Streaming data is rapidly becoming a key component in modern applications, and Apache Kafka has emerged as a popular and powerful platform for managing and processing these data streams. However, as the volume and complexity of streaming data continue to grow, it becomes increasingly critical to have efficient and effective ways of querying and analyzing this data.
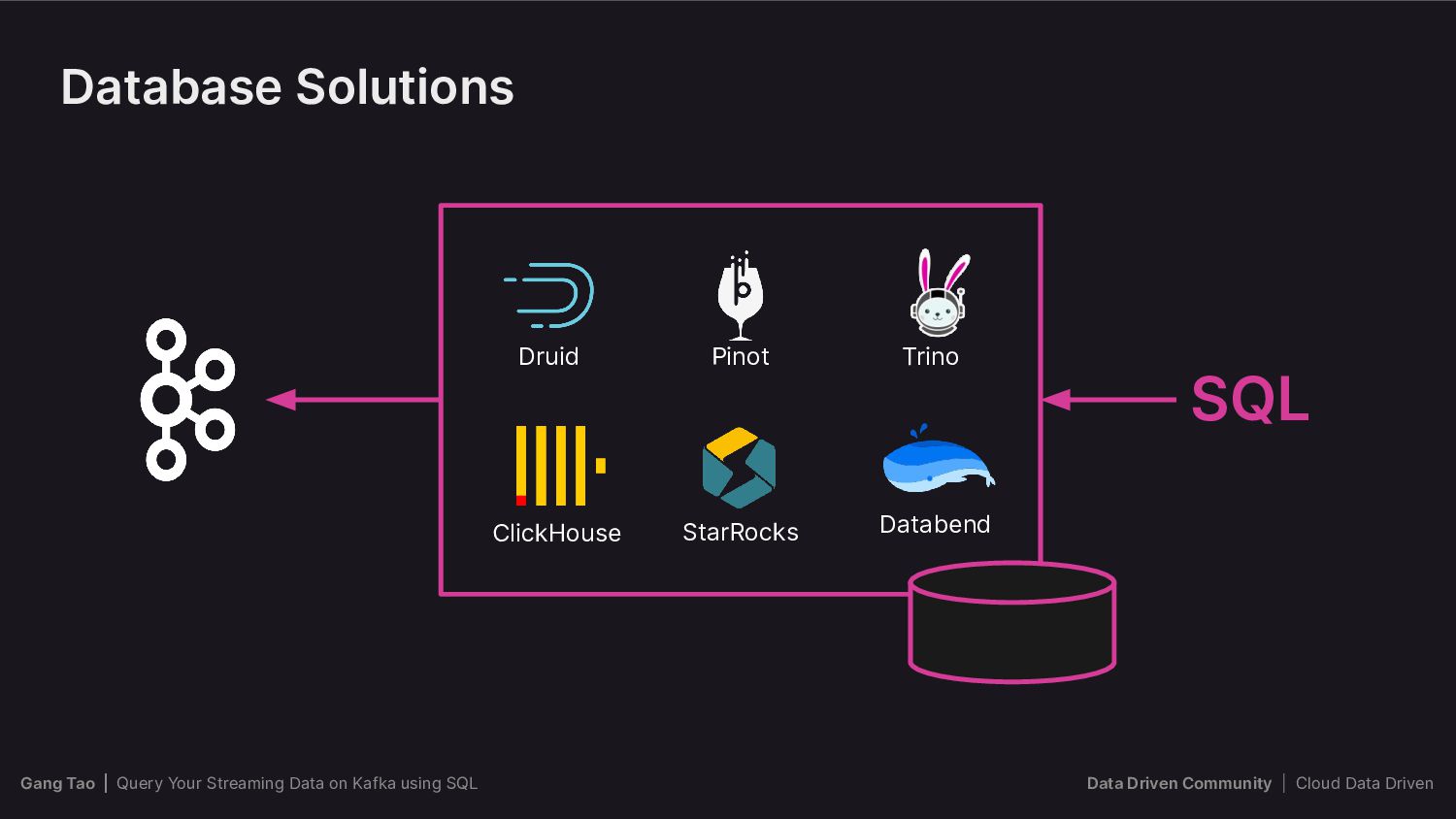
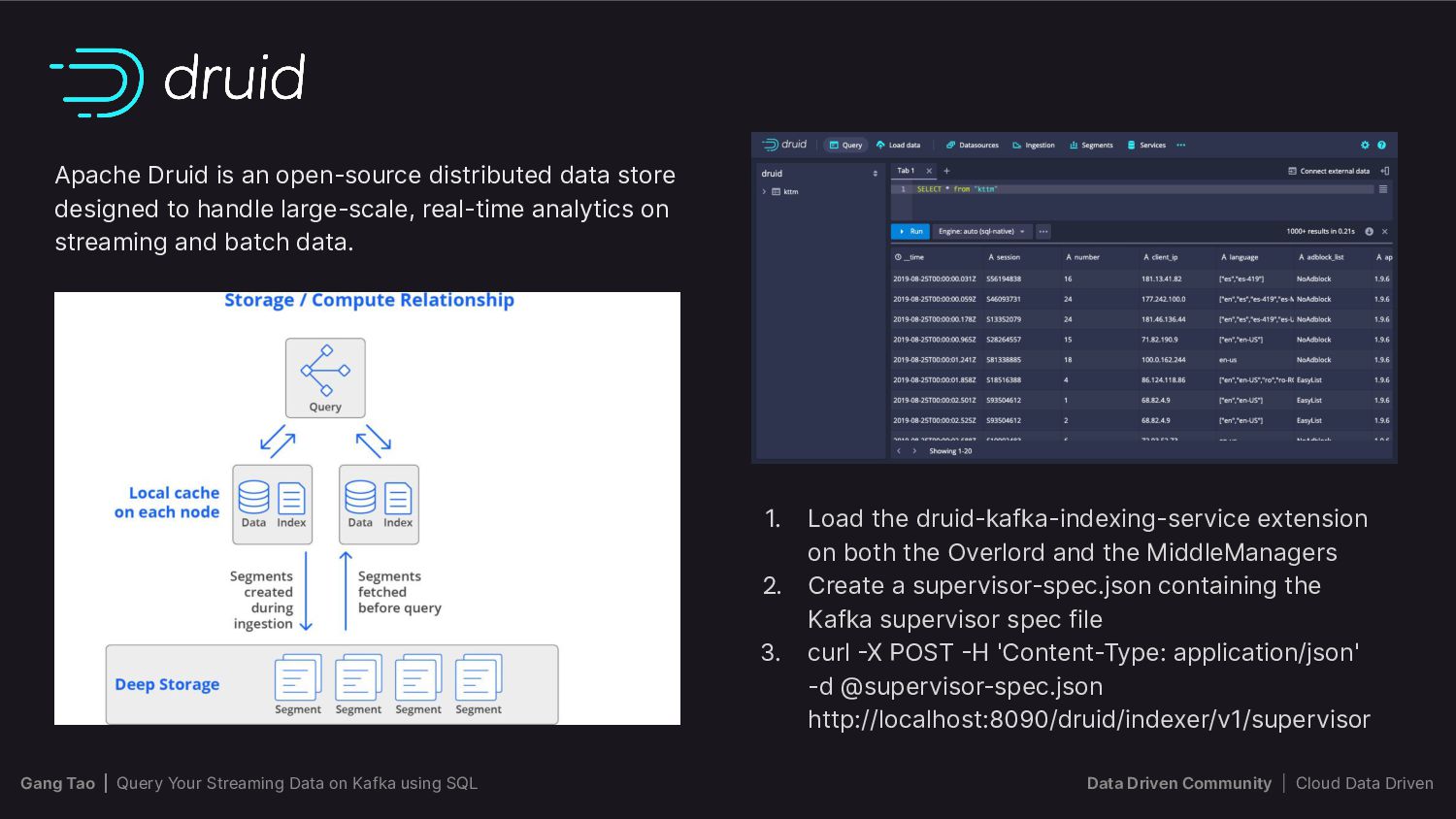
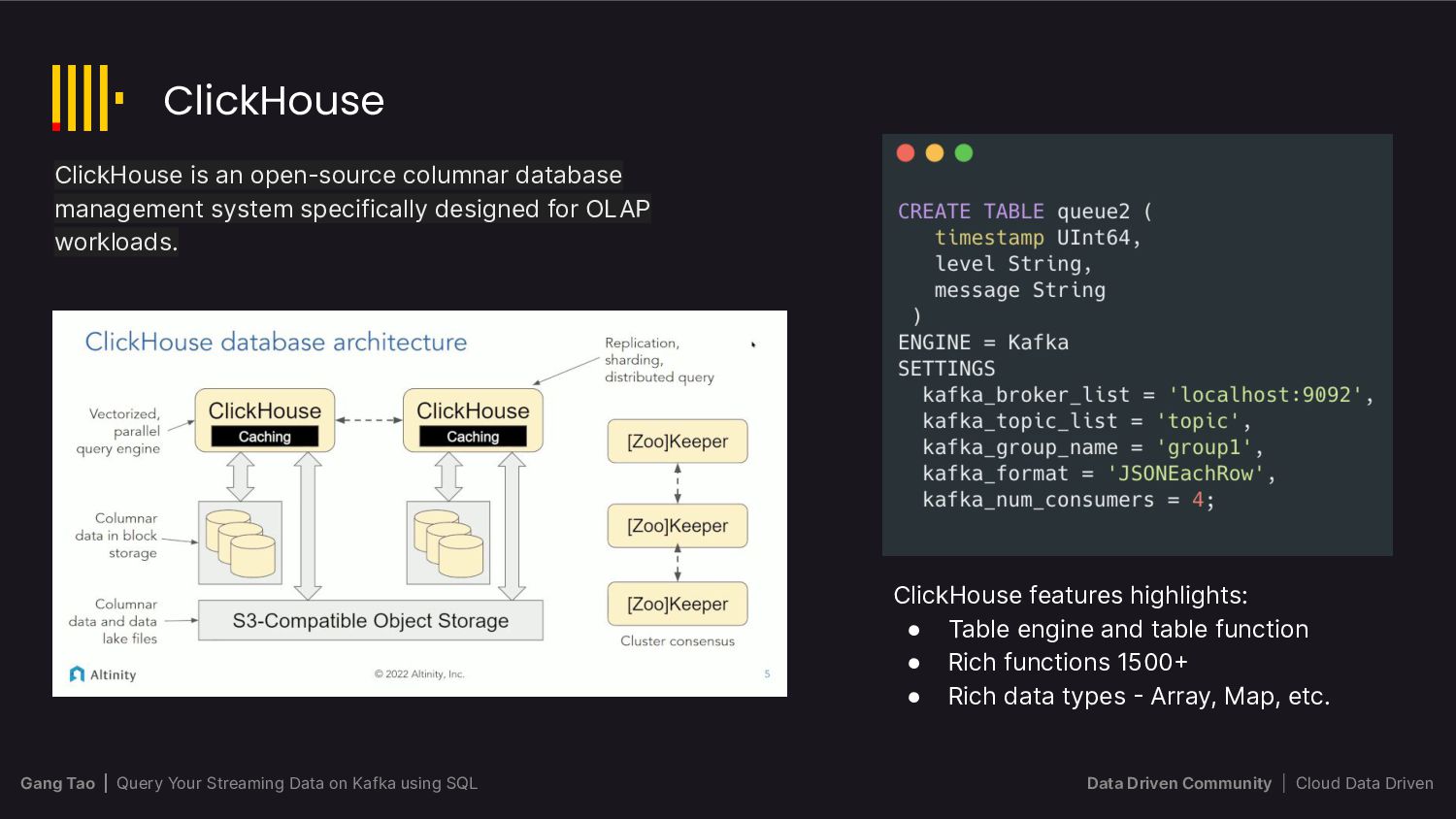
This is where query engines like Apache Flink, Trino, Timeplus, Materialize, and ksqlDB come in. These powerful tools offer flexible and scalable ways of processing and analyzing streaming data in real-time, enabling users to extract valuable insights from their data streams.
In this talk, we will introduce the audience to the world of querying streaming data on Apache Kafka with SQL, compare and contrast the features and capabilities of each of these tools, and provide an in-depth analysis of their respective Pros and Cons. We will also discuss the best practices and scenarios where each tool is most effective.
{kind=link}
{kind=link}
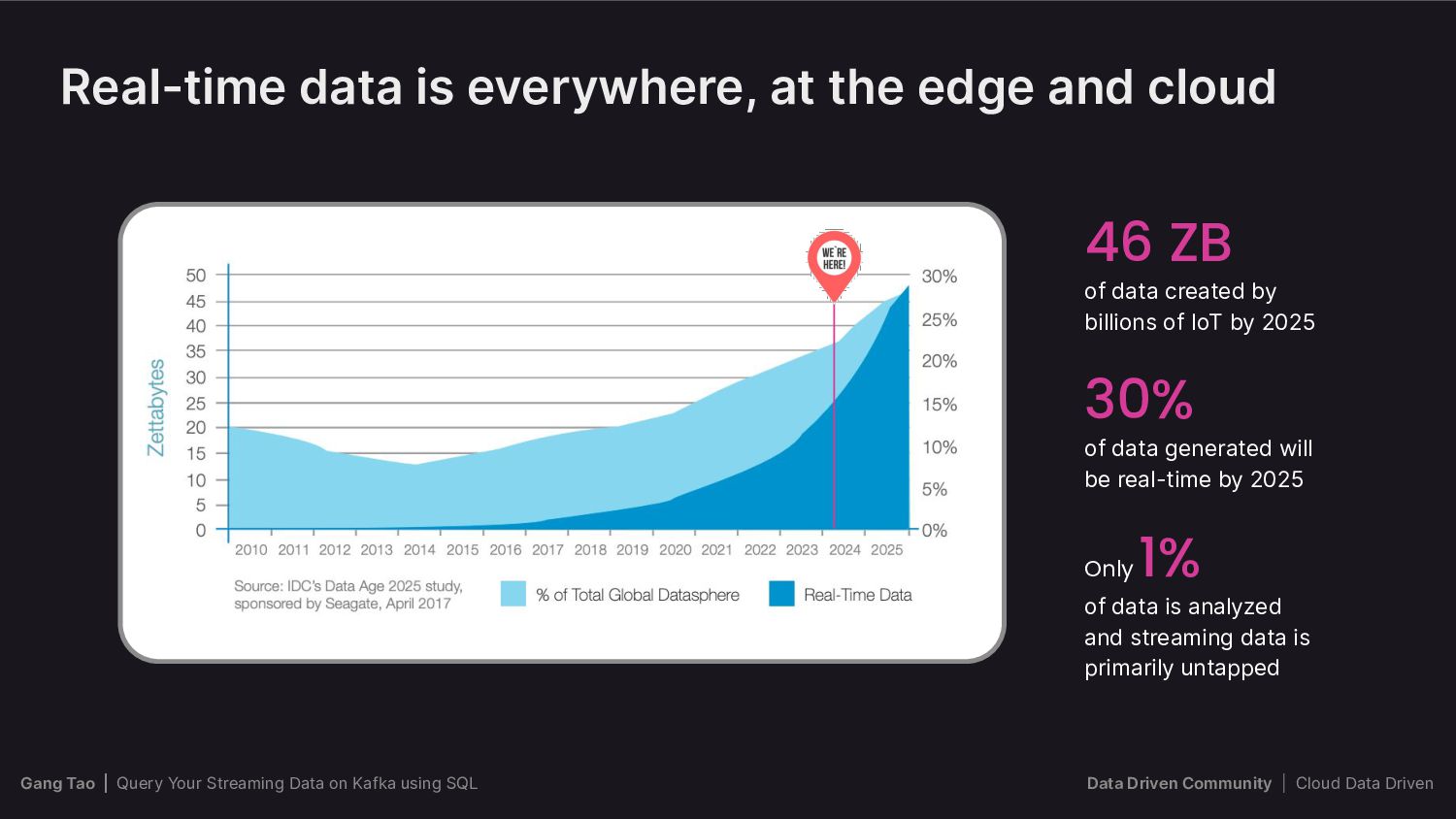{kind=link}
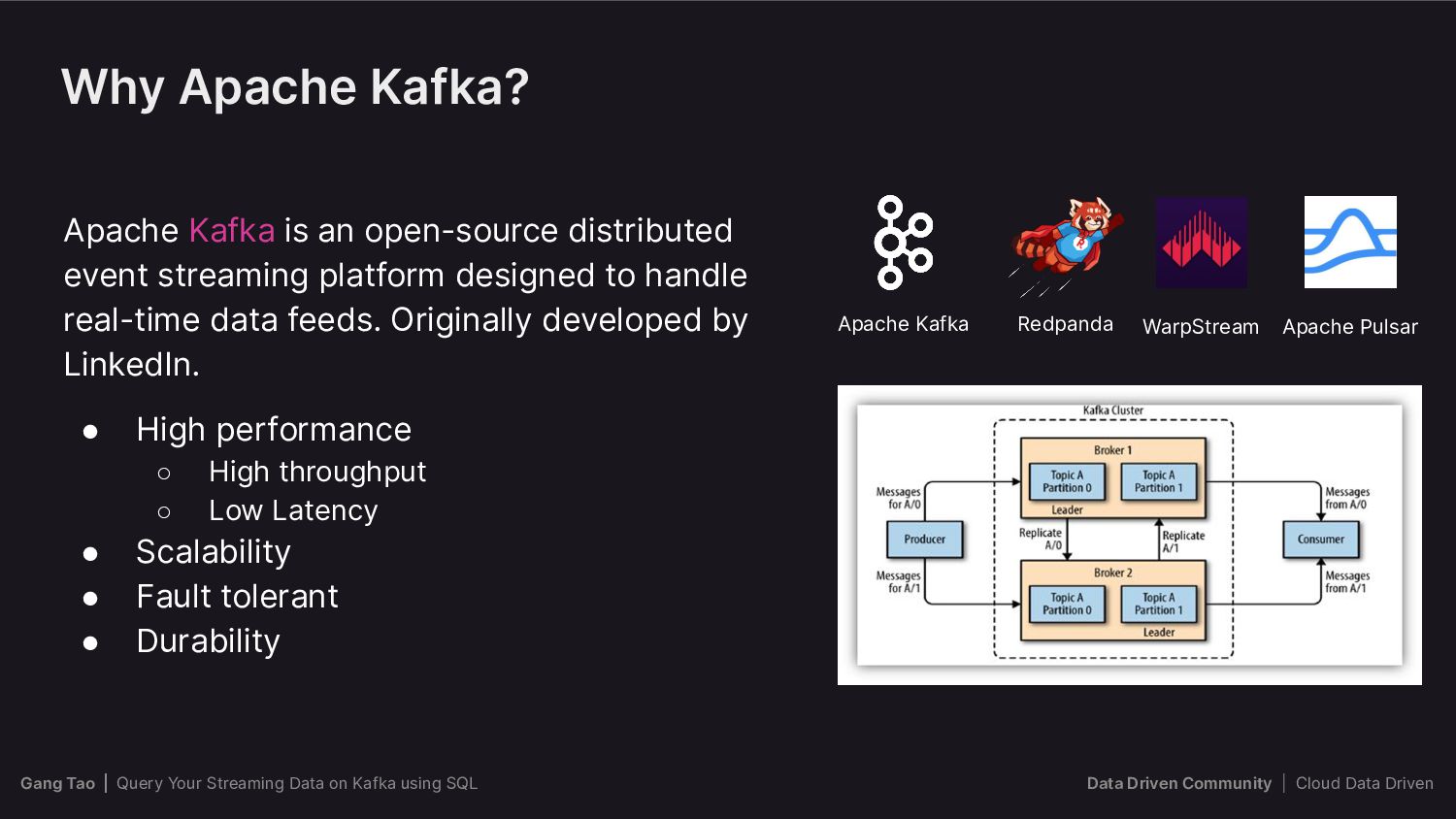{kind=link}
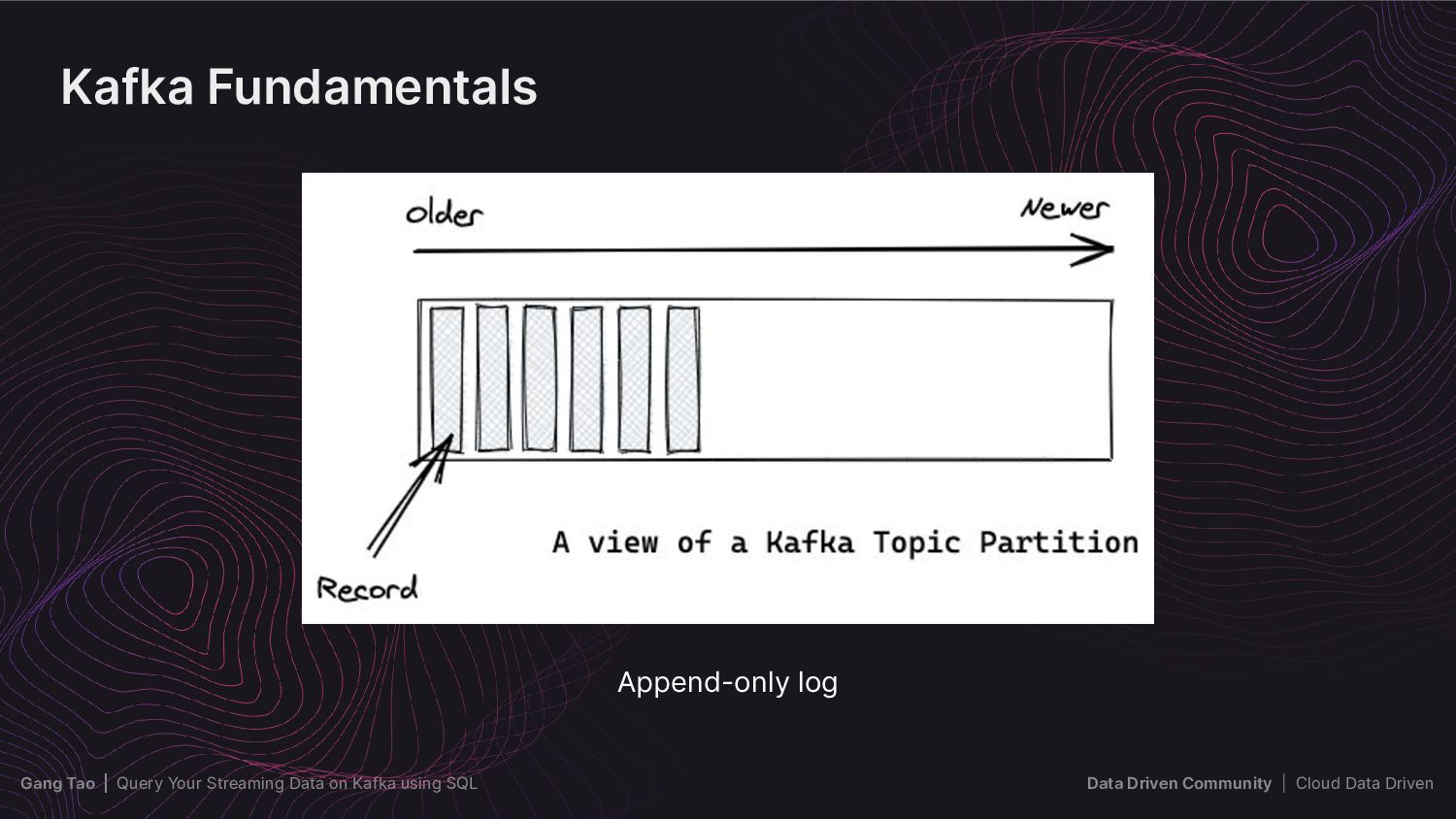{kind=link}
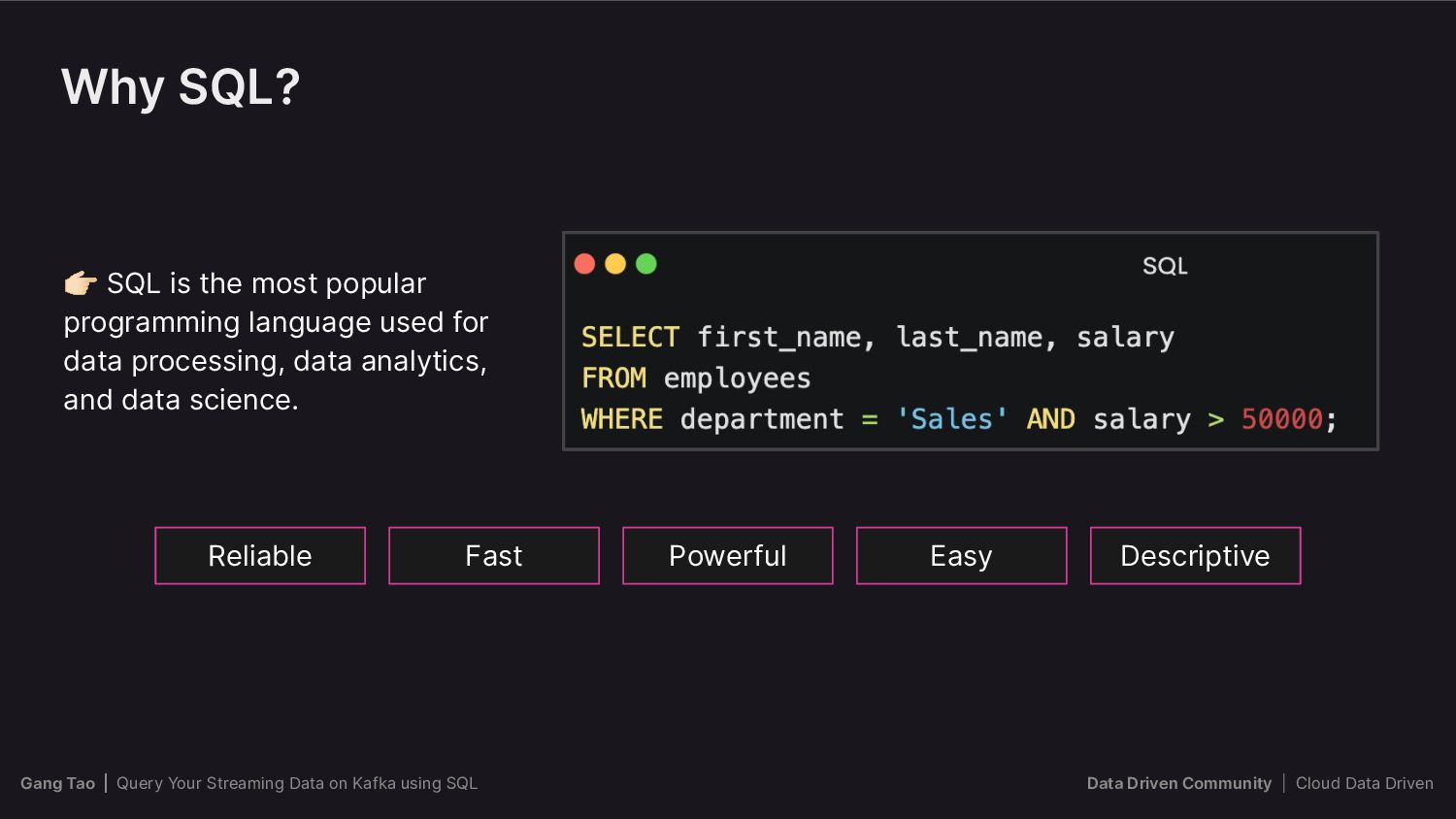{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
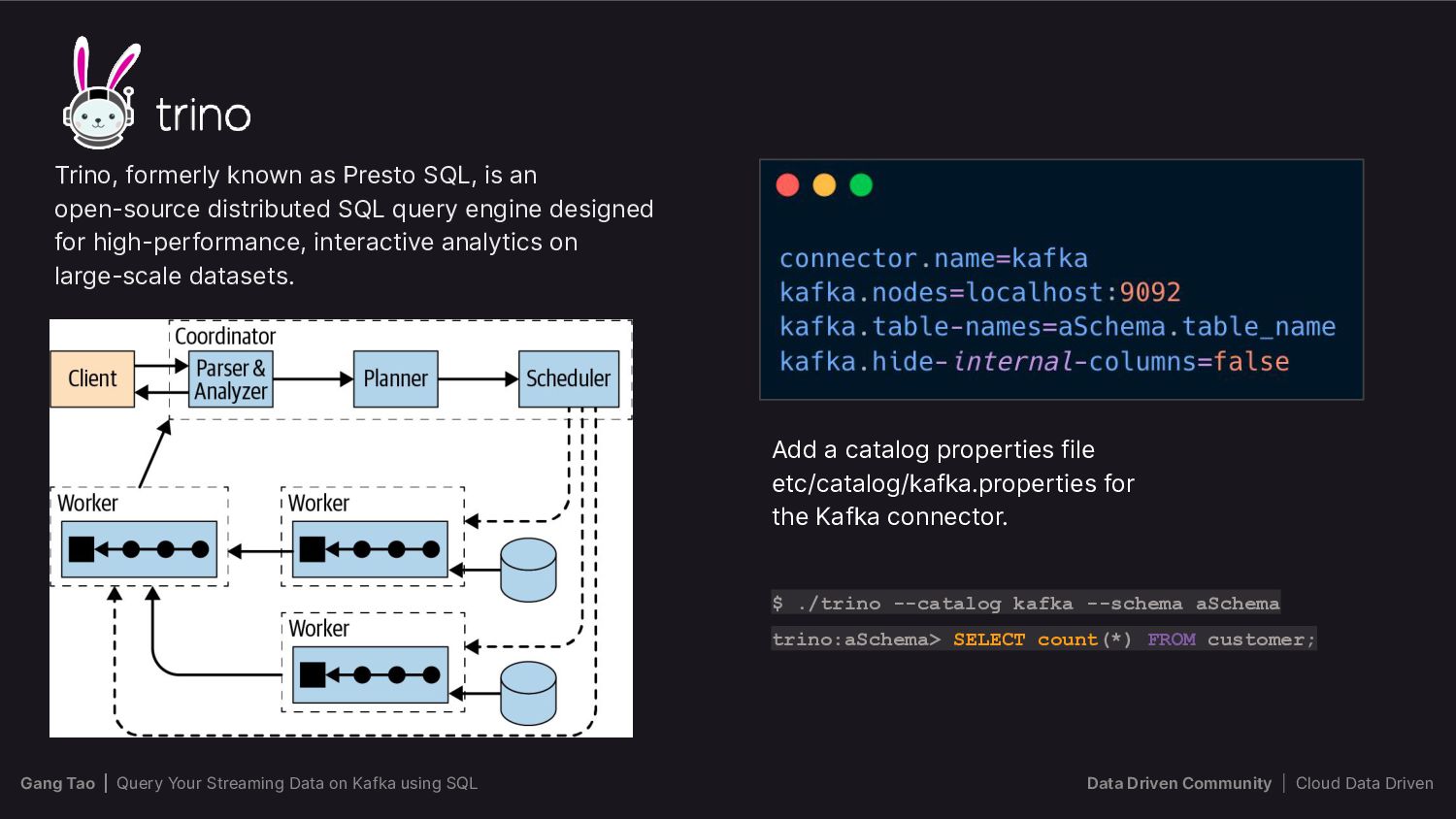{kind=link}
{kind=link}
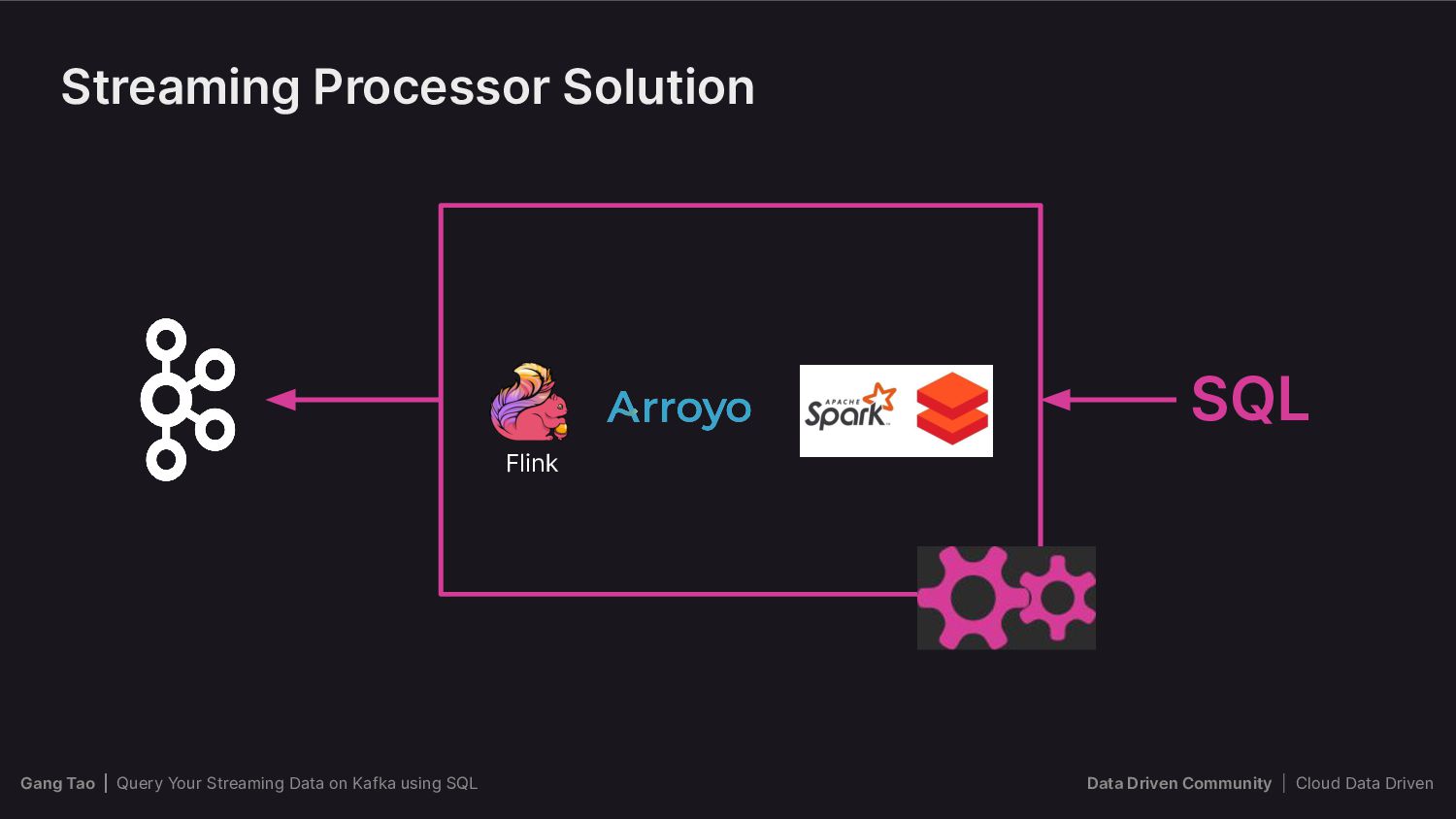{kind=link}
{kind=link}
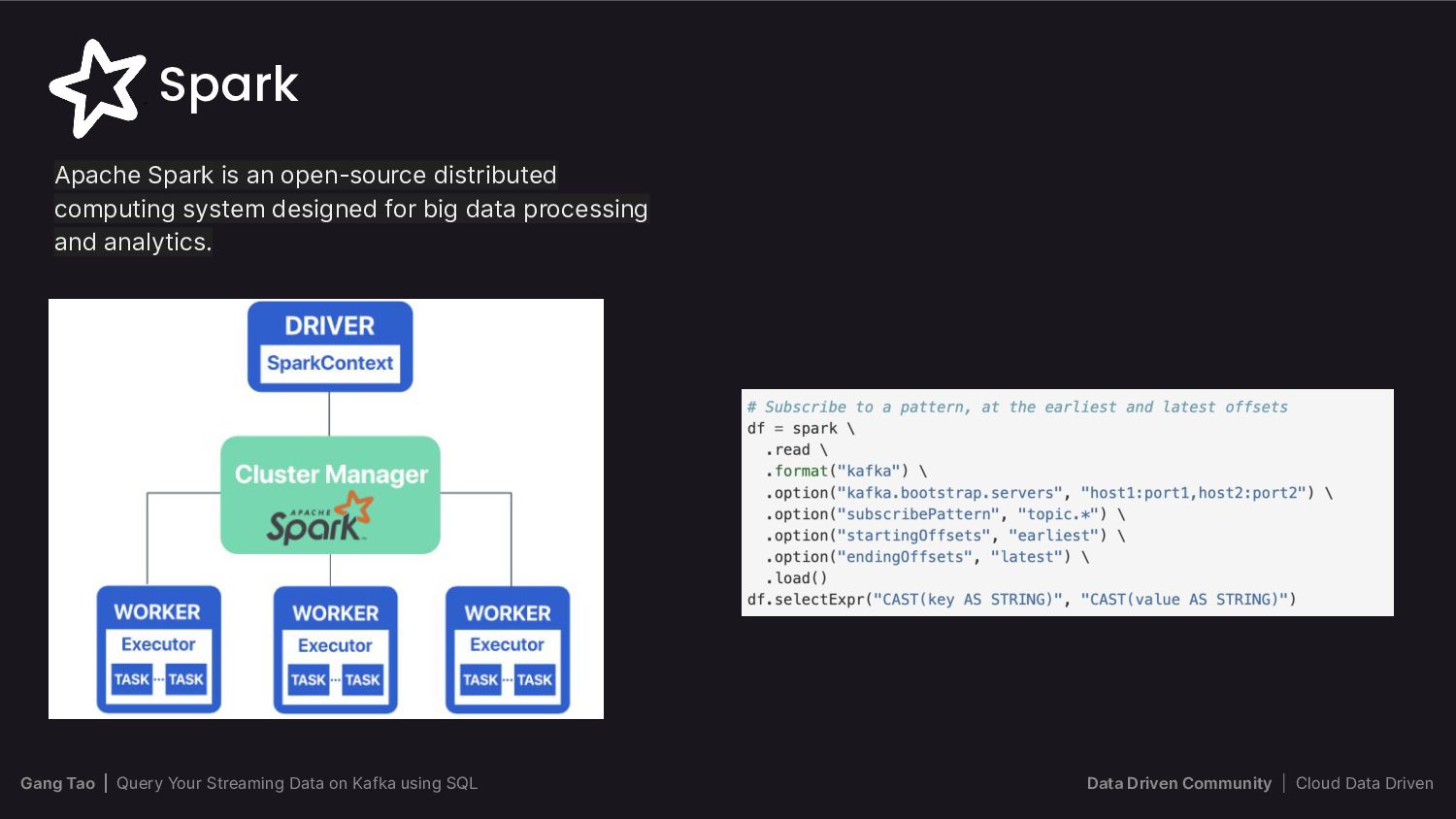{kind=link}
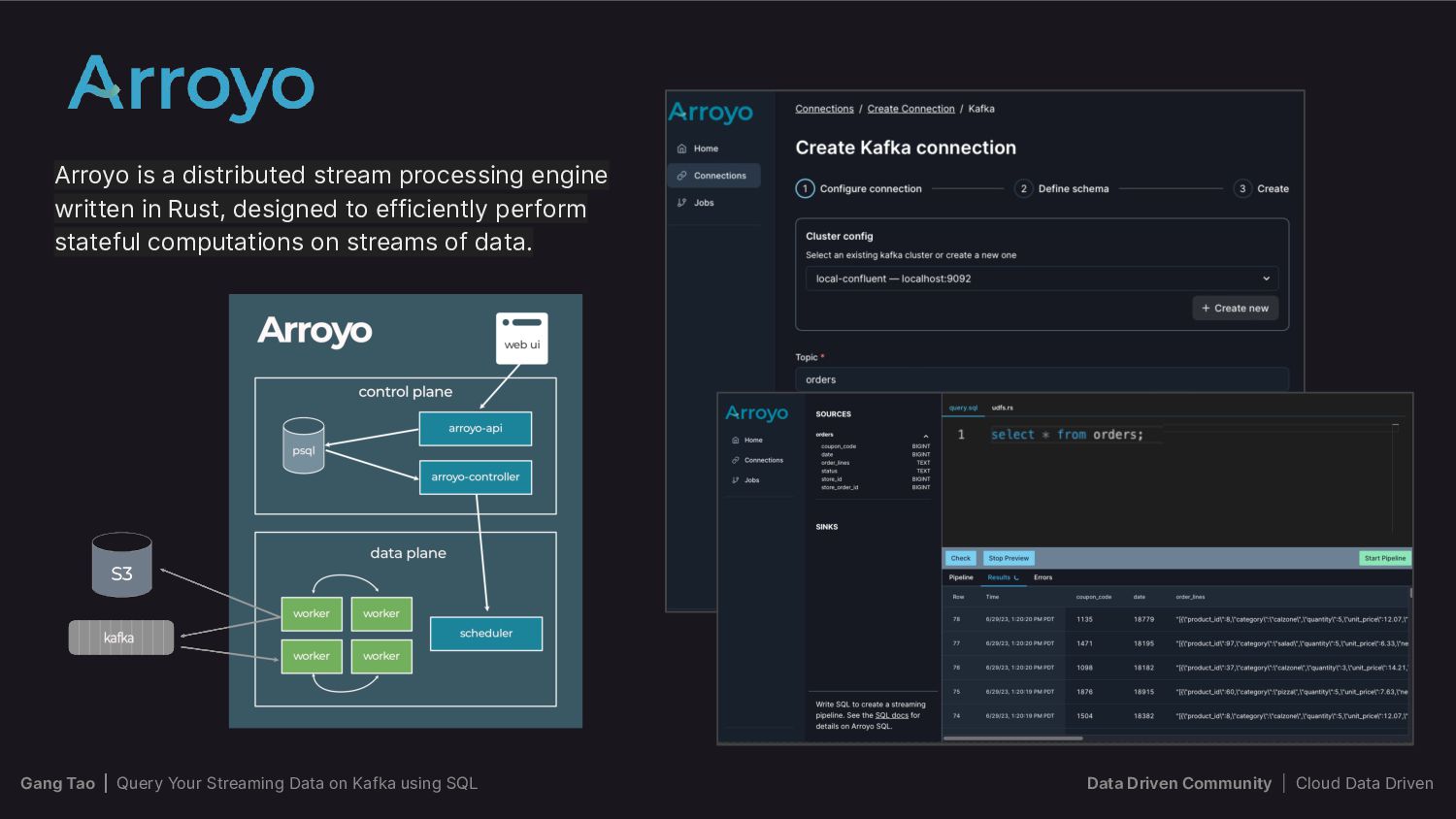{kind=link}
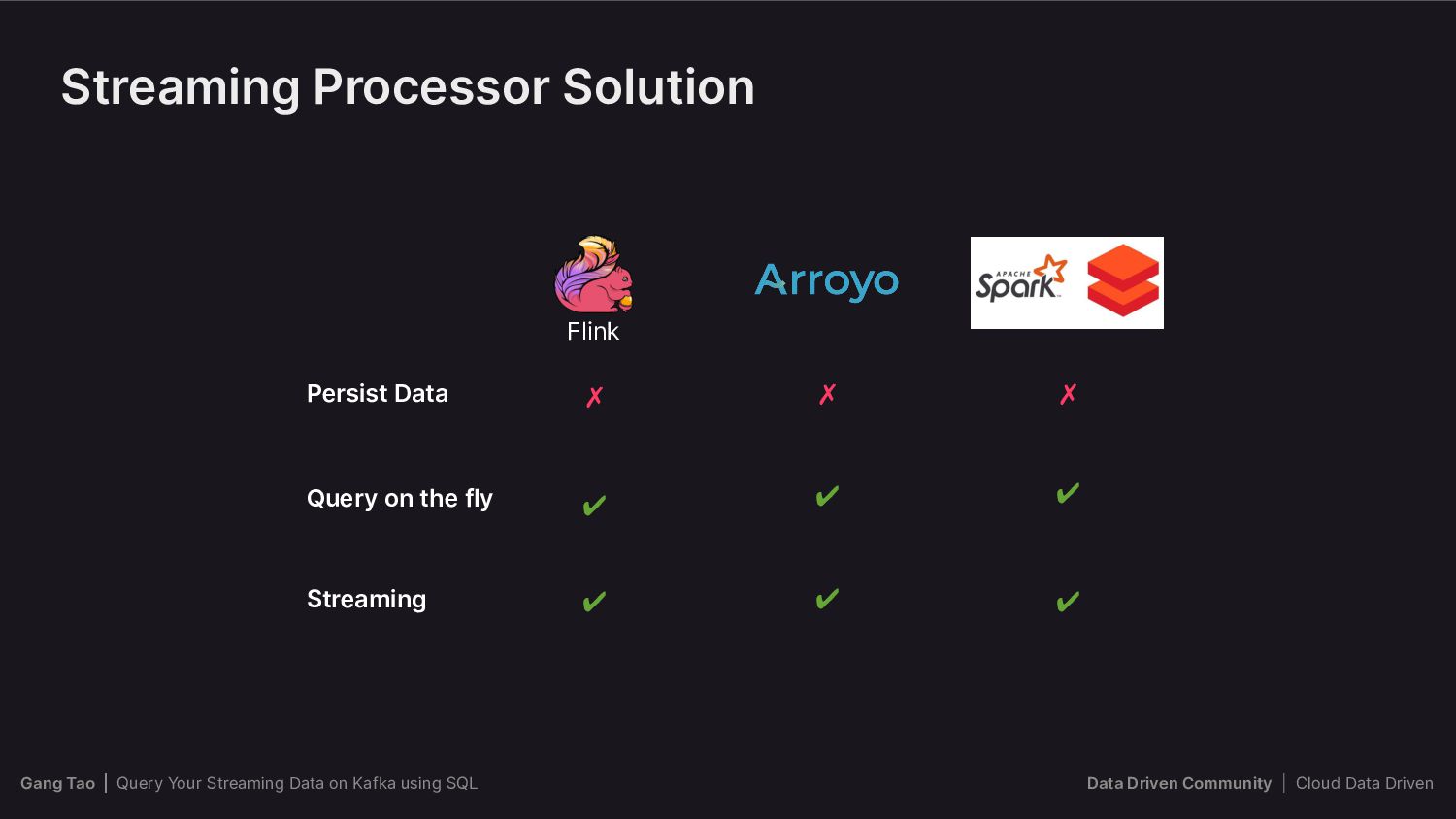{kind=link}
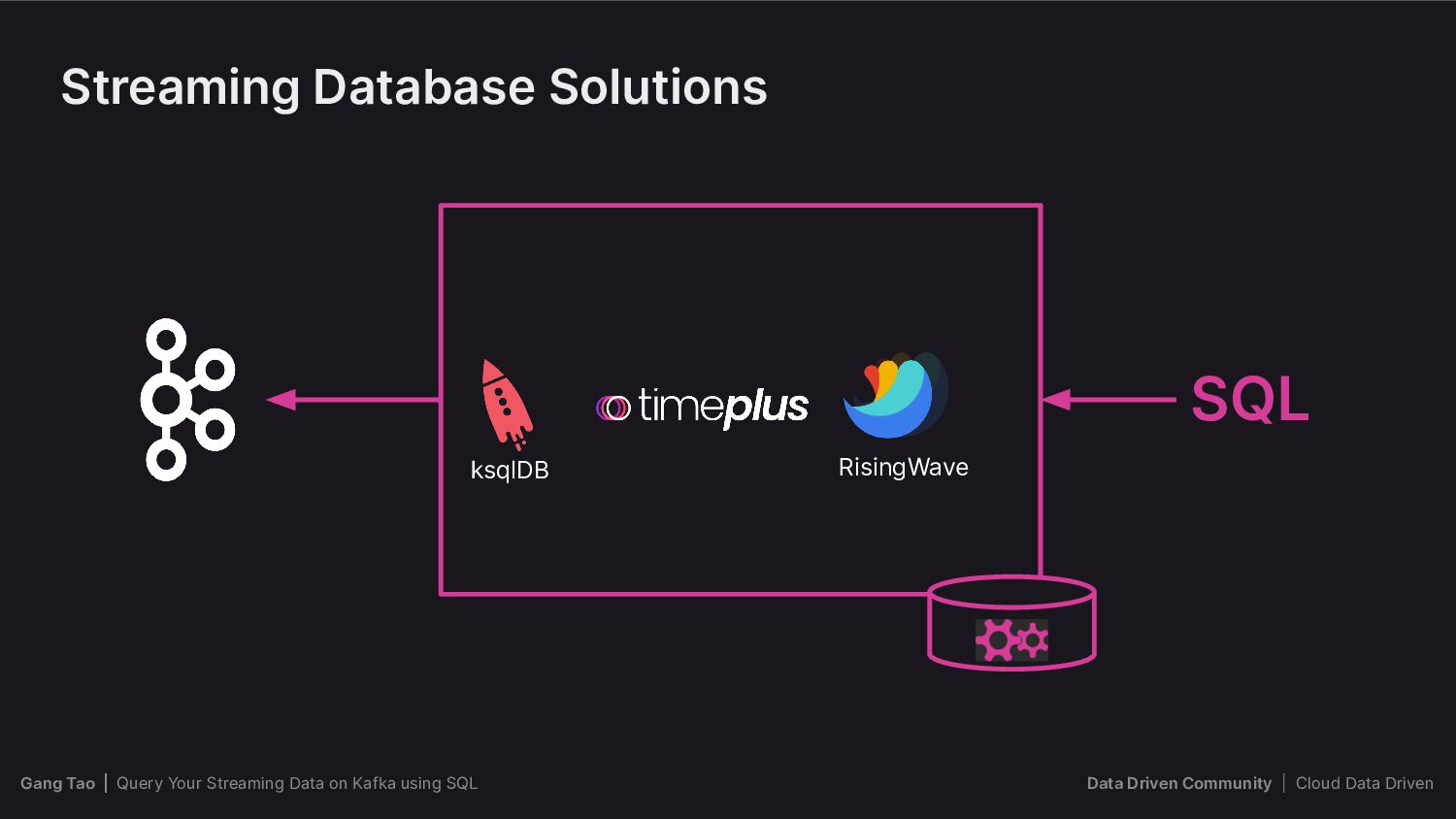{kind=link}
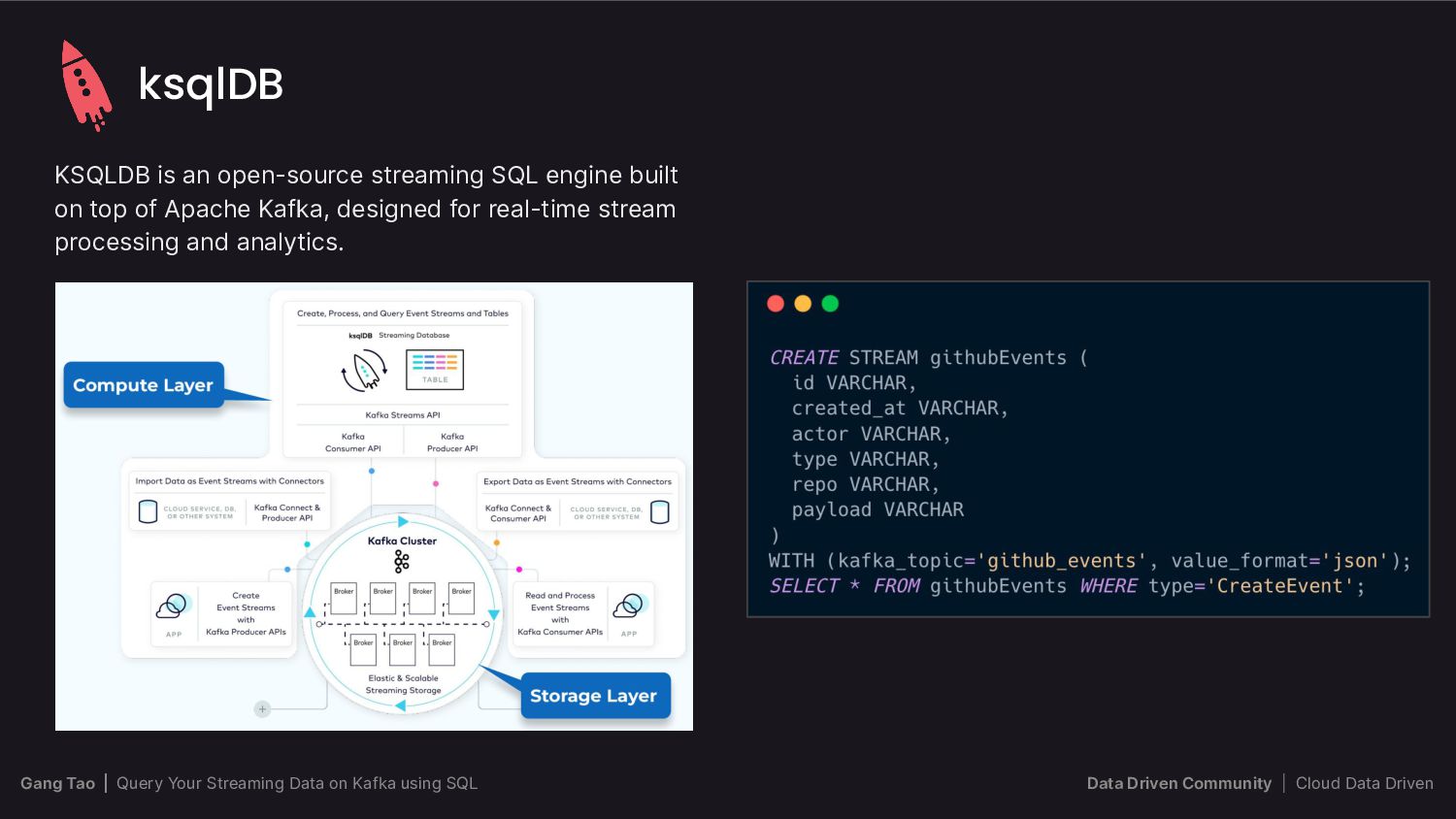{kind=link}
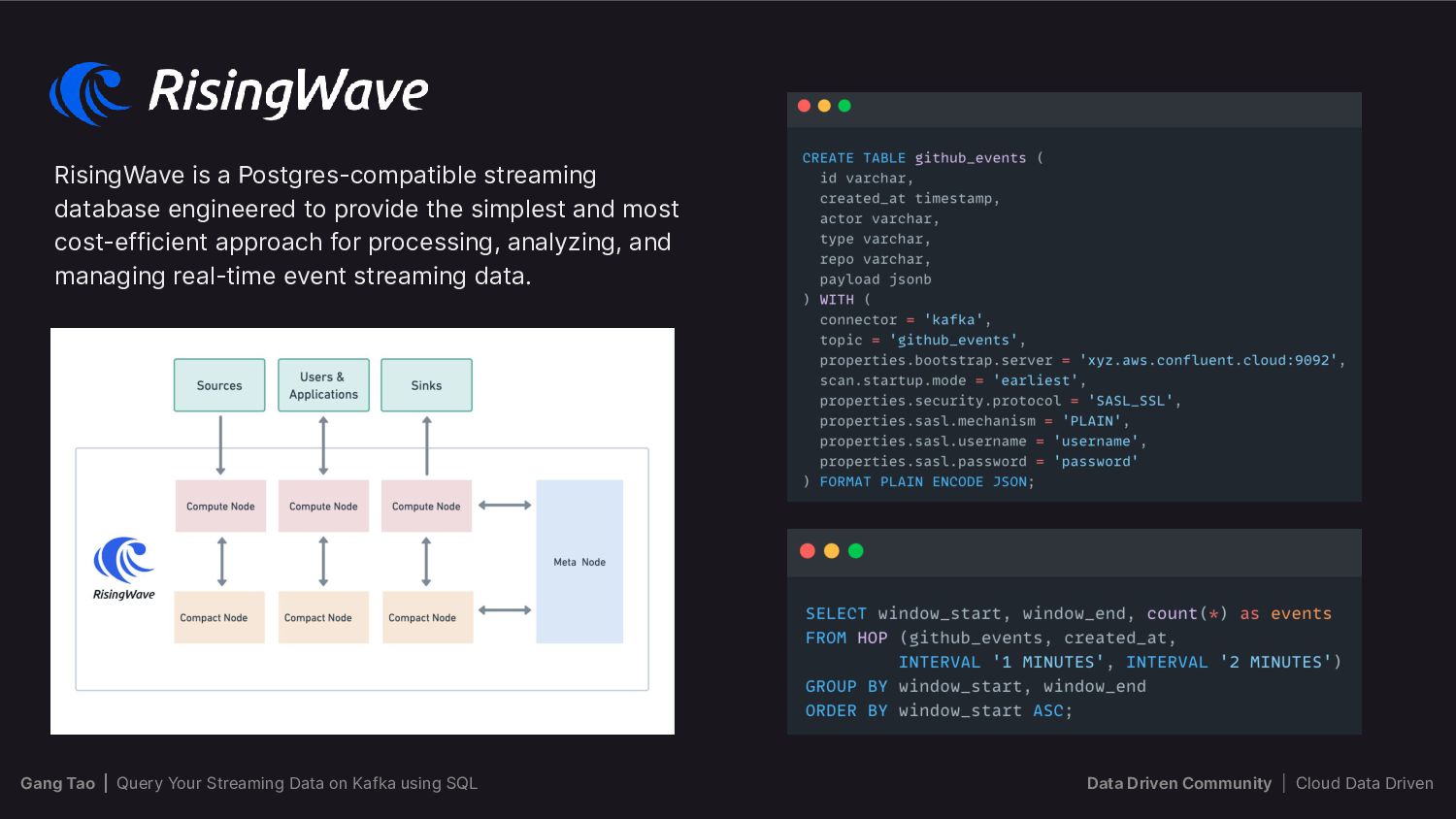{kind=link}
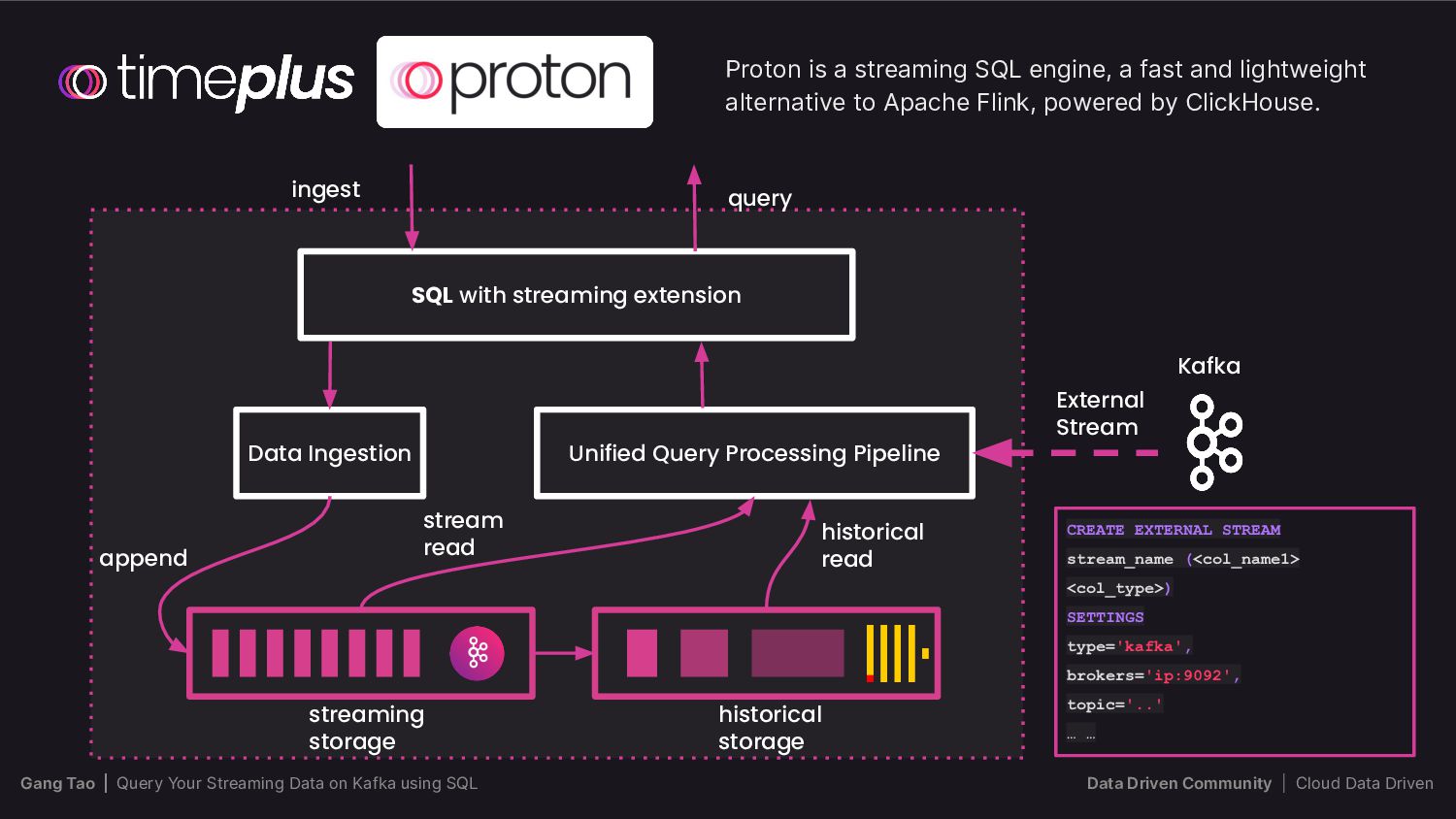{kind=link}
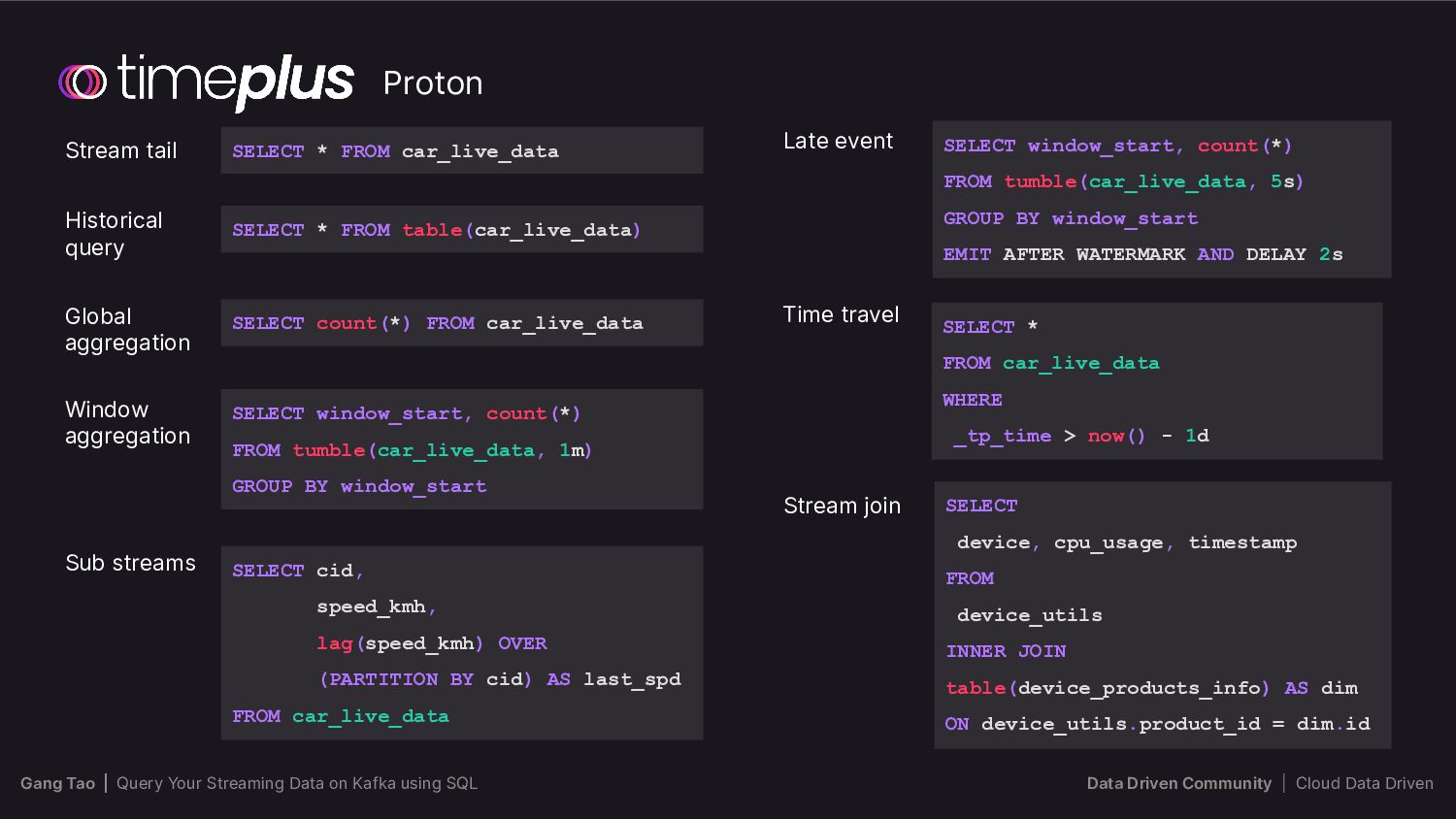{kind=link}
{kind=link}
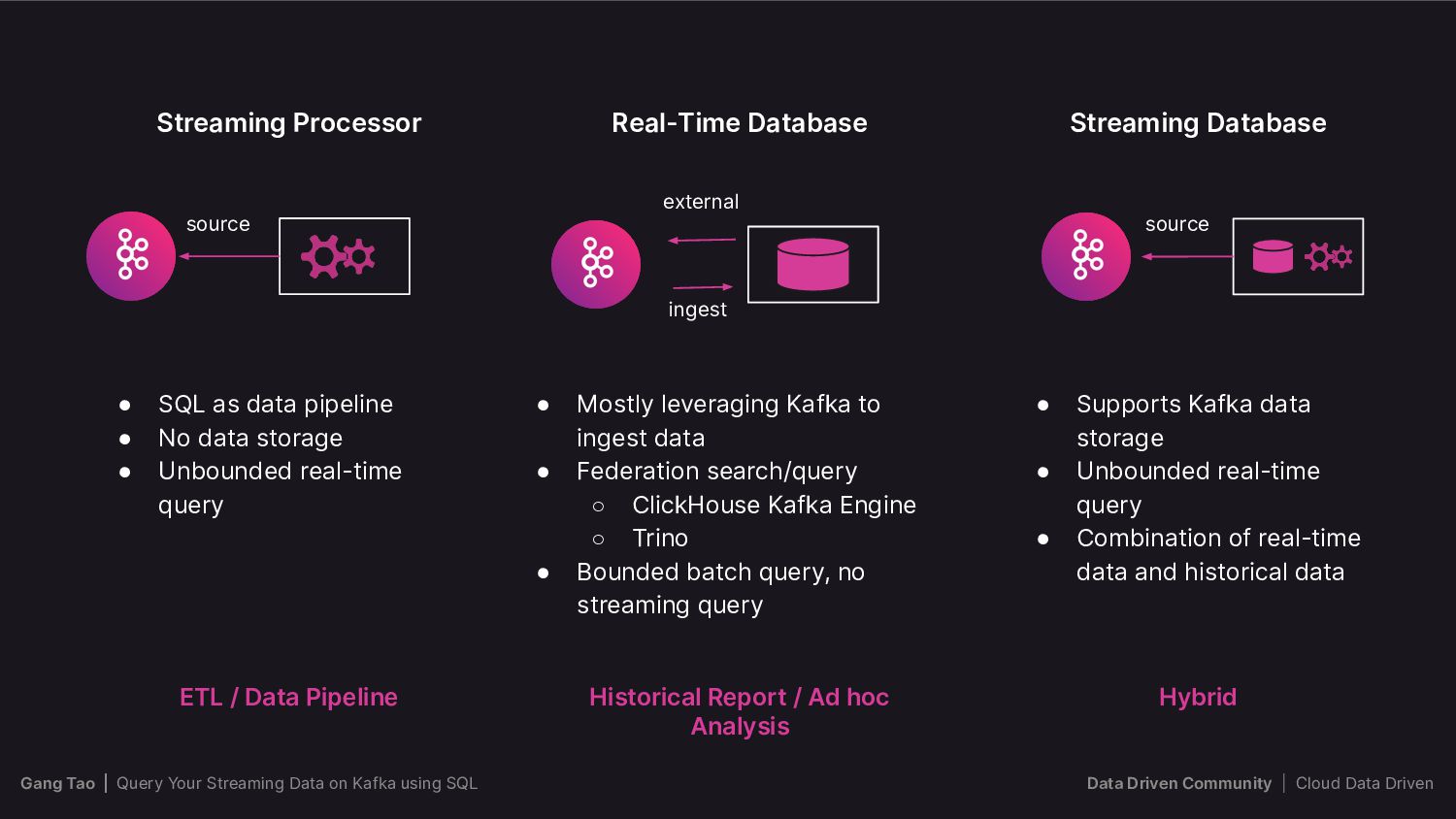{kind=link}
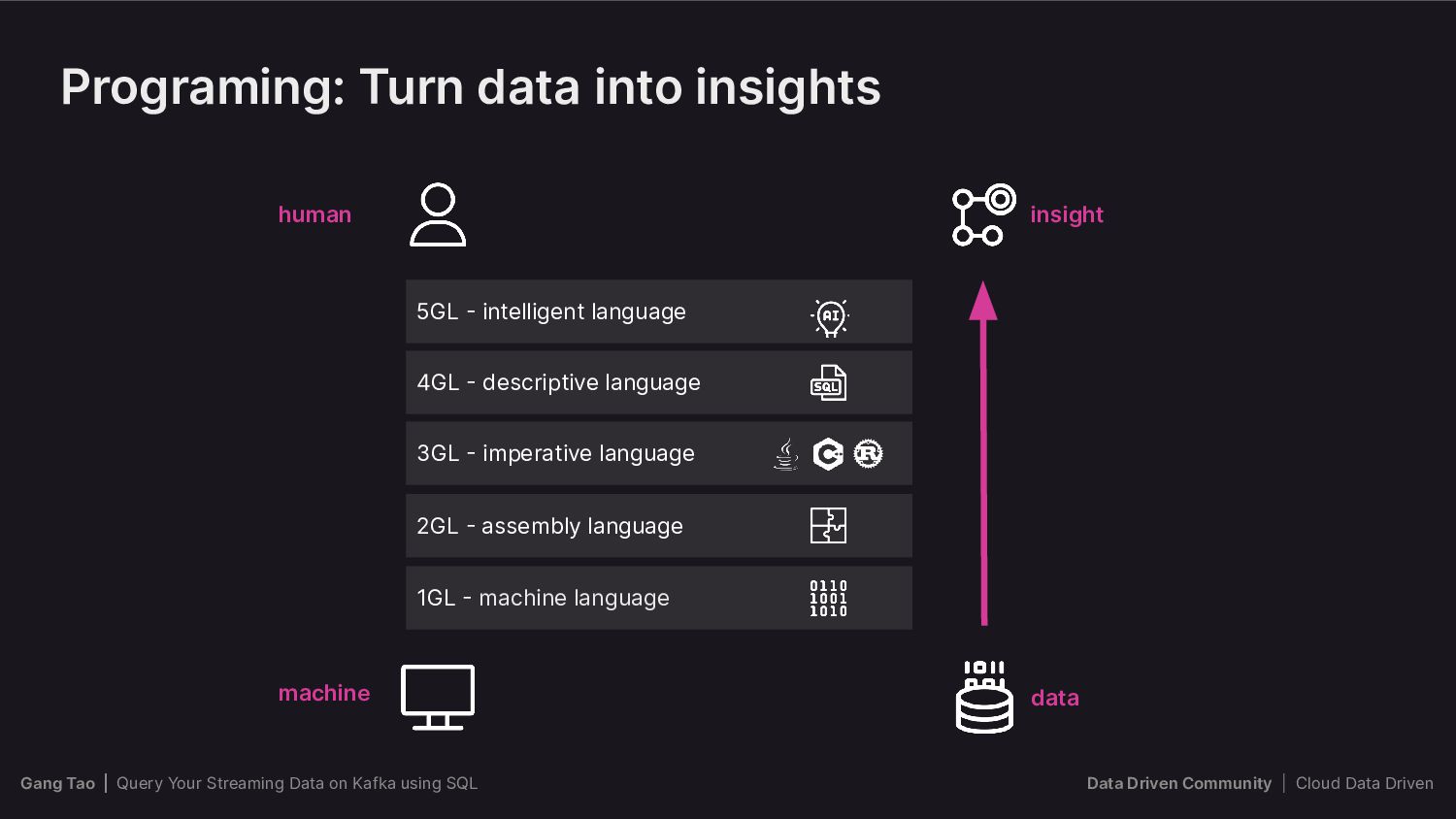{kind=link}
{kind=link}
{kind=link}
{kind=link}