sharding or replication Low latency and High throughput In-memory storage, fast indexing, co-located ops, batch ops Rich API and query language SQL-like against POJOs and schema-free documents. Geospatial API ACID transactions Maintain full ACID compliance against your data set through full transaction semantics High availability and resiliency Fault tolerance through replication, cross-data center replication, auto- healing Data Tiering RAM and SSD
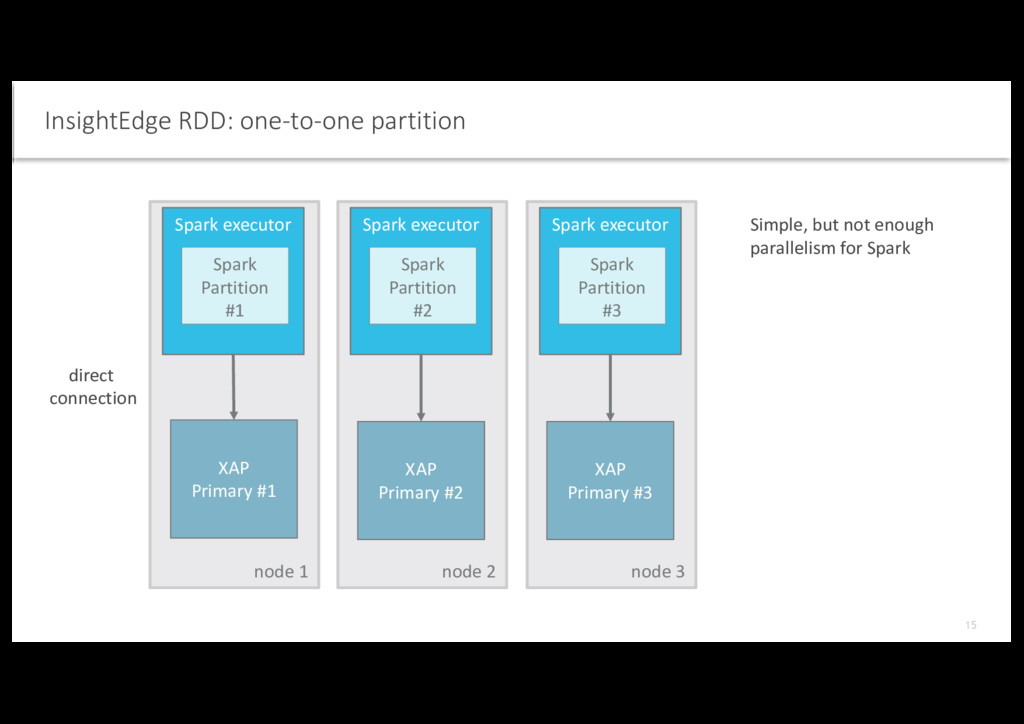
array of partitions that a dataset is divided to – XAP Distributed Query to get partitions and their hosts • A compute function to do a computation on partitions – Iterator over portion of data • Optional preferred locations, i.e. hosts for a partition where the data will be loaded – hosts from Distributed Query InsightEdge RDD: resilient distributed dataset
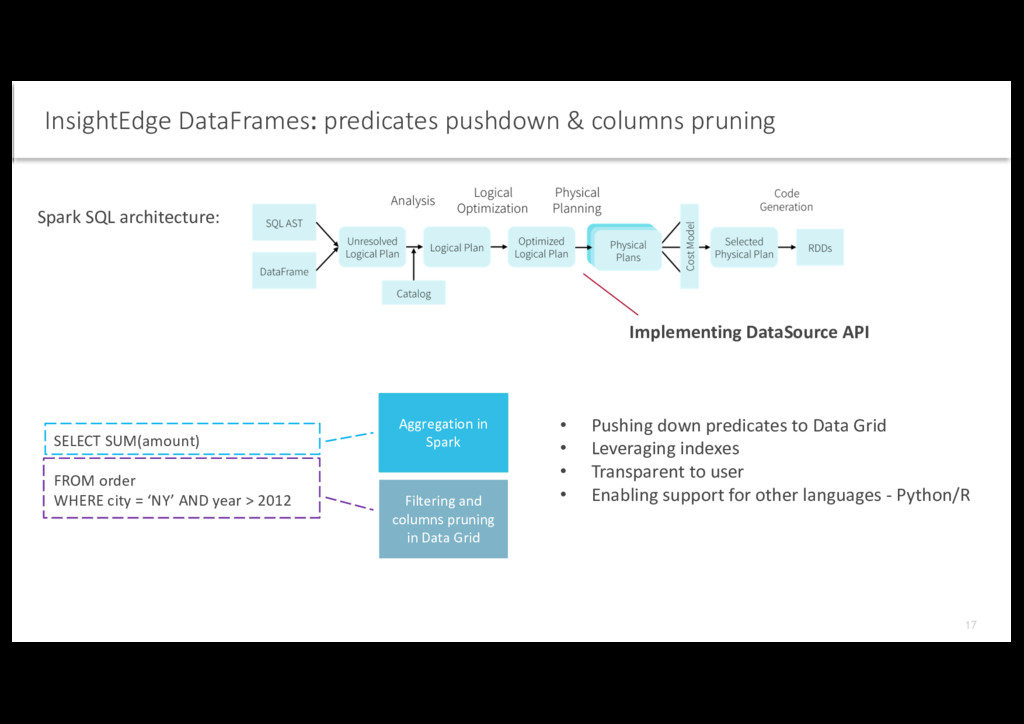
Spark Filtering and columns pruning in Data Grid SELECT SUM(amount) FROM order WHERE city = ‘NY’ AND year > 2012 Spark SQL architecture: • Pushing down predicates to Data Grid • Leveraging indexes • Transparent to user • Enabling support for other languages - Python/R Implementing DataSource API
are packed in 3rd party java library - To register UDT you have to add Spark annotation to shape classes (but you cannot) - Dataframes don’t support a mix of Scala and Java types val searchRadius = 3 // km val userLocation = point(-77.024470, 39.032506) val searchArea = circle(userLocation, kmToDeg(searchRadius)) val schools = sqlContext.read.grid.loadClass[School] val nearestSchools = schools.filter(schools("location") geoWithin searchArea) Shapes: Queries: intersects, within, contains https://github.com/InsightEdge/insightedge-geo-demo/ Geo Indexes
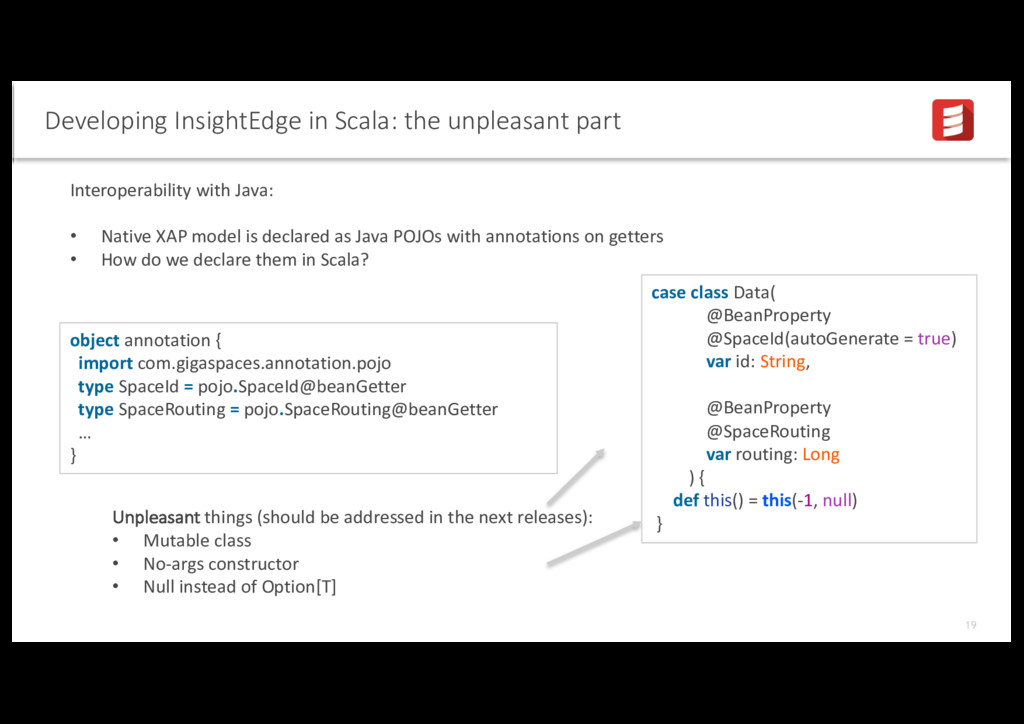
Java: • Native XAP model is declared as Java POJOs with annotations on getters • How do we declare them in Scala? Unpleasant things (should be addressed in the next releases): • Mutable class • No-args constructor • Null instead of Option[T] object annotation { import com.gigaspaces.annotation.pojo type SpaceId = pojo.SpaceId@beanGetter type SpaceRouting = pojo.SpaceRouting@beanGetter … } case class Data( @BeanProperty @SpaceId(autoGenerate = true) var id: String, @BeanProperty @SpaceRouting var routing: Long ) { def this() = this(-1, null) }
to extend Spark API with implicit conversions import org.insightedge.spark.implicits.all._ val stream = … stream.saveToGrid() def gridRdd[R: ClassTag]():InsightEdgeRdd={…} val rdd = sc.gridRdd[Product]() • Code in functional style is concise and readable • Developers are really productive with Scala • Negative experience with SBT so far, we use Maven • ClassTags make the API clean (solves JVM’s type erasure problem) • Mixin class compositions, e.g. for testing class InsightEdgeRDDSpec extends FlatSpec with IEConfig with InsightEdge with Spark
with ScalaTest • Unit tests start Spark and XAP in embedded mode; covers all our API • Integrational tests use Docker for virtualization – covers bash scripts – Zeppelin notebooks – clustering and networking – tag long running tests and launch them only on ‘master’ and ‘release’ branches – we use Spotify’s plugin to build images with Maven – got rid of xebialabs/overcast, using spotify/docker-client OR just running containers with import sys.process._ “docker run image” !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}