Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
自然言語処理のための分散並列学習
Search
Kazuki Fujii
March 15, 2024
720
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
自然言語処理のための分散並列学習
NLP2024 ワークショップ2_生成ai時代の自然言語処理における産学官の役割と課題
Kazuki Fujii
March 15, 2024
More Decks by Kazuki Fujii
See All by Kazuki Fujii
IHPCSS2025-Kazuki-Fujii
fujiikazuki2000
0
30
2024-02-Tokyo-Tech-大規模言語モデルの事前学習知見
fujiikazuki2000
0
39
情報処理学会-全国大会2024-大規模言語モデルの分散並列学習
fujiikazuki2000
0
37
言語処理学会2024-継続事前学習による日本語に強い大規模言語モデルの構築
fujiikazuki2000
0
55
AWS Summit Japan 2025 Amazon SageMaker HyperPodを利用した日本語LLM(Swallow)の構築 (CUS-02)
fujiikazuki2000
0
50
合成データパイプラインを利用したSwallowProjectに おけるLLM性能向上
fujiikazuki2000
1
300
論文では語られないLLM開発において重要なこと Swallow Projectを通して
fujiikazuki2000
8
2k
大規模言語モデルの学習知見
fujiikazuki2000
0
210
Featured
See All Featured
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
WENDY [Excerpt]
tessaabrams
11
38k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
Tell your own story through comics
letsgokoyo
1
990
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Practical Orchestrator
shlominoach
191
11k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
How to Talk to Developers About Accessibility
jct
2
300
Building Adaptive Systems
keathley
44
3.1k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Transcript
自然言語処理のための 分散並列学習 東京工業大学 横田研究室/ Kotoba Technologies 藤井一喜
2 自己紹介 • 東京工業大学 横田研究室 (HPC: High Peformance Computing) •
Kotoba Technologies • LLM-jp モデル構築WG • Swallow Project 分散学習担当 LLM-jp Swallow
3 産学官連携 Turing(自動運転) Kotoba Tech(音声基盤モデル) SB Intuitions (LLM) 経産省、文科省 計算資源
Fugaku, ABCI, GCP(GENIAC)
4 対象 • 分散学習に苦手意識を持っている方 • ブラックボックスで使用している方 • DeepSpeed ZeROについてよく分からず使用している方 今回説明しないこと
3D Parallelism、MoEにおけるExpert Parallel など
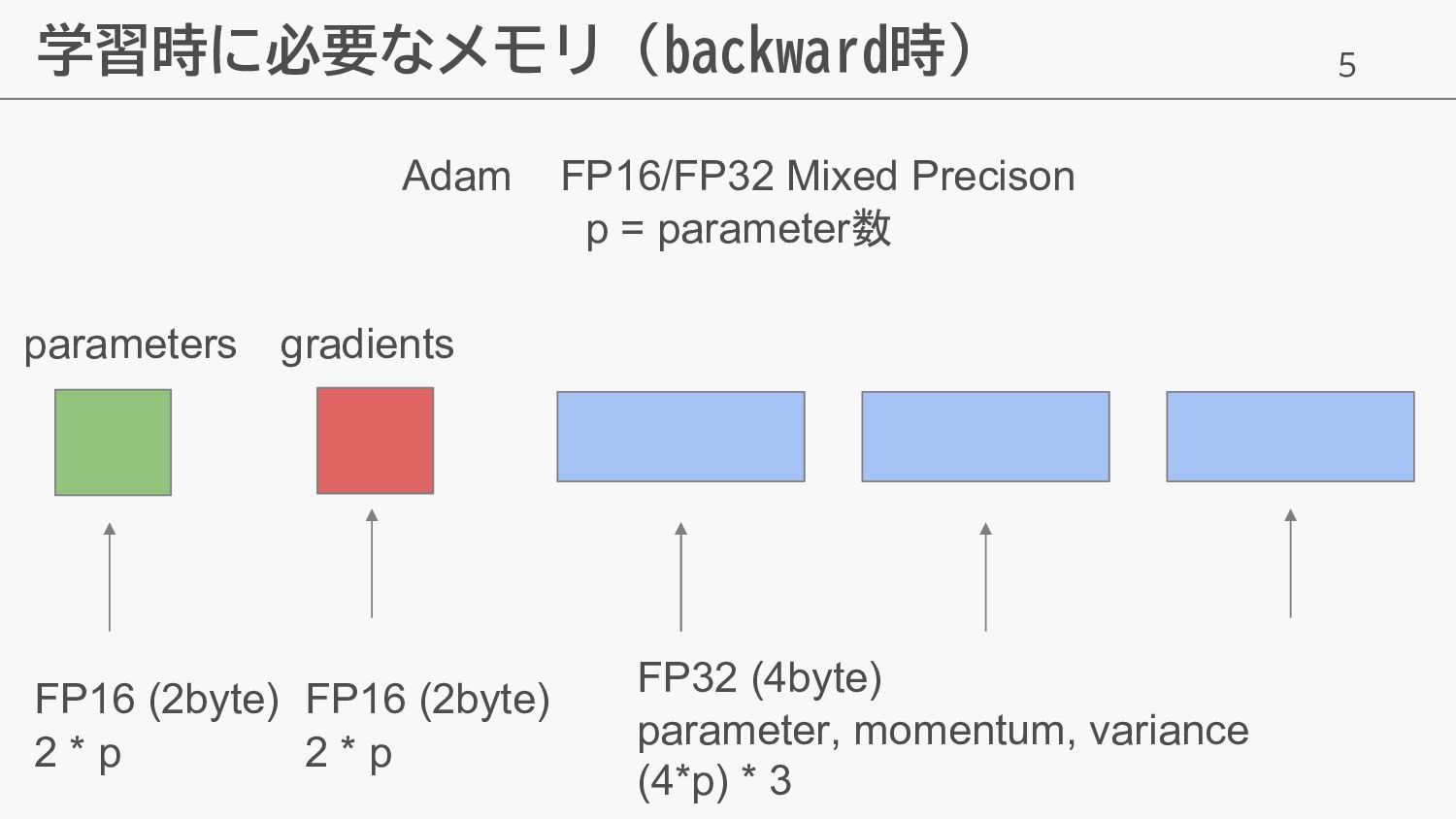
5 学習時に必要なメモリ (backward時) Adam FP16/FP32 Mixed Precison p = parameter数
FP16 (2byte) 2 * p FP16 (2byte) 2 * p parameters gradients FP32 (4byte) parameter, momentum, variance (4*p) * 3
6 学習時に必要なメモリ (backward時) FP16/FP32 Mixed Precison p = parameter数 parameters
gradients optimizer states 2p + 2p + 12p = 16p 必要 → optimizer states はかなり大きい
7 学習時に必要なメモリ (backward時) FP16/FP32 Mixed Precison p = parameter数 parameters
gradients optimizer states 2p + 2p + 12p = 16p 必要 注意: activation、中間層の出力、バッチデータ、 memory fragmentation などあるため、これだけではない
8 言語モデル学習とGPUメモリ(肌感覚) A100 (40GB) : ABCI 等 メモリにのるギリギリのサイズ → GPT-2
1.3B (8GPU) (ZeRO1) 14 * 1.3B = 18.2 GB (定常的) (backward: 20.8GB) + Activation などなど
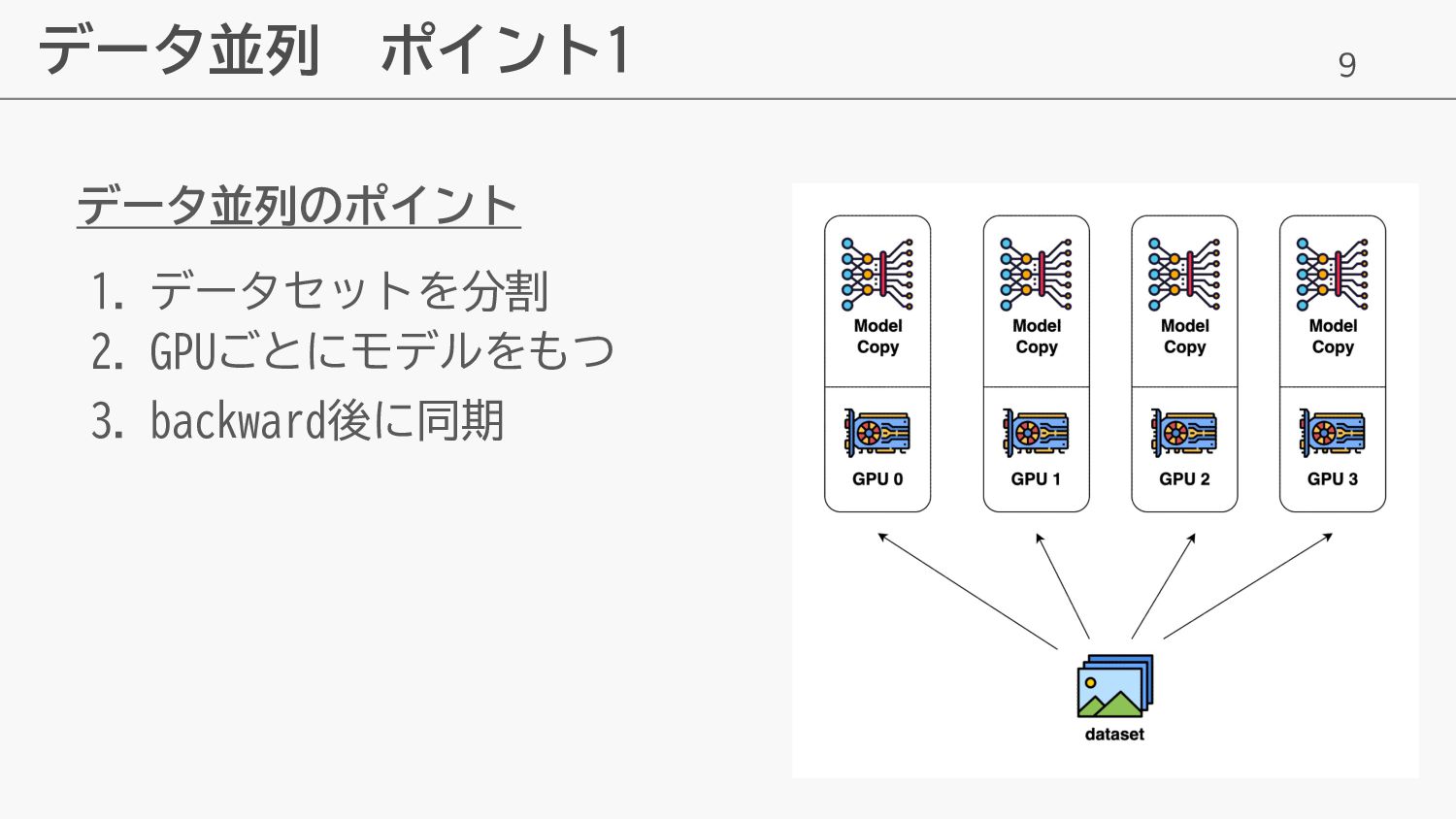
9 データ並列 ポイント1 データ並列のポイント 1. データセットを分割 2. GPUごとにモデルをもつ 3. backward後に同期
10 データ並列 ポイント2 GPUごとにモデルをもつ • forward, backward 処理はそれぞ れ別々に行う •
学習データは別、モデルは一緒 → gradient(勾配) は異なる • 学習に必要なモデル重み, 勾配, Optimizer stateをそれぞれ持つ
11 データ並列 ポイント3 backward後に同期 • 別々のデータで学習しbackwardを行ったので勾配は異なる → All Reduce で同期を行なう
• 勾配の平均でモデル parameter を更新 • 次のstepへ
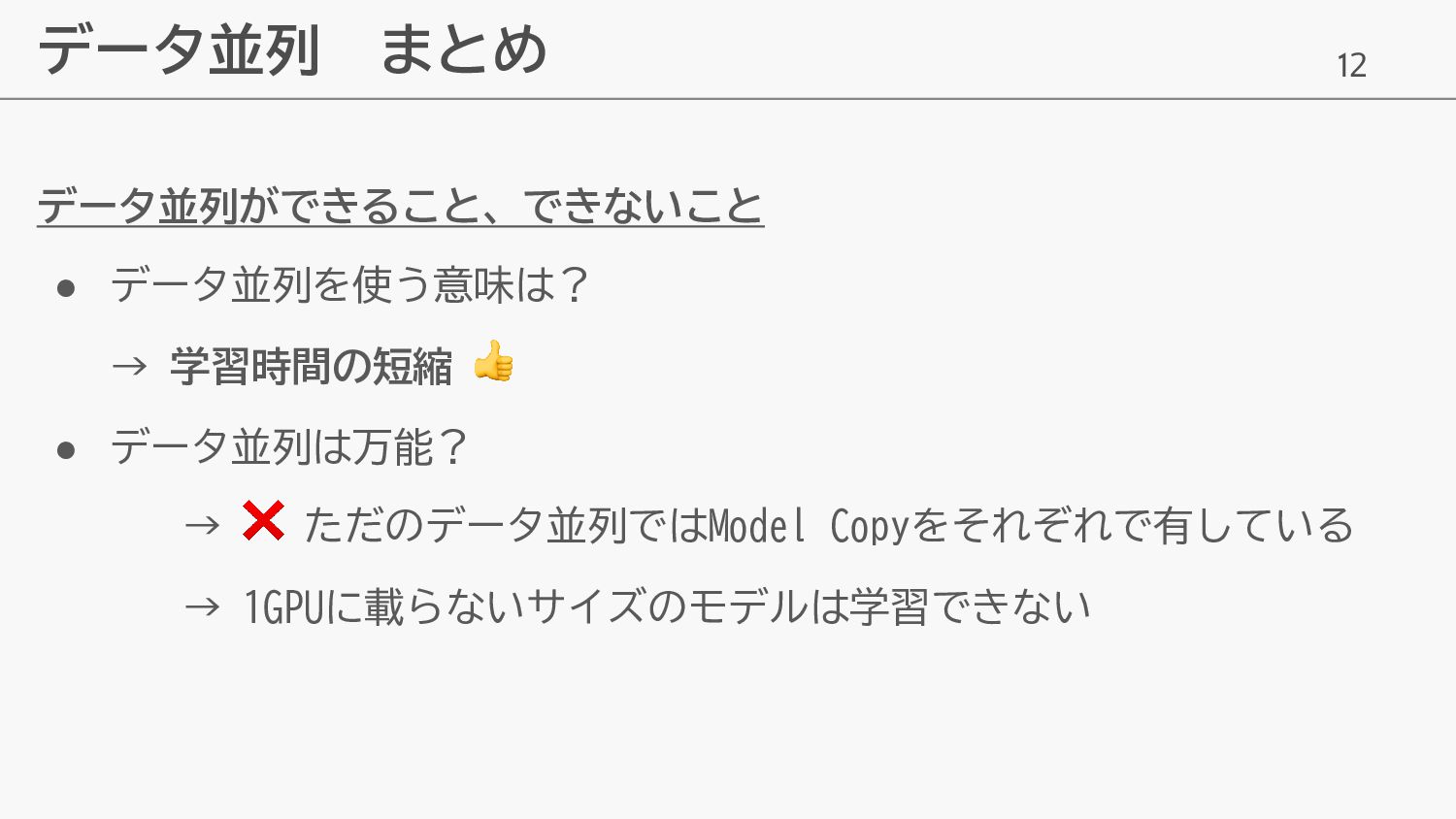
12 データ並列 まとめ データ並列ができること、できないこと • データ並列を使う意味は? → 学習時間の短縮 👍 •
データ並列は万能? → ❌ ただのデータ並列ではModel Copyをそれぞれで有している → 1GPUに載らないサイズのモデルは学習できない
13 ZeRO Stage 1 データ並列 ZeRO 1 GPU: 1 GPU:
2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 Sharding Optimizer States optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
14 再掲: 学習時に必要なメモリ FP16/FP32 Mixed Precison p = parameter数 parameters
gradients optimizer states 2p + 2p + 12p = 16p 必要 注意: activation、中間層の出力、パッチデータ、 memory fragmentation などあるため、これだけではない
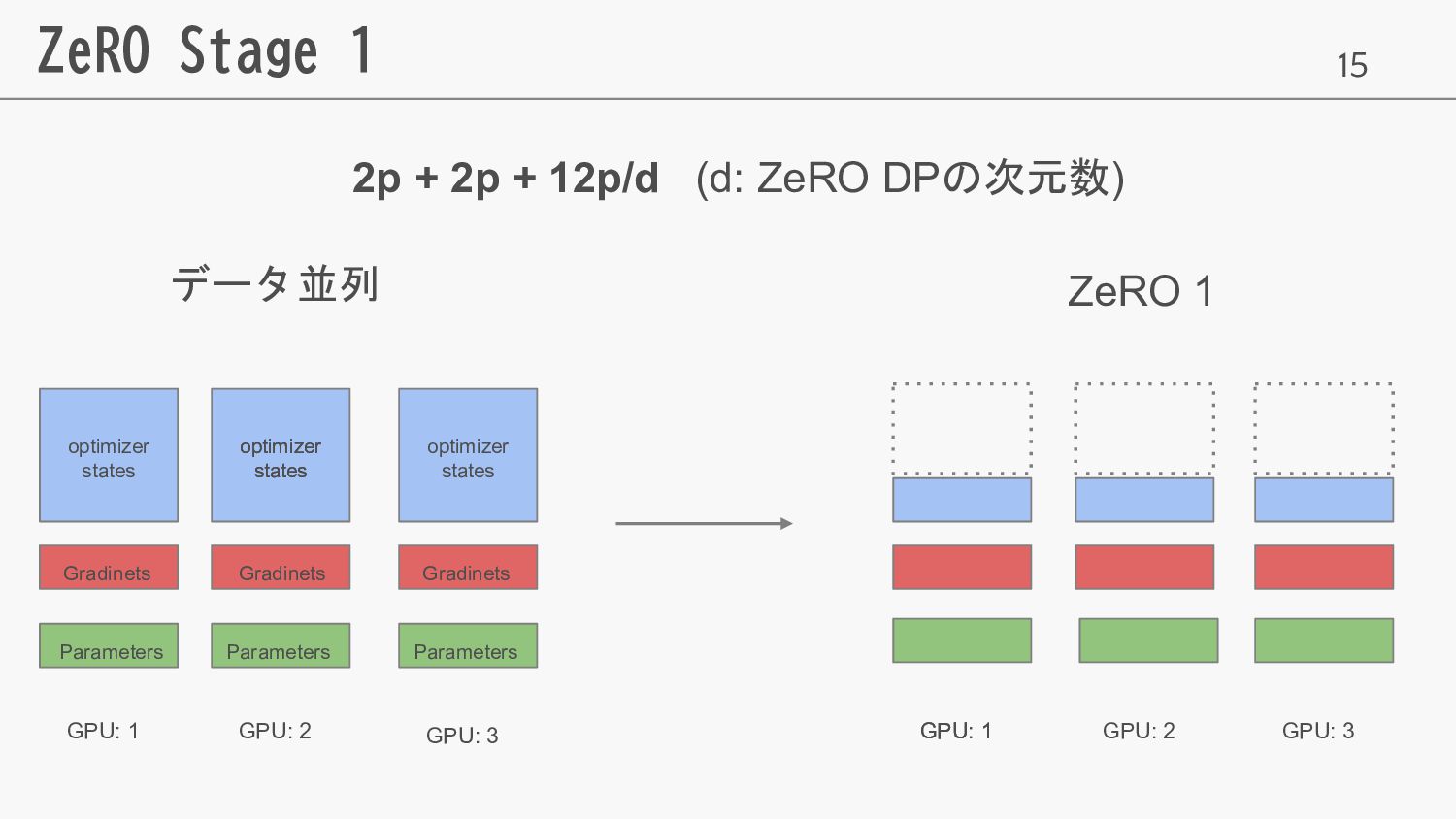
15 ZeRO Stage 1 データ並列 ZeRO 1 GPU: 1 GPU:
2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 2p + 2p + 12p/d (d: ZeRO DPの次元数) optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
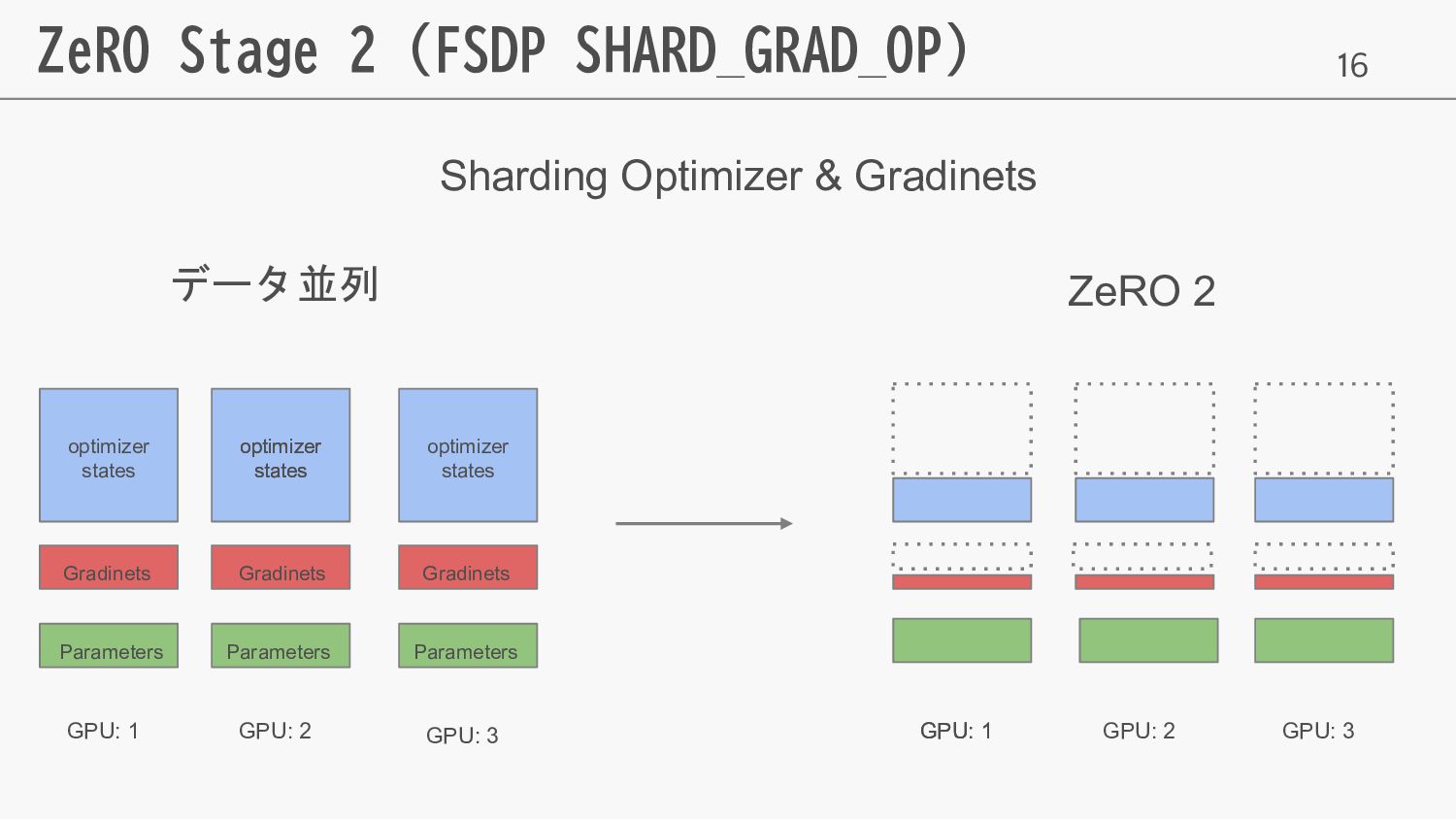
16 ZeRO Stage 2 (FSDP SHARD_GRAD_OP) データ並列 ZeRO 2 GPU:
1 GPU: 2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 Sharding Optimizer & Gradinets optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
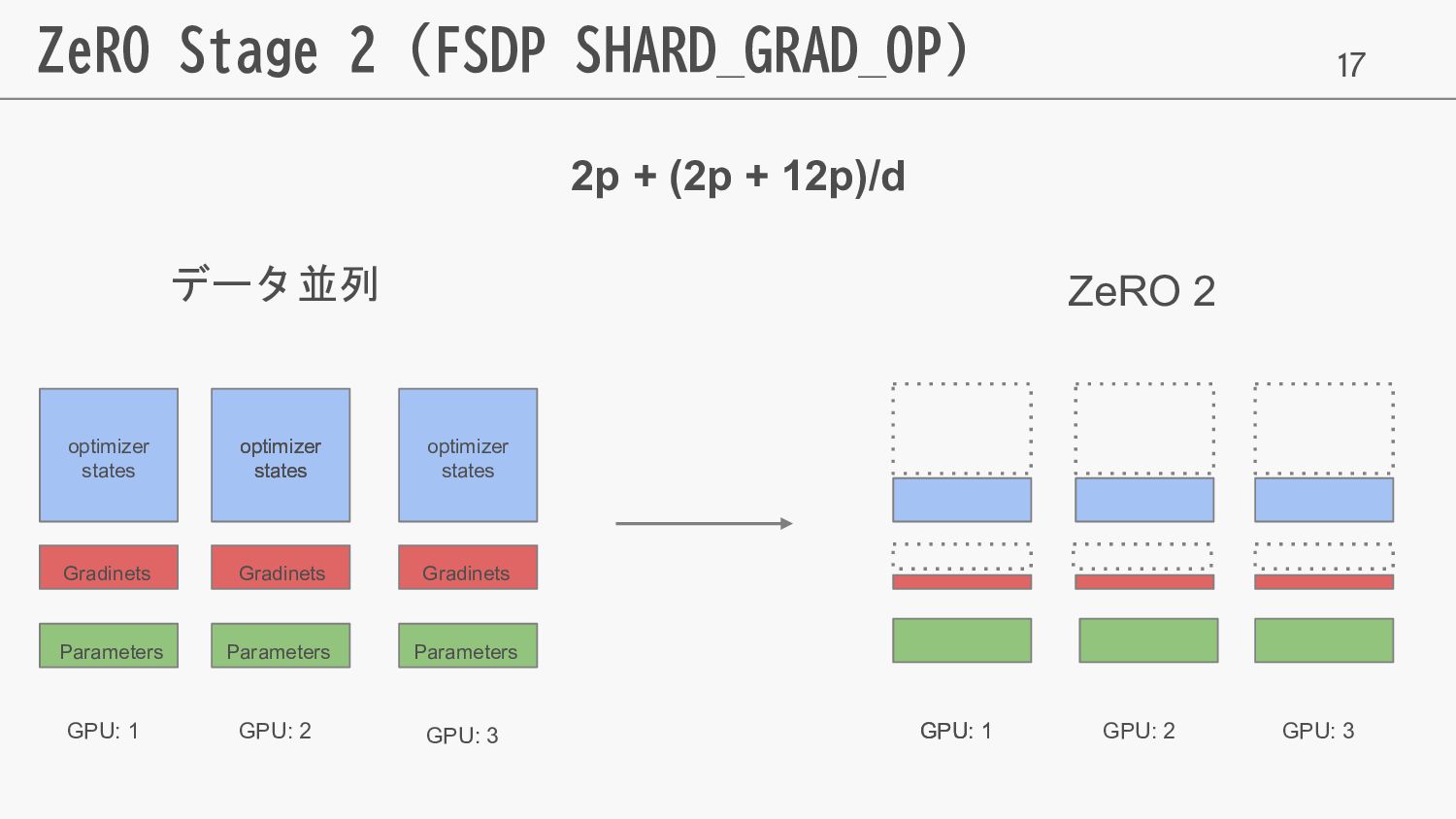
17 ZeRO Stage 2 (FSDP SHARD_GRAD_OP) データ並列 ZeRO 2 GPU:
1 GPU: 2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 2p + (2p + 12p)/d optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
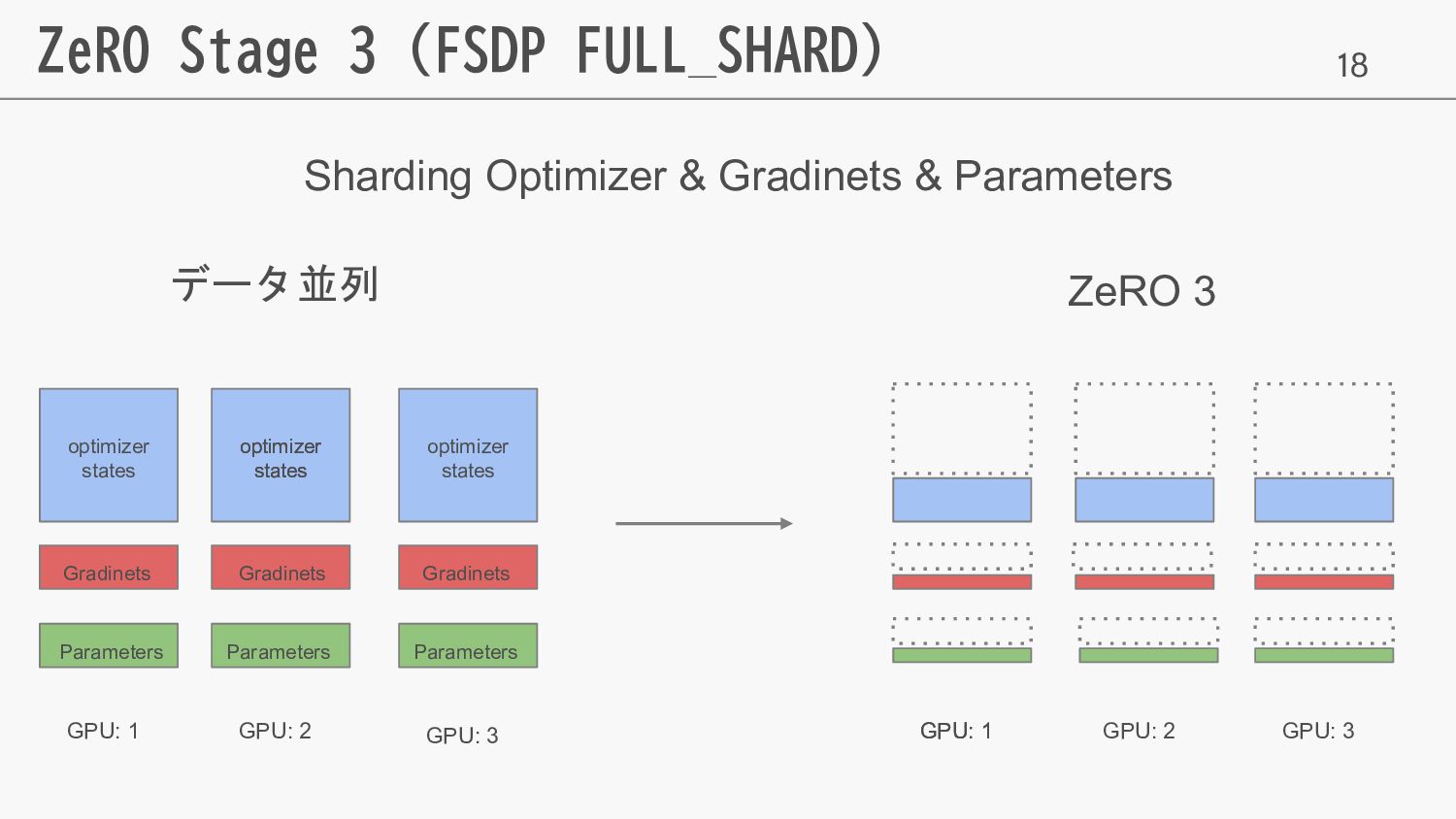
18 ZeRO Stage 3 (FSDP FULL_SHARD) データ並列 ZeRO 3 GPU:
1 GPU: 2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 Sharding Optimizer & Gradinets & Parameters optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
19 ZeRO Stage 3 (FSDP FULL_SHARD) データ並列 ZeRO 3 GPU:
1 GPU: 2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 (2p + 2p + 12p)/d optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
20 おさらい • Adamを利用した学習には 2p + 2p + 12p bytesのメモリが必要
• ZeRO1: 2p + 2p + (12p/d) • ZeRO2: 2p + (2p + 12p)/d • ZeRO3: (2p + 2p + 12p)/d 常にZeRO3を使えばいいの?? → そうでもない。 必要な通信量についても見ていく必要あり → 次へ
21 ZeRO Stage 1 の通信 1 GPU: 1 GPU: 1
GPU: 2 GPU: 3 Parameterは分割されていない → Forwardは普通にできる → 特に通信は発生しない
22 ZeRO Stage 1 の通信 2 各GPUは使用しているmini-batchが 異なる → 計算される勾配が異なる
担当領域分の全プロセスでの勾配を 求める → Scatter Reduce GPU: 1 GPU: 1 GPU: 2 GPU: 3
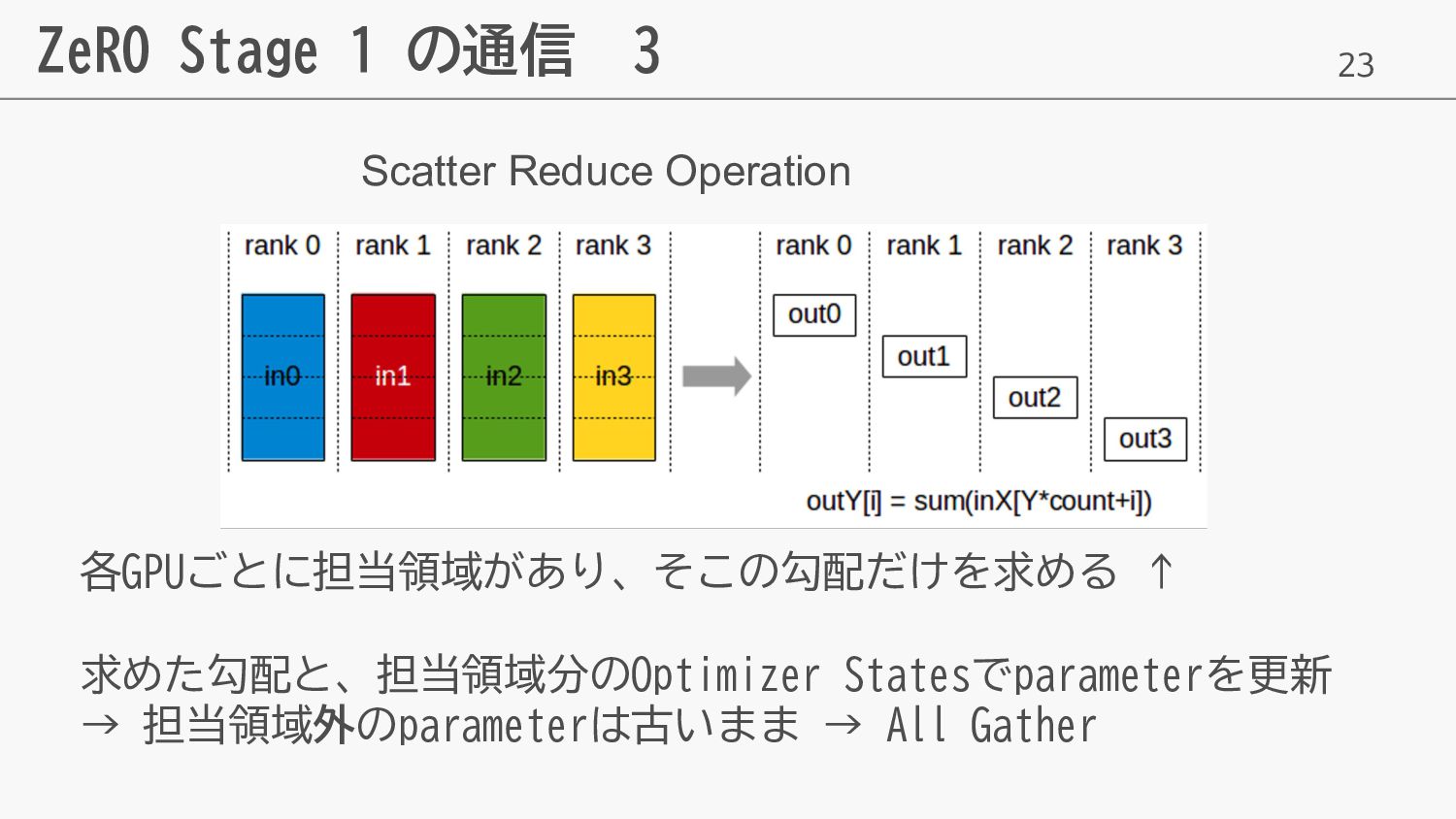
23 ZeRO Stage 1 の通信 3 各GPUごとに担当領域があり、そこの勾配だけを求める ↑ 求めた勾配と、担当領域分のOptimizer Statesでparameterを更新
→ 担当領域外のparameterは古いまま → All Gather Scatter Reduce Operation
24 ZeRO Stage 1 の通信 4 各GPUが担当している領域のparameterを全体に行き渡らせる → 1 step
終了 All Gather Operation
25 ZeRO Stage 1 の通信 5 通信量はどうなった? → 実は変わっていない DPで使用した
All-ReduceとはReduce Scatter + All Gatherの演算 → 別々のタイミングで行っただけで通信量は増えていない → DPと同じ通信負荷
26 ZeRO Stage 2 の通信 1 GPU: 1 GPU: 1
GPU: 2 GPU: 3 Parameterは分割されていない → Forwardは普通にできる → 特に通信は発生しない
27 ZeRO Stage 2 の通信 2 各GPUは使用しているmini-batchが 異なる → 計算される勾配が異なる
担当領域分の全プロセスでの勾配を 求める → Scatter Reduce GPU: 1 GPU: 1 GPU: 2 GPU: 3
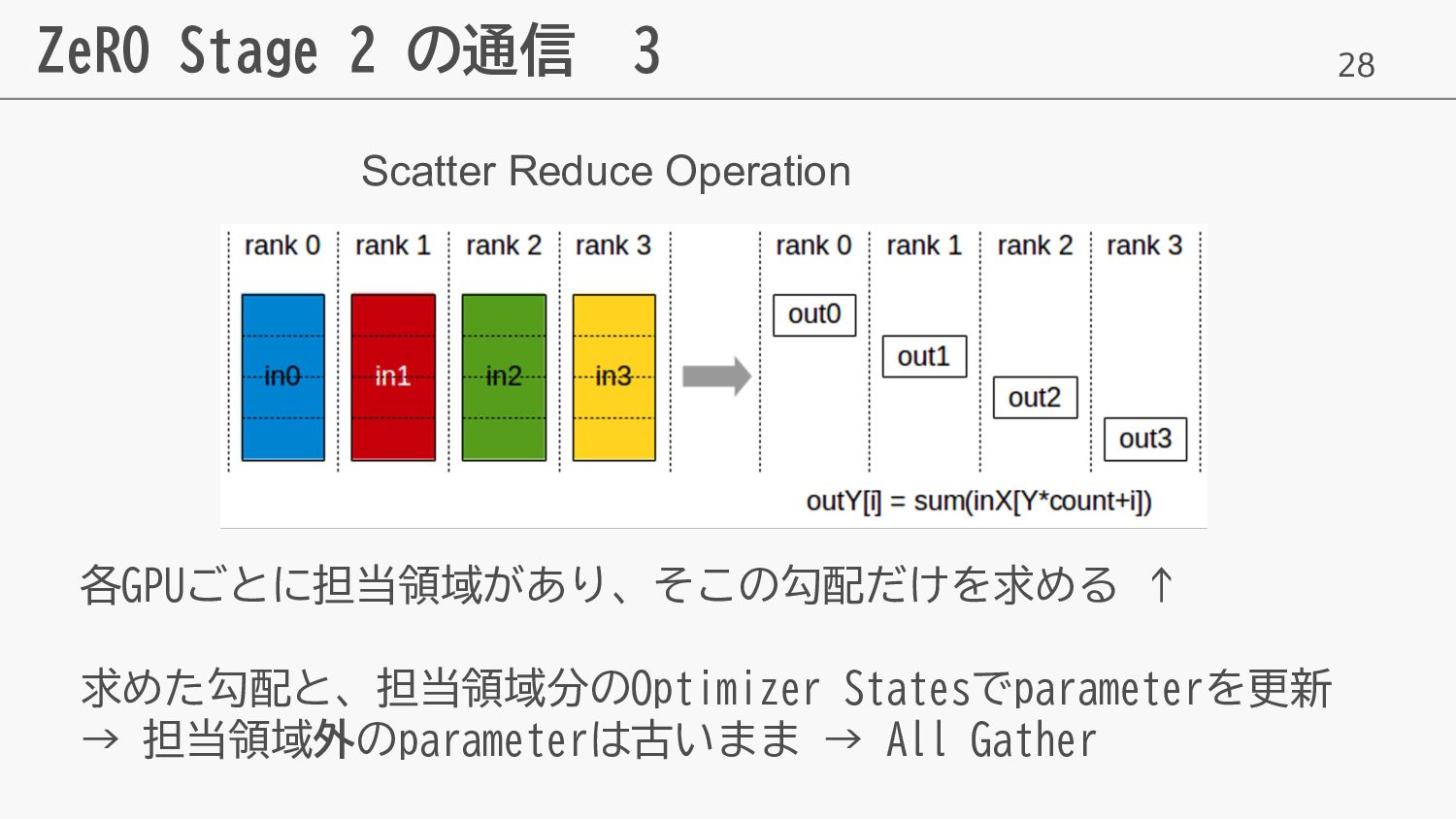
28 ZeRO Stage 2 の通信 3 各GPUごとに担当領域があり、そこの勾配だけを求める ↑ 求めた勾配と、担当領域分のOptimizer Statesでparameterを更新
→ 担当領域外のparameterは古いまま → All Gather Scatter Reduce Operation
29 ZeRO Stage 2 の通信 4 通信量はどうなった? → 実は変わっていない 通信量において、DP
= ZeRO 1 = ZeRO 2 → ZeRO DPだけ利用するならZeRO 2を使えばメモリ上お得 ! → ではどうして、ZeRO1なんてあるのか? → 3D Parallelism との兼ね合い (時間があれば説明します)
30 ZeRO Stage 3 の通信 1 GPU: 1 GPU: 1
GPU: 2 GPU: 3 Parameterまで分割されている → Forwardすらできない → 必要なタイミングでparameterを 集める 全体で見るとAll Gatherと等価
31 ZeRO Stage 3 の通信 2 GPU: 1 GPU: 1
GPU: 2 GPU: 3 “必要なタイミングでparameterを集める” → どうして一度に集めないのか? → 直近のforwardで必要でないものも 集めるとメモリが逼迫してしまう → All Gatherを reschedule している とも言える
32 ZeRO Stage 3 の通信 3 GPU: 1 GPU: 1
GPU: 2 GPU: 3 その後は ZeRO 1, ZeRO2 と同じ Scatter Reduce + All Gather そのため全体では All Gather → Scatter Reduce → All Gather となる → 通信量が 1.5倍になる → 通信負荷もその分、かかる
33 おさらい 通信量は DP = ZeRO 1 = ZeRO 2
< ZeRO3 定量的には DPの通信量を1とすると ZeRO 3は1.5 → モデルサイズが大きいときは、増加分がそれなりに影響
34 ライブラリの紹介 30B 未満のモデルの学習用 PyTorch FSDP backend Swallow Projectでも使用
35 ライブラリの使い方
少し発展的内容
37 ZeRO 3で遅い場合に考えること ZeRO 2 → ZeRO 3とするといきなり大幅に遅くなる場合 ライブラリ側の問題の可能性もあるが、基本は以下が原因 1.
batch per device をZeRO 2から増加させていない 2. ノード間の通信が遅い a. Interconnectそのものが遅い → InfiniBand等に切り替える a. トポロジー配置が悪い → 特定のネットワークスイッチに通信が集中 → ボトルネックに
38 3D Parallelism と ZeRO 2 パイプライン並列は、micro batchの勾配とaccumulateする → Gradientが分散されているZeRO
2では、余計な通信を行う必要 がある → 3D Parallelism と組み合わせる場合は、ZeRO 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}