Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Local Models for Coding
Search
Eugene Oskin
May 18, 2026
Programming
16
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Local Models for Coding
Eugene Oskin
May 18, 2026
More Decks by Eugene Oskin
See All by Eugene Oskin
REST API. Django, Ruby on Rails, Play! Framework
evgeneoskin
0
100
Introduction to gRPC
evgeneoskin
0
110
GrailInventory – Advanced Backend Development
evgeneoskin
0
48
Bracing Calculator
evgeneoskin
1
76
emotional intelligence, part 2
evgeneoskin
0
49
Office temperature
evgeneoskin
0
45
Parse platform
evgeneoskin
0
110
Hubot
evgeneoskin
0
61
An introduction to iOS development
evgeneoskin
0
55
Other Decks in Programming
See All in Programming
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
240
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
160
TSKaigi Night Talks 2026_TypeScriptでサプライチェーンの整合性を型に閉じ込める
geekplus_tech
0
440
Webフレームワークの ベンチマークについて
yusukebe
0
200
どこまでゆるくて許されるのか
tk3fftk
0
460
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
480
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
190
Skillsは効率化、Agentsは"自分の拡張"——Builder時代のエージェント編成(CC Night 2026)
wemra
1
200
symfony/aiとlaravel/boost
77web
0
120
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
840
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
810
Go1.27で導入されるジェネリクスメソッドでできること
mackee
0
260
Featured
See All Featured
Designing for Timeless Needs
cassininazir
1
280
Building Adaptive Systems
keathley
44
3.1k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Done Done
chrislema
186
16k
The Curse of the Amulet
leimatthew05
2
13k
GitHub's CSS Performance
jonrohan
1033
470k
First, design no harm
axbom
PRO
2
1.2k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Building Applications with DynamoDB
mza
96
7.1k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Transcript
Local Models for Coding 1
Who am I • Local AI enthusiast running local models
on my MacBook • Building iowise.dev • ex-CTO of Termius SSH Client • 14 years working in software • Building backend, frontend, iOS, Android, and embedded
Running Models 3
OPENAI_API_BASE="https: / / chivalry - confront - untried.ngrok - free.dev:1234/v1"
OPENAI_API_KEY=lm - studio codex - - oss - - model qwopus3.6-35b - a3b - v1-mlx ANTHROPIC_BASE_URL="https: / / chivalry - confront - untried.ngrok - free.dev:1234/v1" ANTHROPIC_AUTH_TOKEN=lm - studio ANTHROPIC_API_KEY="" claude - - model qwopus3.6-35b - a3b - v1-mlx Connect Your Agent • Add model: qwopus3.6-35b-a3b-v1-mlx • Add OpenAI API key: lm-studio • Add OpenAI URL: https://chivalry-confront-untried.ngrok-free.dev:1234/v1 4
Terms • Model • Dense vs MoE • Agents •
Quantization • KV Cache • Inference engines • Prefill • Distillation • Speculations
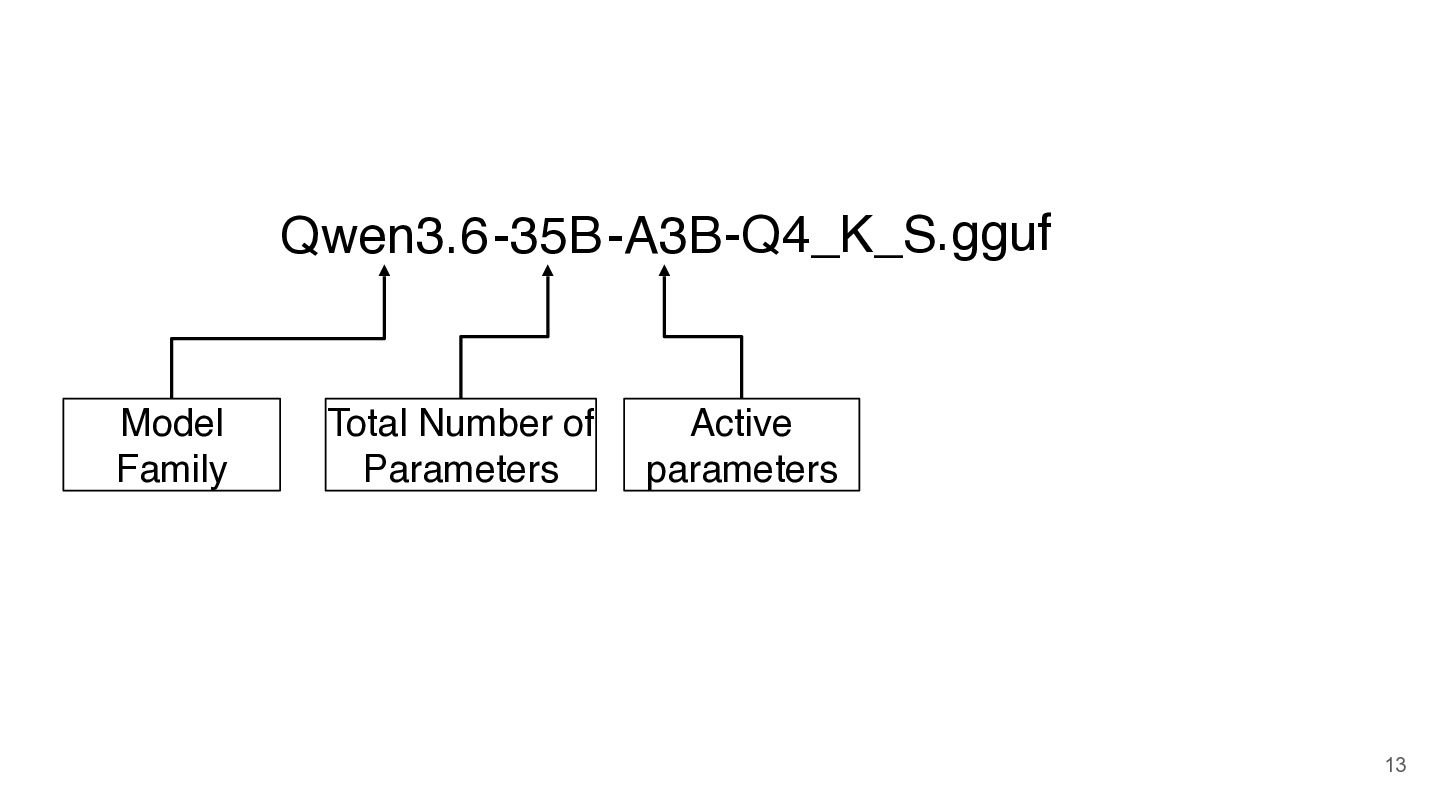
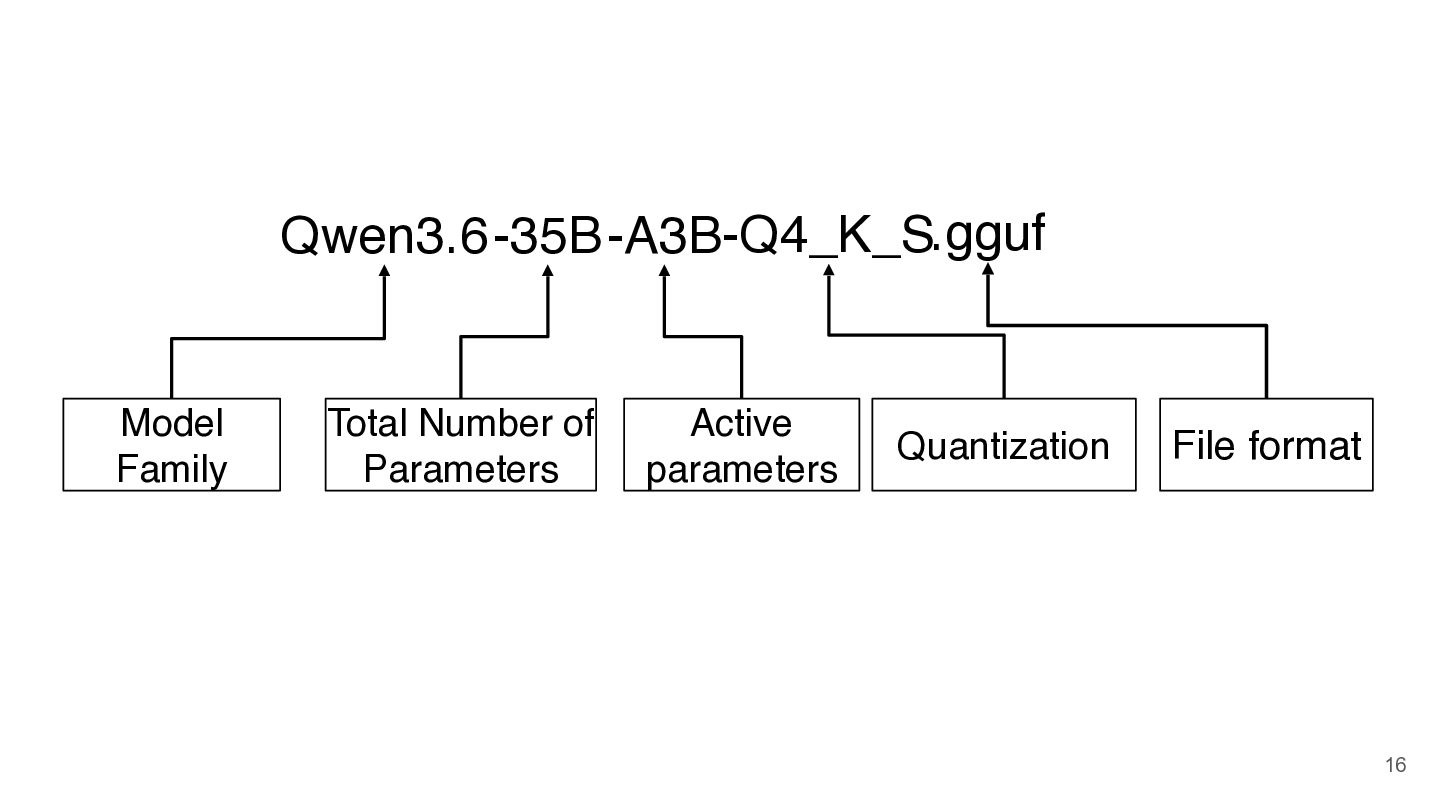
-A3B -35B Model Names Qwen3.6 Model Family Total Number of
Parameters -Q4_K_S.gguf 6
Models • Qwen 3.x • Nemotron 3 • Gemma 4
• Fine-tuned
Where Models Live huggingface.co 🤗 8
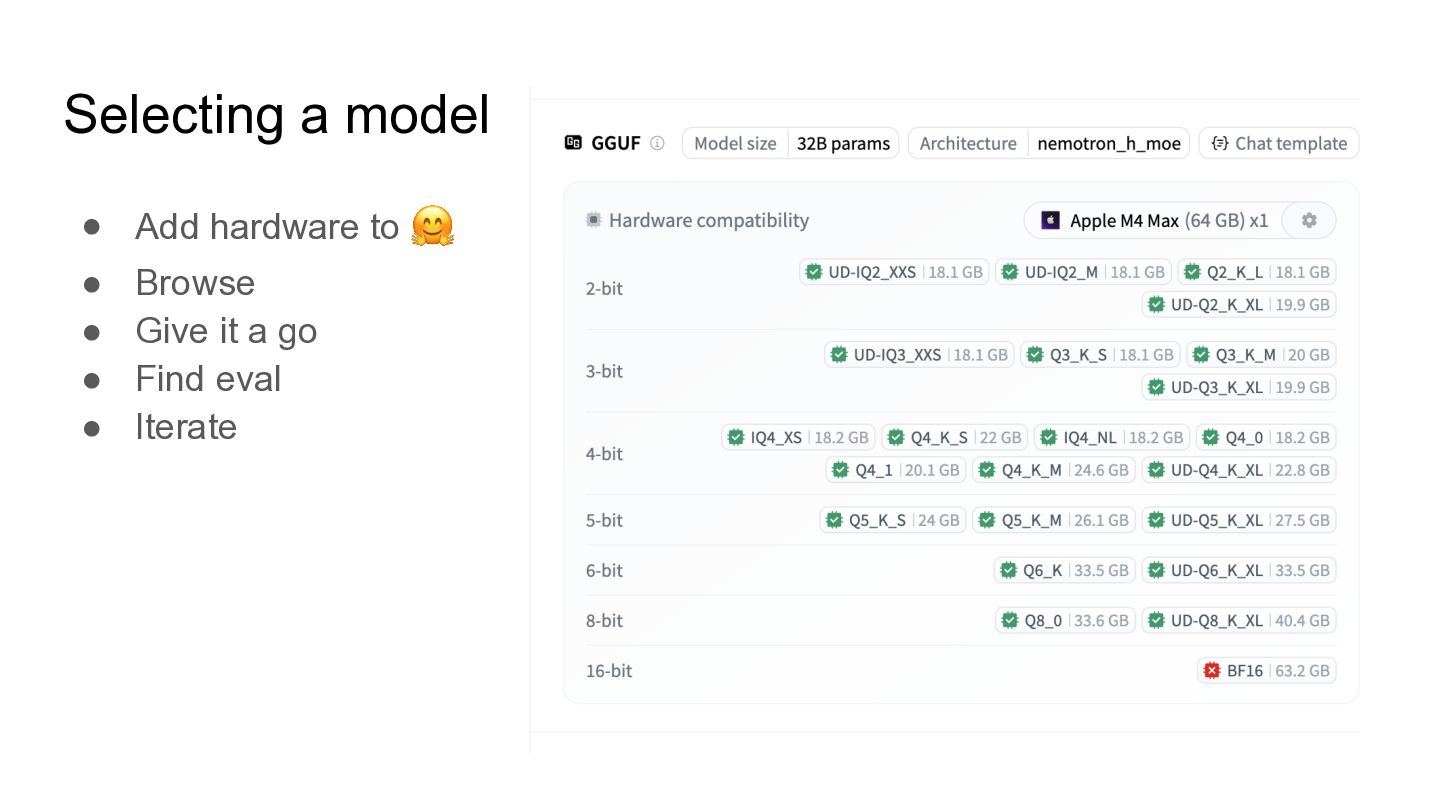
Selecting a model • Add hardware to 🤗 • Browse
• Give it a go • Find eval • Iterate
How to run a model • LM Studio – https://lmstudio.ai/
• Ollama – https://ollama.com/ • Llama.cpp – the cutting edge of inference
Memory Math Total memory ≈ parameters × bytes/parameter + 2
× num_layers × num_kv_heads × head_dim × seq_len × batch_size × bytes/element + runtime overhead
Memory Math Total memory ≈ parameters × bytes/parameter + 2
× num_layers × num_kv_heads × head_dim × seq_len × batch_size × bytes/element + runtime overhead Start simple with LM Studio model loading Guardrails
-A3B -35B Qwen3.6 Model Family Total Number of Parameters -Q4_K_S.gguf
Active parameters 13
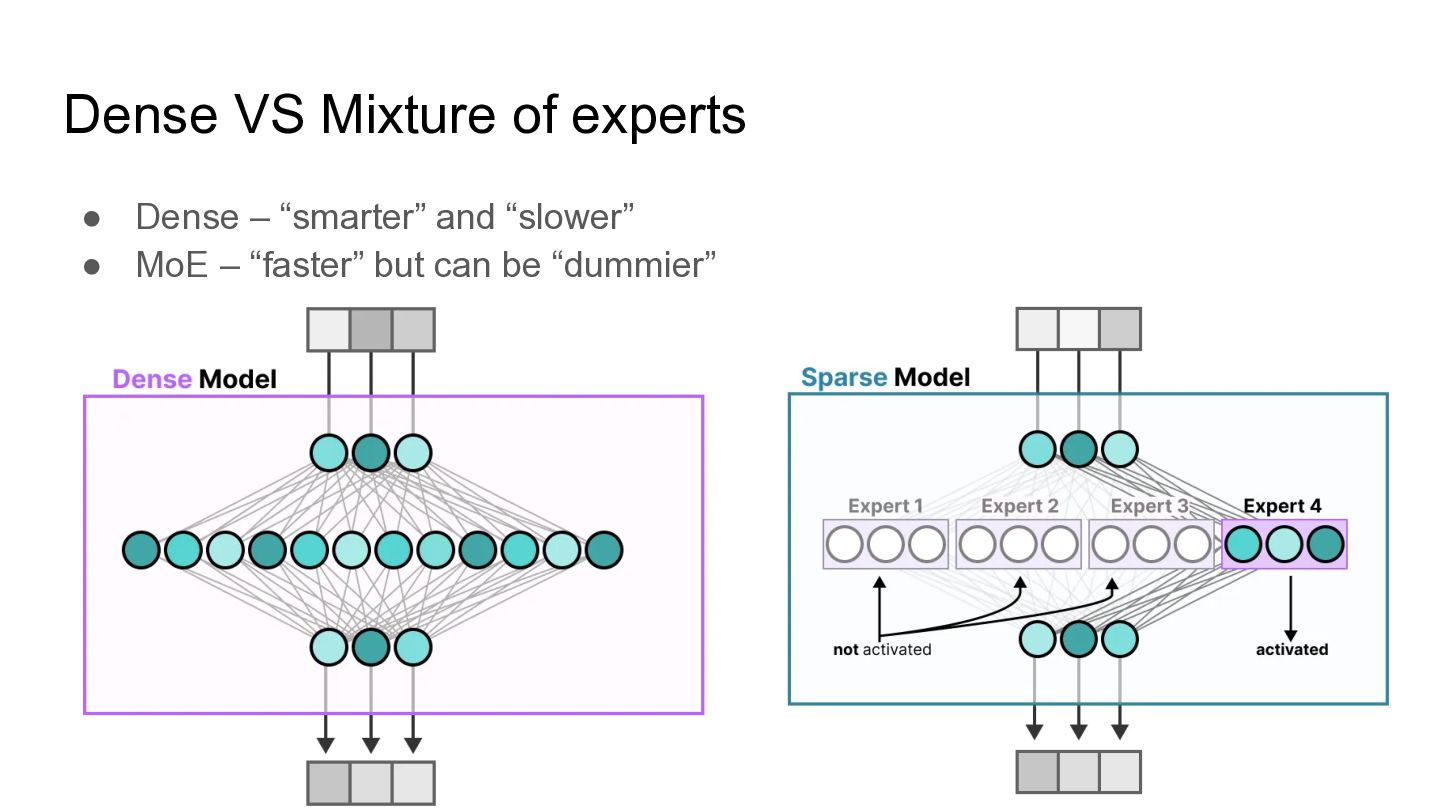
Dense VS Mixture of experts • Dense – “smarter” and
“slower” • MoE – “faster” but can be “dummier”
Faster Inference 15
-A3B -35B Qwen3.6 Model Family Total Number of Parameters -Q4_K_S.gguf
Active parameters Quantization File format 16
Quantization • F32 – original • F16 – 2x smaller
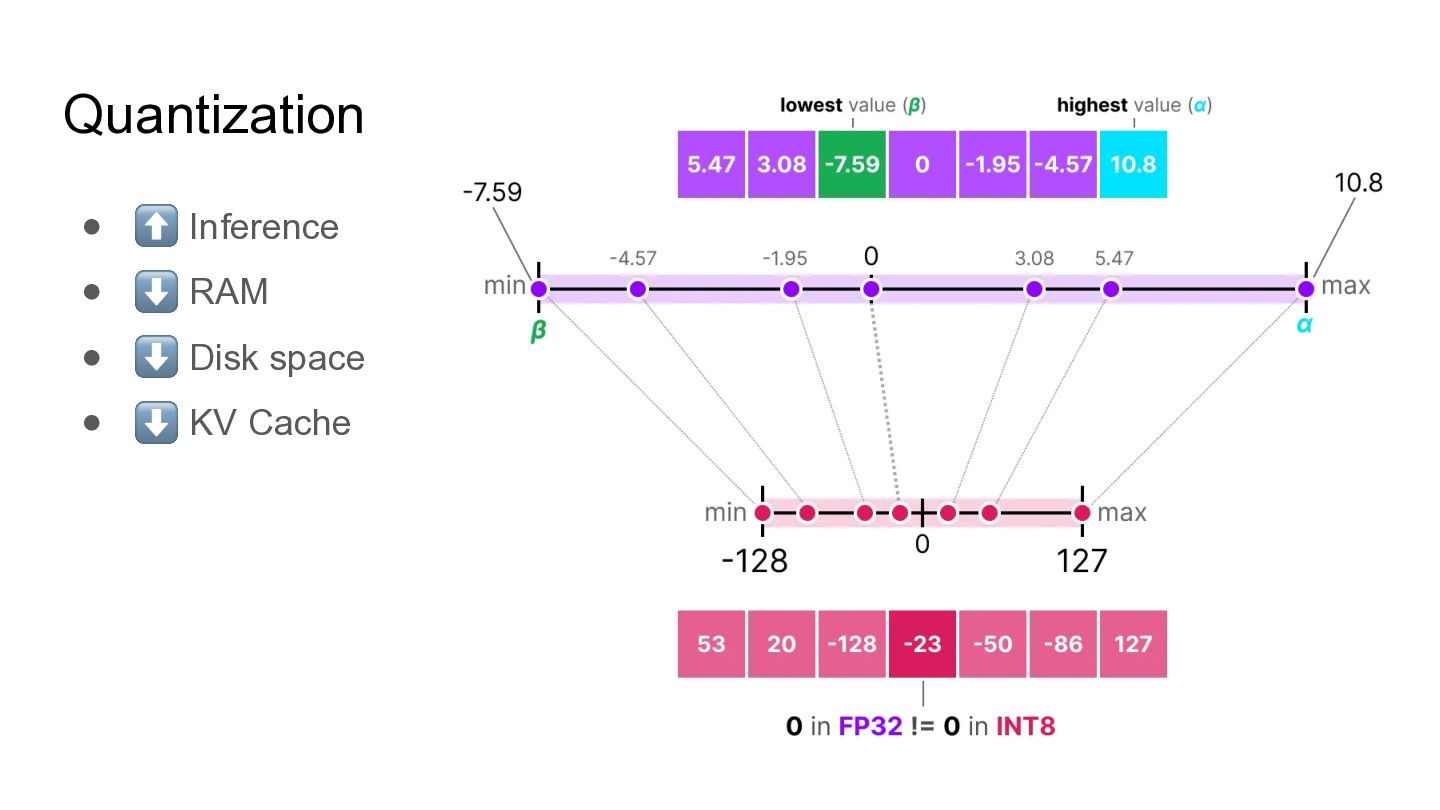
• Q8_0 – 4x smaller, similar quality • Q6_K • Q5_K_S, Q5_K_M, etc • Q4_K_S, Q4_K_M, etc – 8x smaller, the edge of quality • Q3_K_S, Q3_K_M, Q3_K_L, etc • Q2_K • 1-bit models
Quantization • ⬆ Inference • ⬇ RAM • ⬇ Disk
space • ⬇ KV Cache
Distillation • The original distillation requires full probability distribution of
output tokens • Modern distillation: training on synthetic data of a smart model
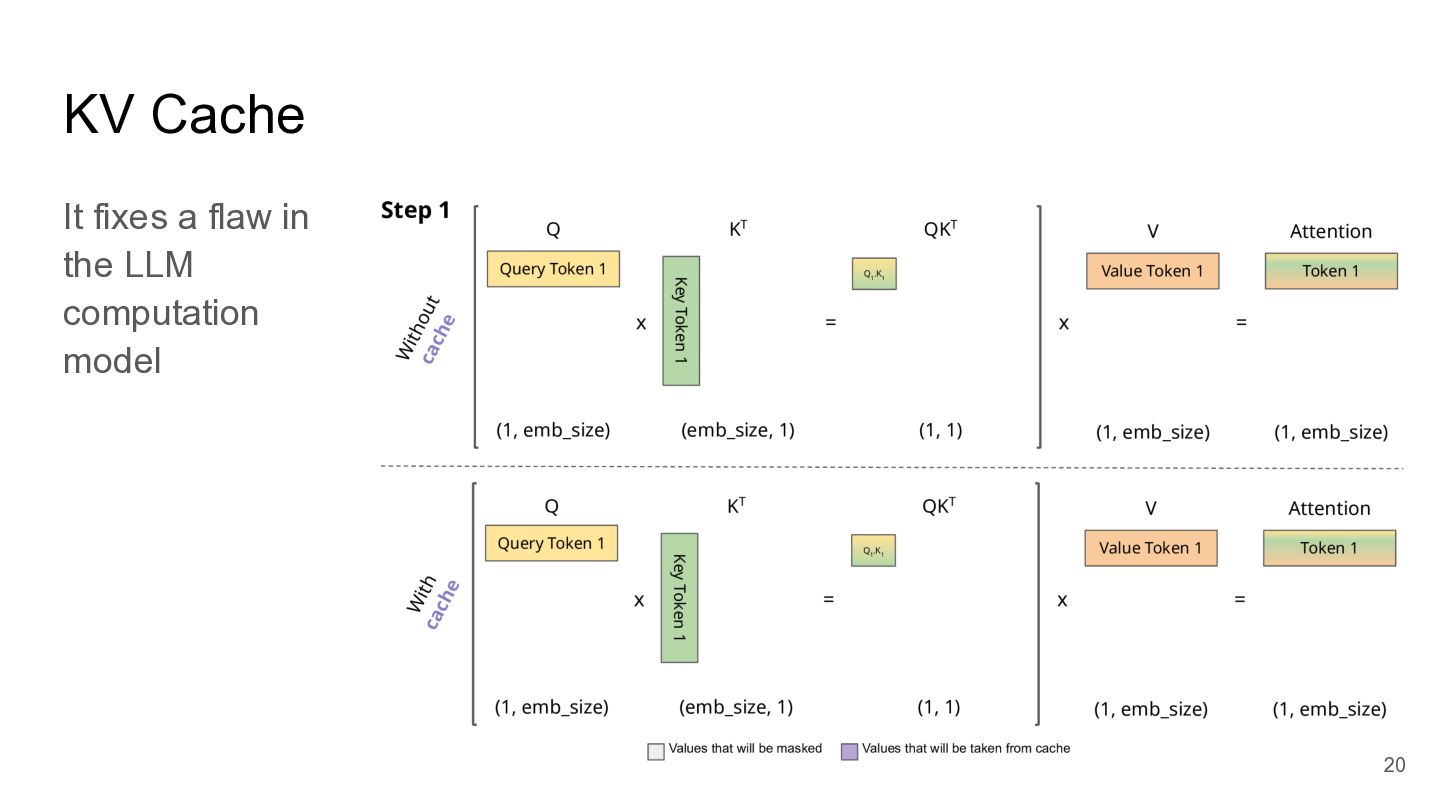
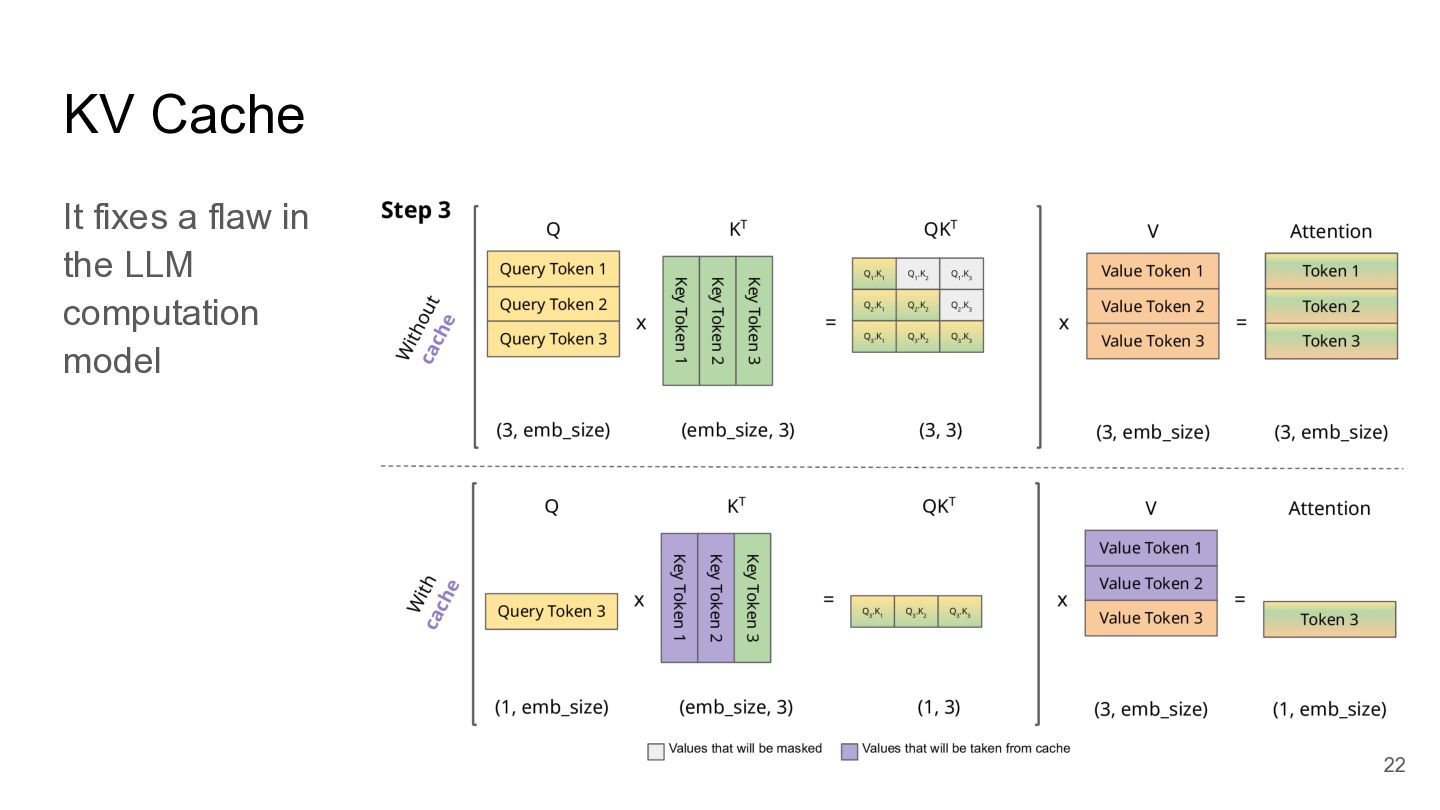
KV Cache It fixes a flaw in the LLM computation
model 20
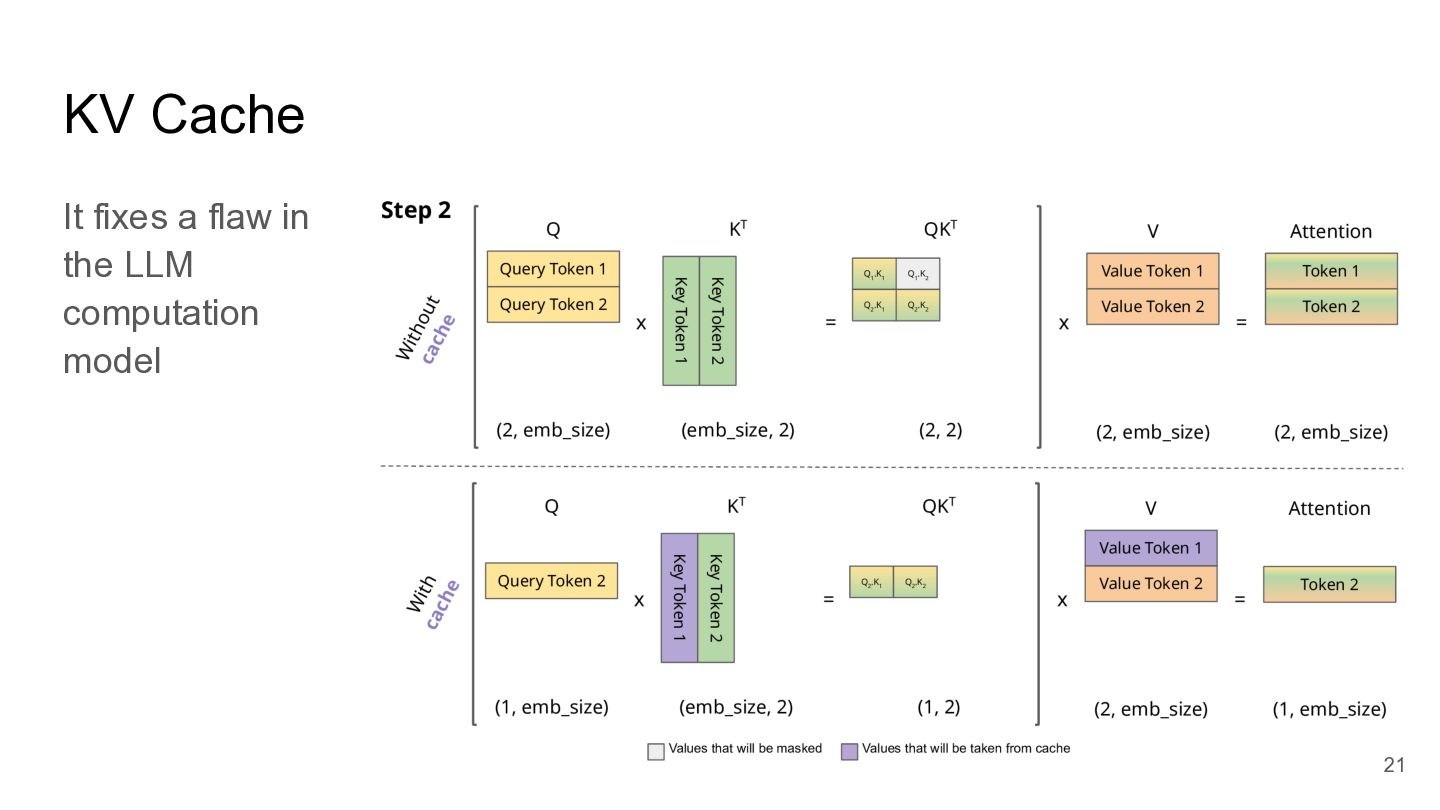
KV Cache It fixes a flaw in the LLM computation
model 21
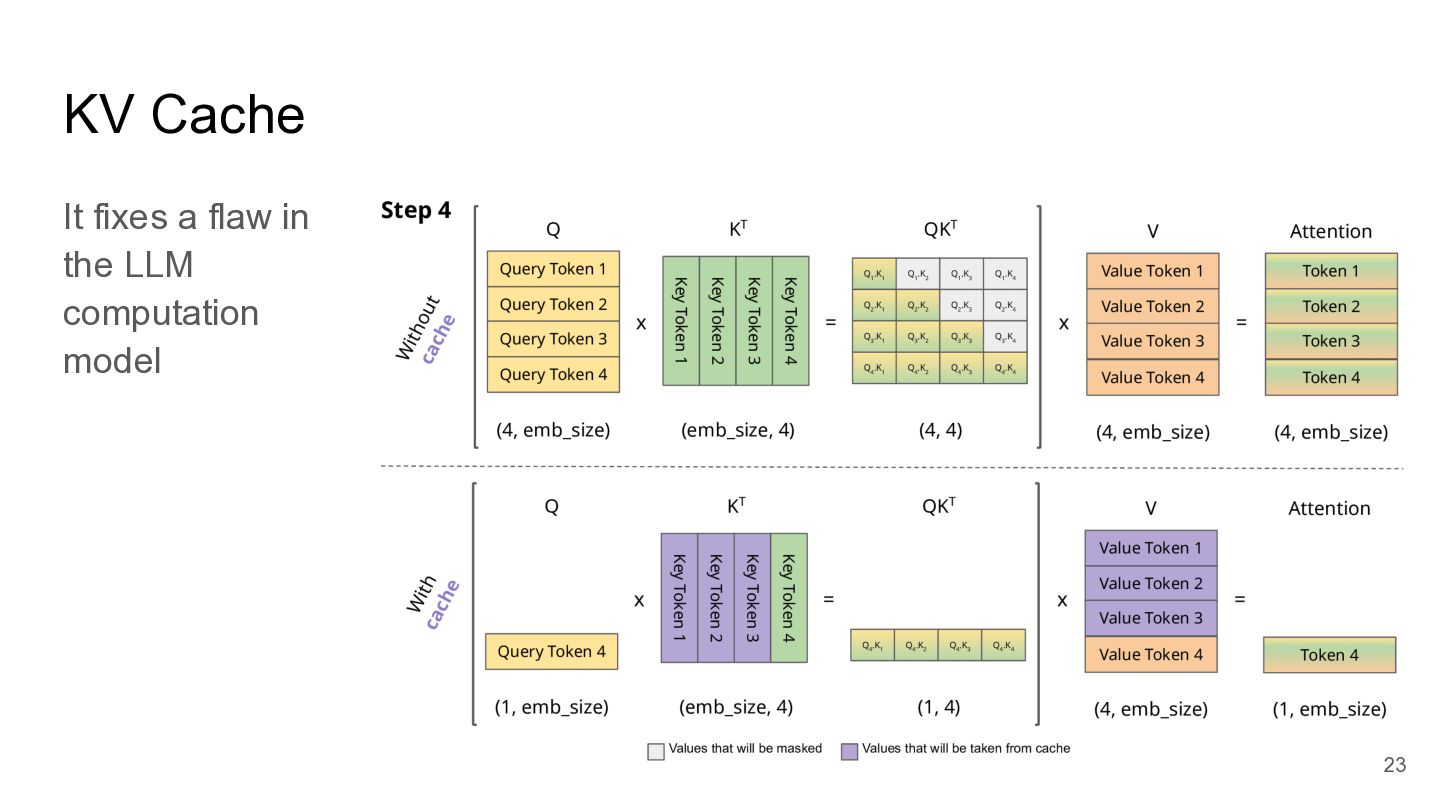
KV Cache It fixes a flaw in the LLM computation
model 22
KV Cache It fixes a flaw in the LLM computation
model 23
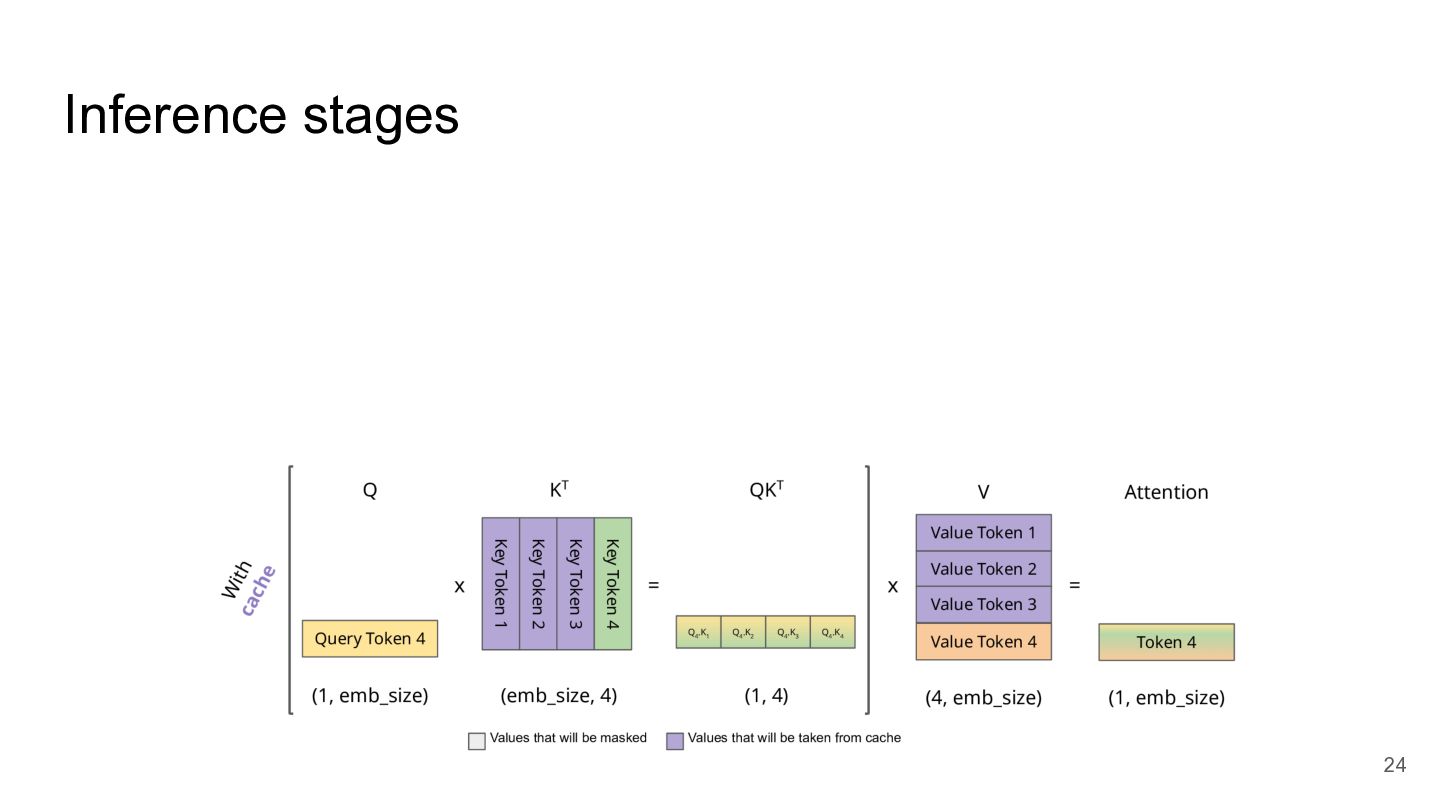
Inference stages 24
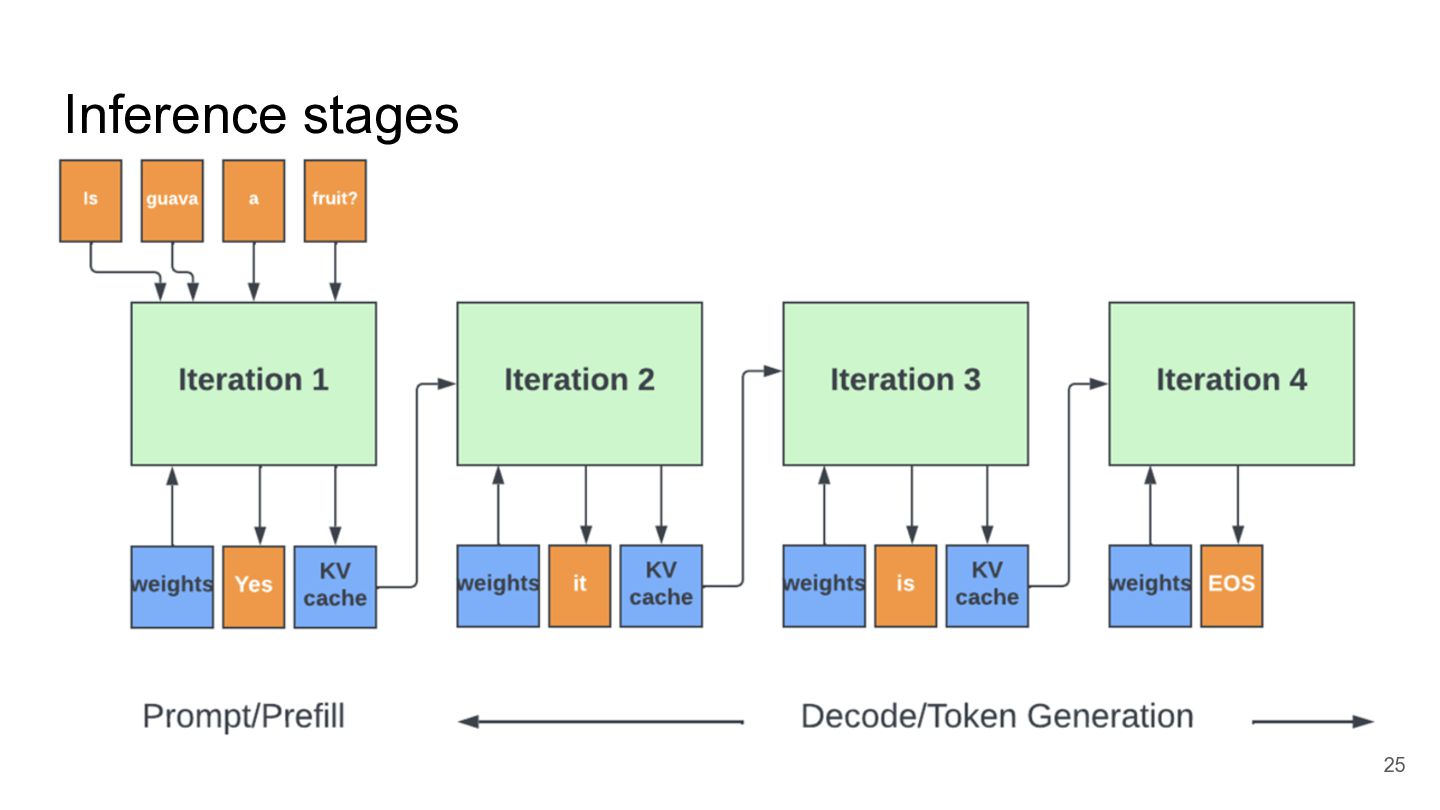
Inference stages 25
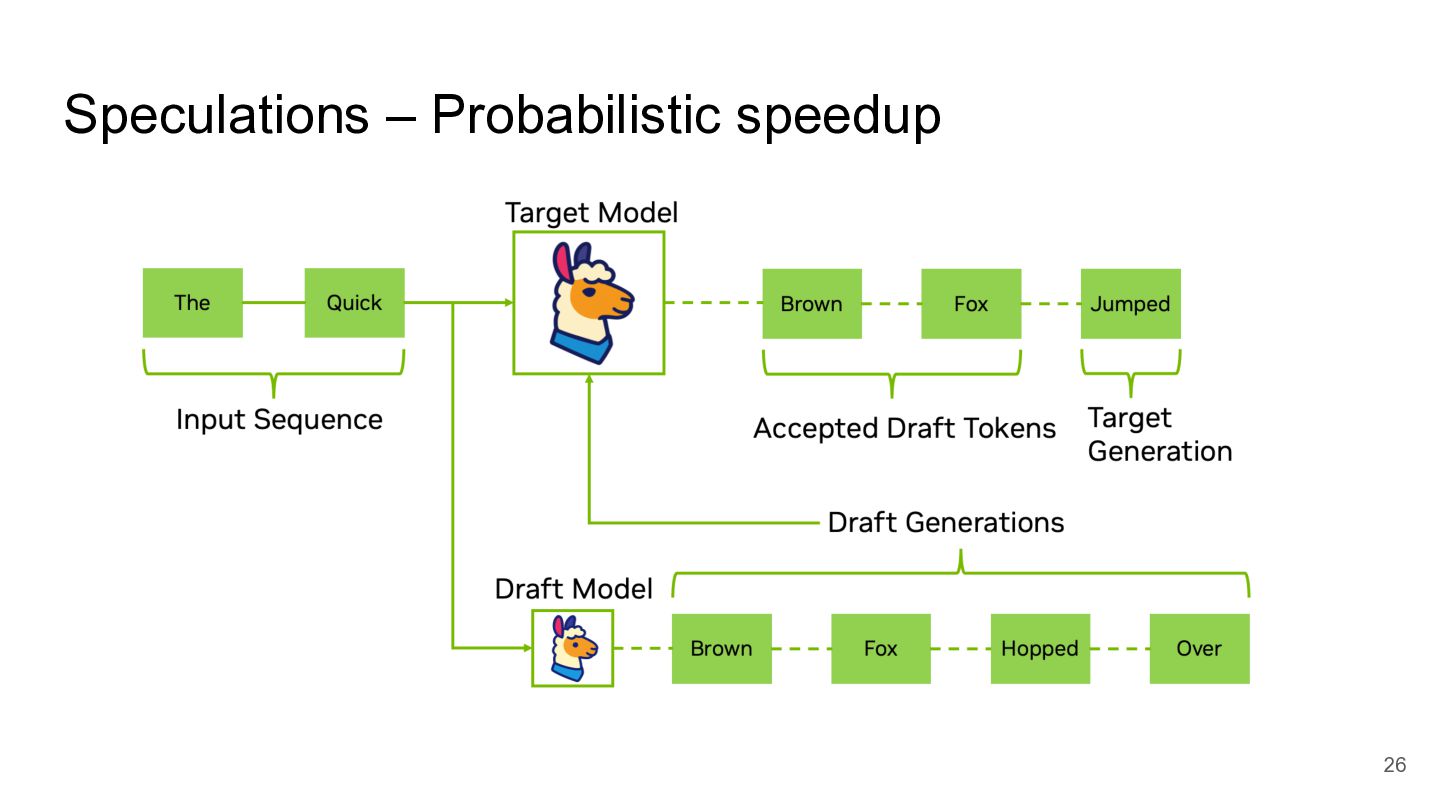
Speculations – Probabilistic speedup 26
Coding Agents • OpenCode • Pi • Goose • Hermes
Agent • OpenClaw • OpenAI Codex • Claude Code
Do you want to hear more? 28
Links • https://bbycroft.net/llm • https://hfviewer.com/Qwen/Qwen3.6-35B-A3B-FP8 • https://hfviewer.com/nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning- BF16 • http://hfviewer.com/nvidia/Nemotron-Cascade-2-30B-A3B
• https://huggingface.co/spaces/mlx-community/mlx-my-repo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}