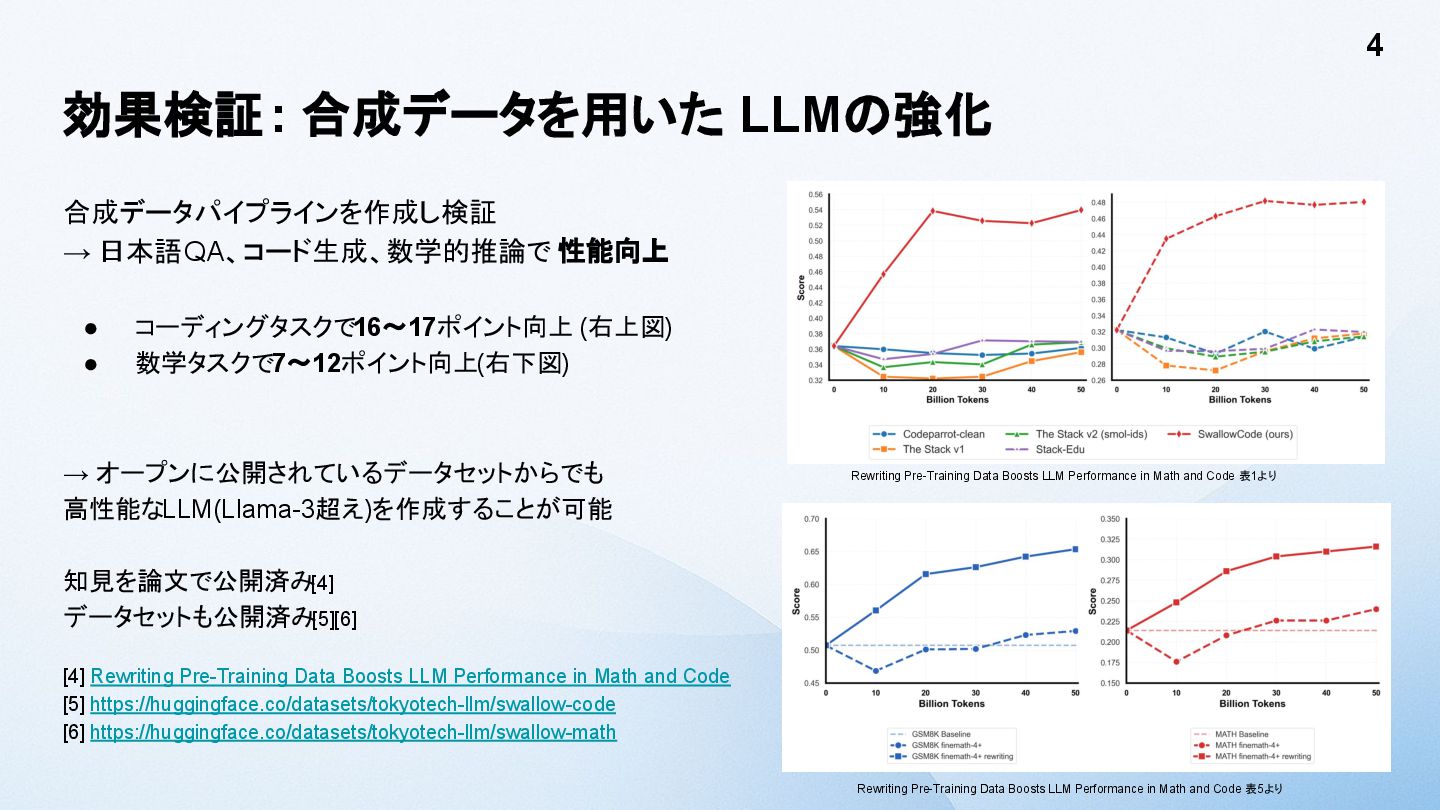
• 数学タスクで7〜12ポイント向上(右下図) → オープンに公開されているデータセットからでも 高性能なLLM(Llama-3超え)を作成することが可能 知見を論文で公開済み[4] データセットも公開済み[5][6] [4] Rewriting Pre-Training Data Boosts LLM Performance in Math and Code [5] https://huggingface.co/datasets/tokyotech-llm/swallow-code [6] https://huggingface.co/datasets/tokyotech-llm/swallow-math 4 Rewriting Pre-Training Data Boosts LLM Performance in Math and Code 表1より Rewriting Pre-Training Data Boosts LLM Performance in Math and Code 表5より
{kind=link}
{kind=link}
![背景: 合成データの利用 Microsoft Research Phi [1] 以降、LLMを利用して作成された”合成データ”の利用が進んでいる[2]。 GPT-5の学習でも使用されていることが明言されている[3]。 • 合成データの利点](https://files.speakerdeck.com/presentations/b3d541f6a2b44696b4631423c46609bf/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}