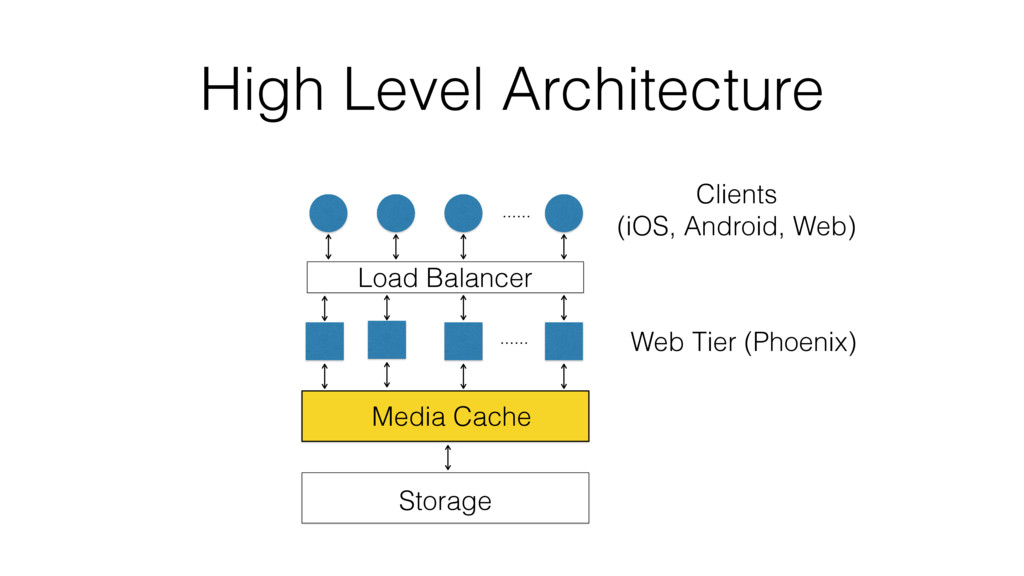
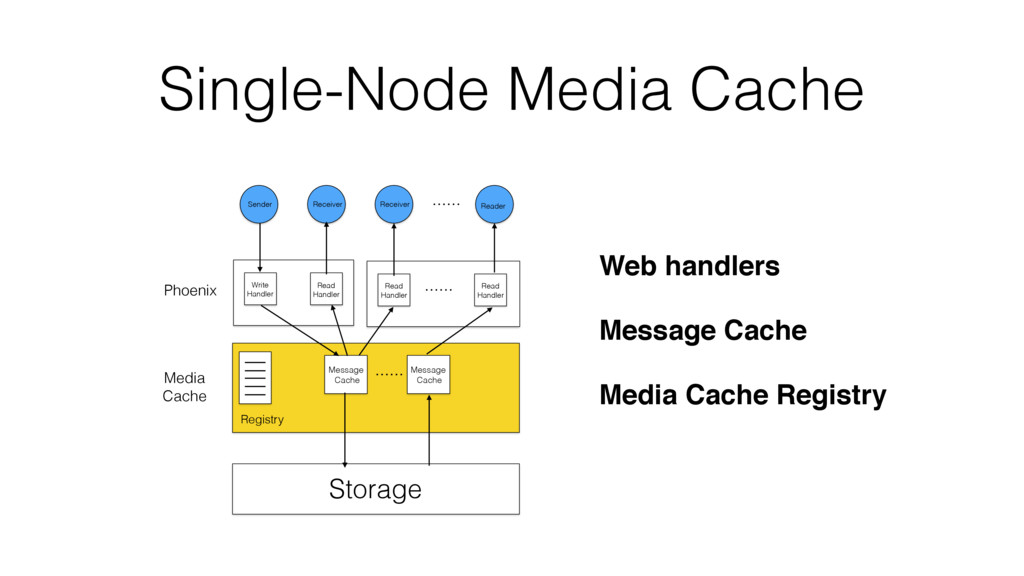
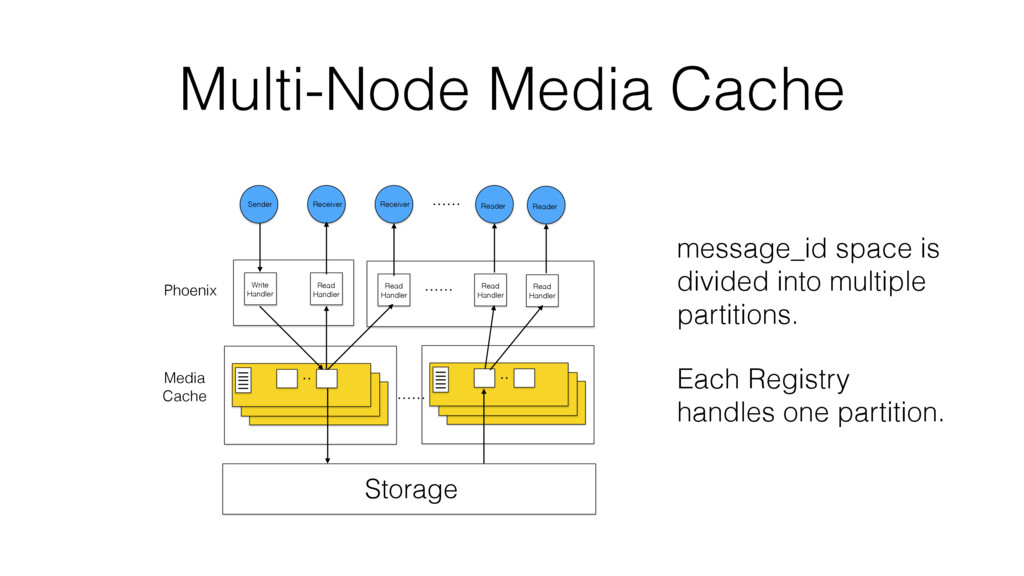
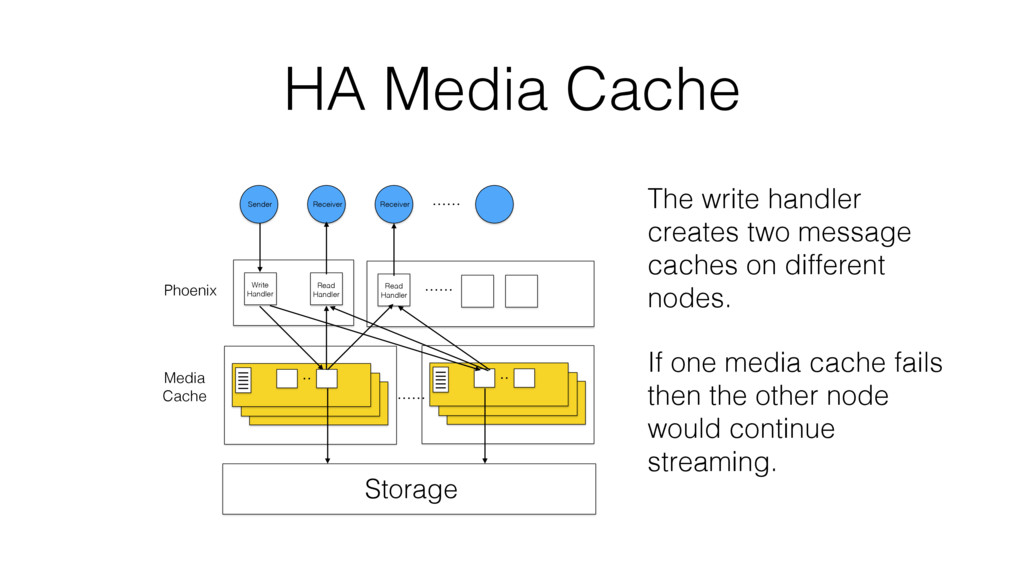
VoiceLayer is a real-time voice messaging platform developed using the Phoenix Framework. Its media router core service must be resilient to a wide variety of adverse conditions, including software, hardware and even network failures.
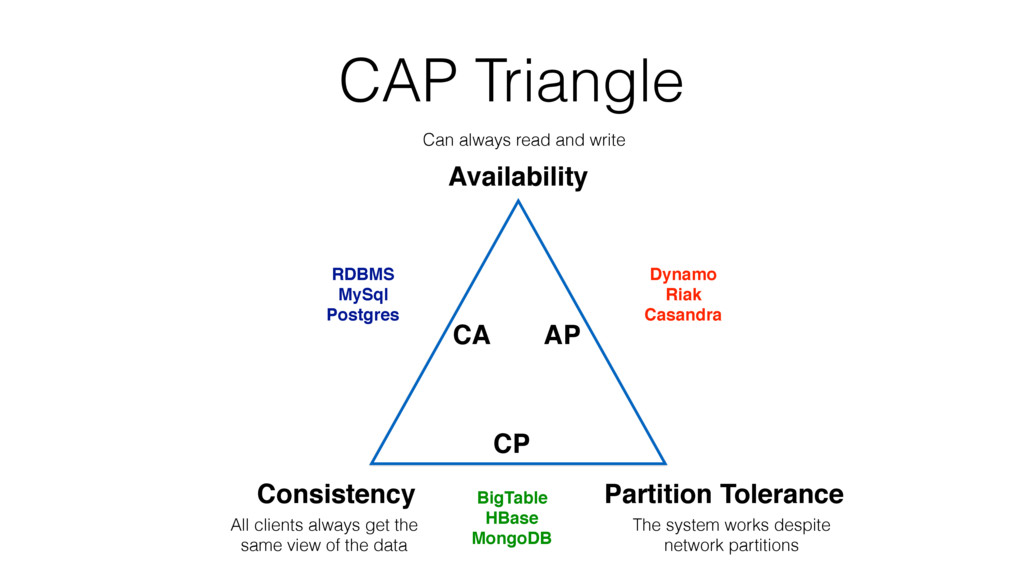
According to the CAP theorem, a system can only meet two of the following three guarantees: Consistency, Availability or Partition Tolerance. We will characterize Available and Partition Tolerant (aka AP) systems and describe different implementation approaches.
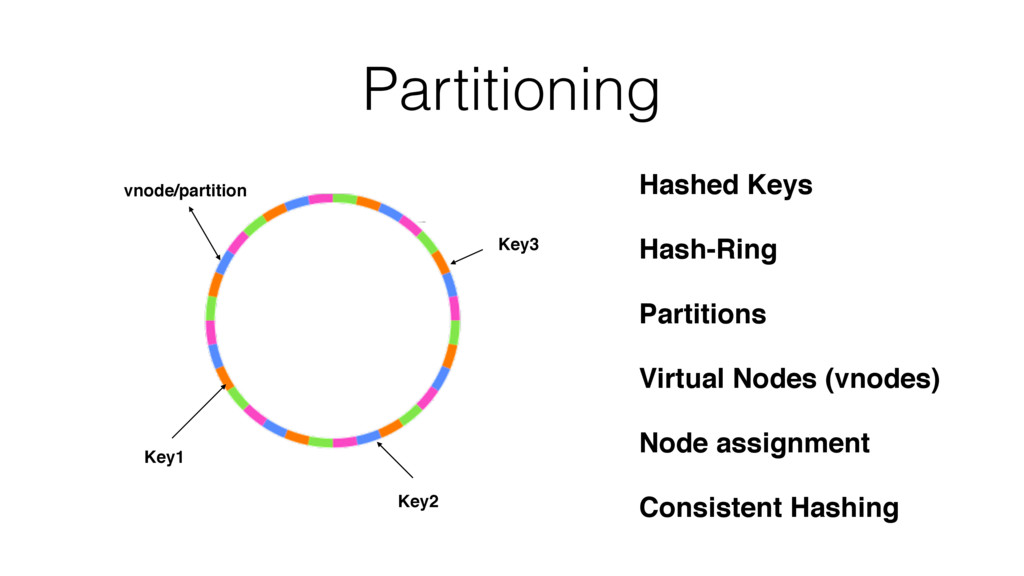
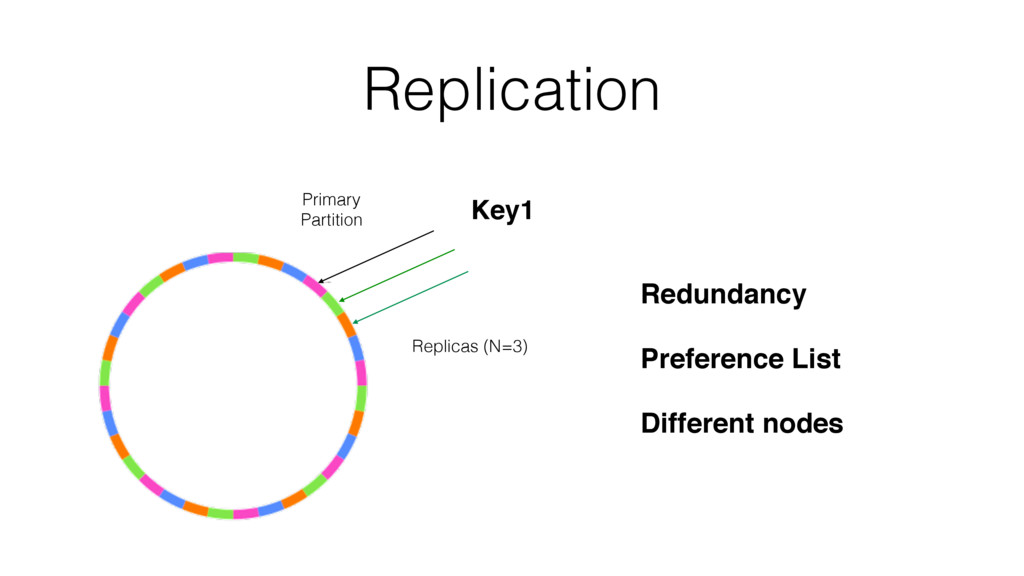
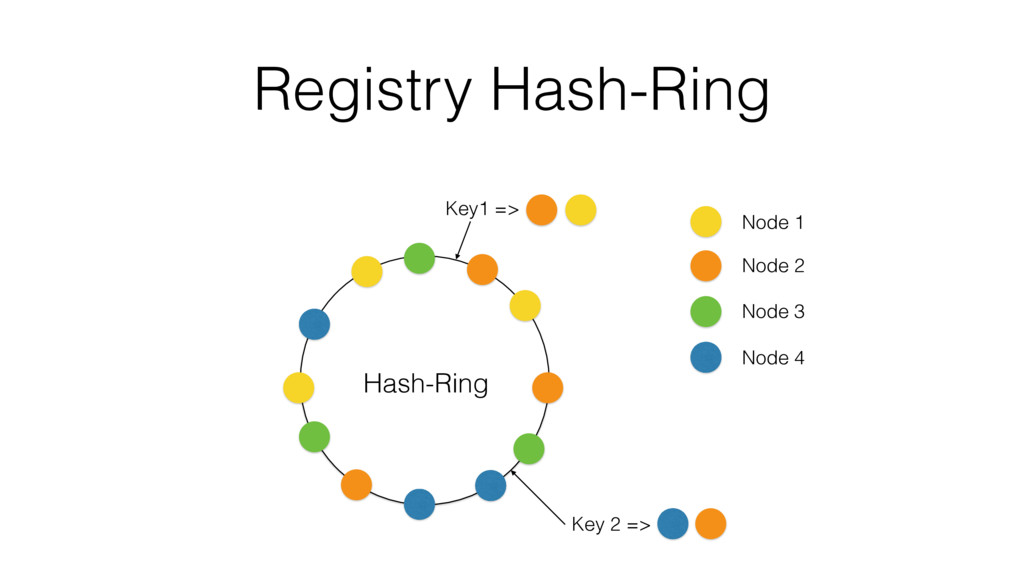
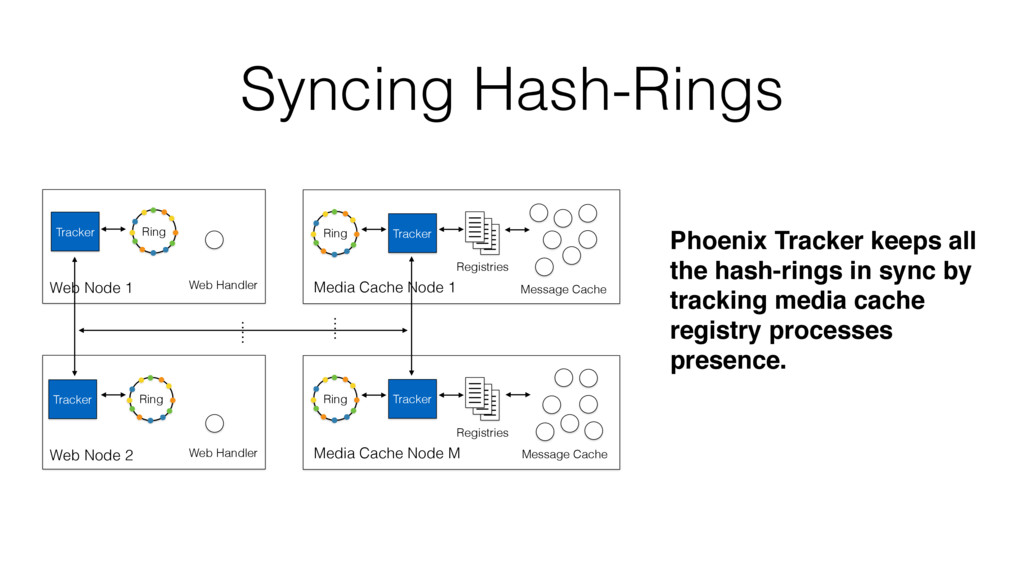
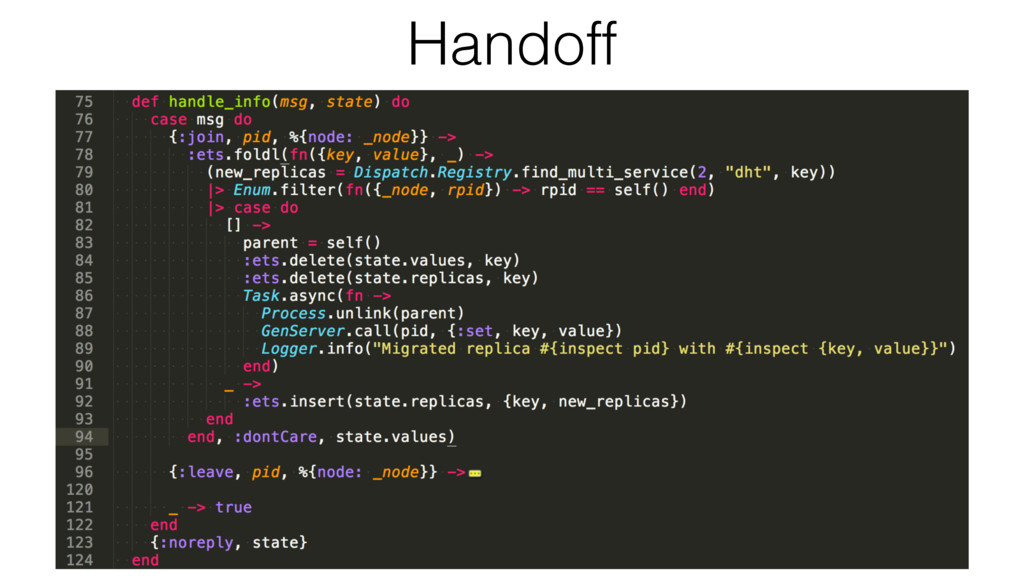
One such approach is based on Riak-Core, which is the distributed systems framework that forms the basis of how Riak distributes data and scales. Despite Riak-Core being an impressive framework, at VoiceLayer, we took a different route and relied on Phoenix Tracker (a core component of Phoenix Pubsub) to meet our requirements. We will describe this approach details, contrast it to other solutions and discuss its tradeoffs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}