This presentation is an adaptation of https://speakerdeck.com/wayoutmind/dwolla-tableau-and-aws-building-scalable-event-driven-data-pipelines-for-payments focussing specifically on how to capture flexible, semantically atomic events. It also introduces an open source Python library, https://github.com/Dwolla/arbalest and demonstrates how to compose AWS services to enable interactive querying and analysis at scale. [This presentation was originally presented at Iowa Code Camp 16, Dec. 5, 2015.]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
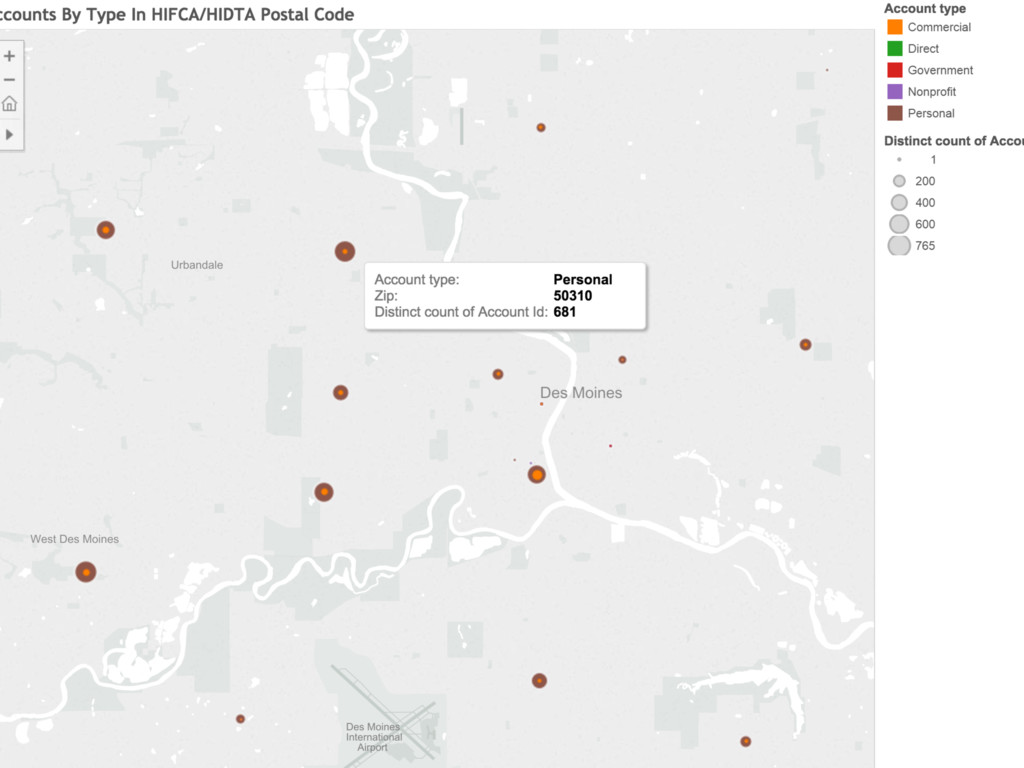{kind=link}
{kind=link}
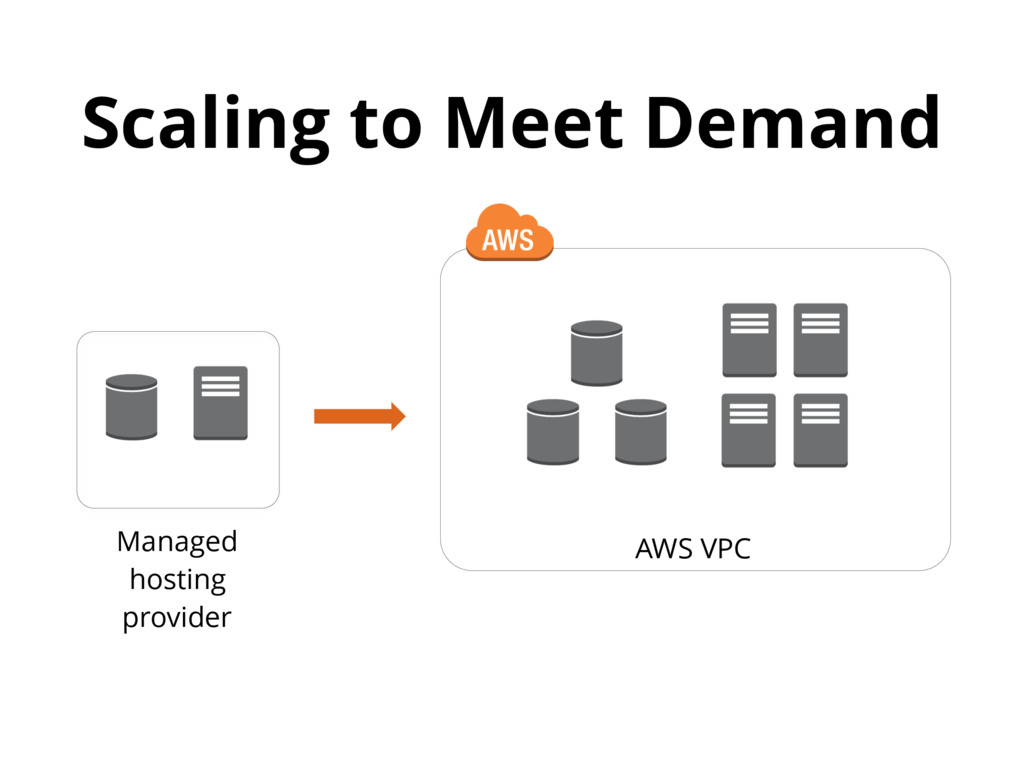{kind=link}
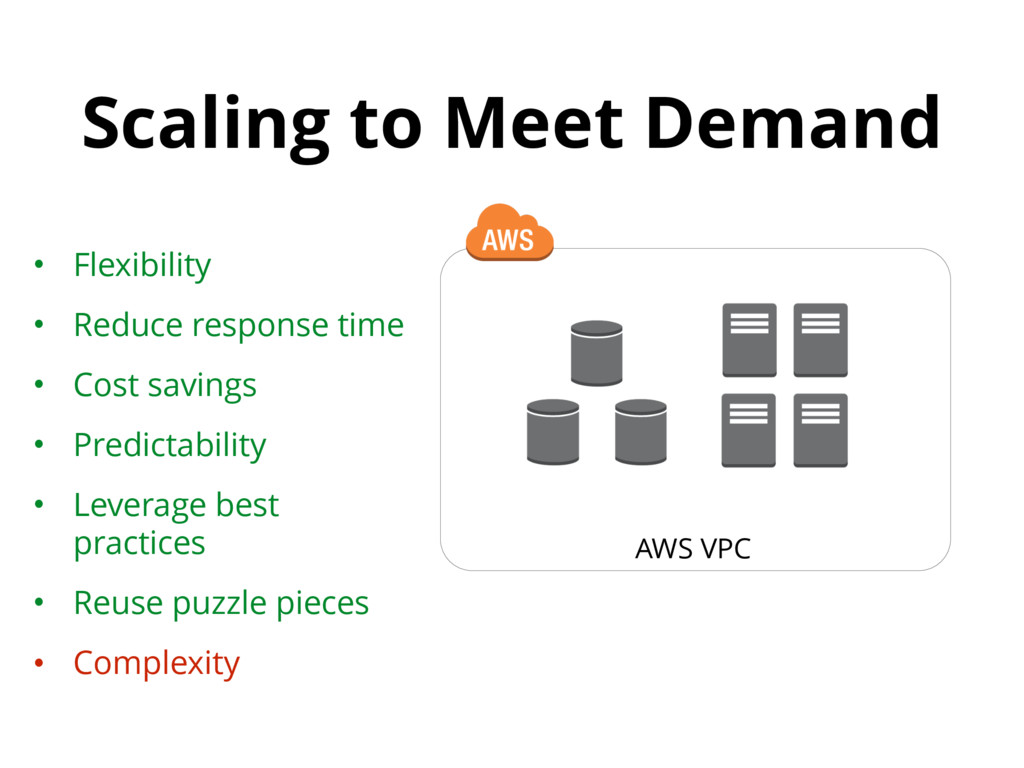{kind=link}
{kind=link}
{kind=link}
{kind=link}
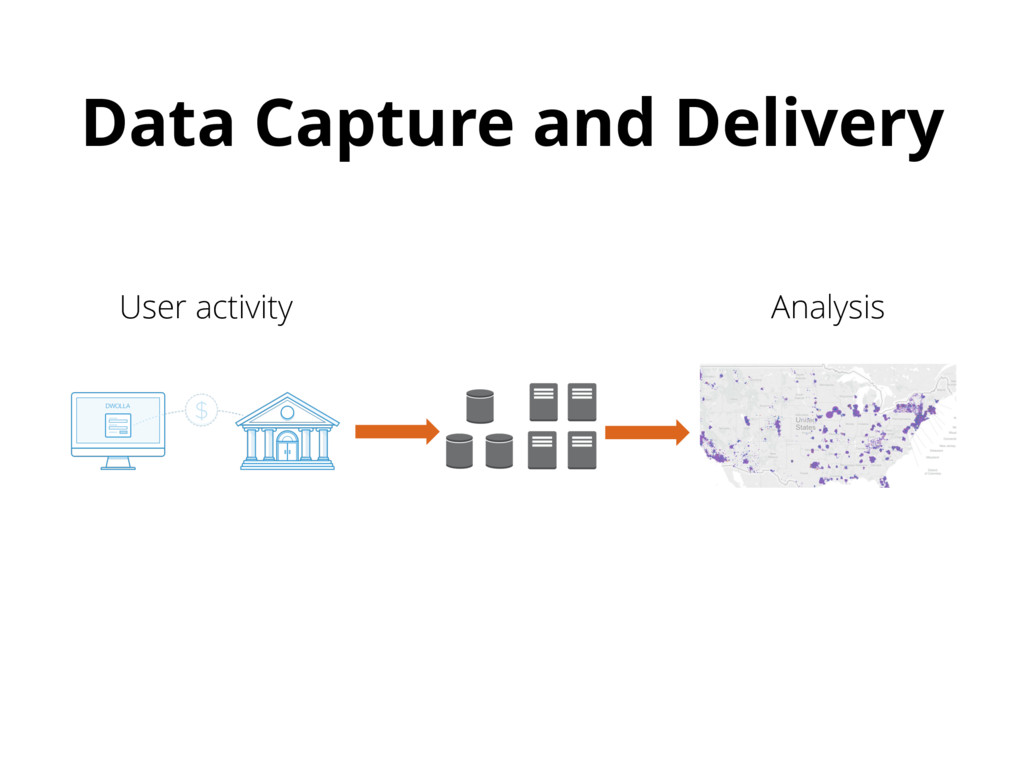{kind=link}
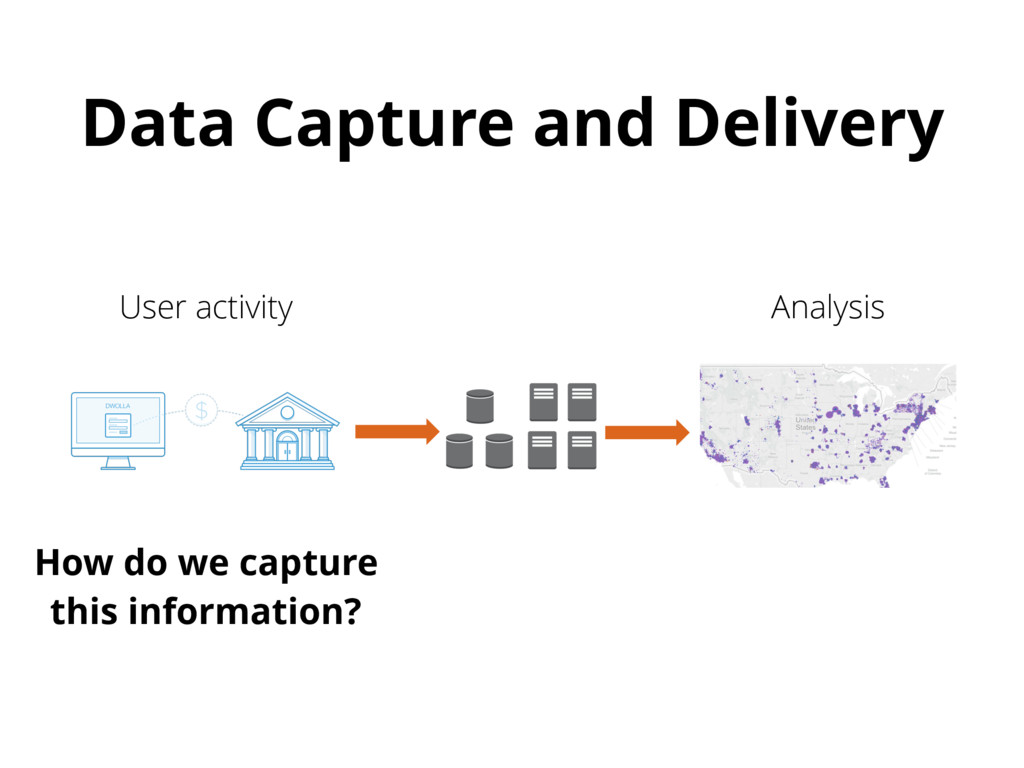{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![State Transition With Events user.created { “email_address”: “[email protected]”, “timestamp”: “2015-08-18T06:36:40Z”](https://files.speakerdeck.com/presentations/4263ab2e2b9a4a0fb158839caa031b7a/slide_29.jpg){kind=link}
![Context Specific Event Values user.created { “email_address”: “[email protected]”, “timestamp”: “2015-08-18T06:36:40Z”](https://files.speakerdeck.com/presentations/4263ab2e2b9a4a0fb158839caa031b7a/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
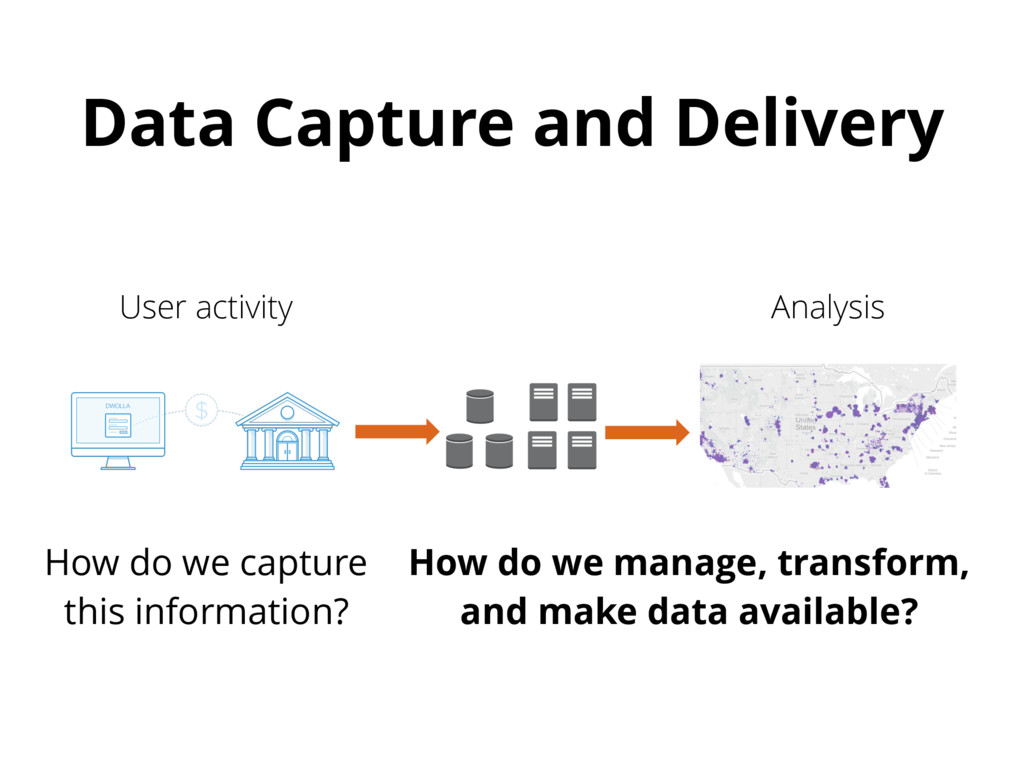{kind=link}
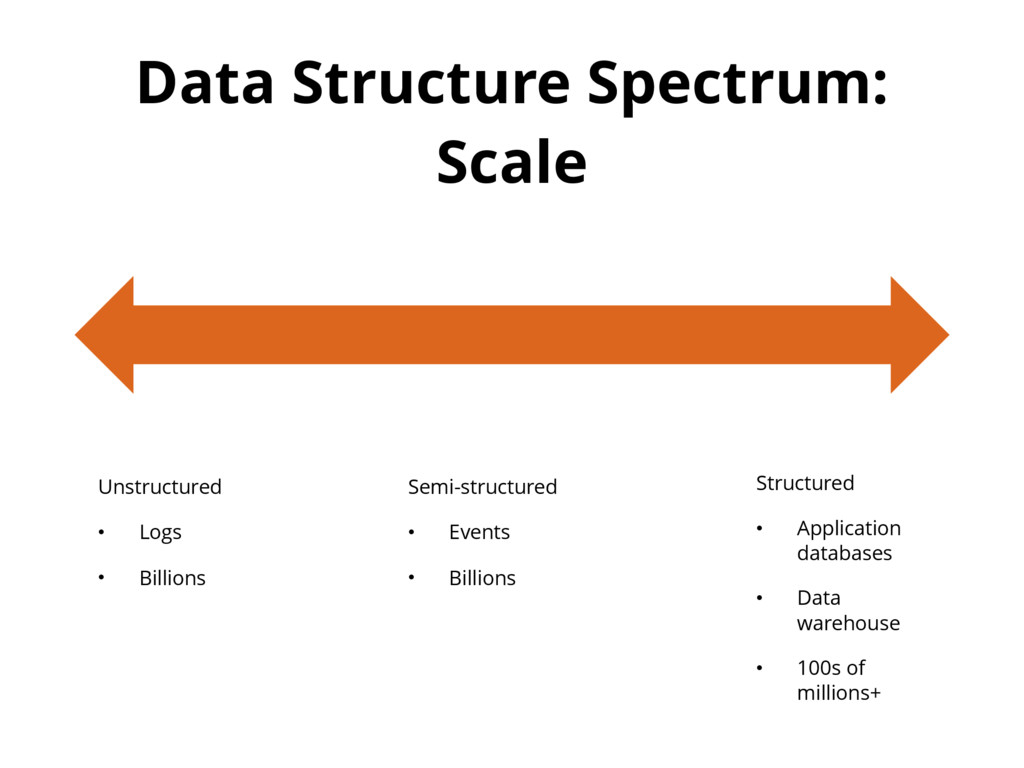{kind=link}
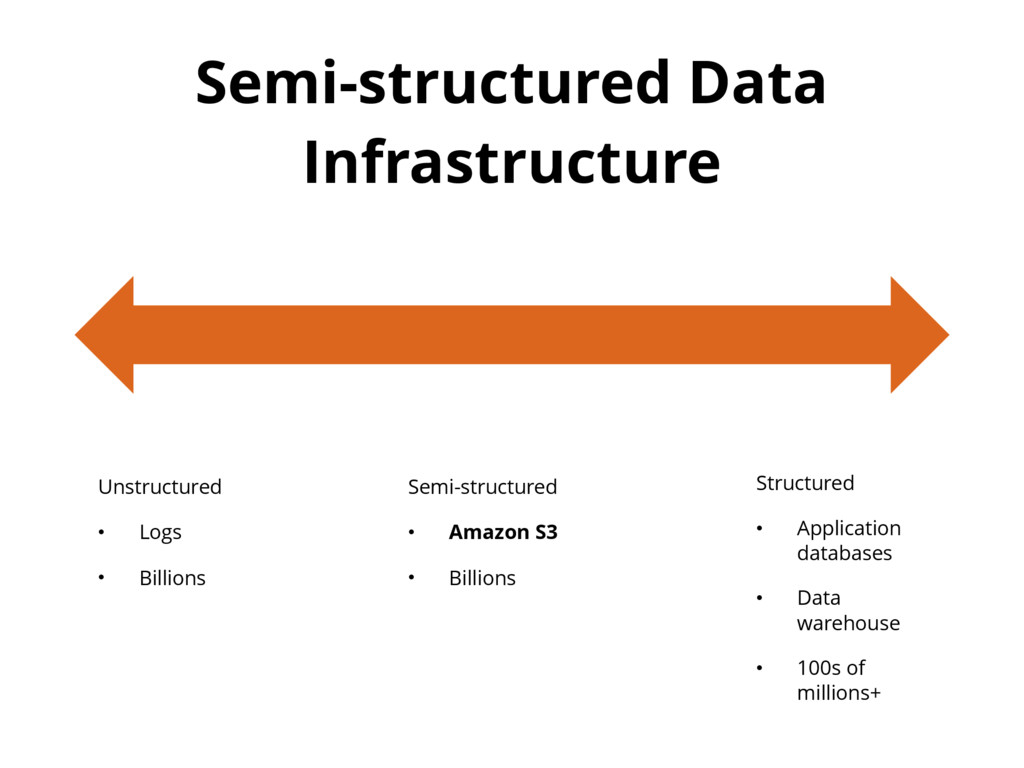{kind=link}
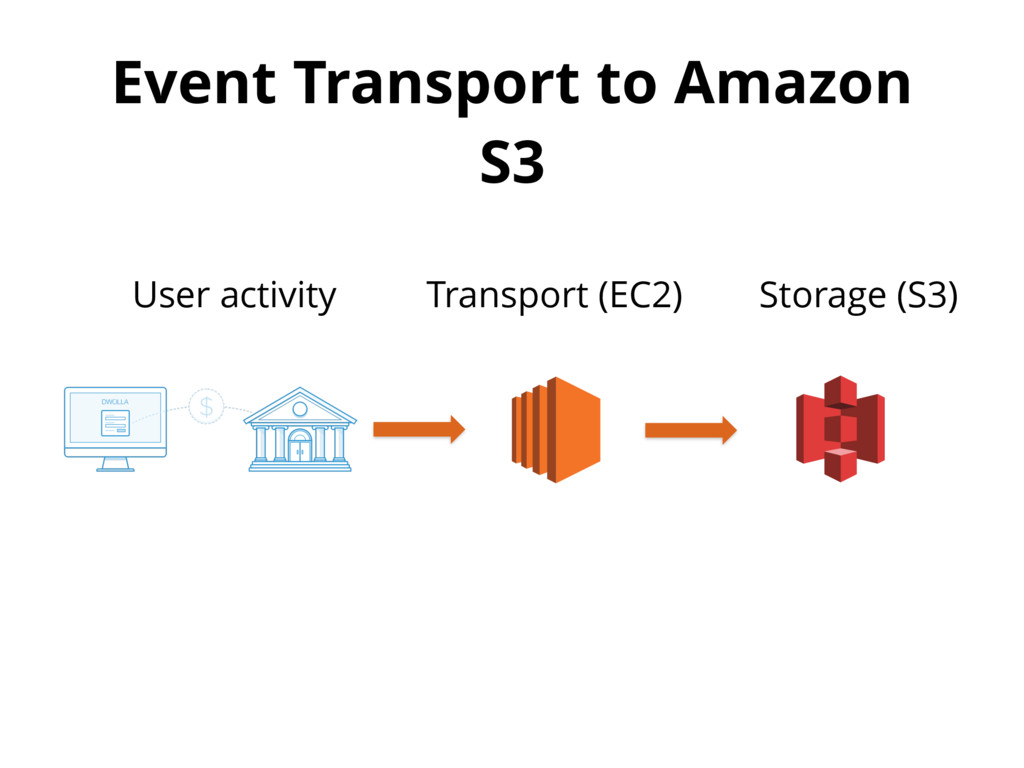{kind=link}
![Event Payload s3://bucket-name/[event name]/[yyyy-MM- dd]/[hh]/eventId s3://bucket-name/user.created/ 2015-08-18/06/009bd890-cb8f-4896- b9e7-8bb6c9b8b8fb {“email_address”: “[email protected]”,](https://files.speakerdeck.com/presentations/4263ab2e2b9a4a0fb158839caa031b7a/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
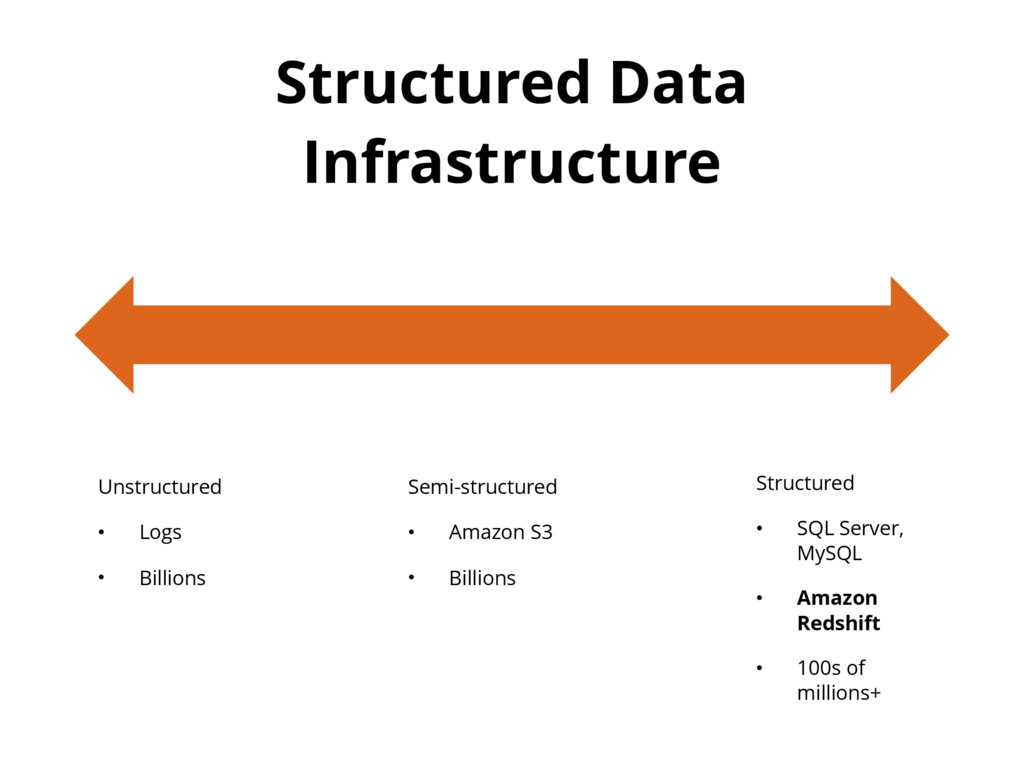{kind=link}
{kind=link}
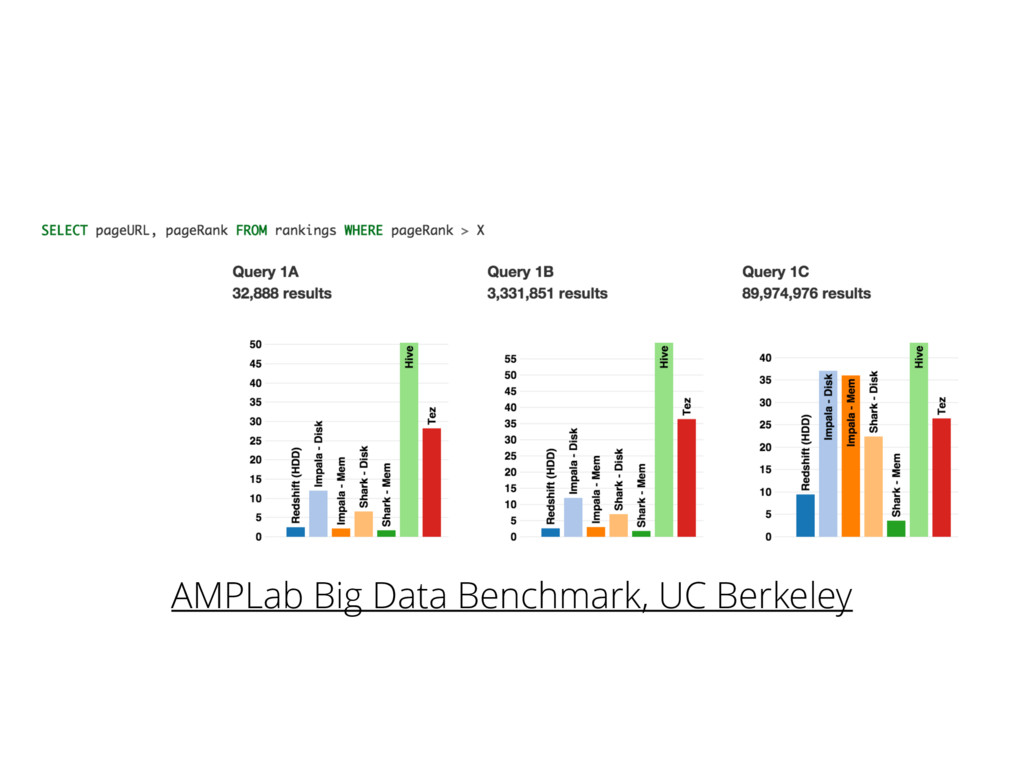{kind=link}
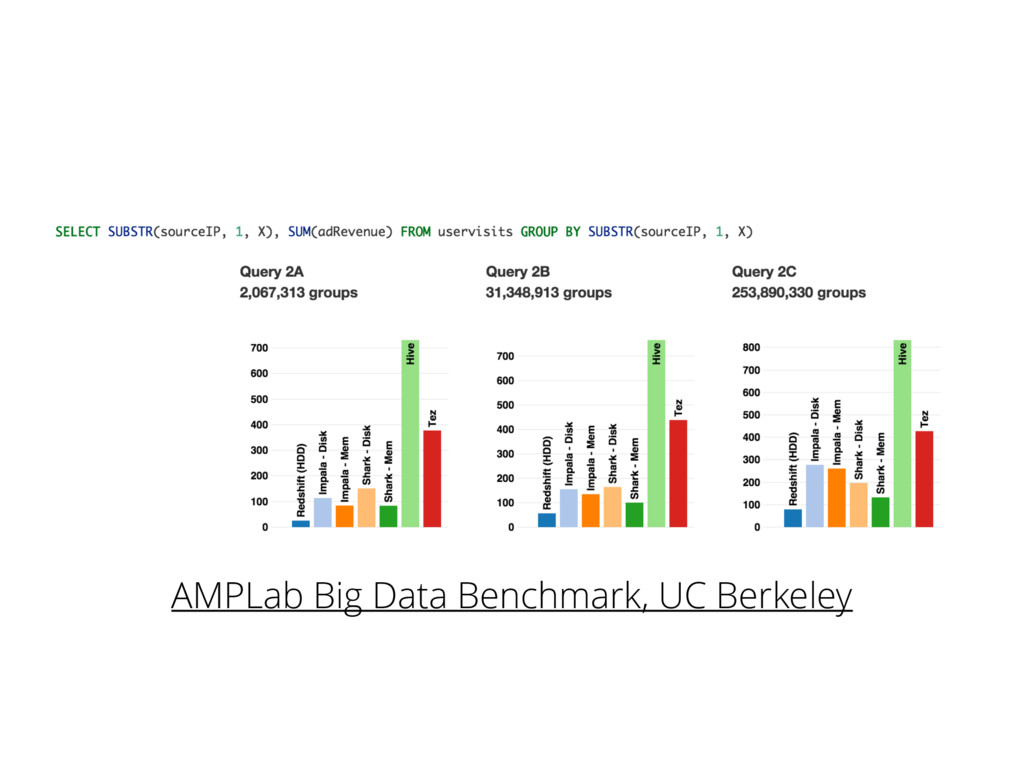{kind=link}
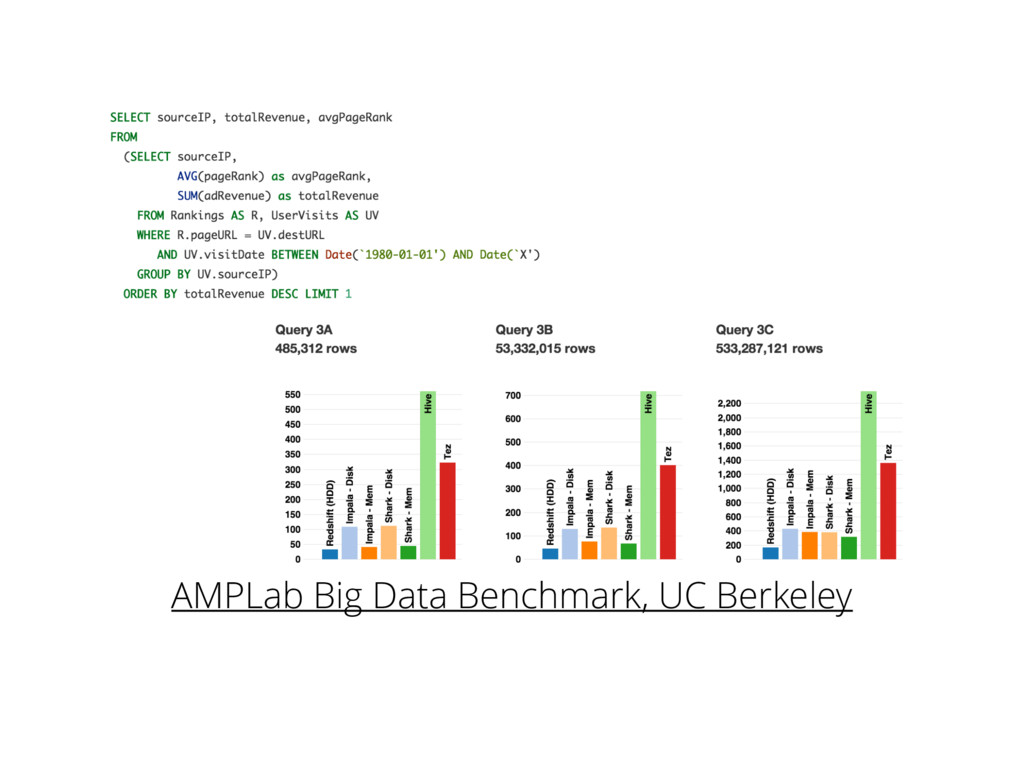{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
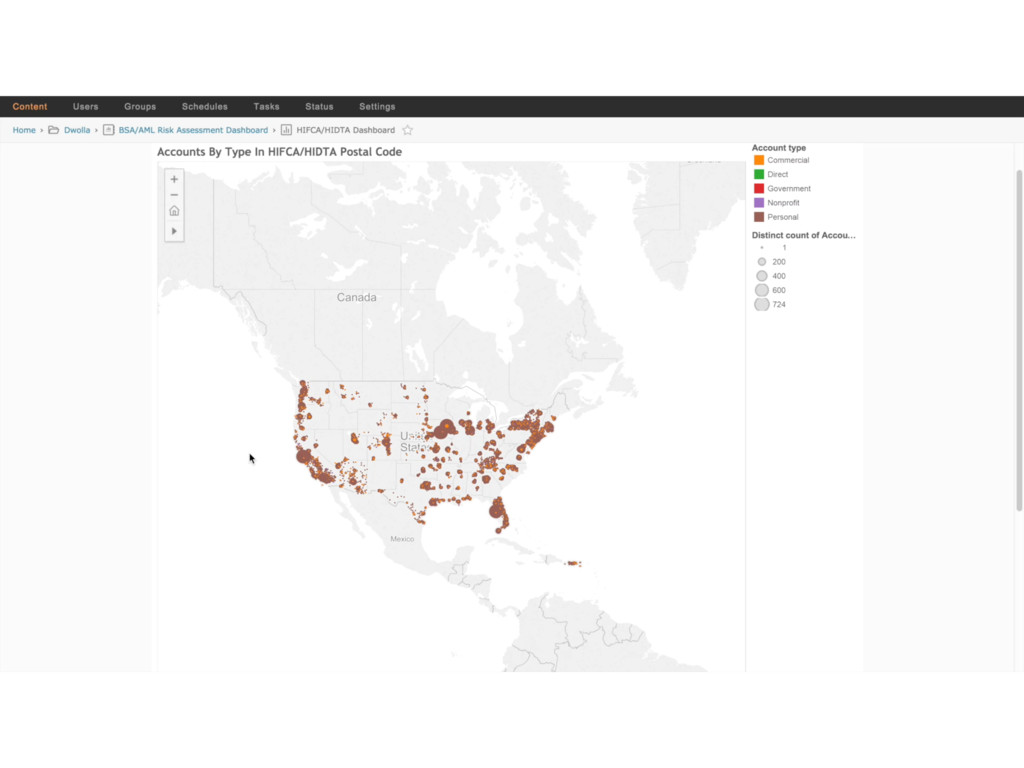{kind=link}
{kind=link}