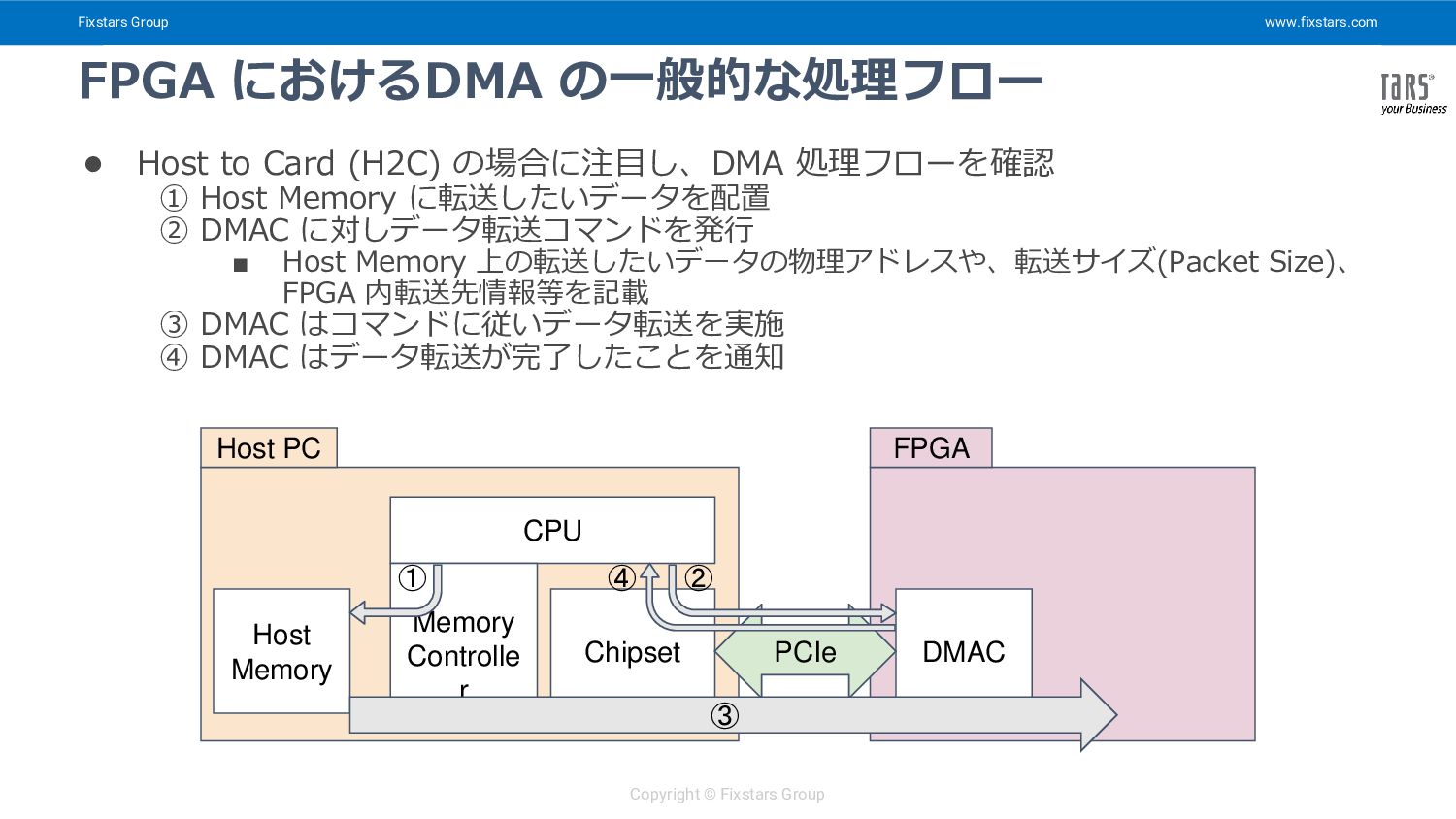
Card (H2C) の場合に注目し、DMA 処理フローを確認 ① Host Memory に転送したいデータを配置 ② DMAC に対しデータ転送コマンドを発行 ▪ Host Memory 上の転送したいデータの物理アドレスや、転送サイズ(Packet Size)、 FPGA 内転送先情報等を記載 ③ DMAC はコマンドに従いデータ転送を実施 ④ DMAC はデータ転送が完了したことを通知 Chipset Host PC CPU Memory Controlle r Host Memory FPGA DMAC PCIe ③ ① ② ④ FPGA におけるDMA の一般的な処理フロー
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
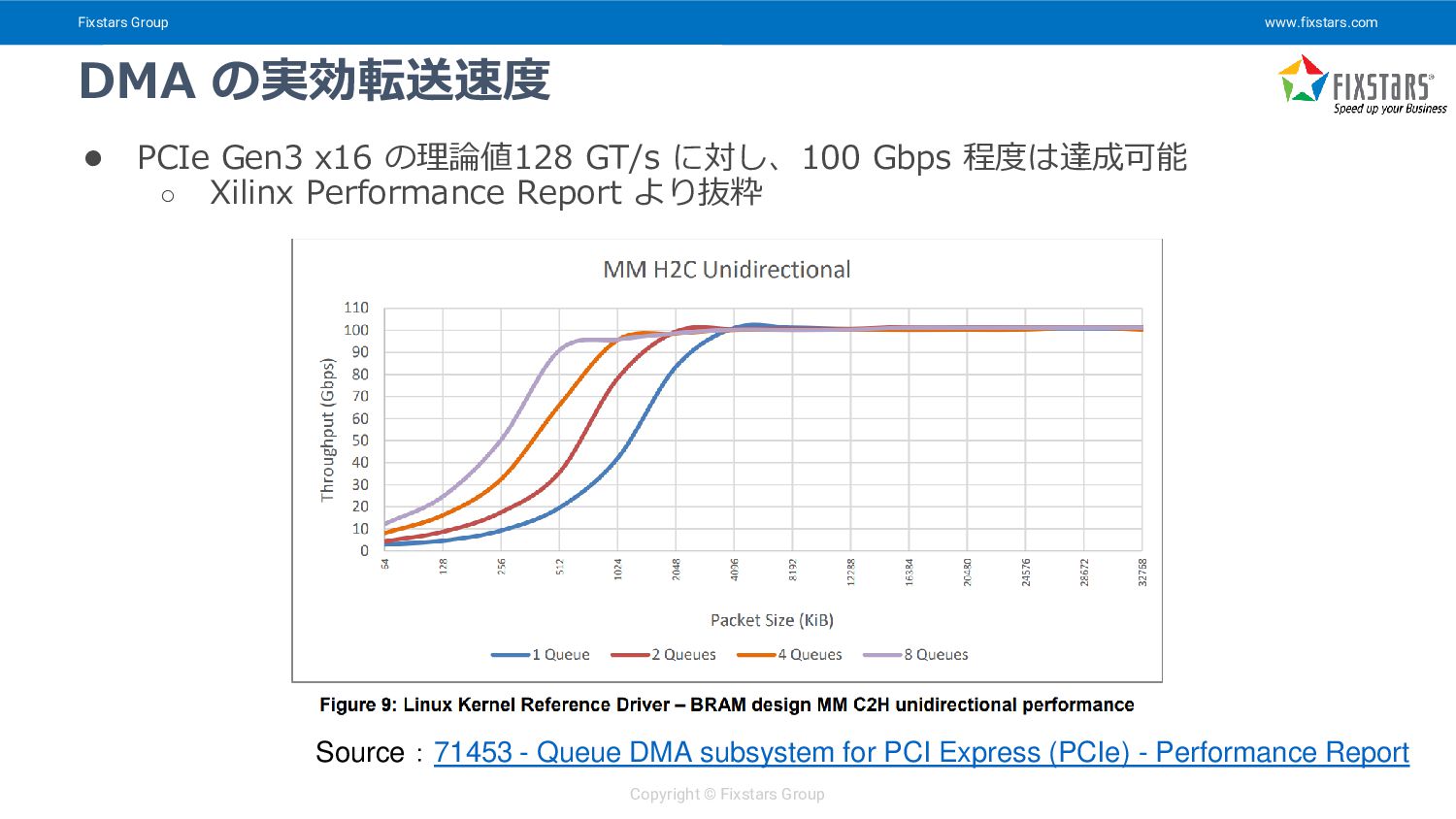
{kind=link}
{kind=link}
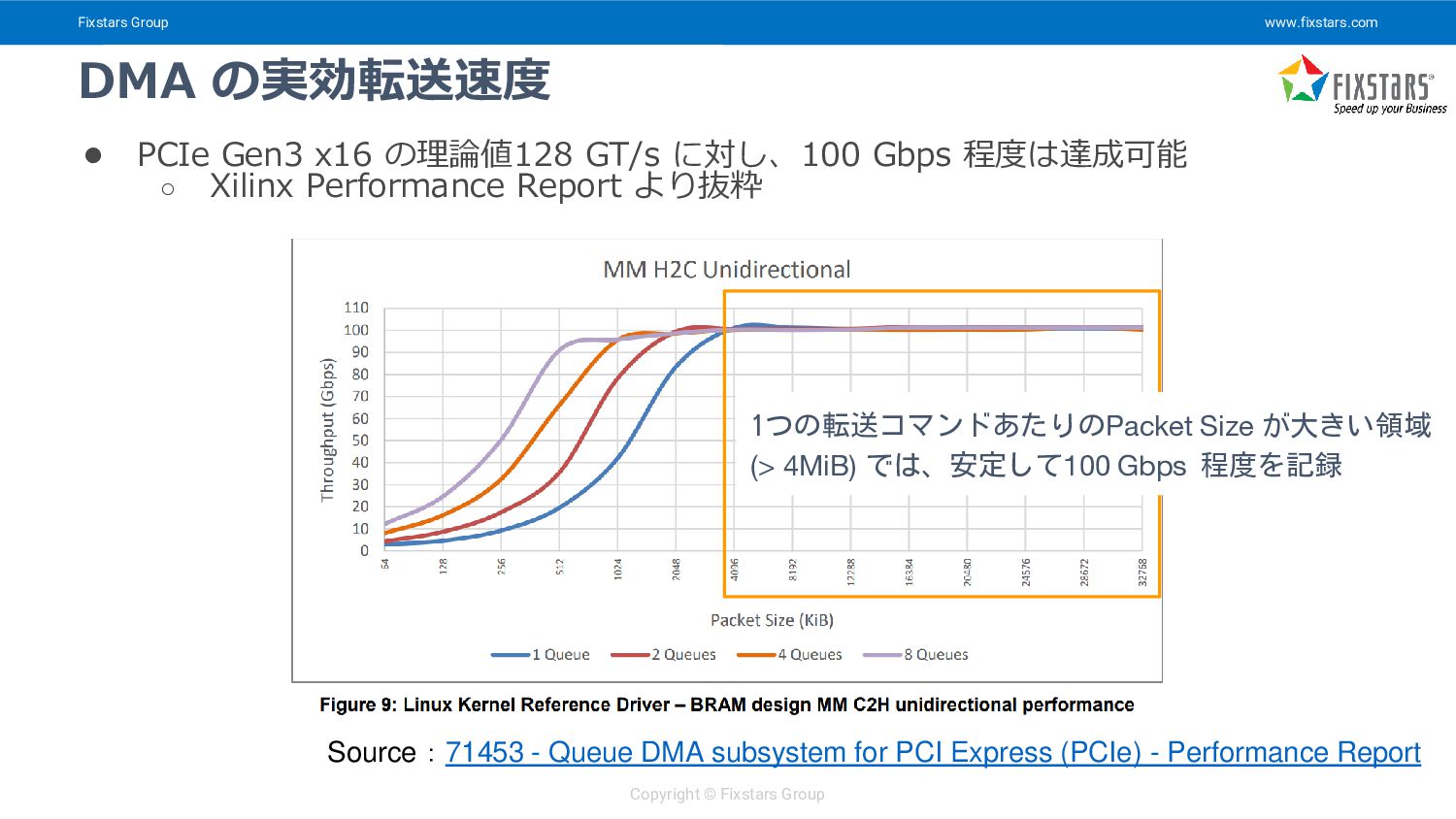
{kind=link}
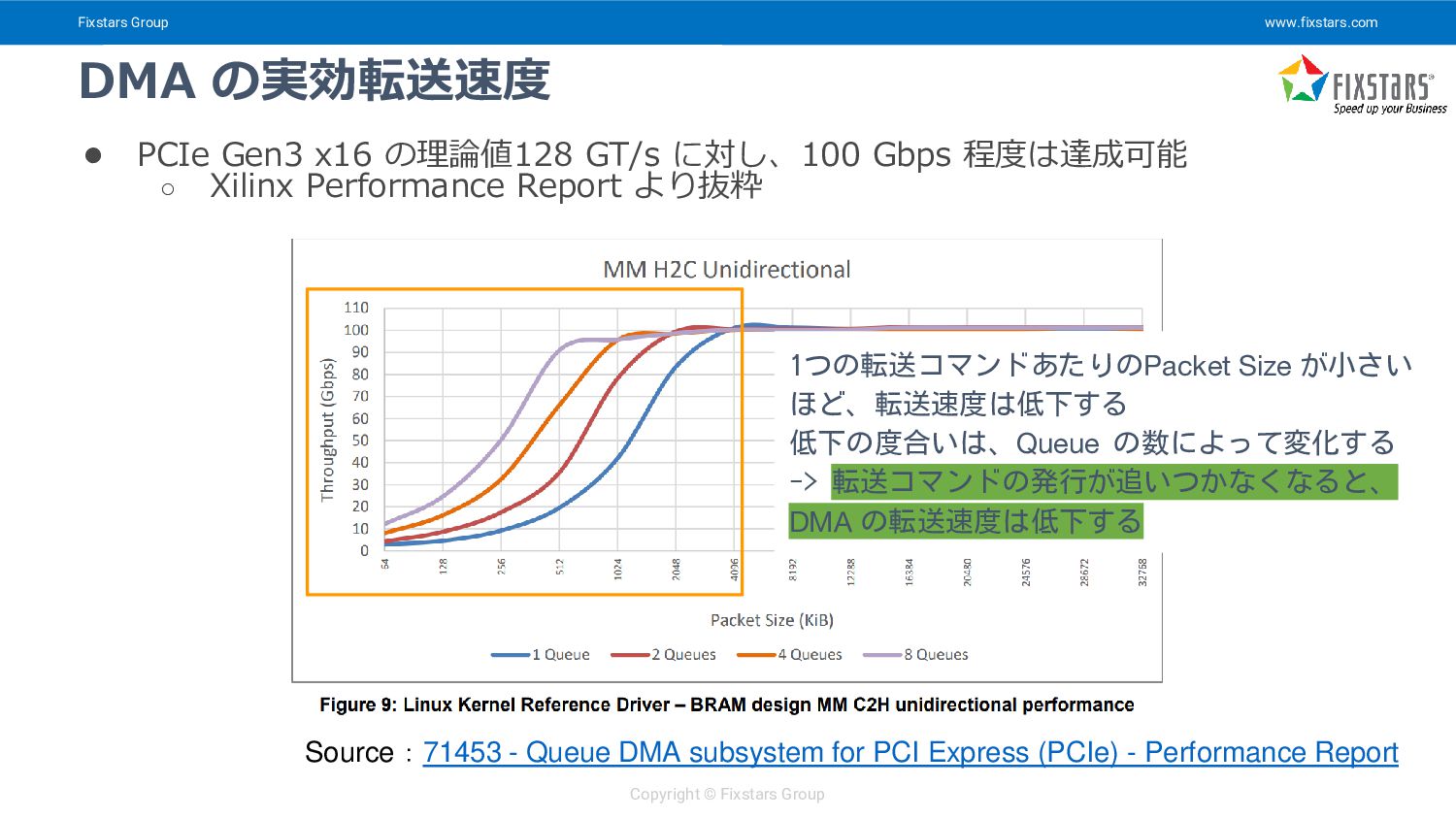
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
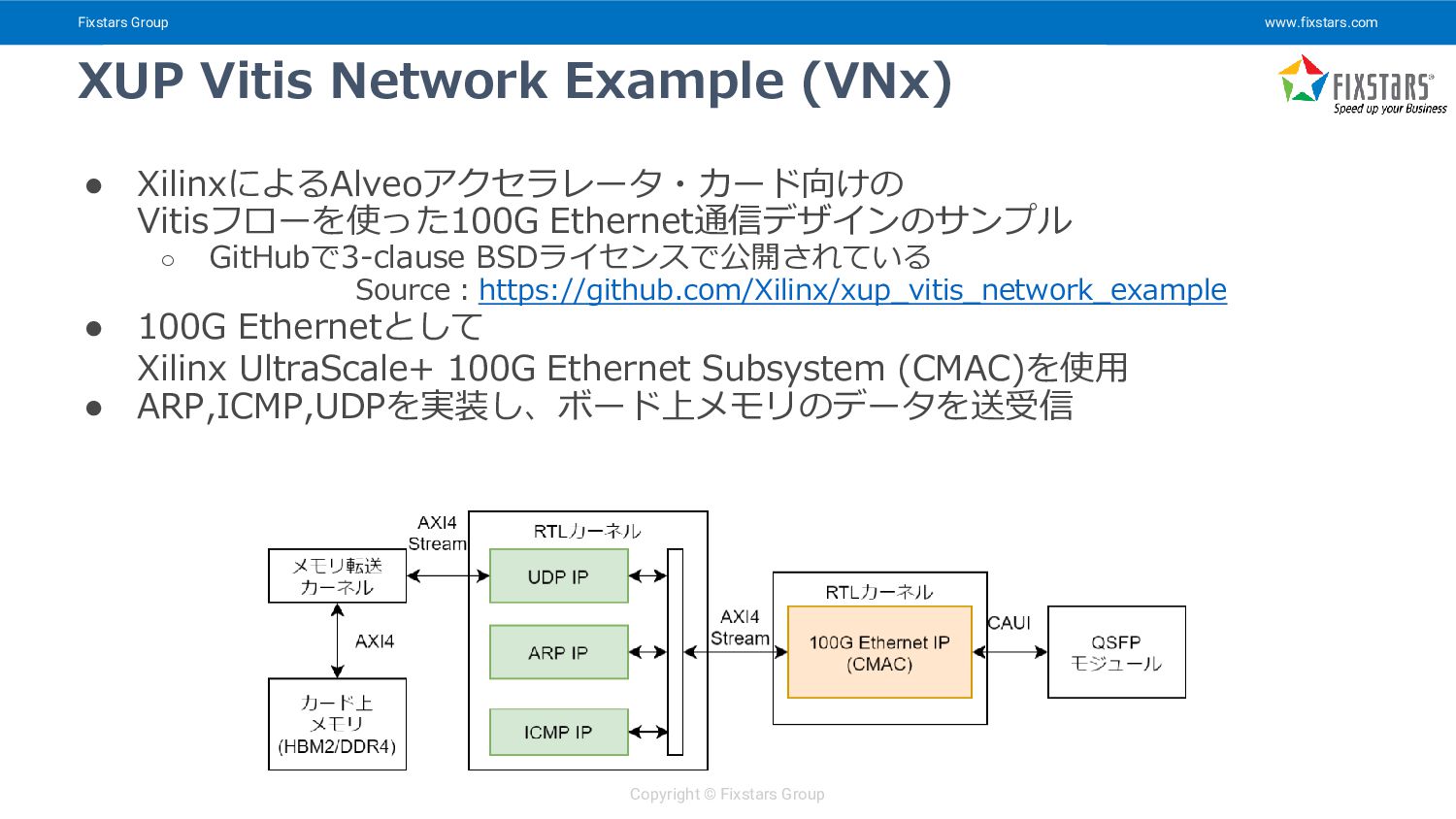{kind=link}
{kind=link}
{kind=link}
{kind=link}
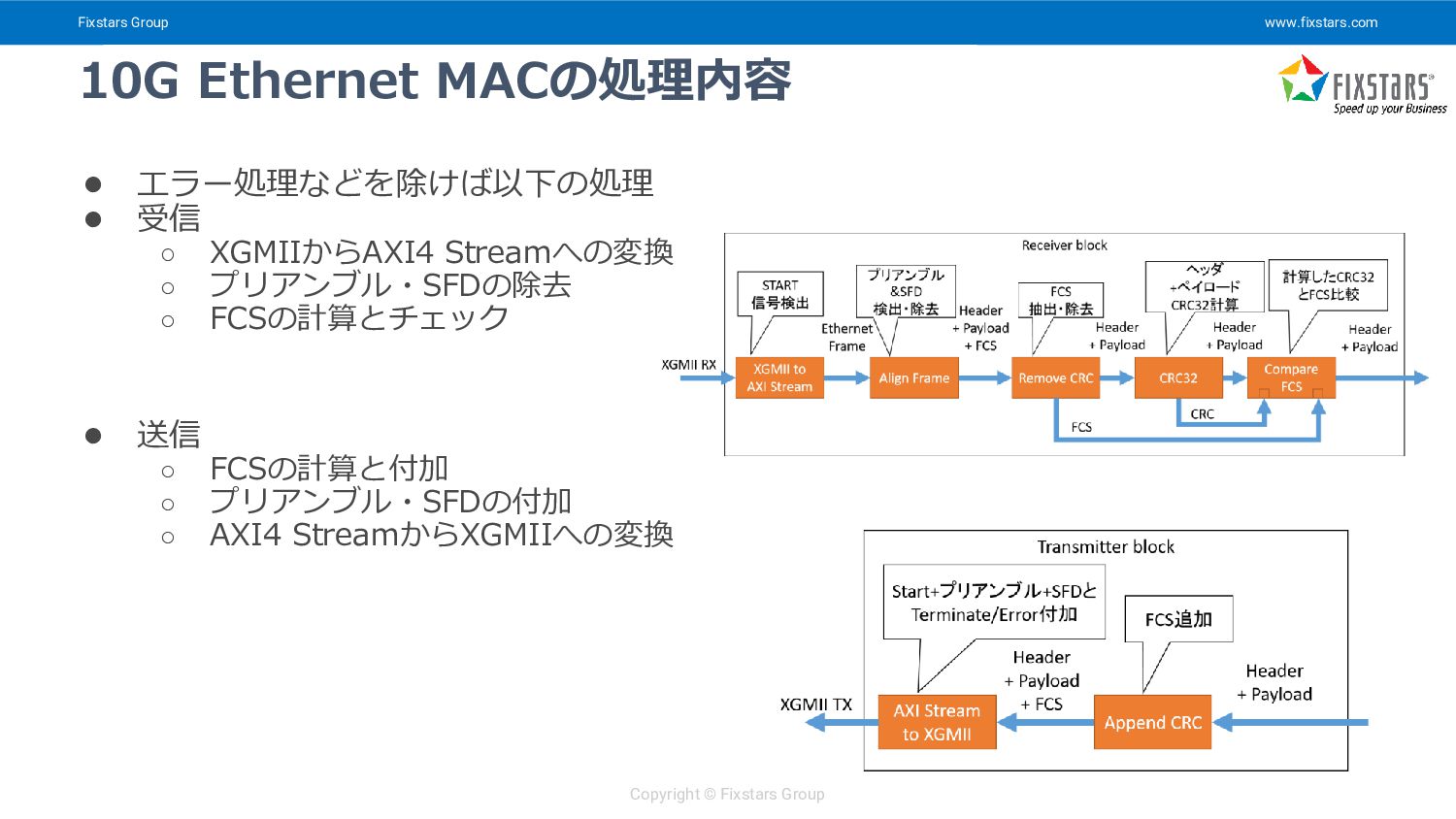{kind=link}
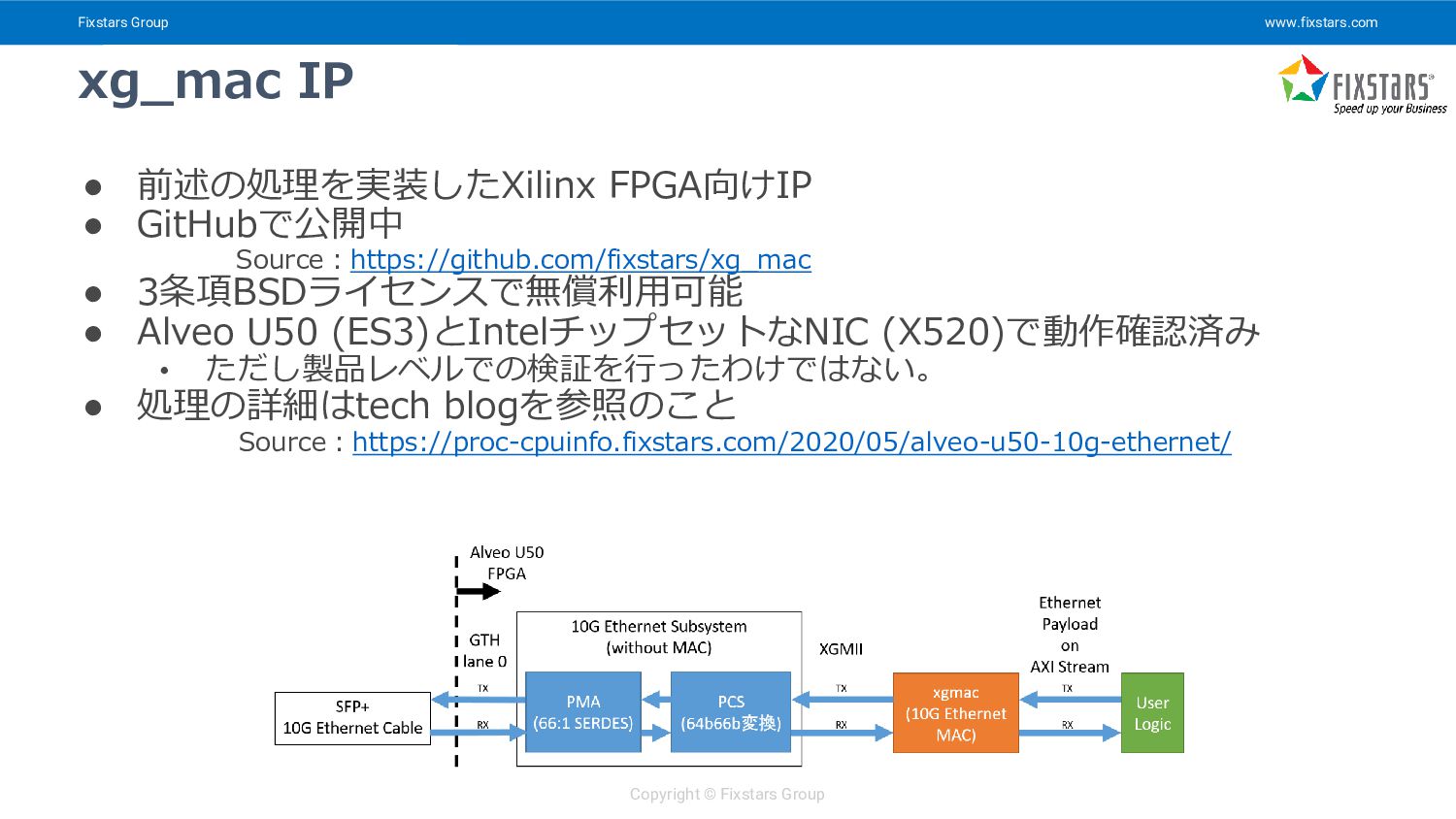{kind=link}
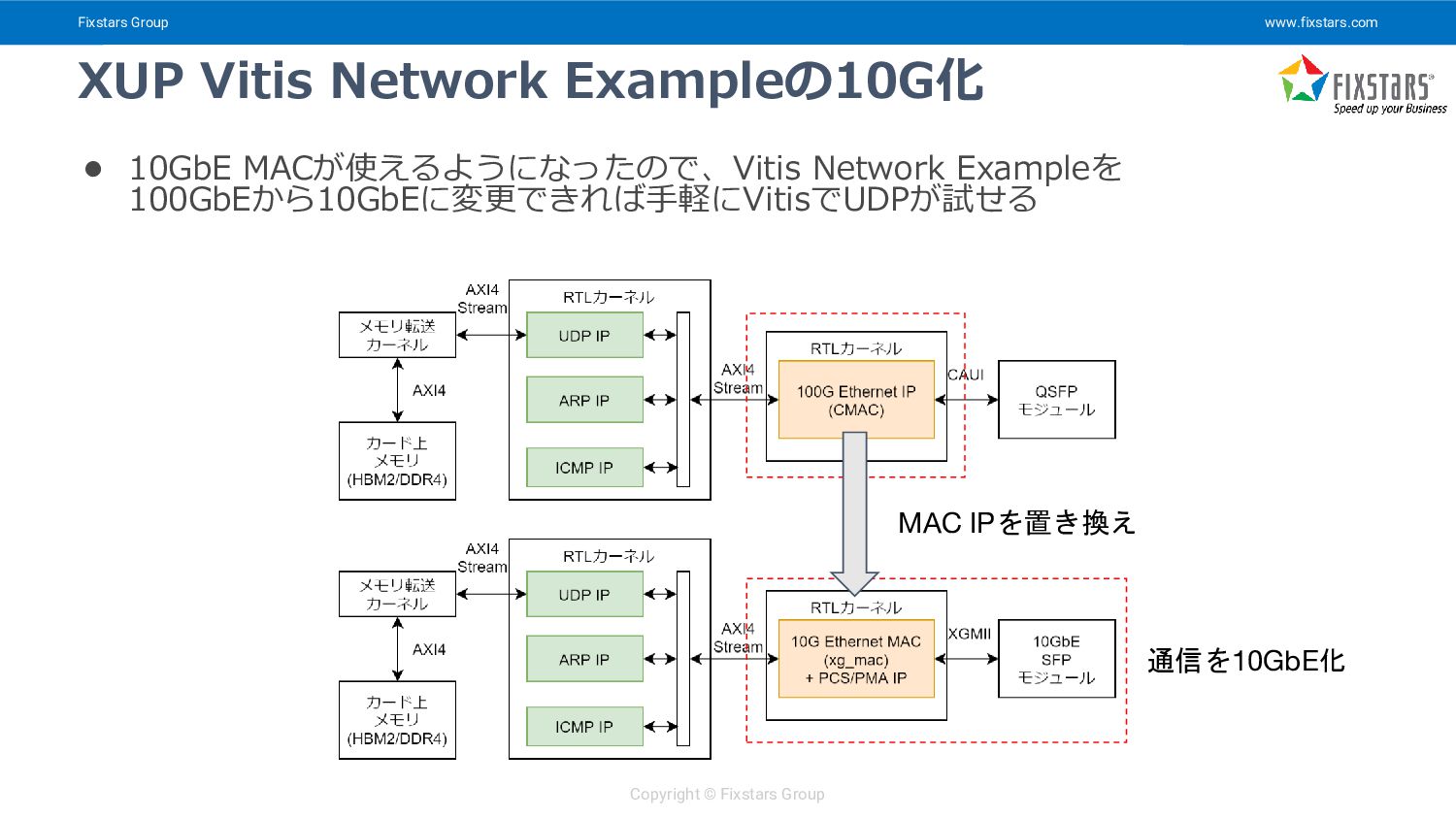{kind=link}
{kind=link}
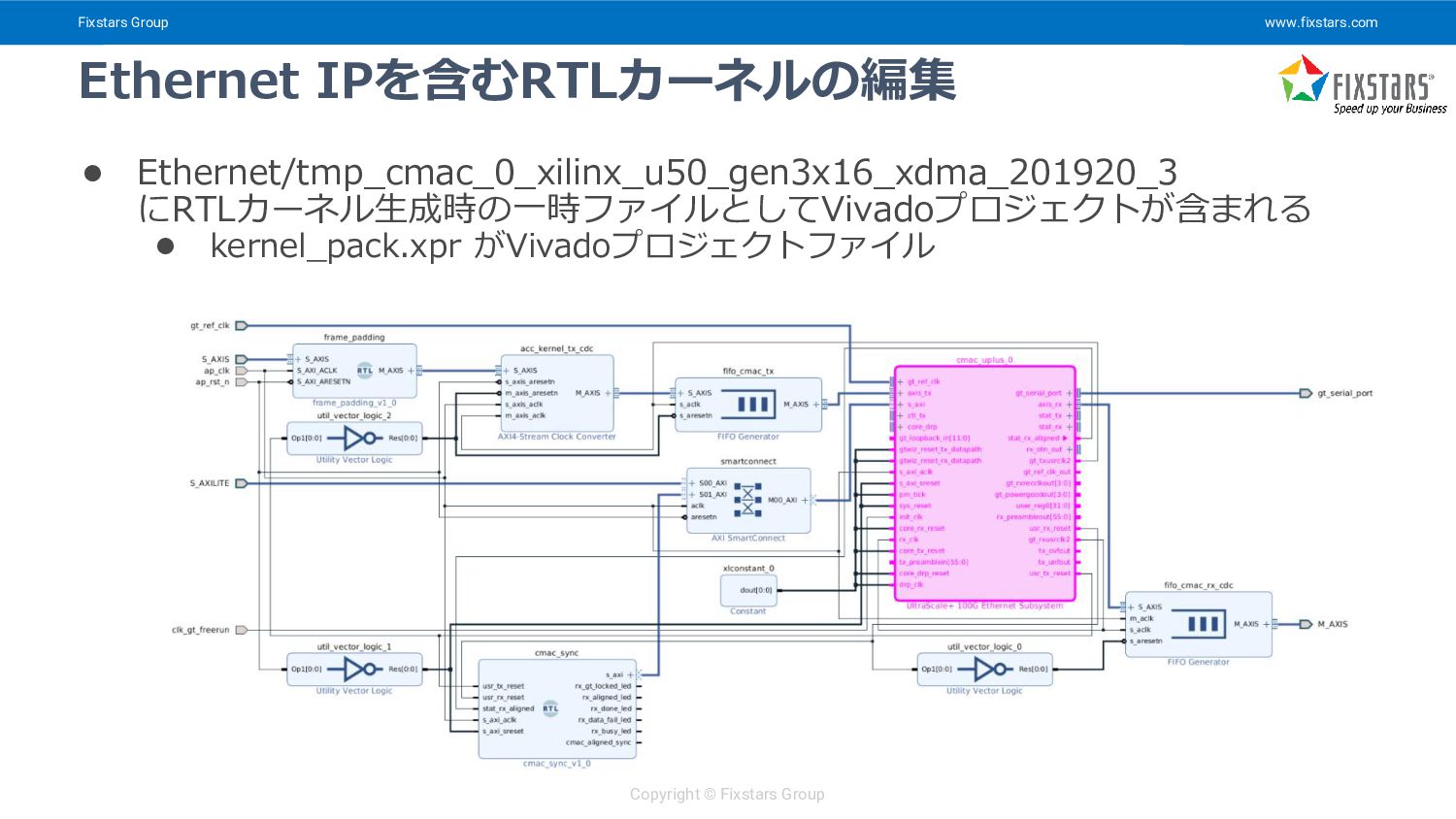{kind=link}
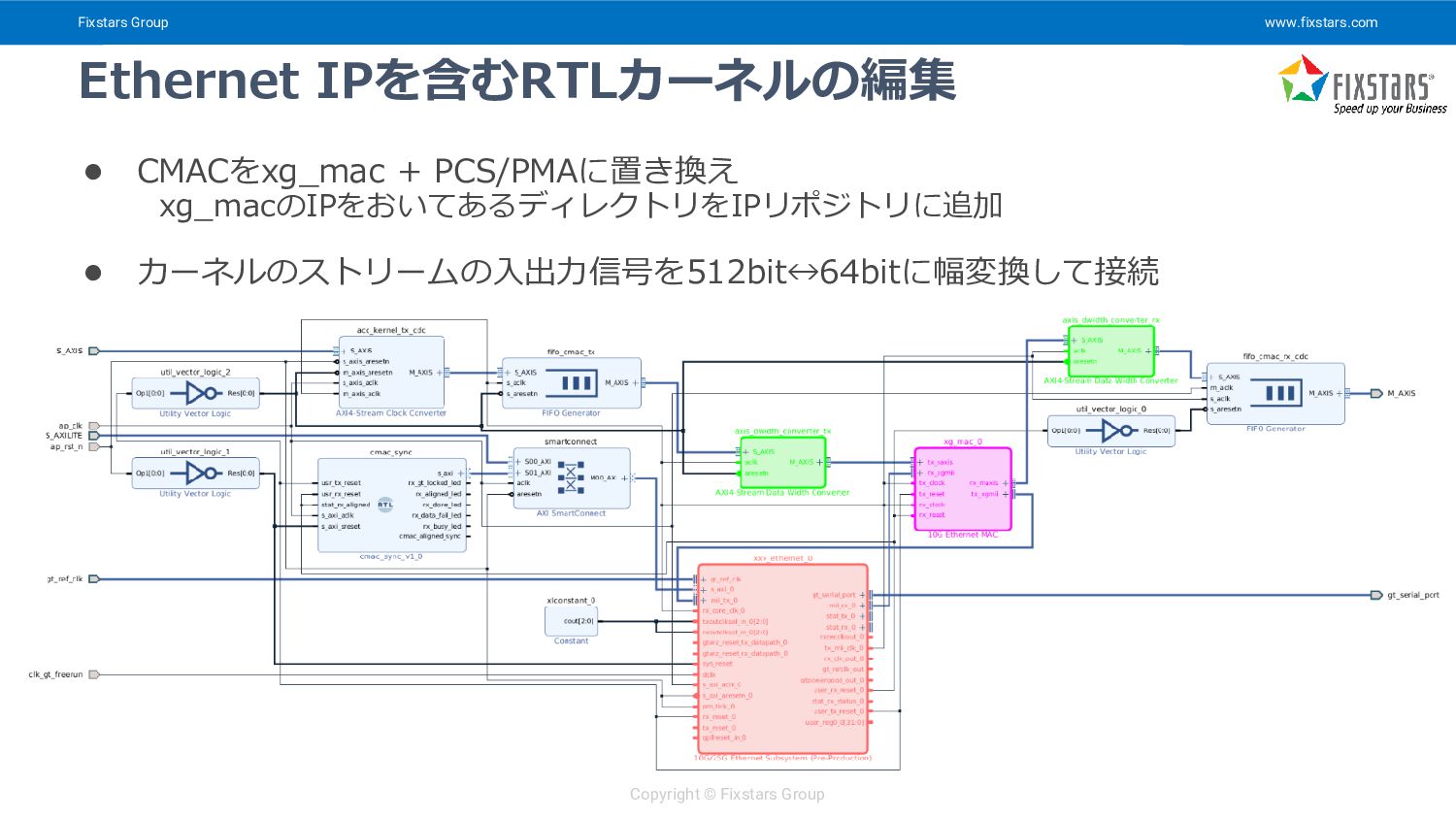{kind=link}
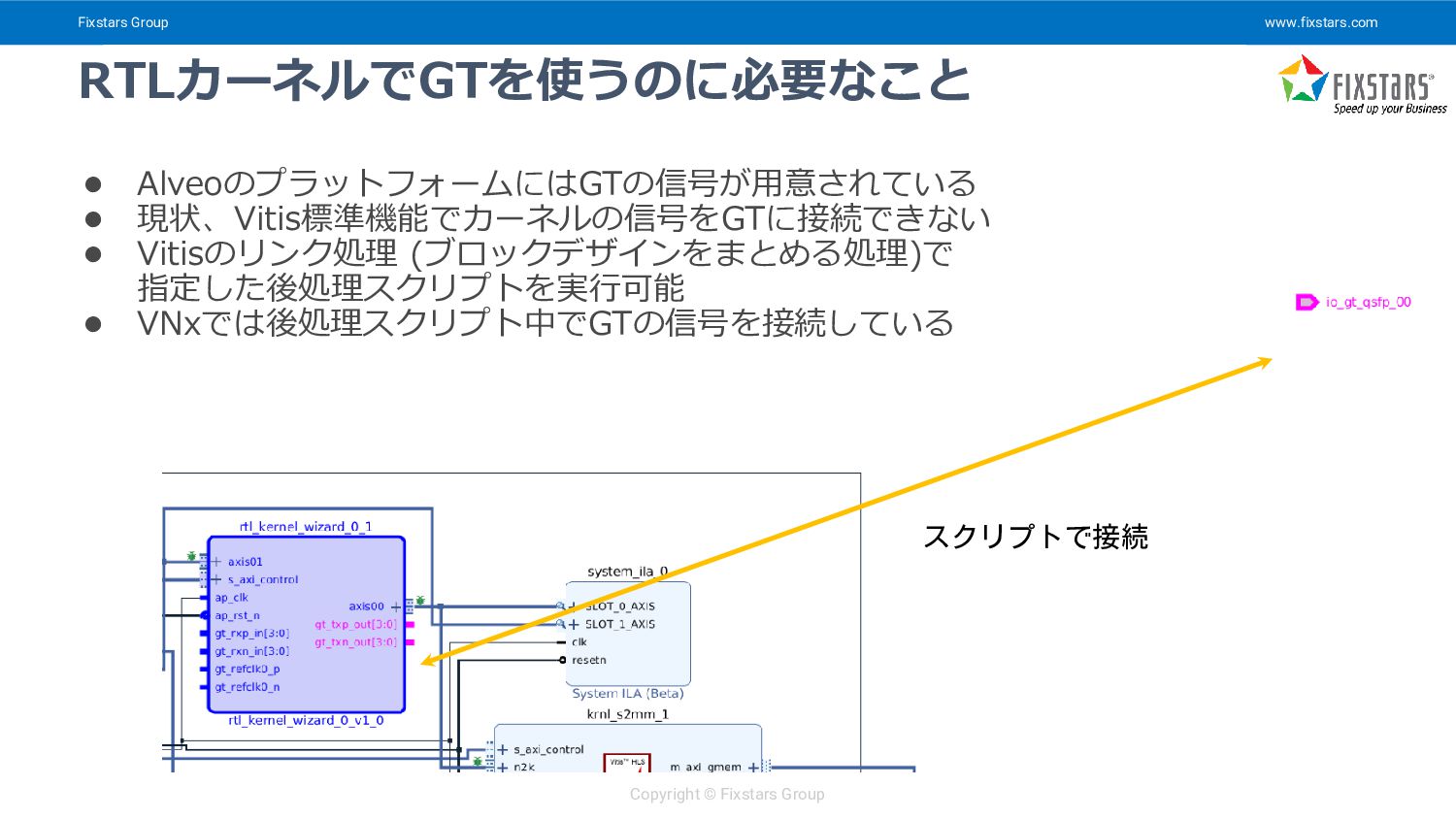{kind=link}
{kind=link}
{kind=link}
{kind=link}