Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Reinforcement Learning Second edition - Notes o...
Search
Etsuji Nakai
November 18, 2019
Technology
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Reinforcement Learning Second edition - Notes on Chapter 4
Etsuji Nakai
November 18, 2019
More Decks by Etsuji Nakai
See All by Etsuji Nakai
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
800
Agent Development Kit によるエージェント開発入門
enakai00
23
9.1k
GDG Tokyo 生成 AI 論文をわいわい読む会
enakai00
1
690
Lecture course on Microservices : Part 1
enakai00
1
3.8k
Lecture course on Microservices : Part 2
enakai00
2
3.7k
Lecture course on Microservices : Part 3
enakai00
1
3.7k
Lecture course on Microservices : Part 4
enakai00
1
3.7k
JAX / Flax 入門
enakai00
1
1.5k
生成 AI の基礎 〜 サンプル実装で学ぶ基本原理
enakai00
7
4.4k
Other Decks in Technology
See All in Technology
Network Firewallやっていき!
news_it_enj
0
160
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
820
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
310
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
260
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.5k
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
360
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
3.1k
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
410
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
AI時代の闇と光
tatsuya1970
0
110
SRE Next 2026 何でも屋からの脱却
bto
0
910
Featured
See All Featured
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Skip the Path - Find Your Career Trail
mkilby
1
170
Mind Mapping
helmedeiros
PRO
1
280
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
The Language of Interfaces
destraynor
162
27k
Transcript
Reinforcement Learning Second edition - Notes on Chapter 4 Etsuji
Nakai (@enakai00)
Policy Iteration (ポリシーの改善ステップ) 2 ※ ここでは、 は既知とする。 ・任意のポリシー を1つ選択する ・Value function
を(何らかの方法で)計算する ・Action-Value function が決まる ・Greedy ポリシー ( が最大の a を確率 1 で選択する) この時、任意の s について が成り立つ。 つまり、π' は、π よりも優れたポリシーと言える。この改善処理を繰り返す。 この方法は 次ページで説明
Bellman Equation の右辺を用いて、左辺を漸化的にアップデートしていくと、最終的に両辺が等しくなる。 Policy Evaluation 3
Policy Iteration の課題:計算が長い! 4 全状態についての ループを・・・ 収束するまで 何度も繰り返す ポリシーの更新も 状態数×アクション数
回のループが必要
改善案 5 • Value Function を真面目に収束するまで計算しても、次のステップで Policy が更新される と、そこからまた再更新が必要。収束する手前で、早めに打ち切ってもよくない? •
Policy 更新のために全状態をループするのと、Value Function の計算のために全状態をルー プするの、別々にやるのってもったいなくない? Value Function の計算ループの中に、Policy の更新も埋め込んでしまえ! ⇨ Value Iteration
Value Iteration 6 実質的に Greedy Policy を更新・適用している
Value Iteration 7 更新済みの Policy を適用 https://github.com/enakai00/rl_book_solutions/blob/master/Chapter04/Exercise_4_7_(Value_Iteration)_part1.ipynb
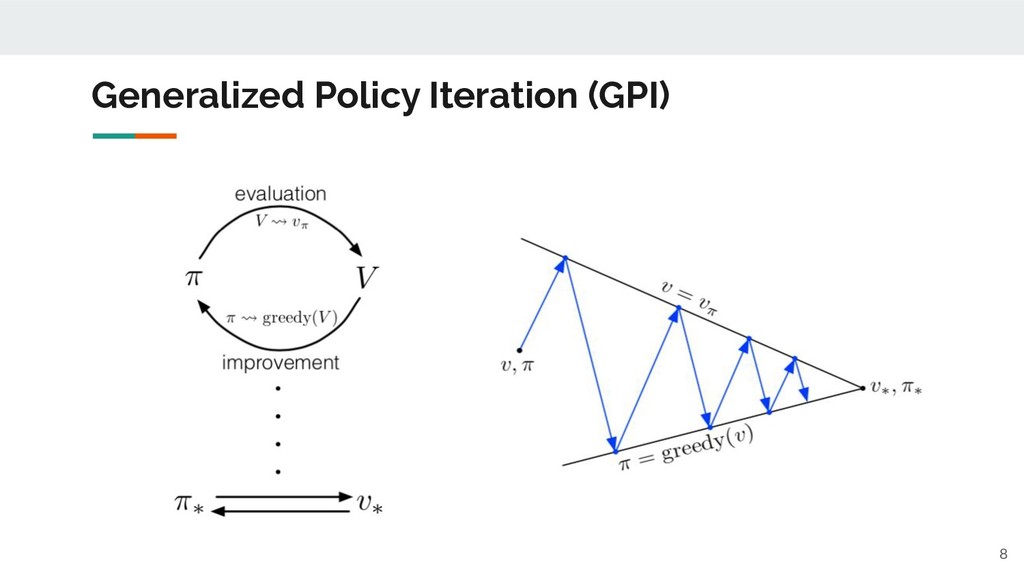
Generalized Policy Iteration (GPI) 8
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}