save model/pipeline as file Tensorflow provide tf.train.Saver that persists the tensor graph It is pickle + metadata + checkpoint Python Sklearn / Spark / Tensorflow
dependency on python version Code serialization has potential security concerns For tf model, those tensor names are required ( need check if there are in the meta data) tf mode has dependency on customer code which defined customer operations Issues and Limitations
Tensorflow, Spark Scale up and down Performance, Latency optimization Accessing model, API Audit and Versioning CI/CD Metrics and Monitoring Optimization, AB Tests ML Deployment Challenges
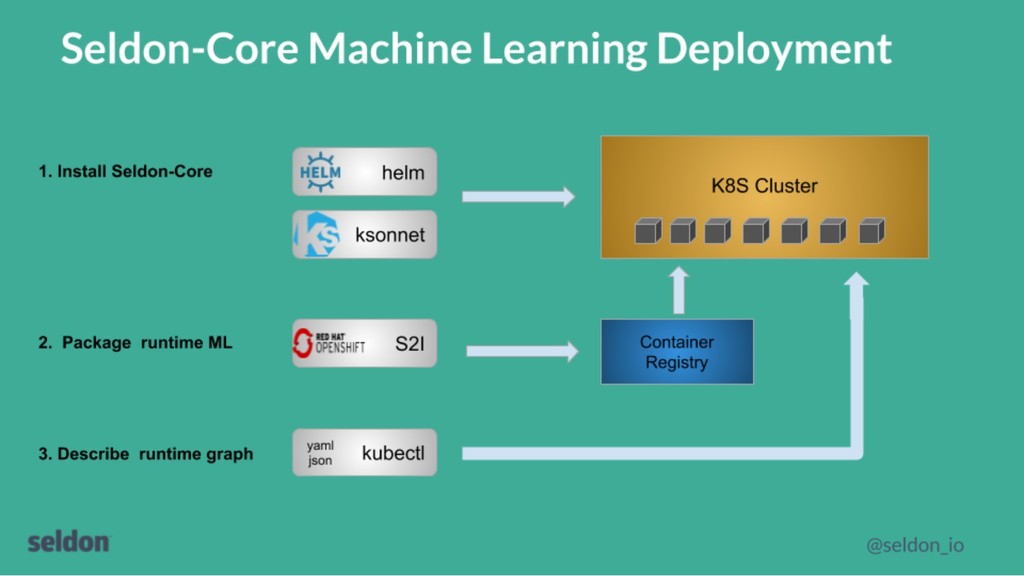
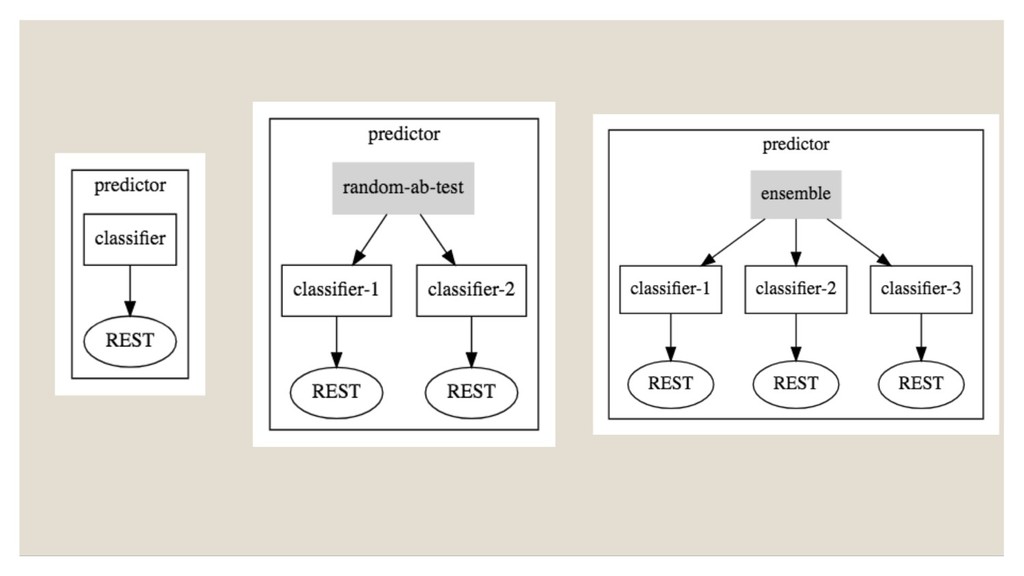
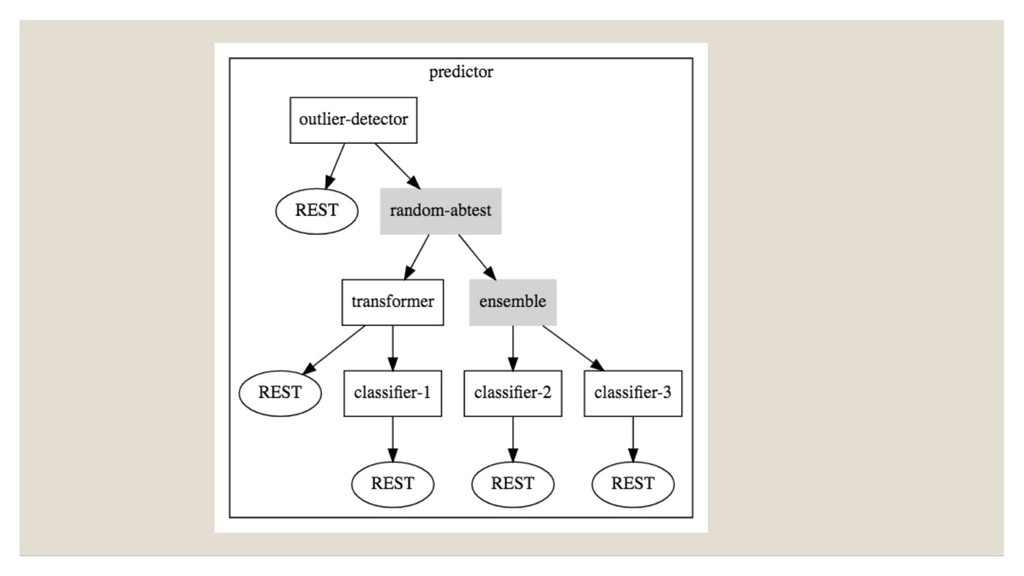
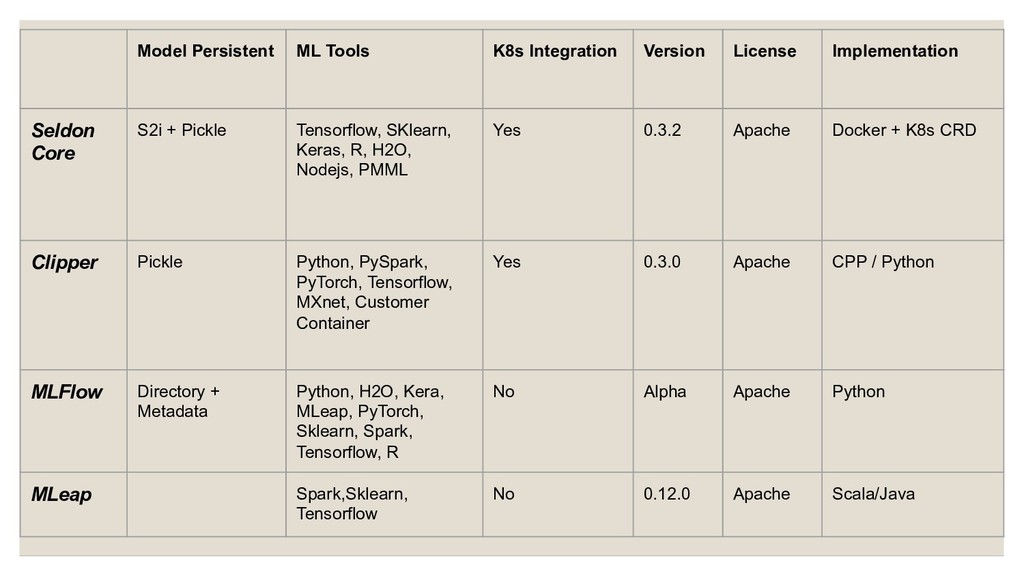
Learning based on open source software Seldon Core is a open source platform for deploying machine learning model on Kubernetes • Python/Spark/H2O/R model support • REST and gRPC API • Deploy Inference graph of Model/Routers/Combiner/Transformers as microservices • Leveraging K8s to provide scale, security, monitoring etc Seldon
test and ensembling No Scala support for Spark Need customer image for pySpark No customization support for liveness/readiness check due to CRD Summary
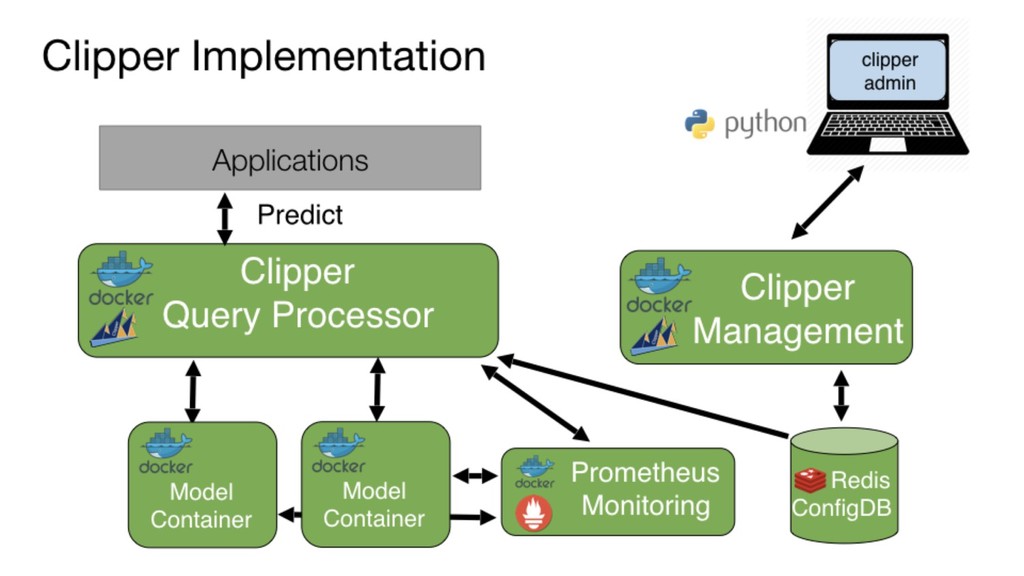
Clipper is a prediction serving system that sits between user-facing applications and a wide range of commonly used machine learning models and frameworks. Clipper
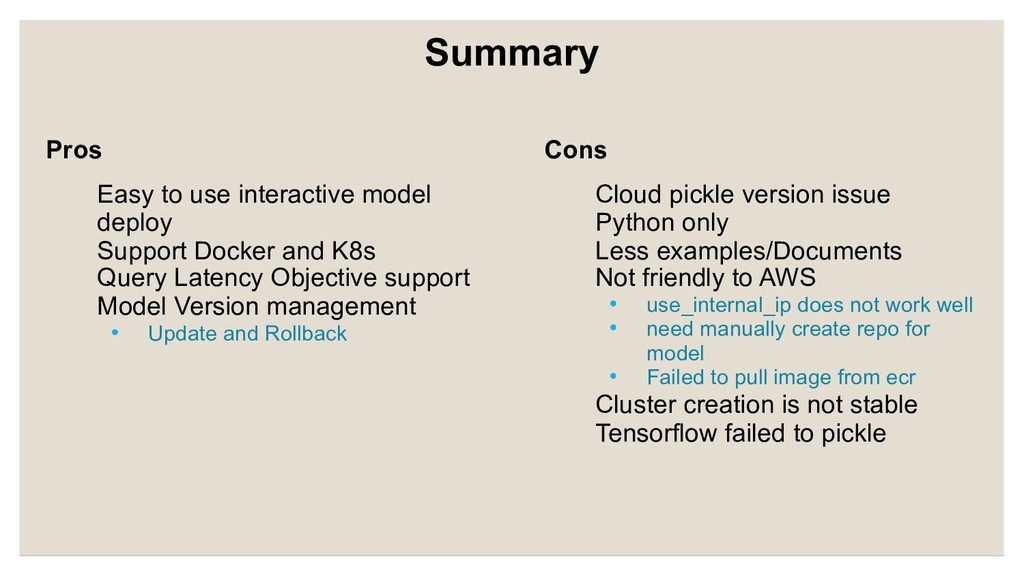
and K8s Query Latency Objective support Model Version management • Update and Rollback Cloud pickle version issue Python only Less examples/Documents Not friendly to AWS • use_internal_ip does not work well • need manually create repo for model • Failed to pull image from ecr Cluster creation is not stable Tensorflow failed to pickle Summary
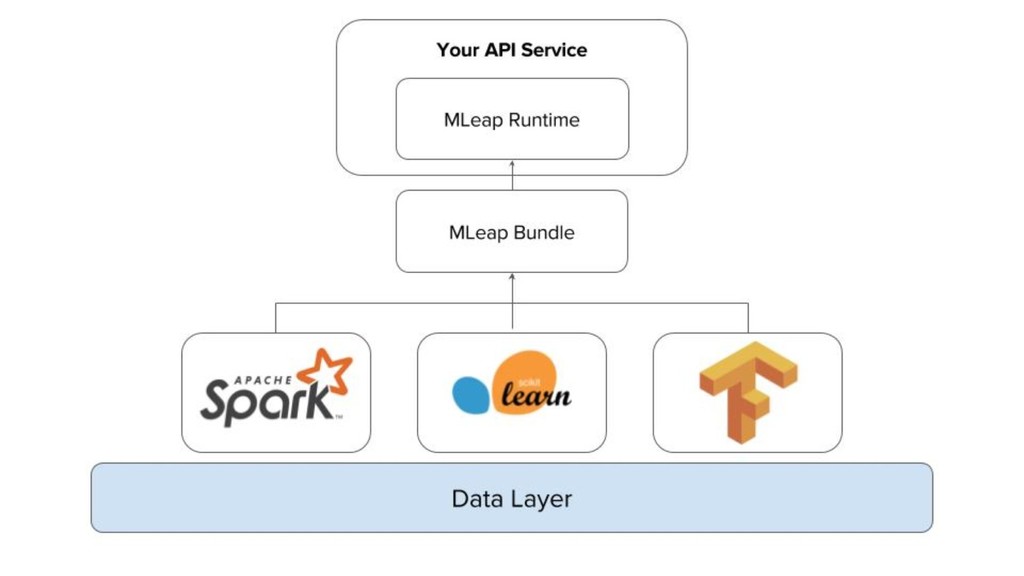
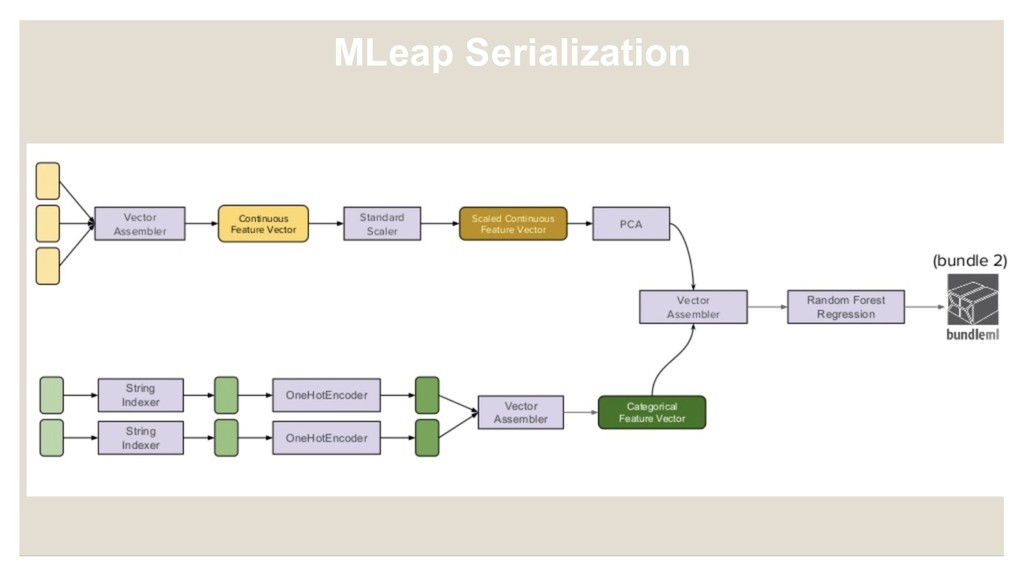
pipelines from Spark and Scikit-learn to a portable format and execution engine. • A JSON base serialization • A Runtime execution engine • Benchmarks http://mleap-docs.combust.ml/core-concepts/transformers/support.html MLeap
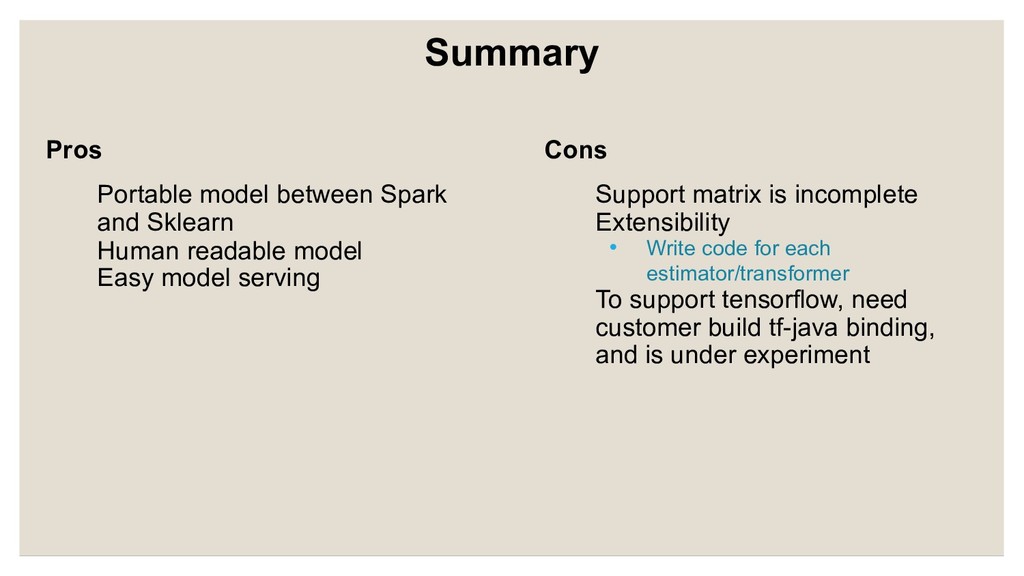
model Easy model serving Support matrix is incomplete Extensibility • Write code for each estimator/transformer To support tensorflow, need customer build tf-java binding, and is under experiment Summary
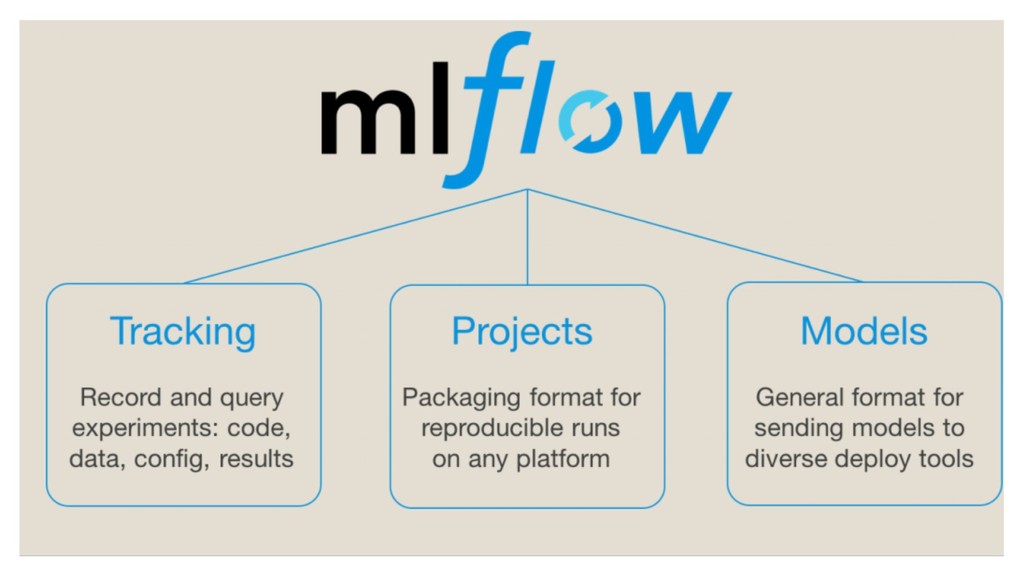
model serving, and it’s graph function is powerful. Clipper provides good interaction, while the code is not stable enough MLflow’s model serving is simple, with less functions MLeap targets to provide inter-operation between different tools which is very nice, while there is still a long way to go to support all the features. • PMML is not covered Some other tools are not touched • MXnet model server • Oracle Graphpipe Wrap up
version • Build spark image with glibc support • Java gateway process exited before sending its port number • Access spark from k8s is not easy Some K8s pods are pending with Unknown status • kubectl delete pod {} --grace-period=0 --force Building your own ML image from python is not easy, use continuumio/miniconda may save you some time Using batch command to clean the docker images • docker images | grep "something_to_search" | awk '{print $1 ":" $2}' |xargs docker rmi -f • docker system prune Some other findings
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}