しかし、Llama-3からの継続事前学習では、100Bトークン未満でも学習の不安定化、下流タスクの性能低下を招く[2] FP8をMLPに導入することにより高速化できるスループットは実用的には高々1.3倍 (Hopper) → 複雑な提案法の多くはbaselineのチューニング不足を解消するとFP8を導入した恩恵を相殺 してしまう → NVIDIAのBlockwise FP8, MXFP8[3]を導入することが最も実用的 (学会にAcceptされる手法ではなく、NVIDIAがGTCで発表する手法の方が実用に耐える) 12 [1] FP8 Format for Deep Learning https://arxiv.org/abs/2209.05433 [2] Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs https://arxiv.org/abs/2411.08719 [3] Microscaling Data Formats for Deep Learning https://arxiv.org/abs/2310.10537 Llama-3-70Bからの継続事前学習 (BF16/FP8 DelayedScaling)
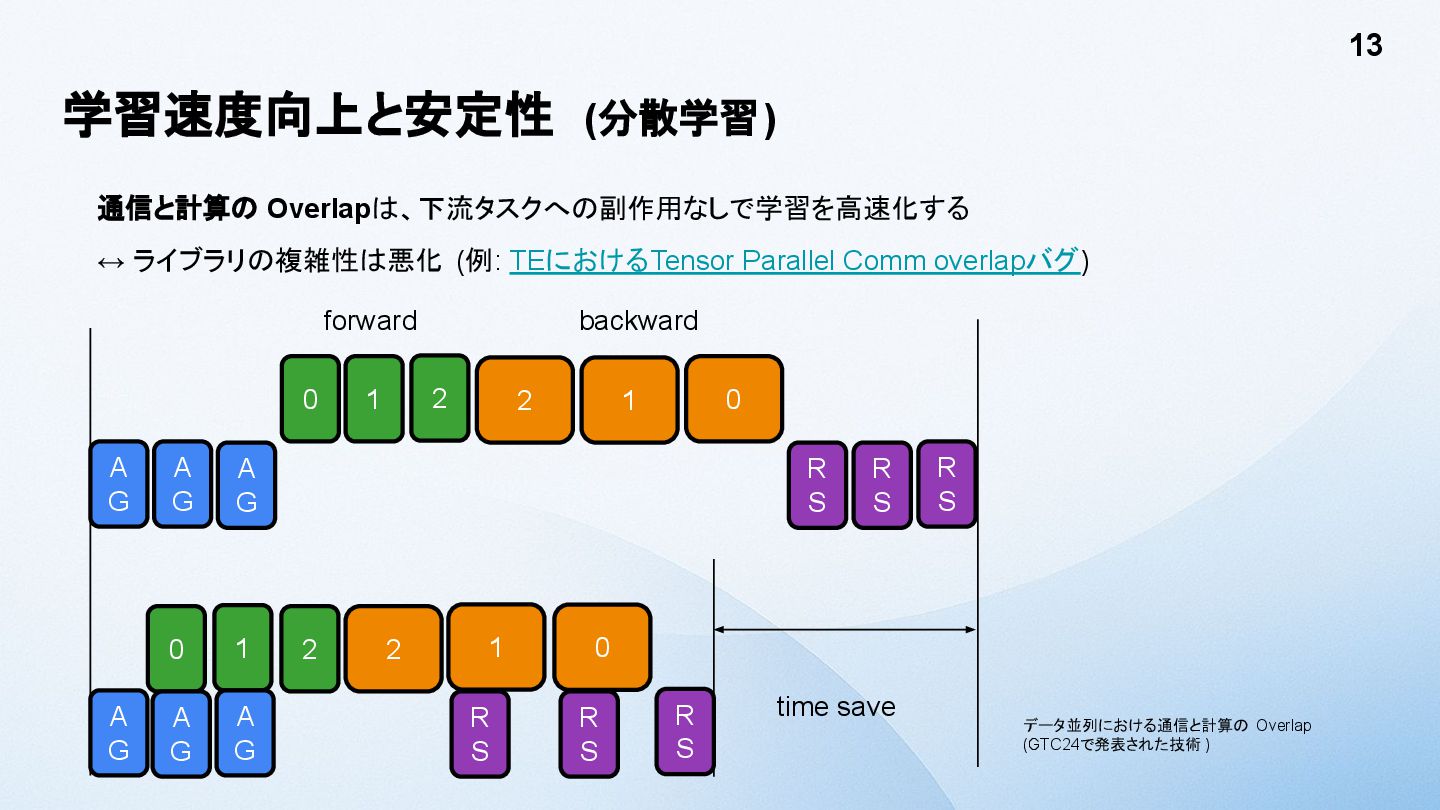
1 2 forward 2 1 0 R S R S R S backward A G 0 1 2 A G A G 2 R S 1 0 R S R S time save 通信と計算の Overlapは、下流タスクへの副作用なしで学習を高速化する ↔ ライブラリの複雑性は悪化 (例: TEにおけるTensor Parallel Comm overlapバグ) データ並列における通信と計算の Overlap (GTC24で発表された技術 )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
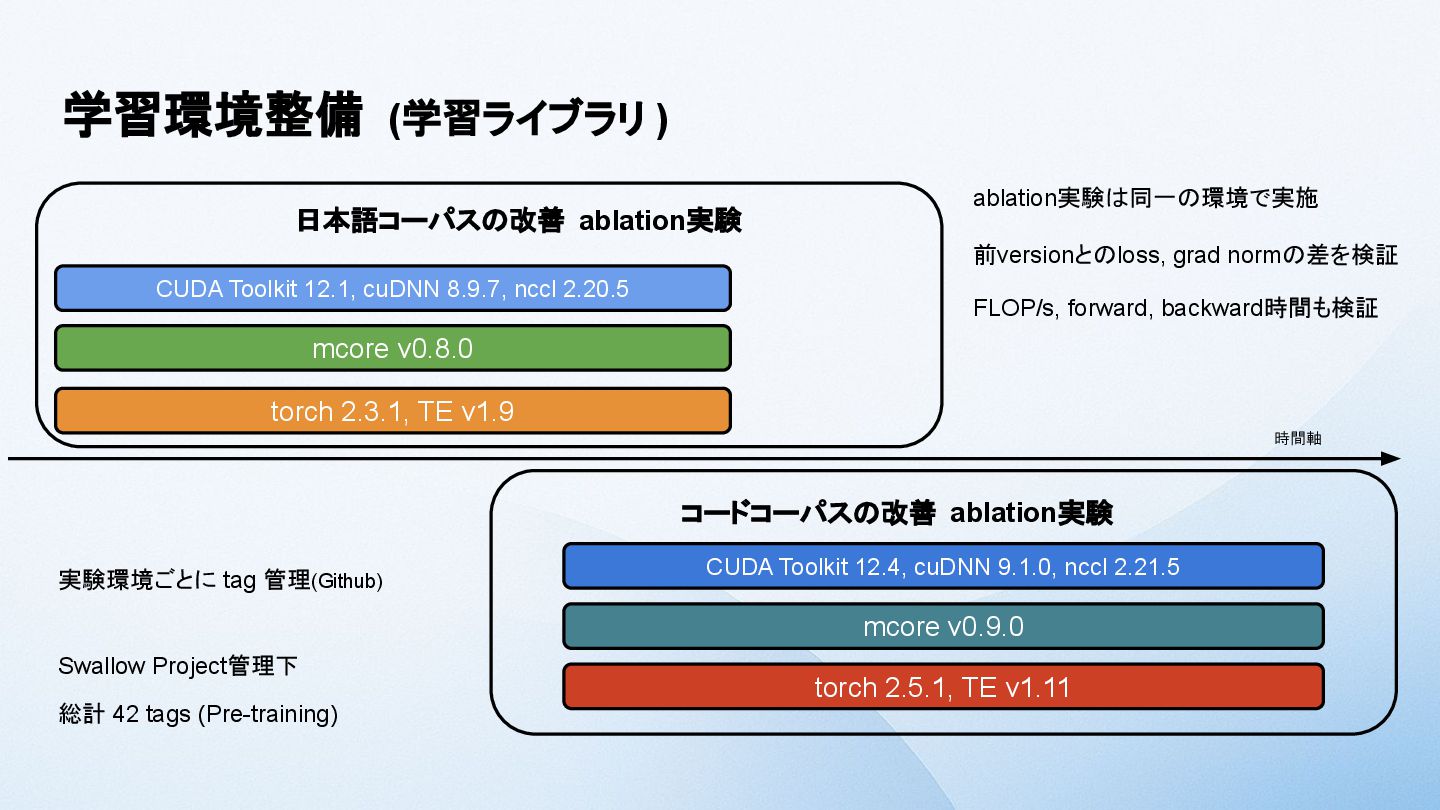{kind=link}
{kind=link}
{kind=link}
{kind=link}
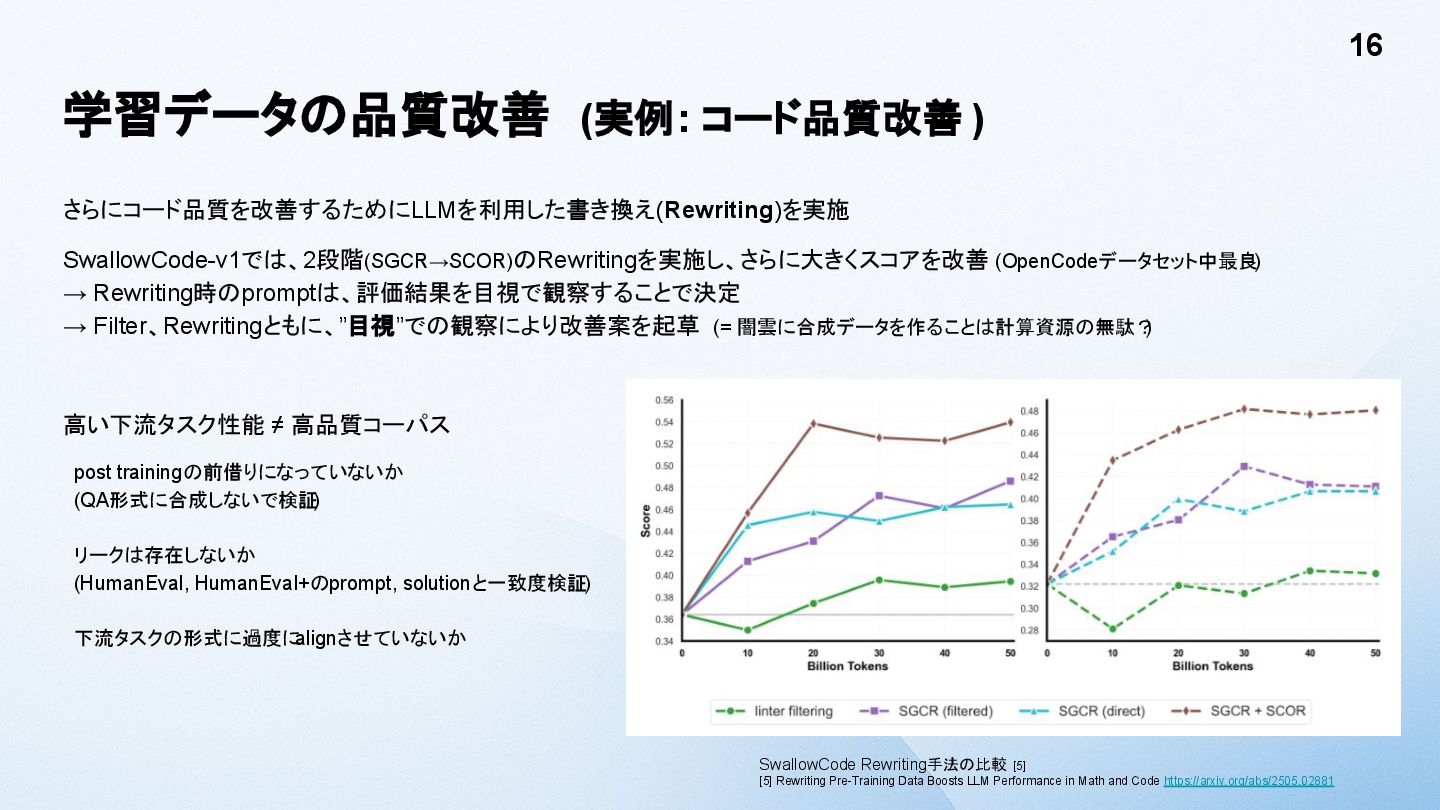
![学習速度向上と安定性 (低精度) • 低精度化 (FP8) 手法の多くはモデル構築には導入できない FP8 Delayed Scaling[1] は、175Bモデルで200Bトークン学習する限りでは問題ない](https://files.speakerdeck.com/presentations/da744b3ac4be40dca766eb92eae6922b/slide_11.jpg){kind=link}
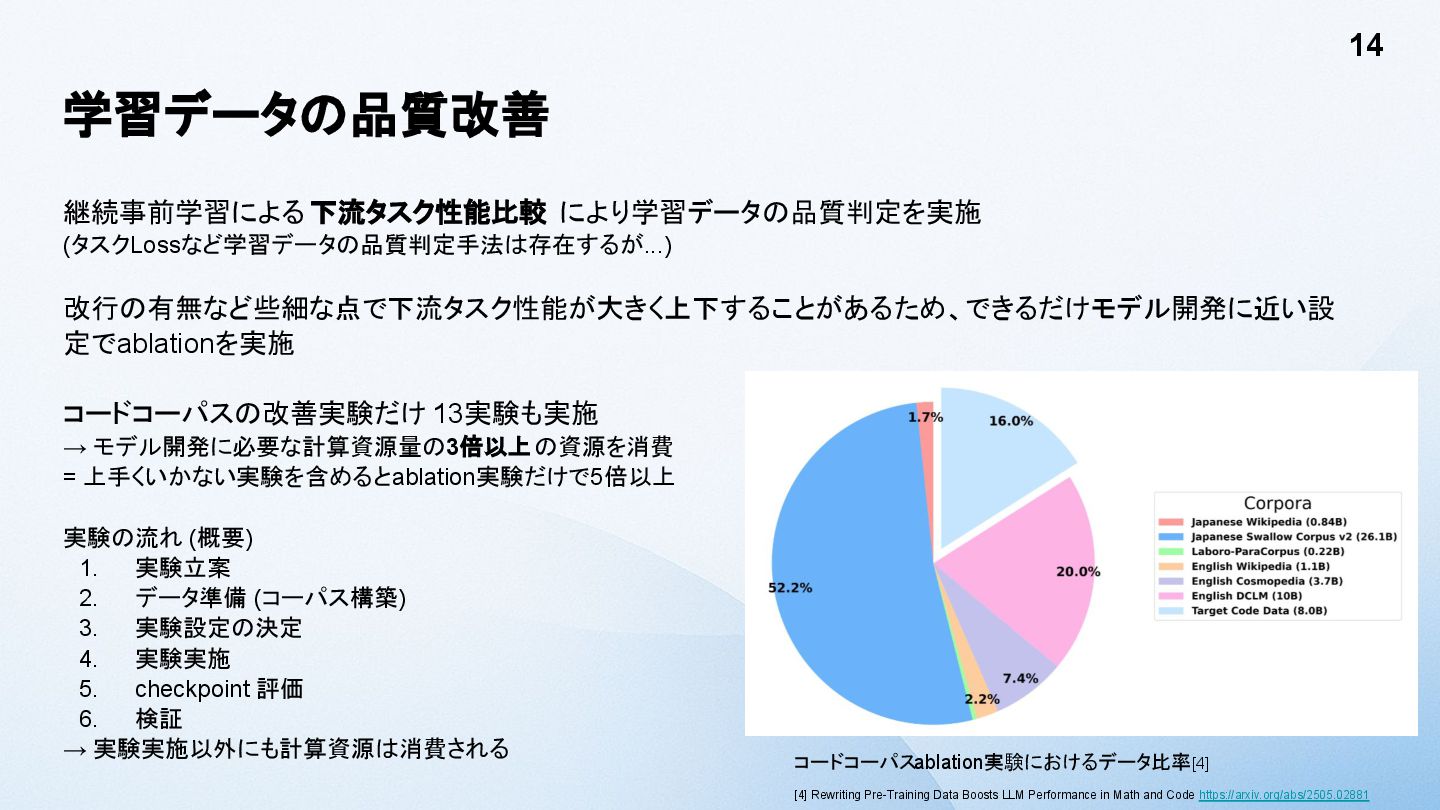
{kind=link}
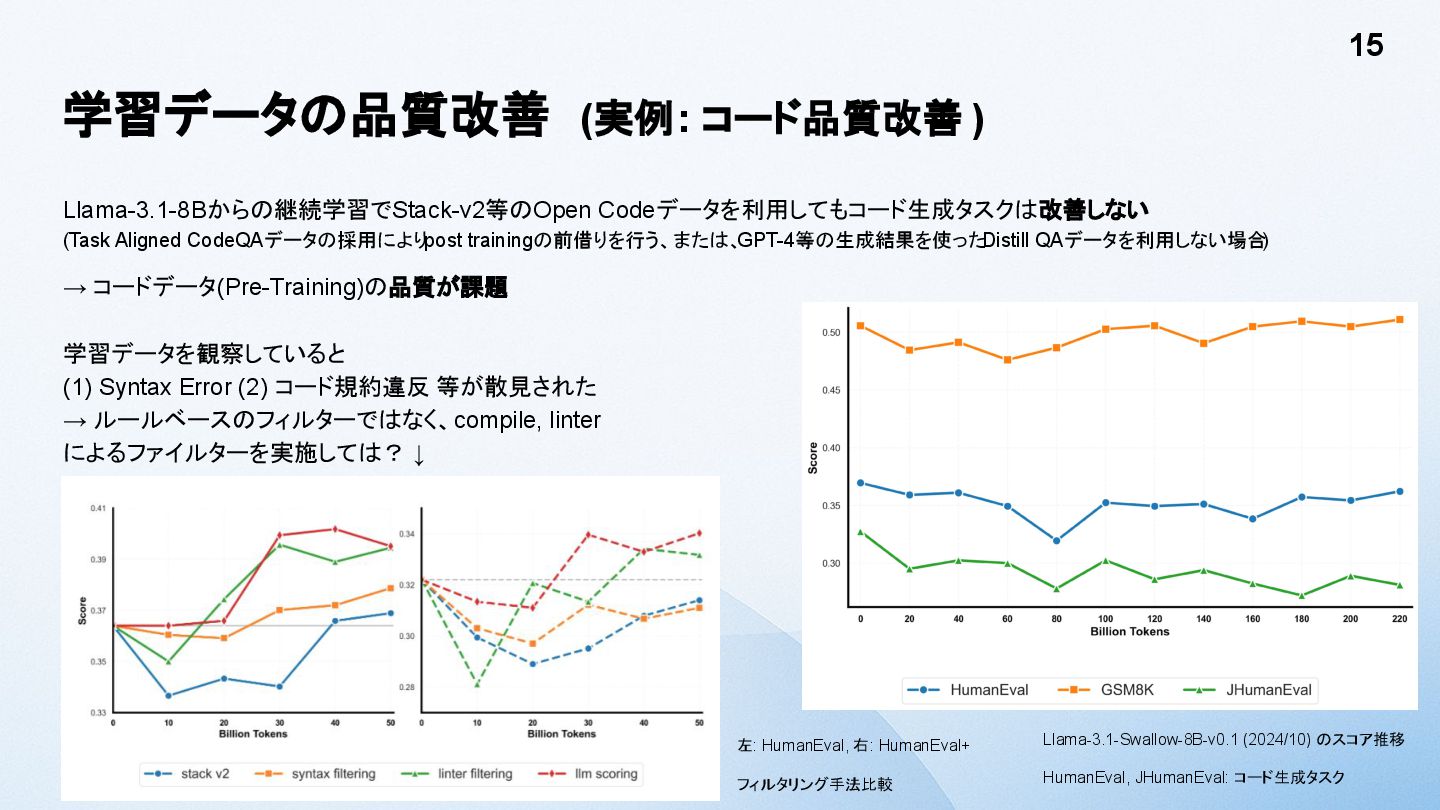
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}