and machine learning Graduate Student, Data Science The George Washington University • Cognitive Engineer Consultant Intern - Worked with the New York State Government • Graduate Teaching Assistant (Natural Language Processing) - Assist students and grade assignments/exams • Hiking/exploring nature • Playing the piano Favorite way to pass time @eemuraye linkedin.com/in/eserichard
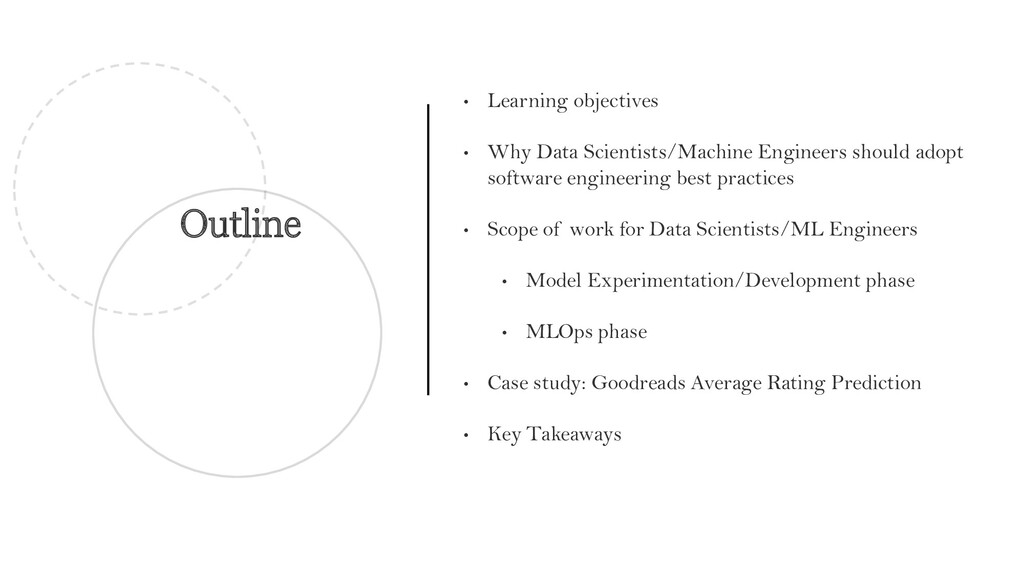
adopt software engineering best practices • Scope of work for Data Scientists/ML Engineers • Model Experimentation/Development phase • MLOps phase • Case study: Goodreads Average Rating Prediction • Key Takeaways
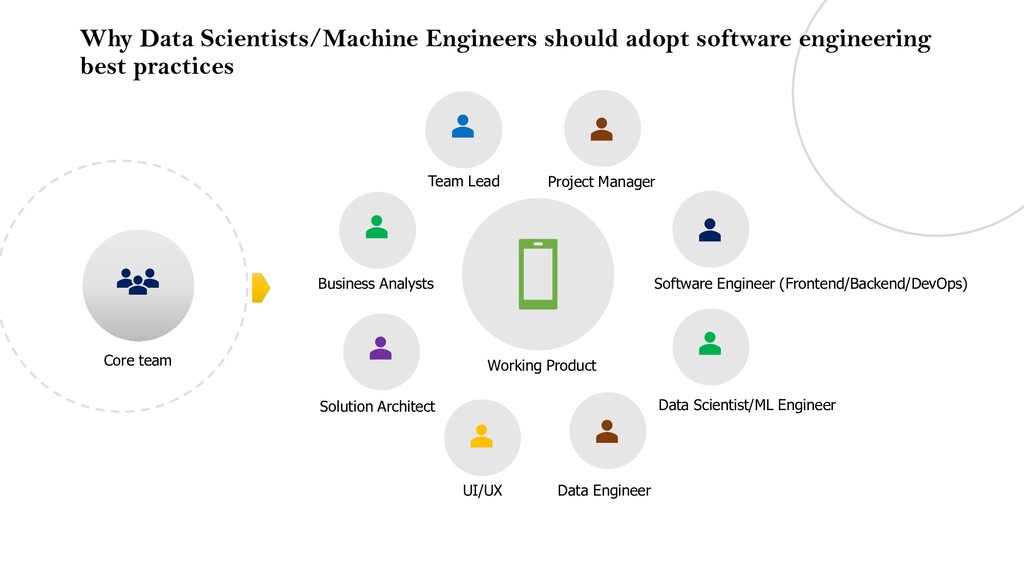
Core team UI/UX Data Engineer Data Scientist/ML Engineer Software Engineer (Frontend/Backend/DevOps) Project Manager Team Lead Business Analysts Solution Architect Working Product
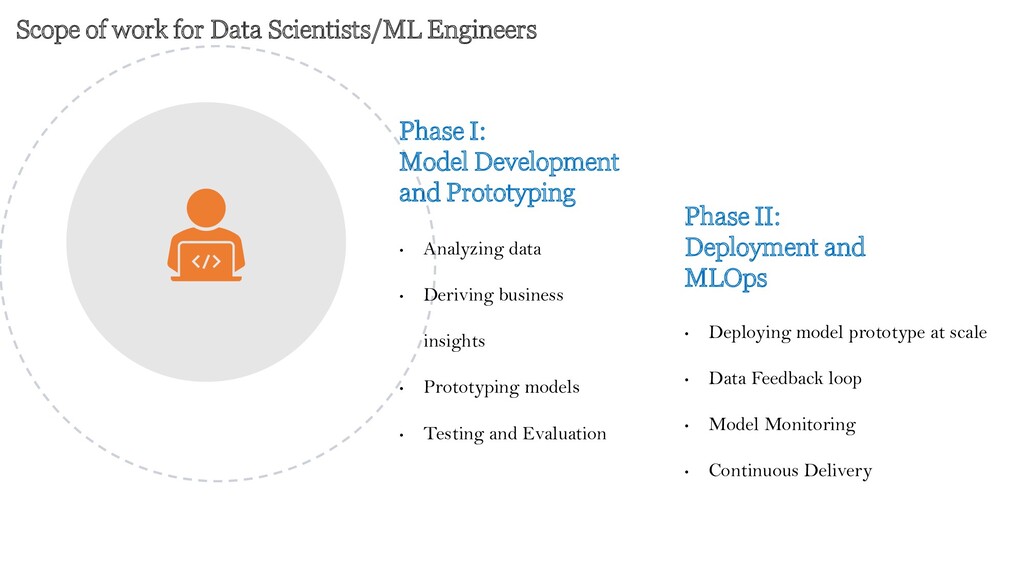
MLOps • Deploying model prototype at scale • Data Feedback loop • Model Monitoring • Continuous Delivery • Analyzing data • Deriving business insights • Prototyping models • Testing and Evaluation Scope of work for Data Scientists/ML Engineers
Proper versioning • Good dependency management • Efficient testing • Efficient CI/CD implementation Essential software engineering best practices for Data Scientists/ML Engineers Objective: To write clean, stable, reusable code that can be maintained for years and is easily scalable
pylint, yapf, pep8), Google Style Guide • Naming conventions • Classes, variables and parameters should be nouns • Methods should be verbs • Avoid abbreviations except it is universally known • Methods • Should be an easily described functionality • Should be reusable throughout the project • Should handle a single thing • Should provide a useful output • Classes/Objects • Avoid unrelated functionality in your class (SOLID) – Single Responsibility Principle • Use functions for functionality unrelated to any object/class
of the class • Docstring for constructor method and for each method in the class • Methods and functions • Brief description of the functionality • Description of the arguments, with type and default value • Description of outputs, with their type • Description of error/exception with reasons NB: Splinx can be used to auto-generate HTML-based documentation for consumers/users of API • Repository/Component level documentation • The readme.md should contain the purpose of the respository/component and how to use it
anywhere and stable overtime across environments • Pip is the most popular dependency manager for python • Use requirements.txt file to record all project dependencies so others can install them easily. The exact version of the package should be specified alongside • While pip is the common dependency manager, poetry is becoming widespread because of its simplicity. [auto creates a virtual env, adds/removes packages from pyproject.toml, akin to requirements.txt for pip] • Config files should be .env or .json
+ model • Source code versioning: version control e.g. git. • Data versioning: Data Versioning Control (DVC) or MLflow • Model Versioning: MLflow • NB: Use .gitignore to exclude files which are not relevant to the project (e.g. IDE configuration) • Cloud solutions have self-managed services that handle code, data and model versioning
software to validate that the tested unit meets design specification • Integration testing: Involves testing the combined individual units of a software as a unit/group • System testing: Involves end-to-end testing of system specifications • Monitoring: Drift testing, Seam testing (unit testing our data inputs and outputs to ensure model lies within tolerance)
and automated testing is initiated as soon as code is merged • CD begins if all tests passes • Continuous Deployment • Deploys changes automatically to production • Trained model is served as a prediction service for predictions • Monitoring: Track summary statistics of the live data and monitor online performance of your model to send triggers or rollback to previous version when values deviate from expectations • CI/CD is implemented to automatically build, test and safely deploy your application, so you can iterate quickly when developing new software.
social cataloging website that allows individuals to search freely its database of books, annotations, quotes, and reviews. About Goodreads This project involves the use of book features from the goodreads datasets to predict the average rating of a book. The average rating of a book ranges from 1 to 5. Several features from the books datasets and generated features have been explored to carry out a classification task Scope
team with other engineers and managers to deliver a complete solution • Data Scientists/Machine Learning Engineers should be able to write clean, reusable code that can be maintained for a long time and can scale easily
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}