NVIDIA AI Summit 2024 Japan Tokyo
https://www.nvidia.com/ja-jp/events/ai-summit/
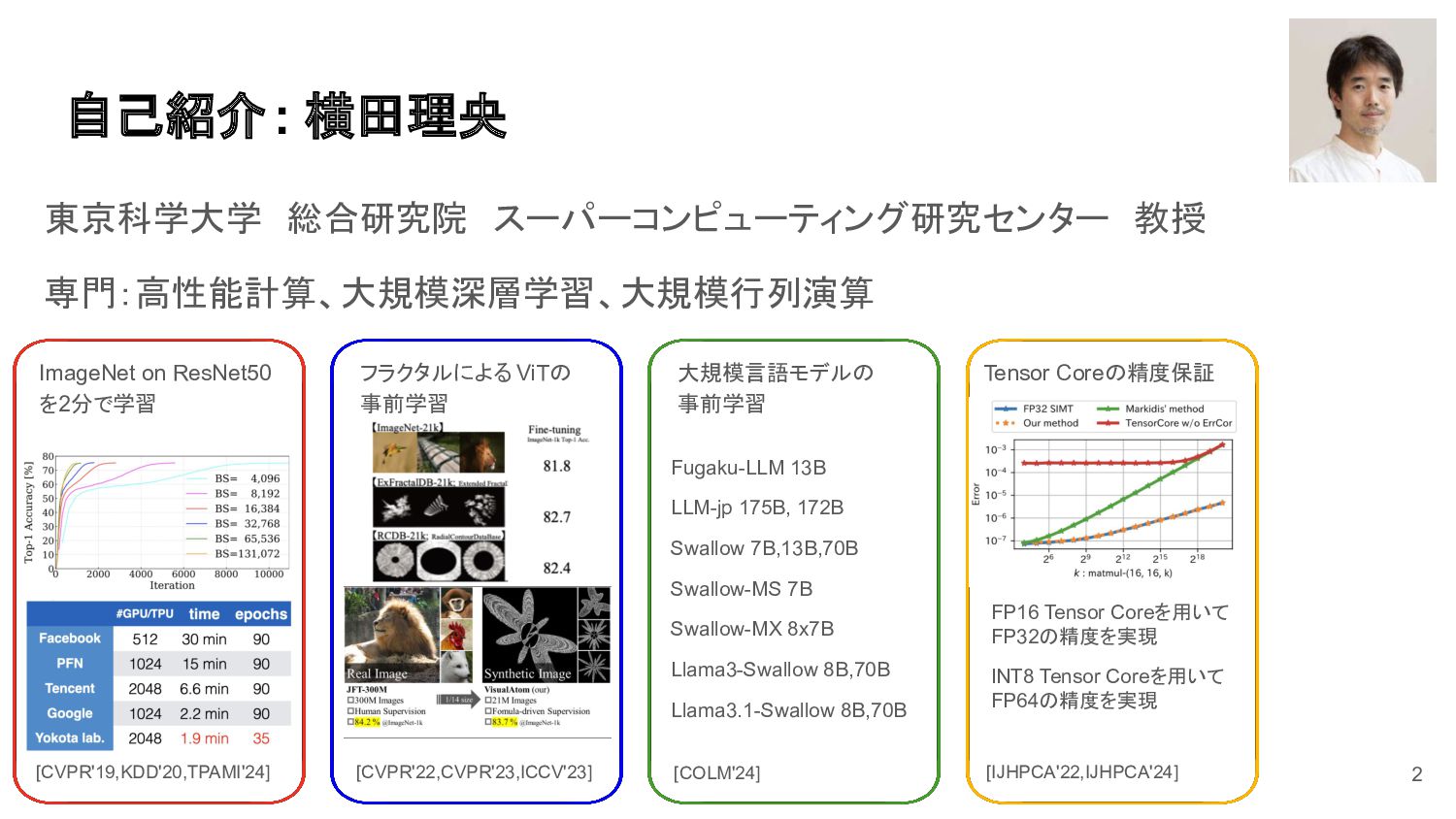
横田理央 , 教授, 東京科学大学
藤井一喜, 修士課程, 東京科学大学
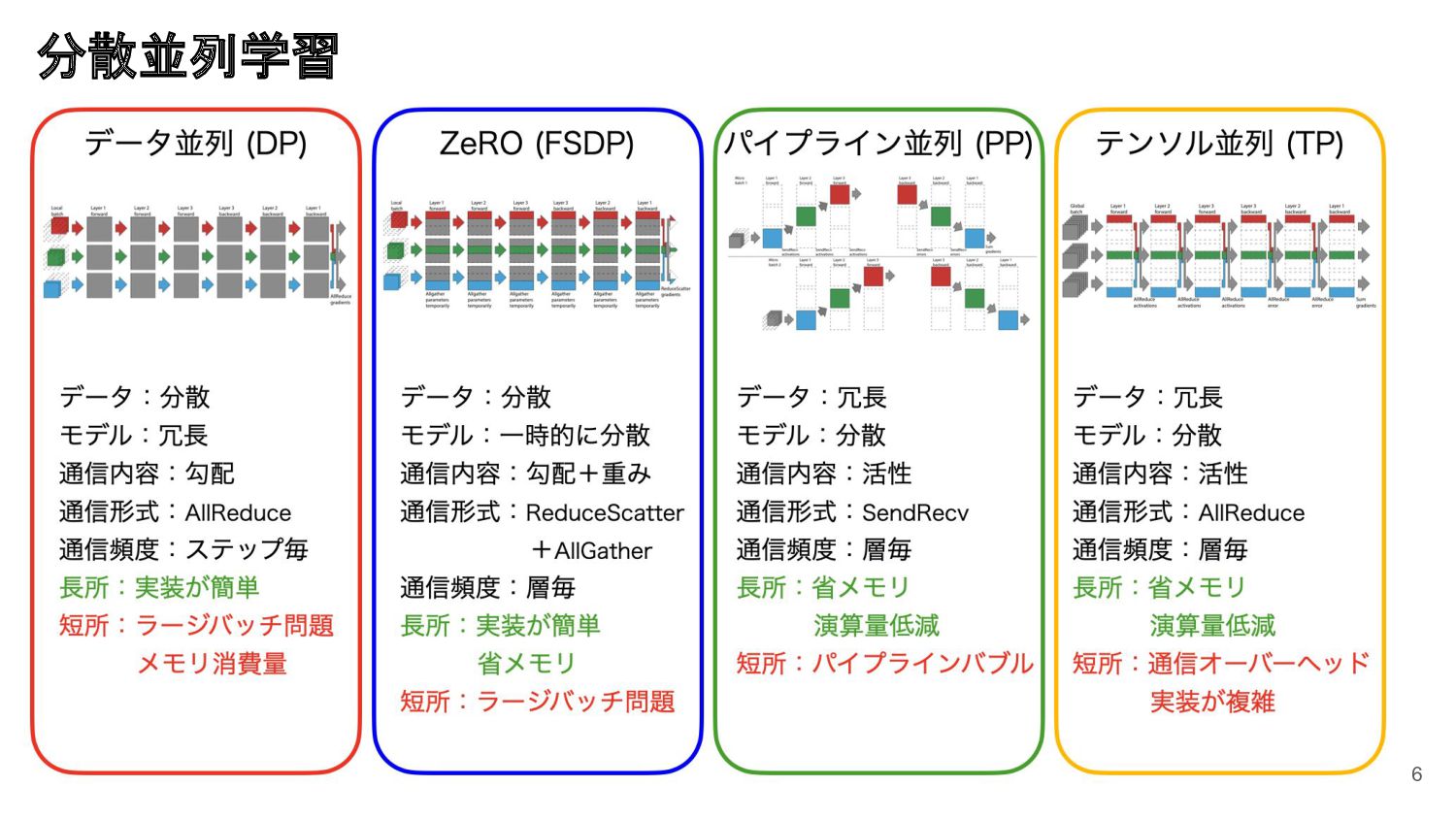
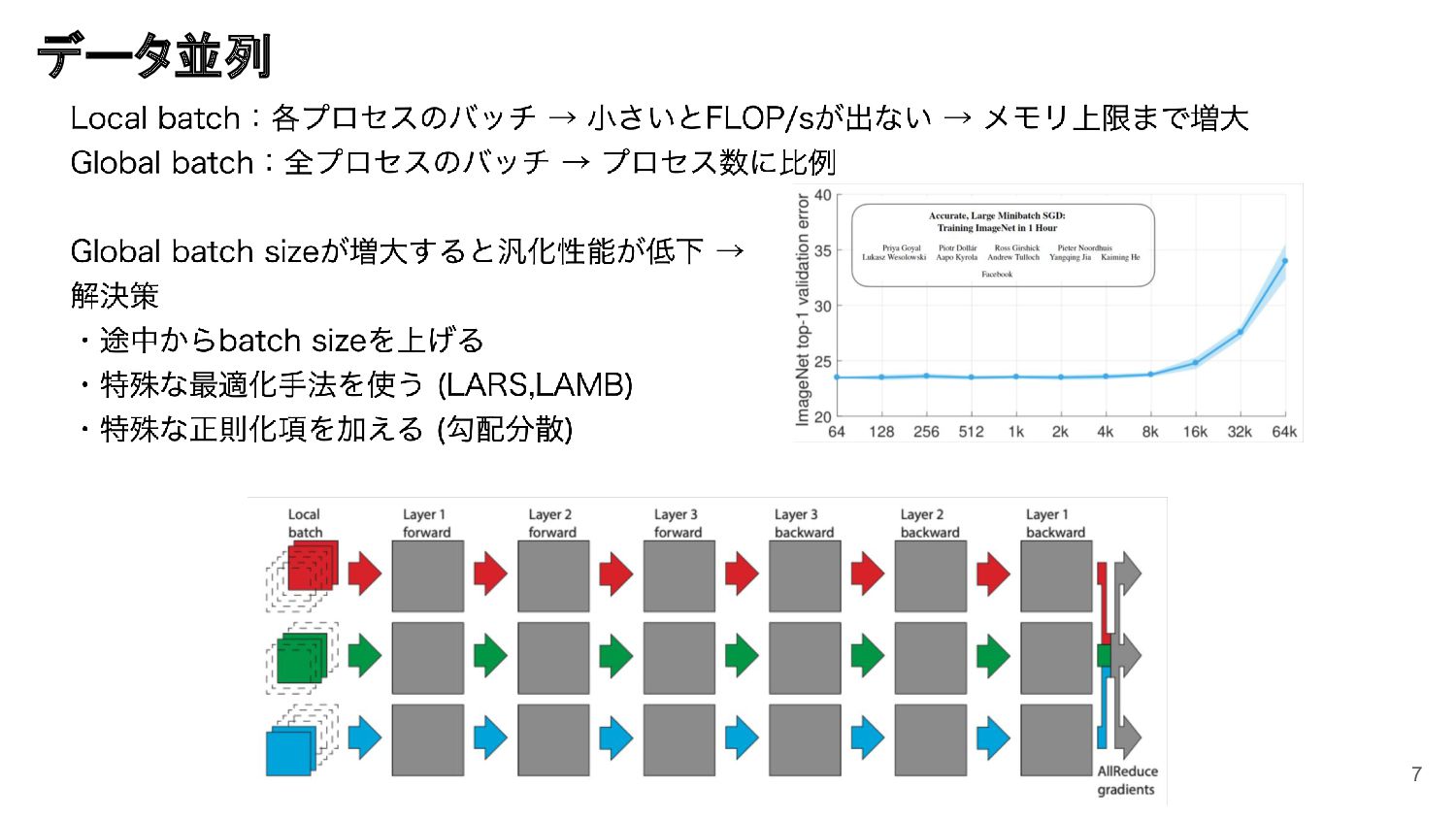
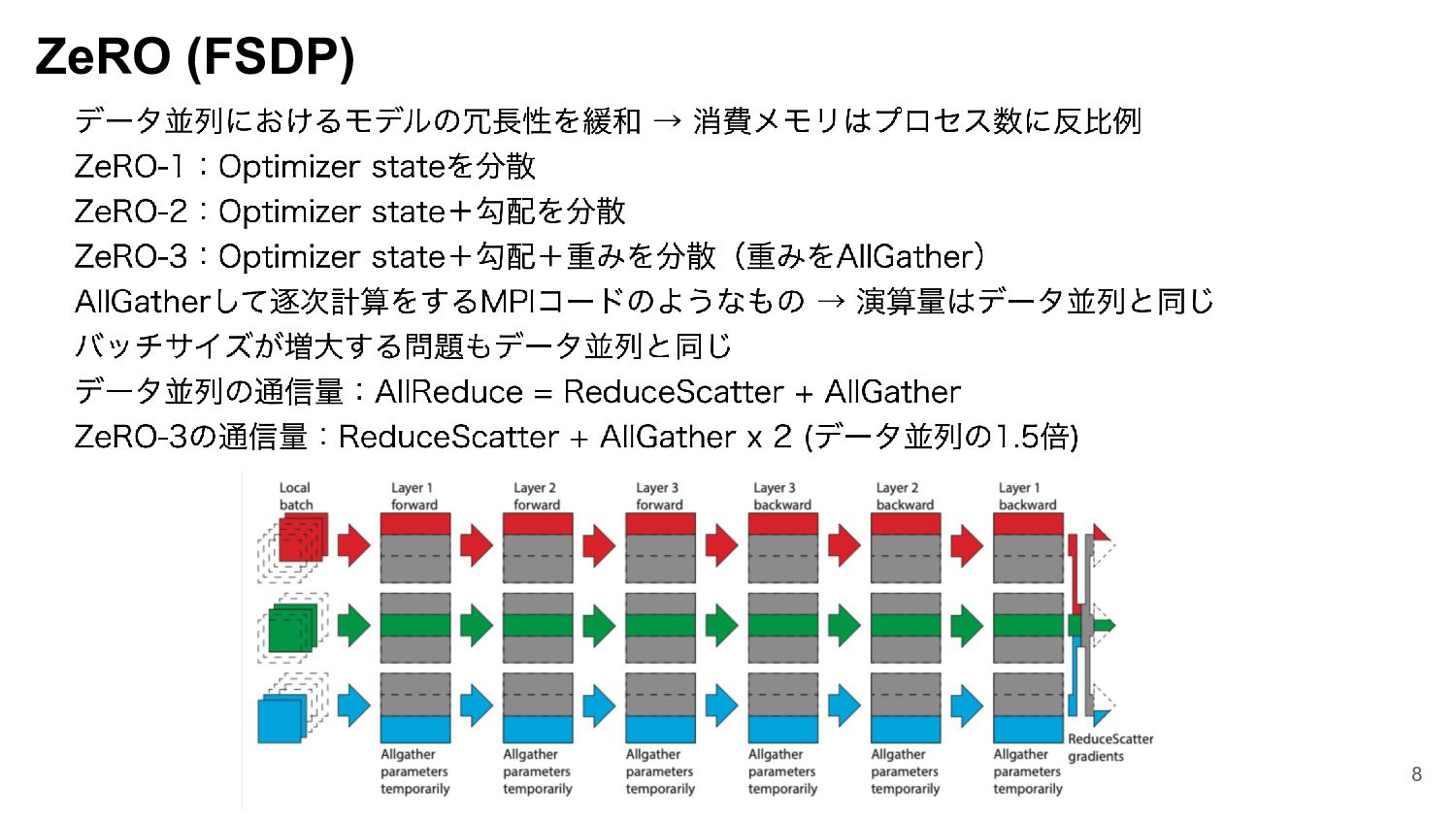
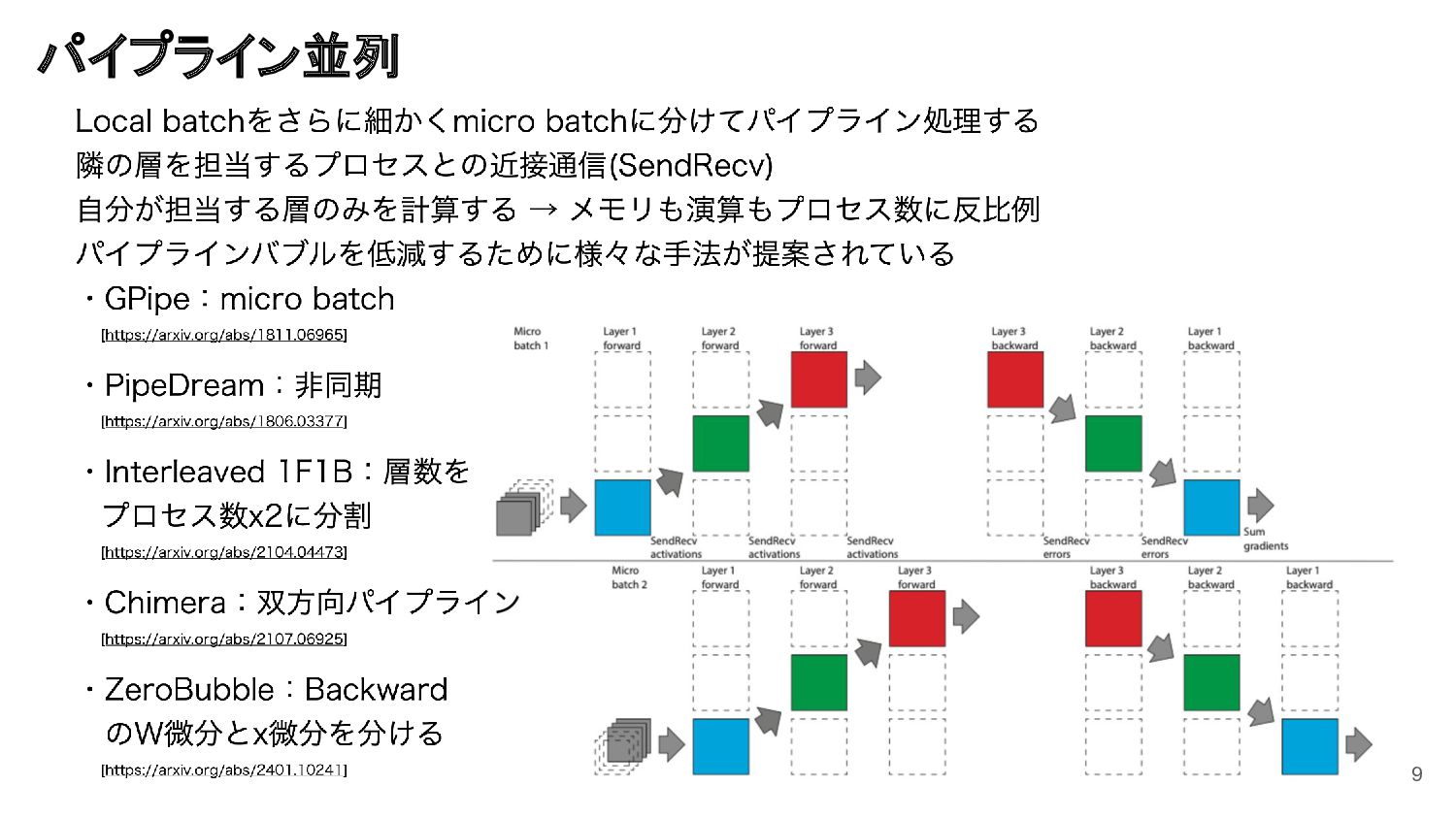
GENIAC プロジェクトにおける 172B 規模の LLM の学習をはじめとする大規模モデルの学習には、分散学習に関する知識と、大規模な計算機環境を使いこなす知見が必要です。本セッションでは、Megatron-LM を用いた大規模モデルの実例と知見について紹介します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
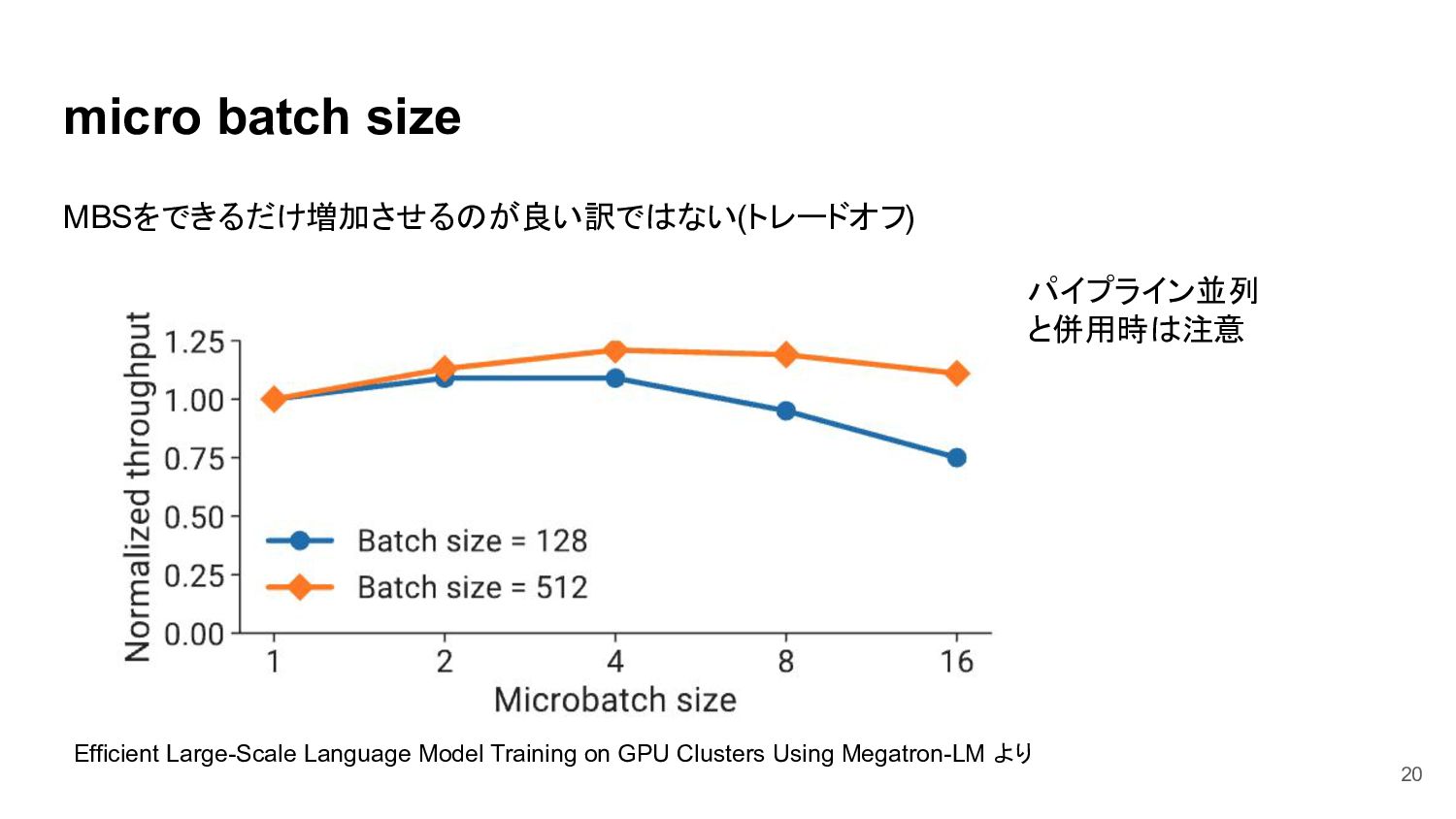{kind=link}
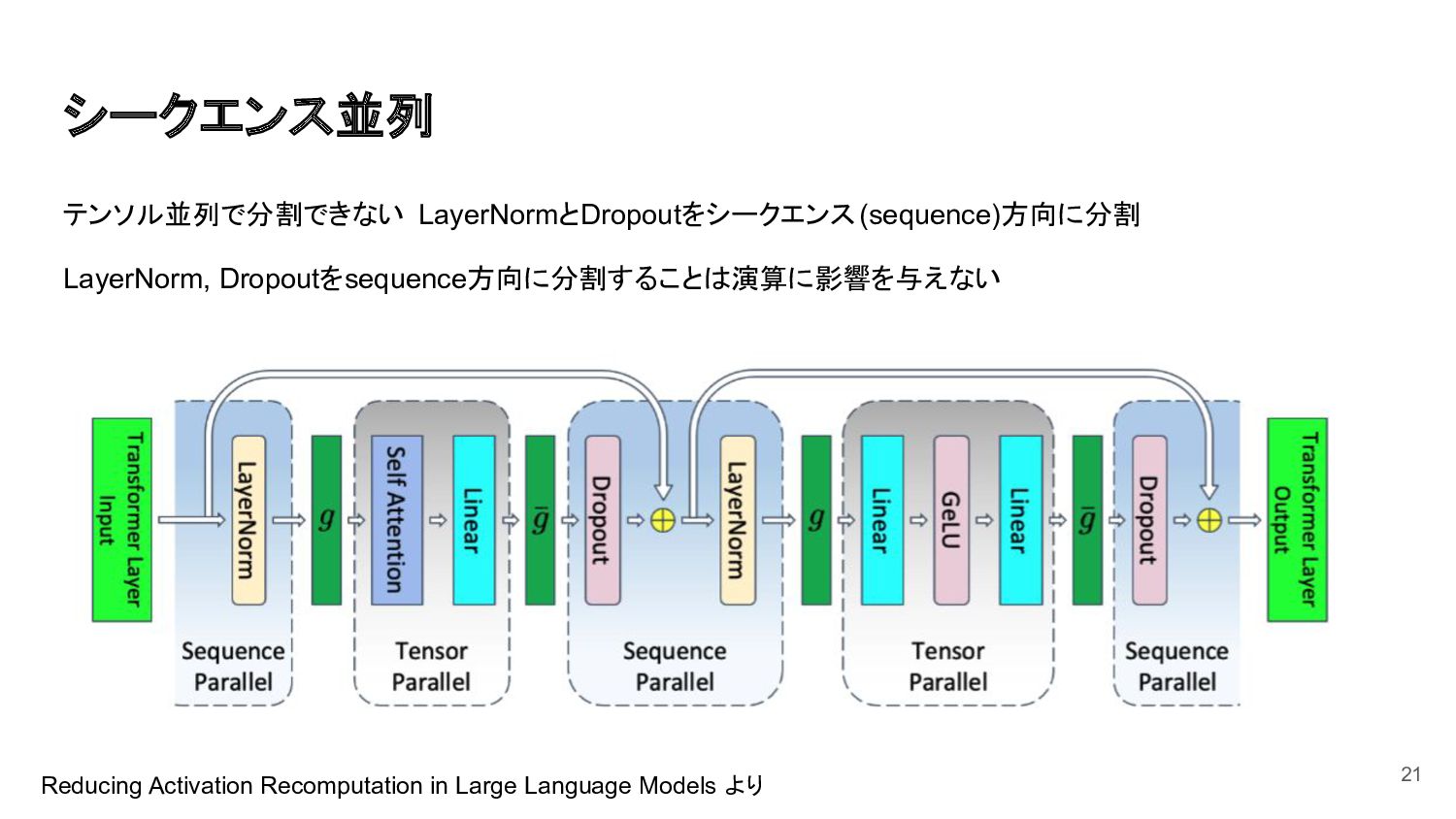{kind=link}
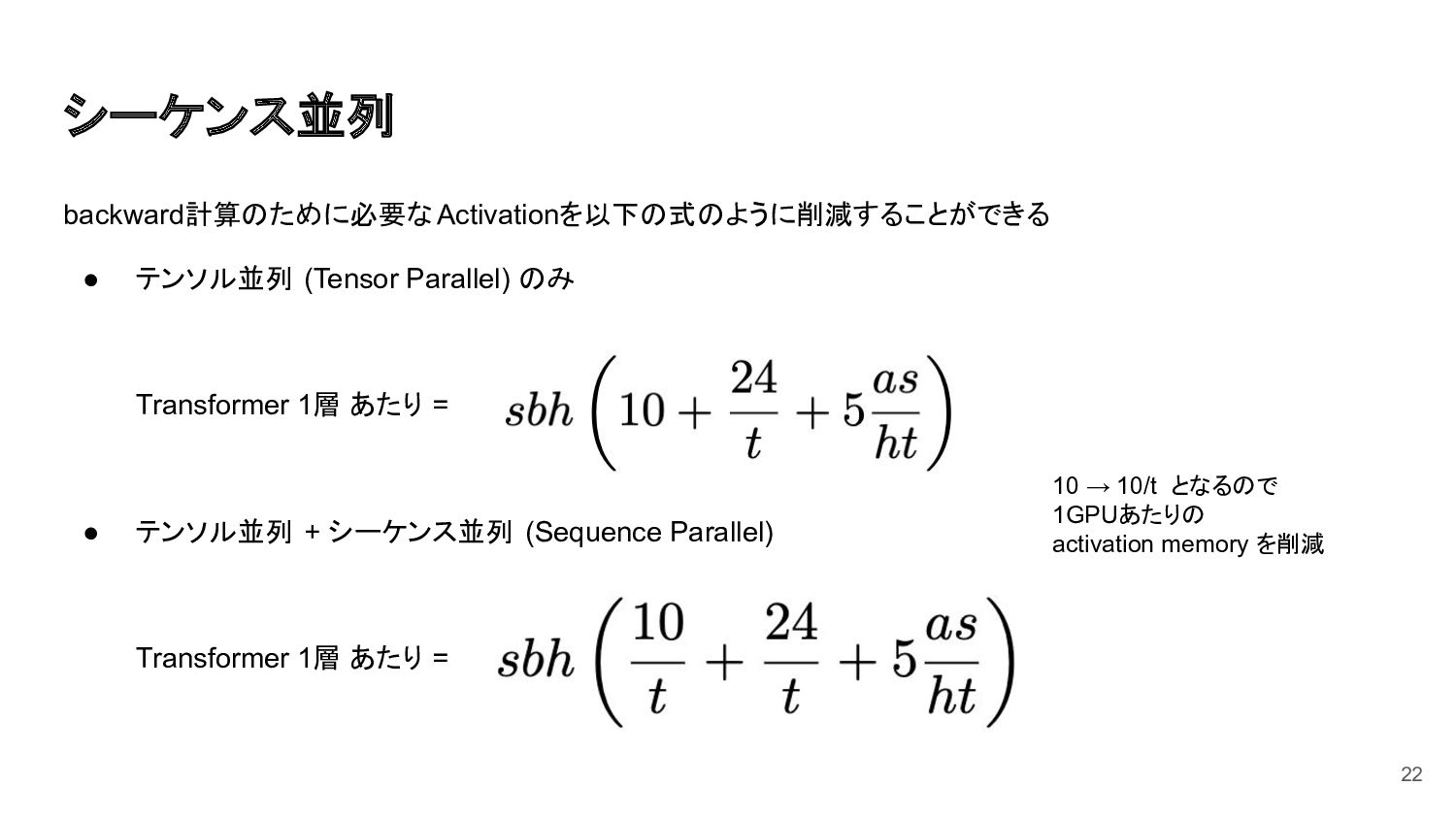{kind=link}
{kind=link}
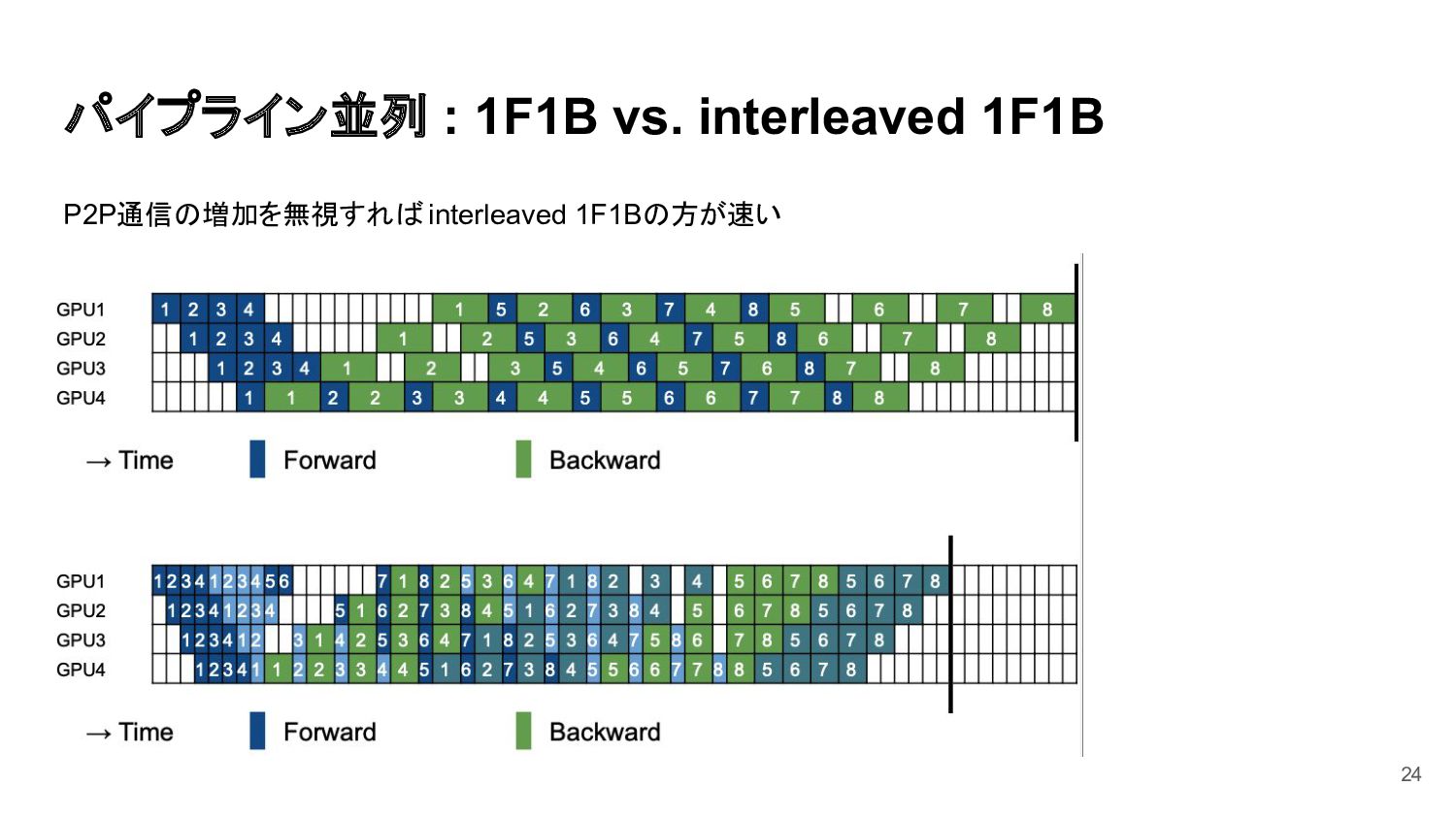{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
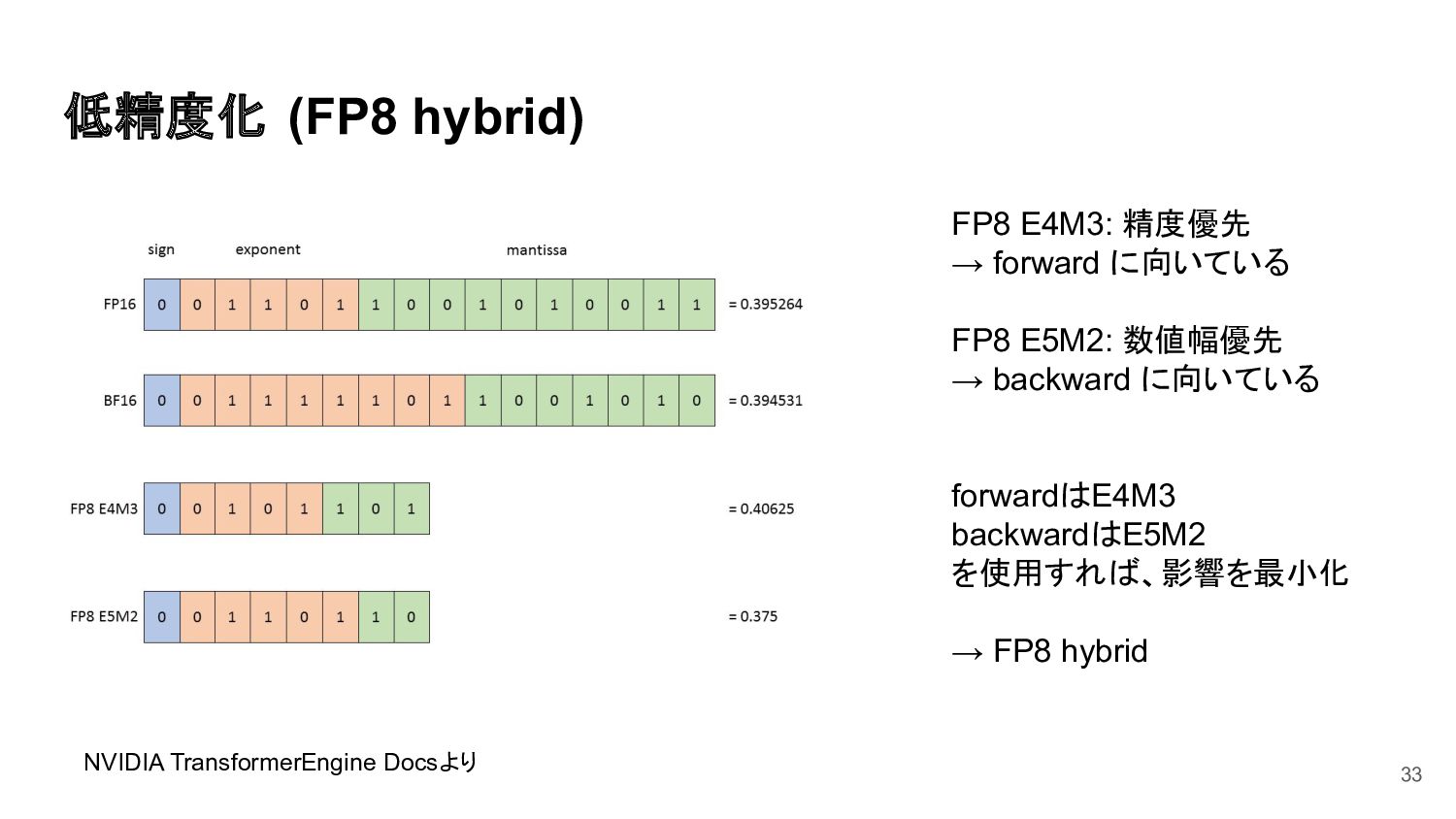{kind=link}
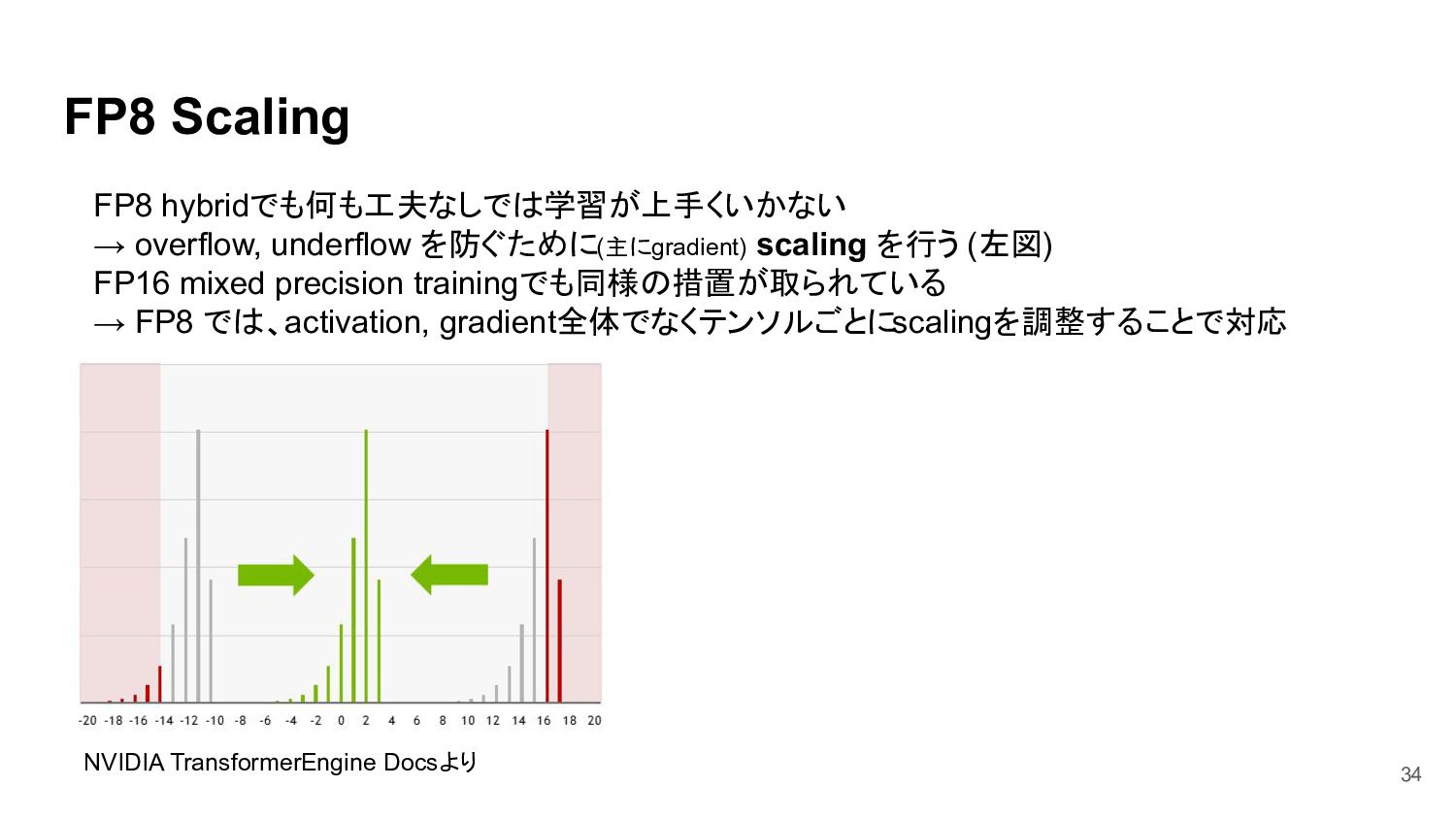{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}