O documento discute estratégias para alta concorrência no PostgreSQL, incluindo ajustes de hardware, sistema operacional e configuração do banco de dados para suportar milhares de conexões simultâneas e crescimento de dados de vários GB por dia. Ele também fornece dicas sobre modelagem de dados, tratamento de transações e consultas para melhor desempenho.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
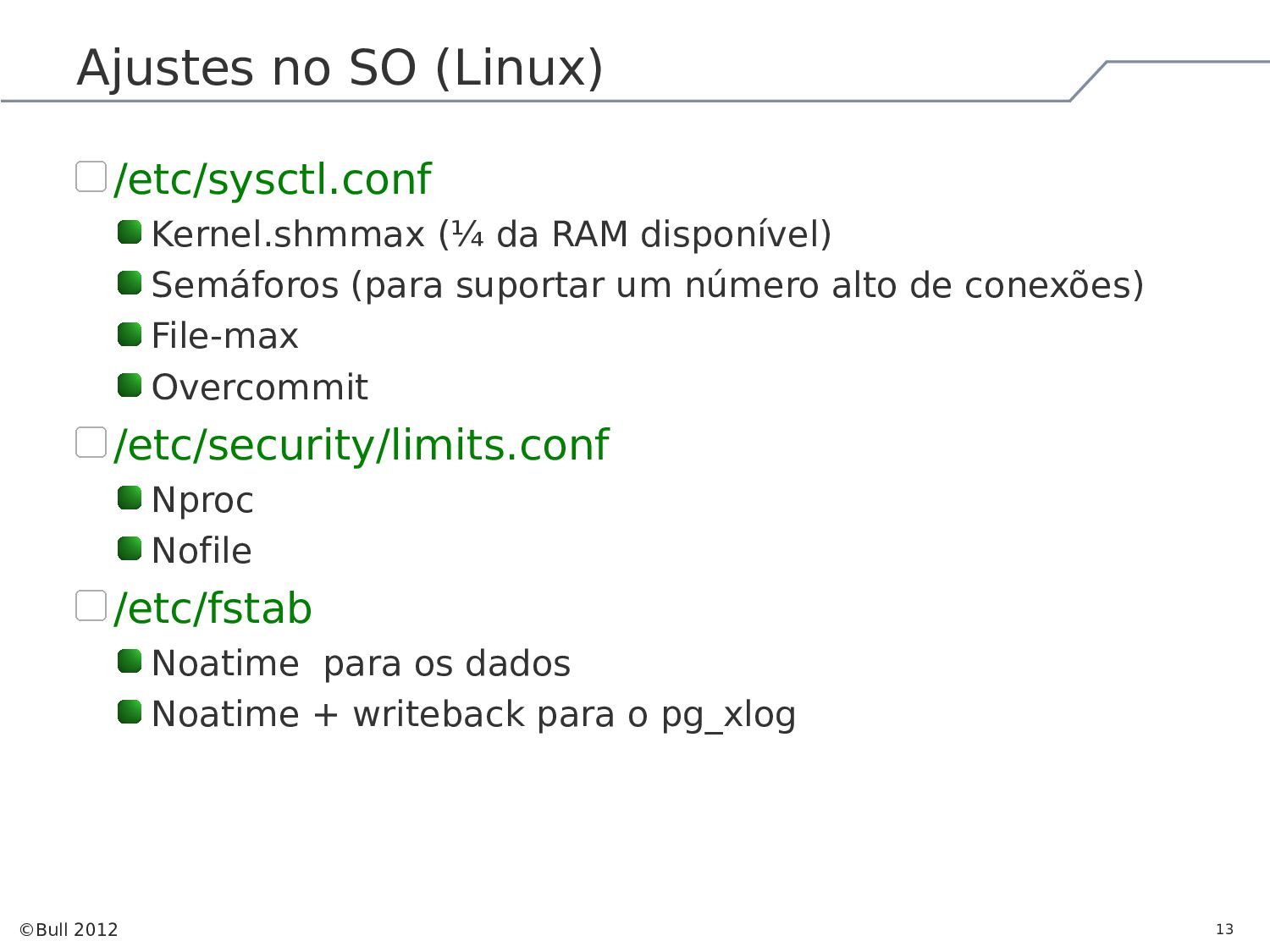{kind=link}
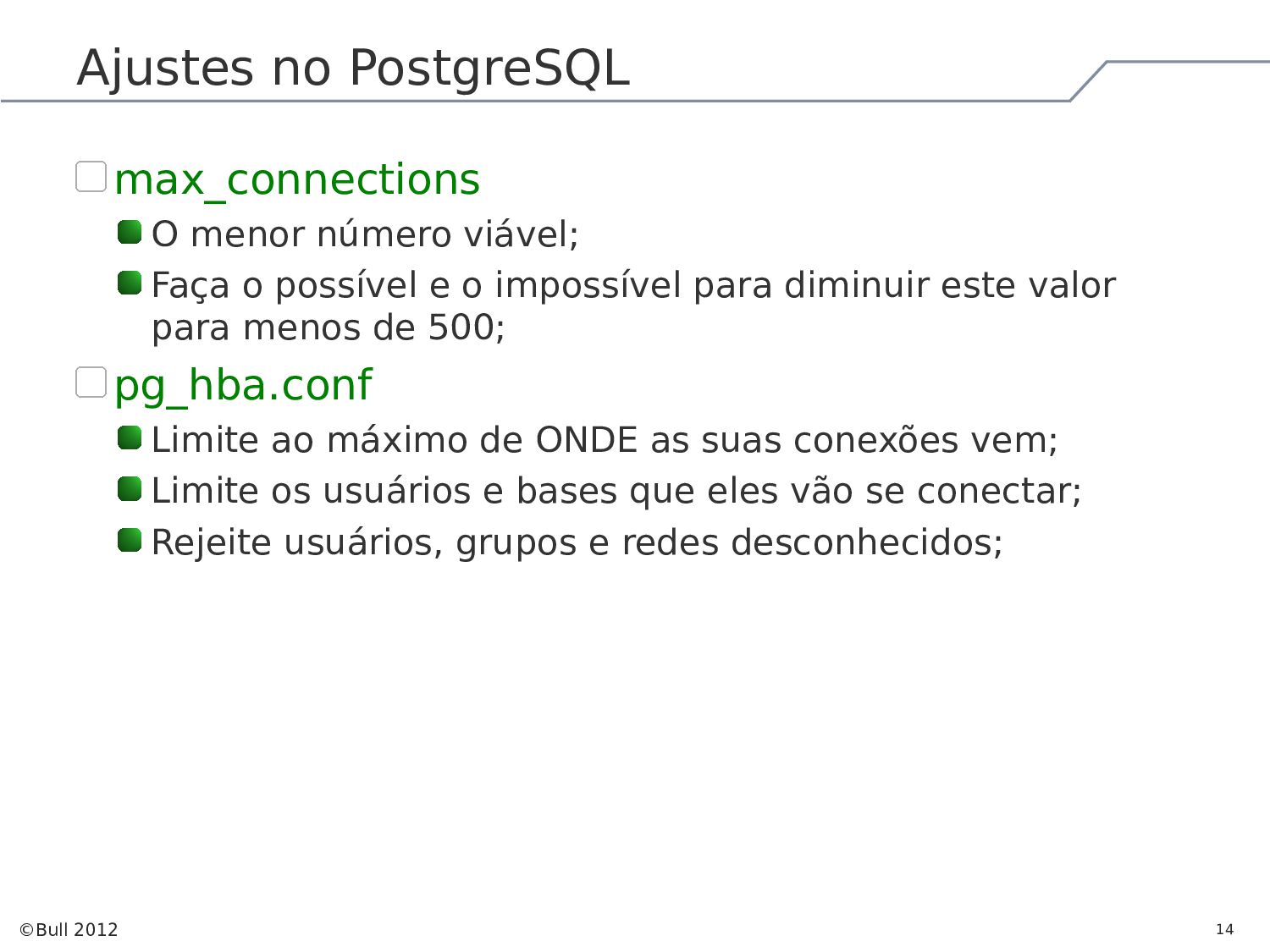{kind=link}
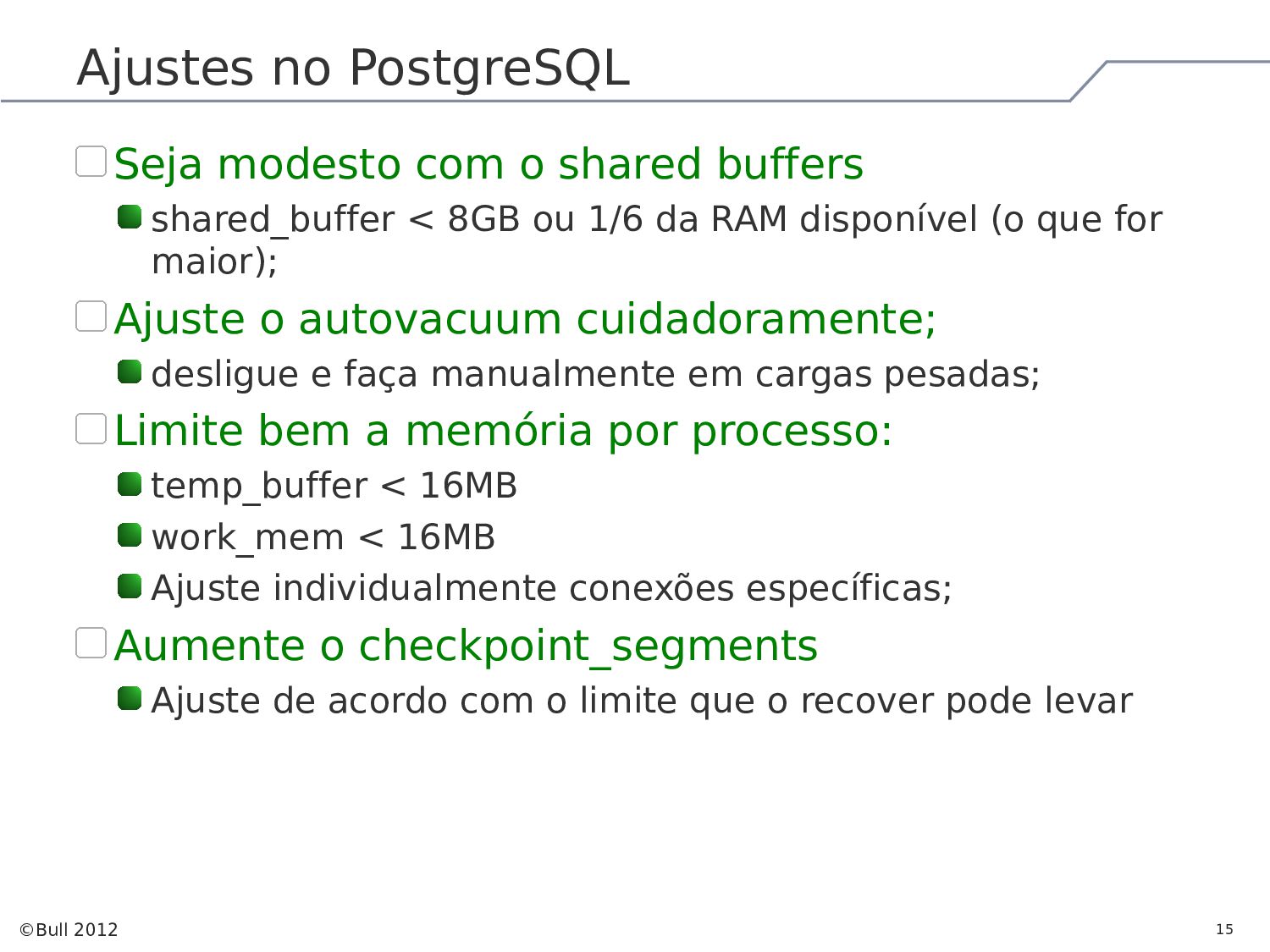{kind=link}
{kind=link}
{kind=link}
{kind=link}
![19 ©Bull 2012 Fábio Telles Rodriguez [email protected] [email protected]](https://files.speakerdeck.com/presentations/b642353215cd4392b23048e189fbc2e0/slide_18.jpg){kind=link}