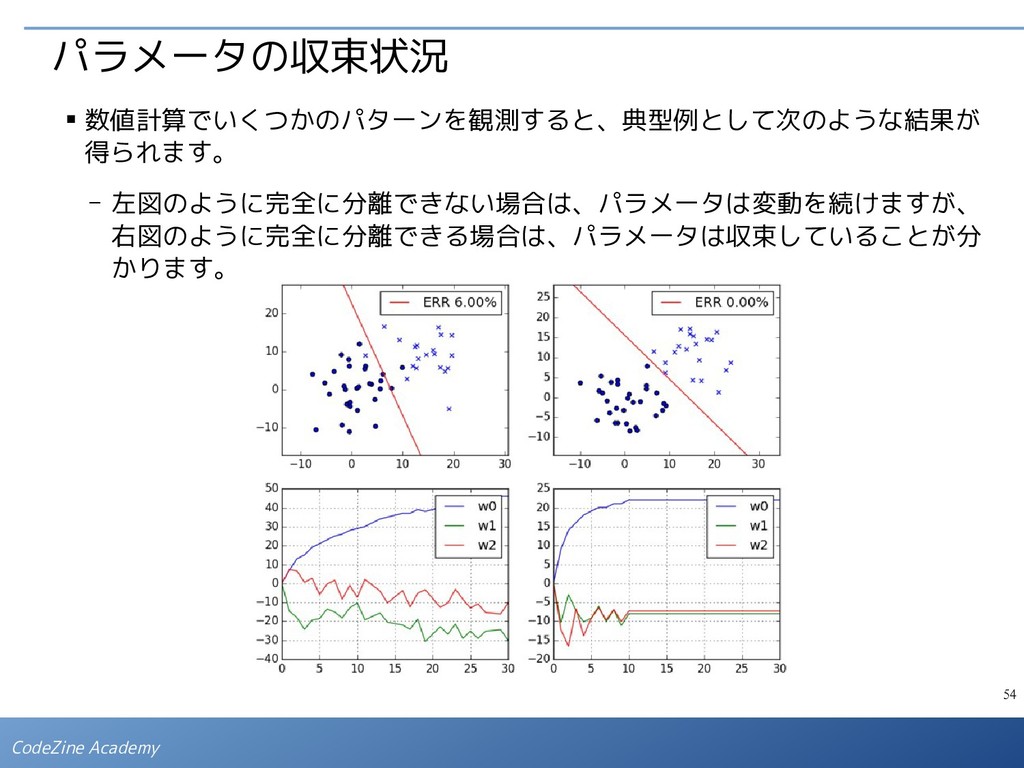
の値を減らす方向のベクトルは、この関数の「勾 配」で決まります。 ▪ これは、「ある w において、誤って判定された点 があった場合、 ベクトル の方向に w を修正すると、E P (w) の値を減らすことができる」 と解釈できます。(直感的には。) ▪ 厳密に議論すると、誤って判定された点について、1つずつ順番に次の式で w の値を修正していくことを何度も繰り返すと、(完全な分割が可能な場合は) いつかは正しい分割線が得られることが証明されています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
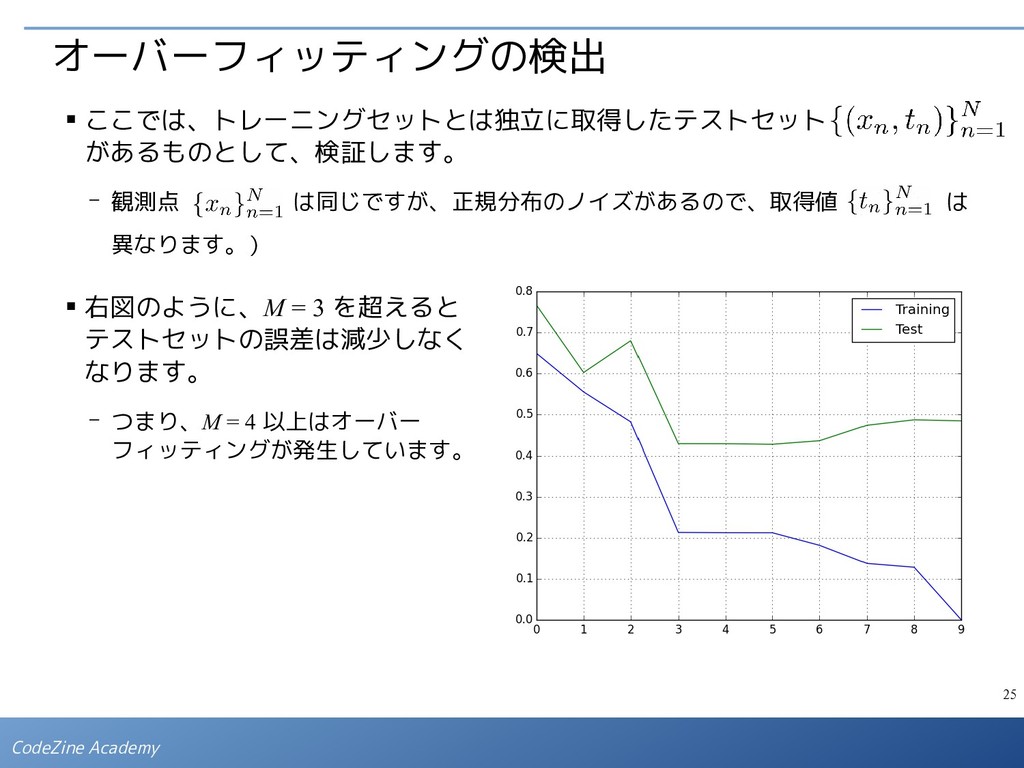{kind=link}
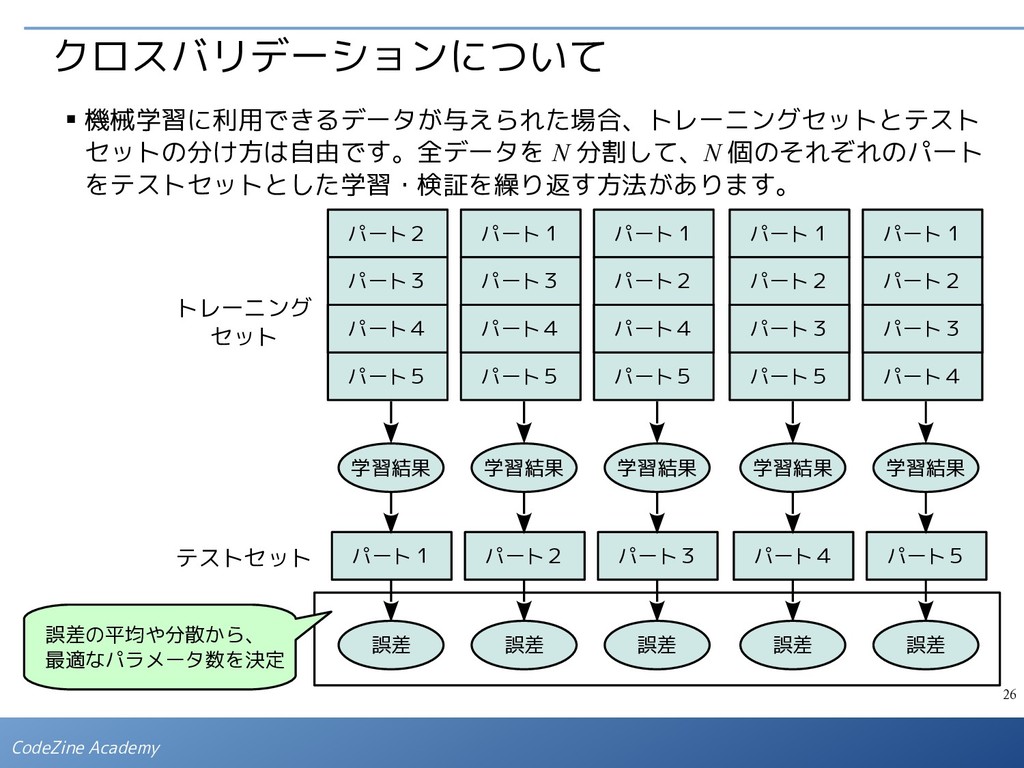{kind=link}
{kind=link}
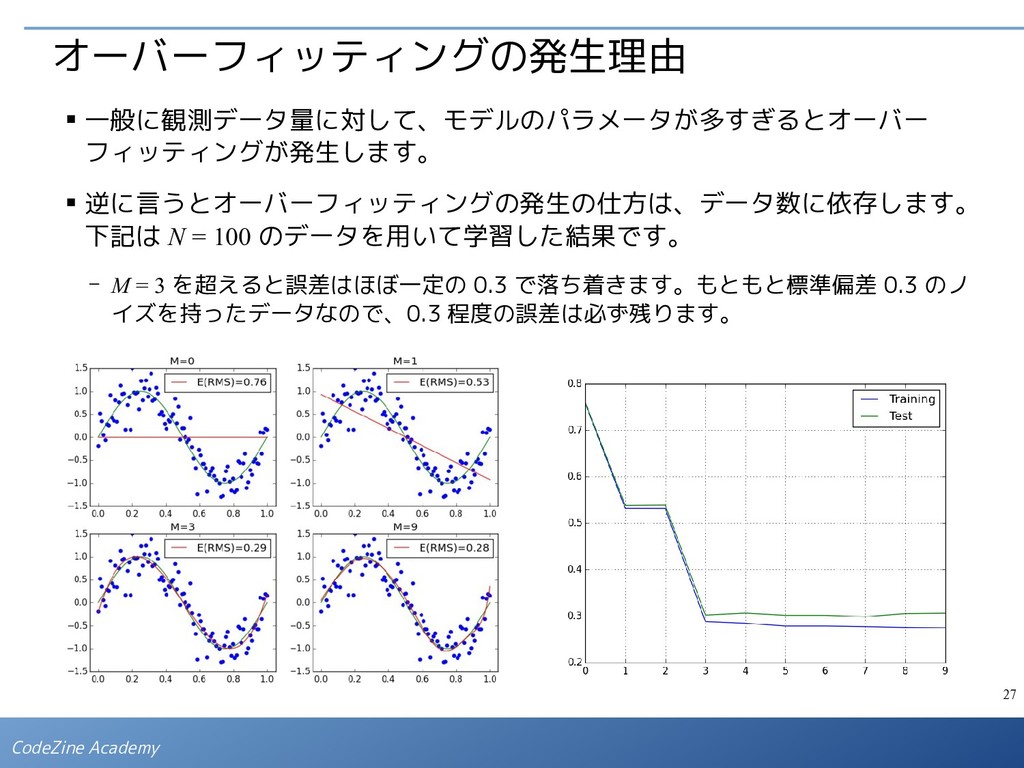
{kind=link}
{kind=link}
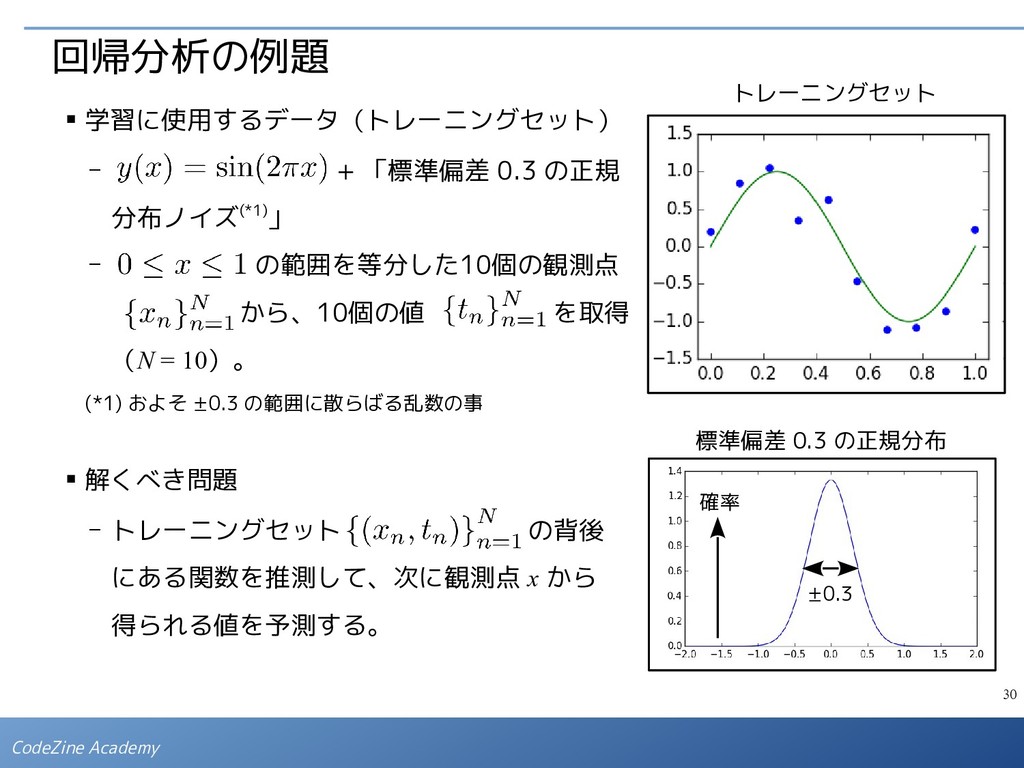{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}