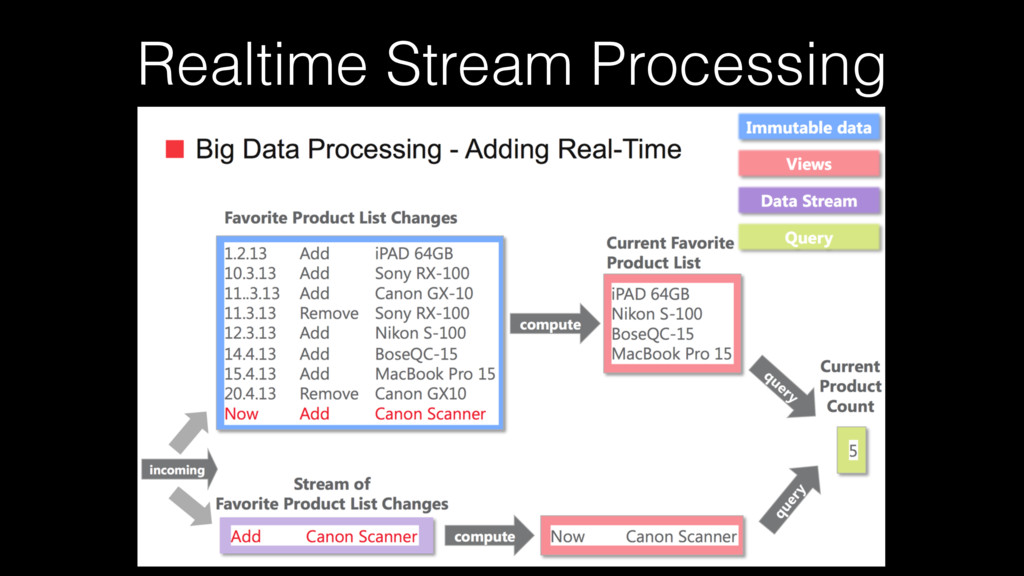
data loss or data corruption because at scale it could be irreparable. data immutability – store data in it’s rawest form immutable and for perpetuity. (INSERT/ SELECT/DELETE but no UPDATE !) recomputation – with the two principles above it is always possible to (re)-compute results by running a function on the raw data.
data • There should be another way to query past data • Queries cannot be run twice • All results will be lost when any error occurs All data have gone when bugs found • Disorders of events break results • Recorded time based queries? Or arrival time based queries?
{kind=link}
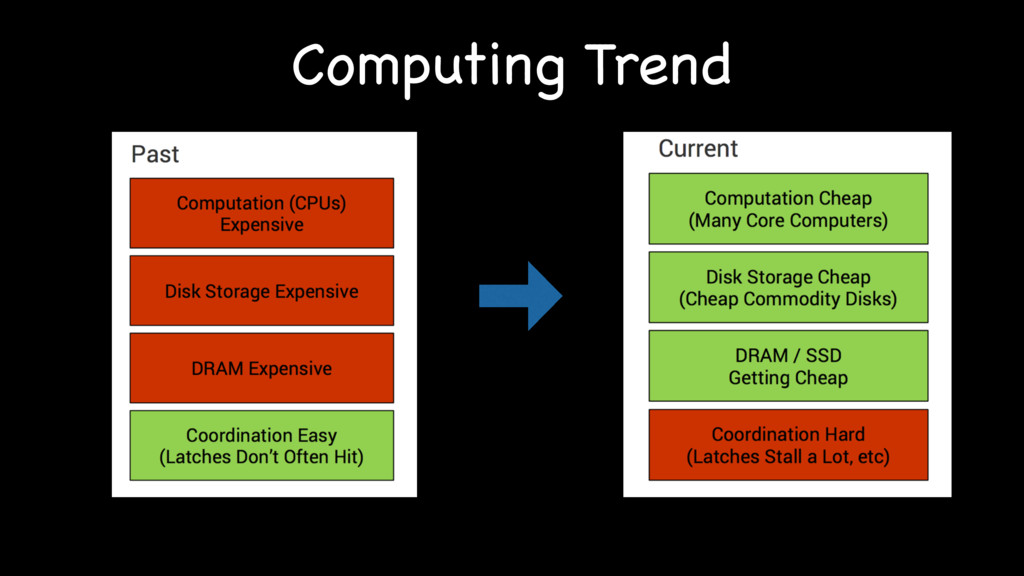{kind=link}
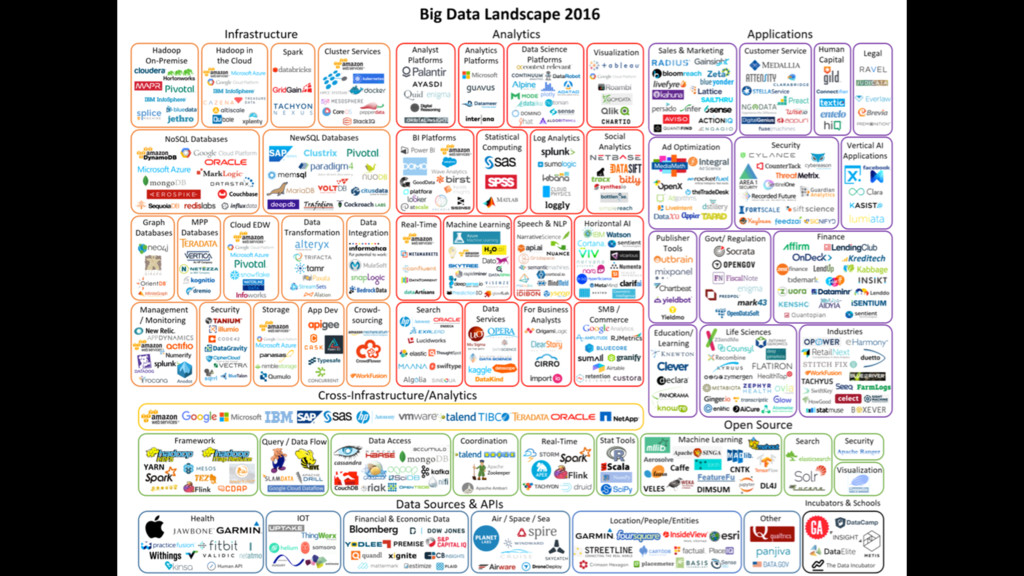{kind=link}
{kind=link}
{kind=link}
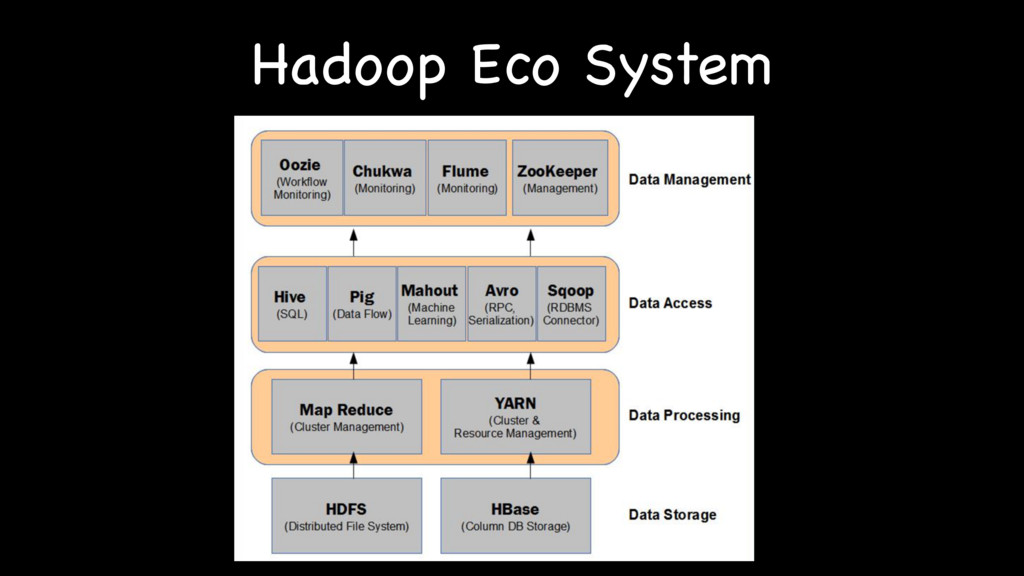{kind=link}
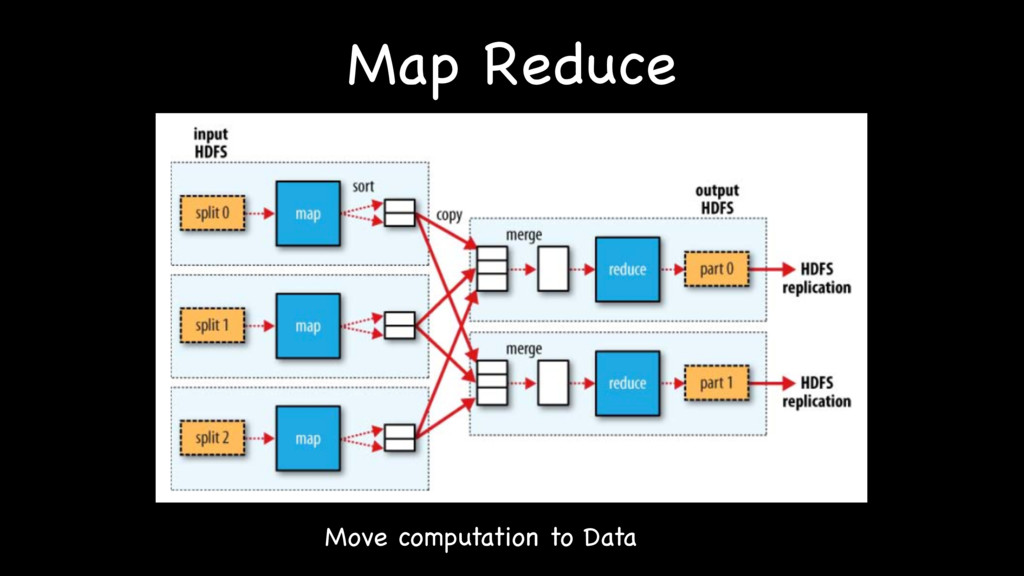{kind=link}
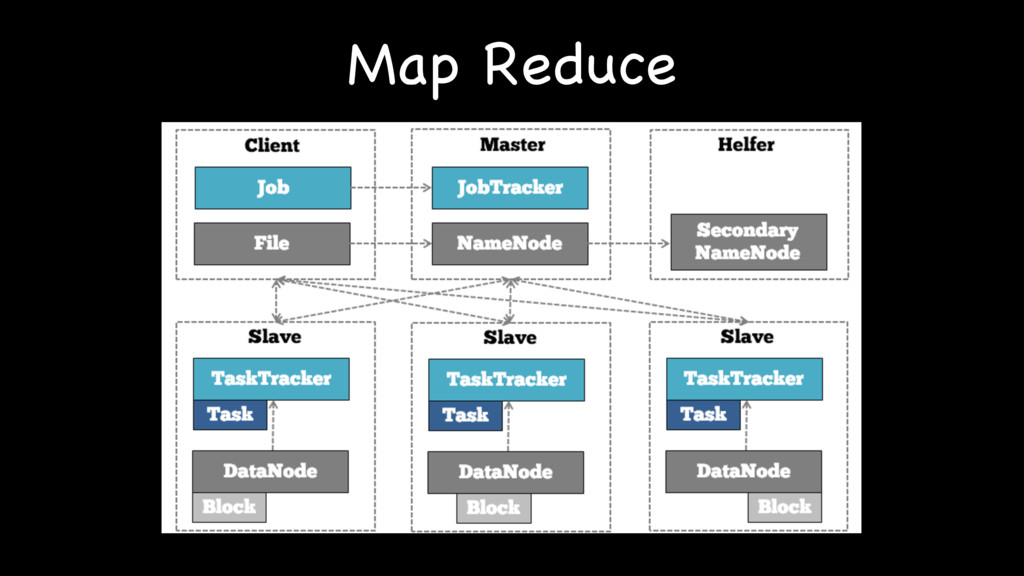{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
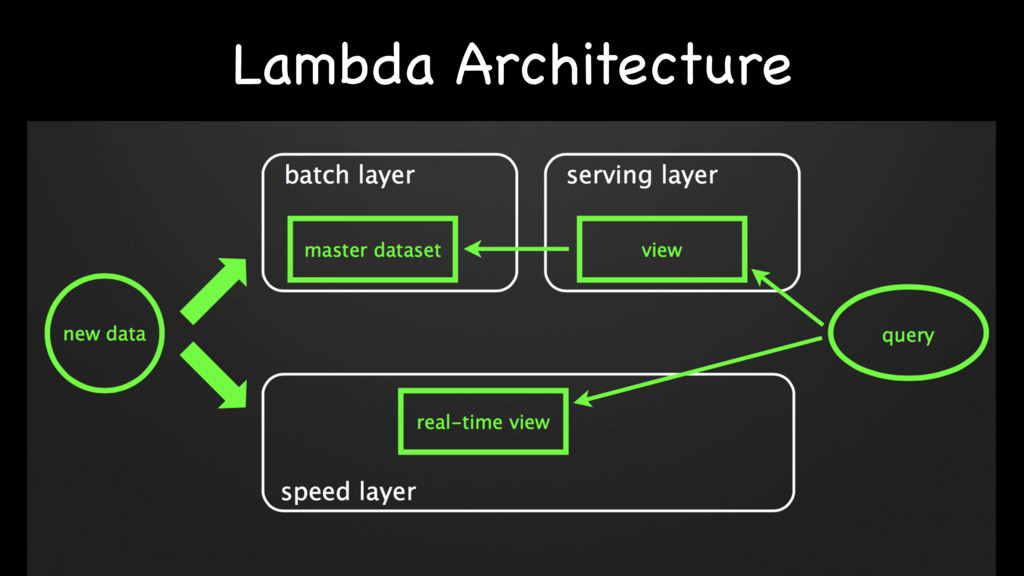{kind=link}
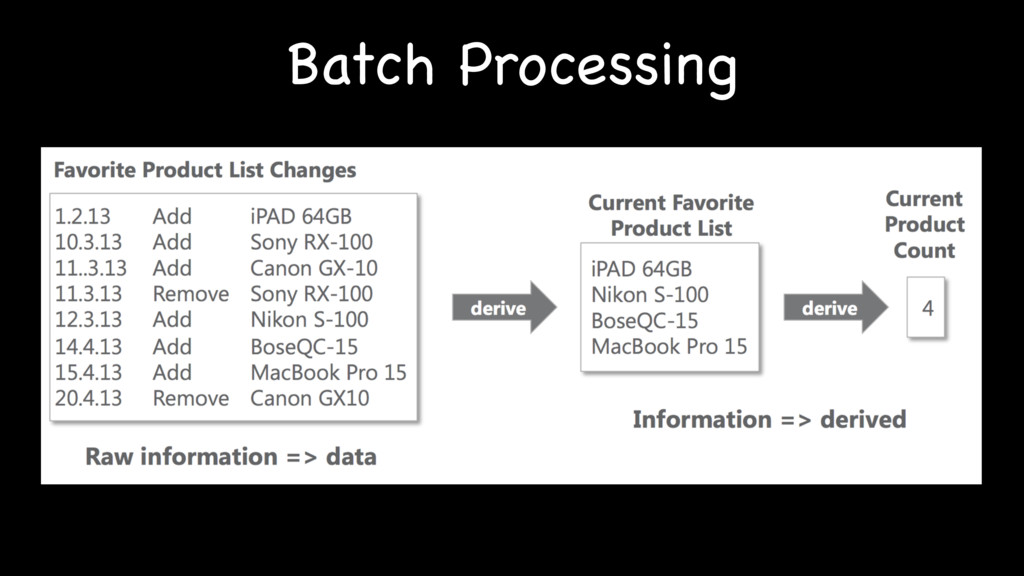{kind=link}
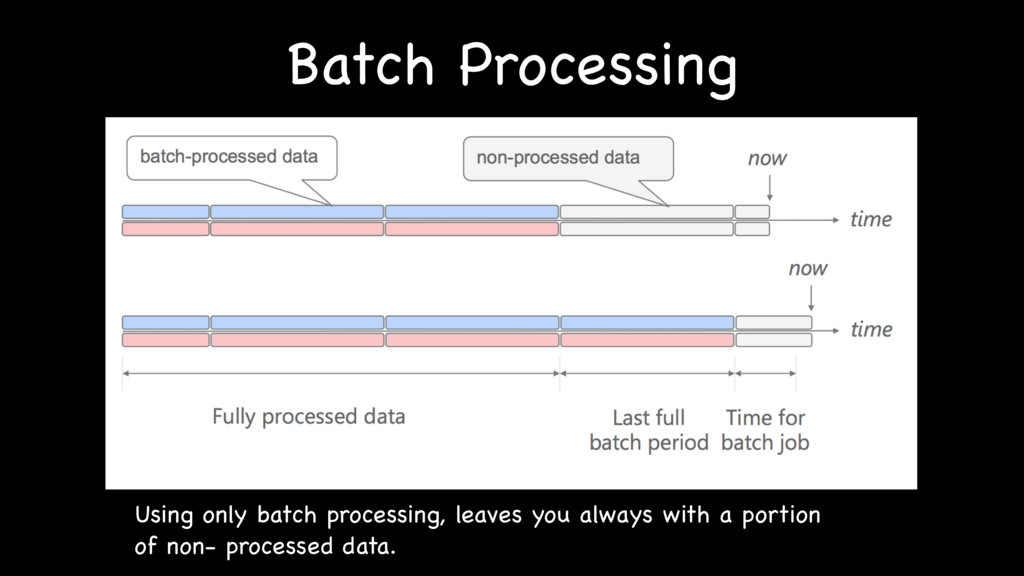{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
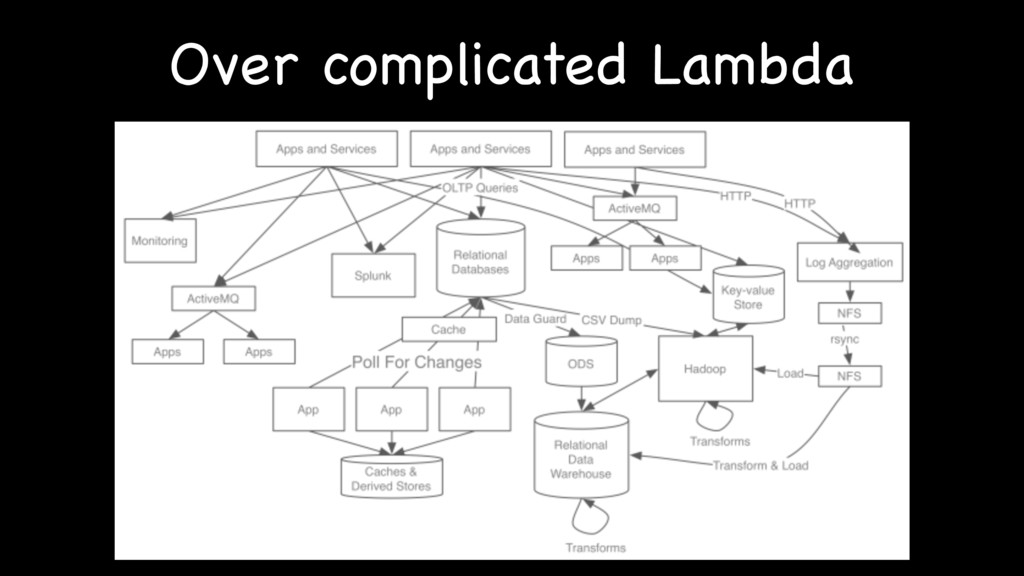{kind=link}
{kind=link}
{kind=link}
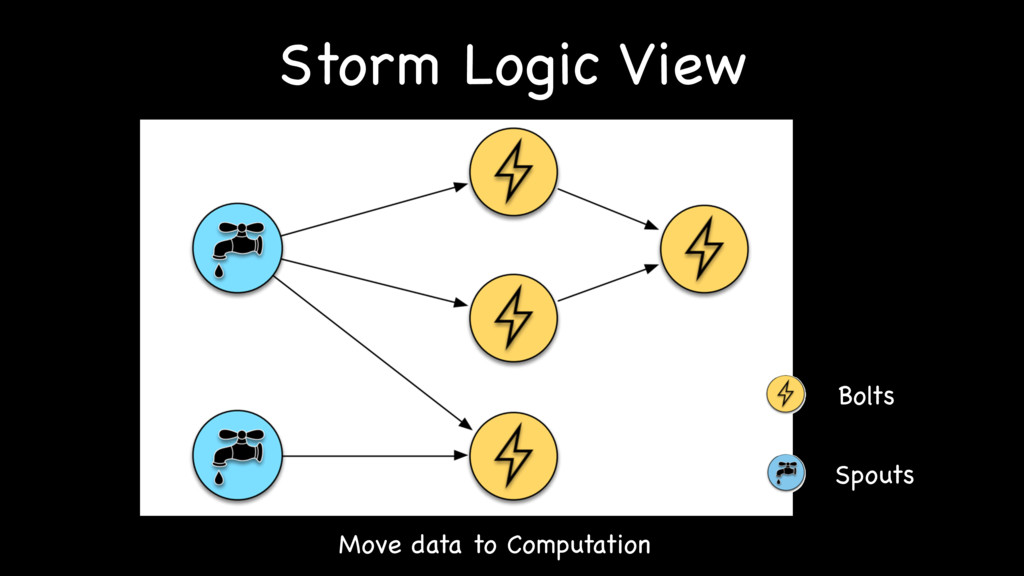{kind=link}
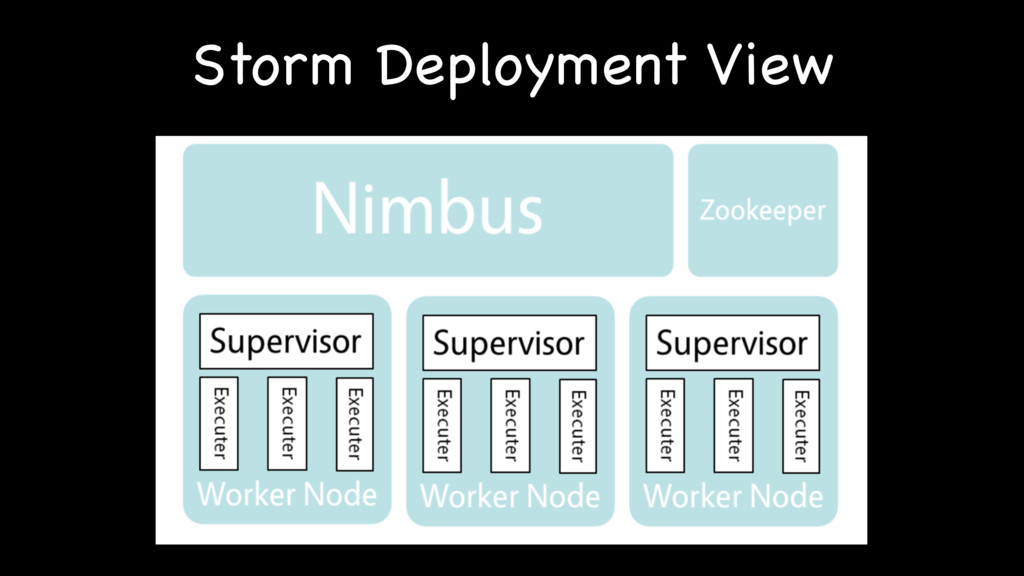{kind=link}
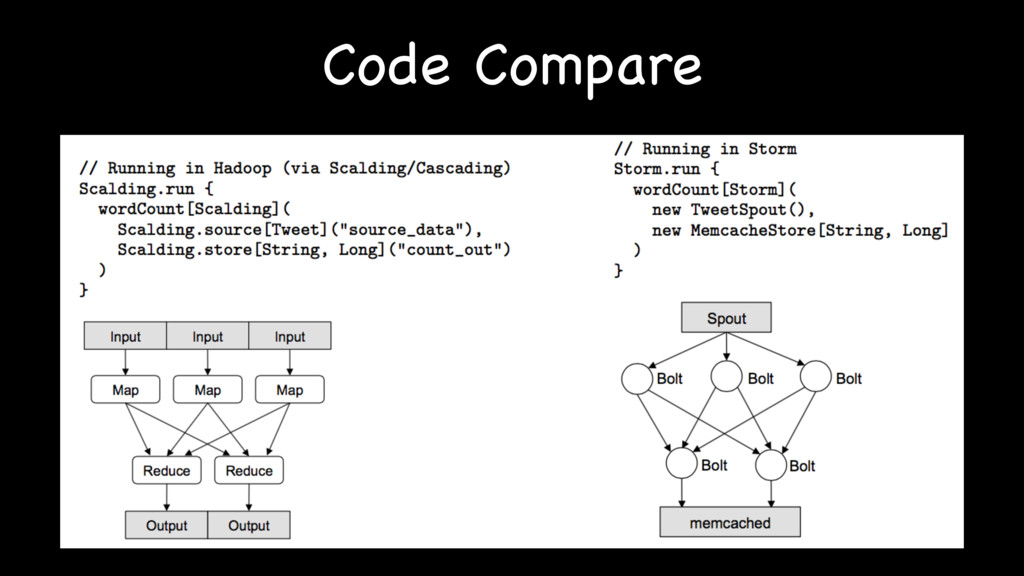{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
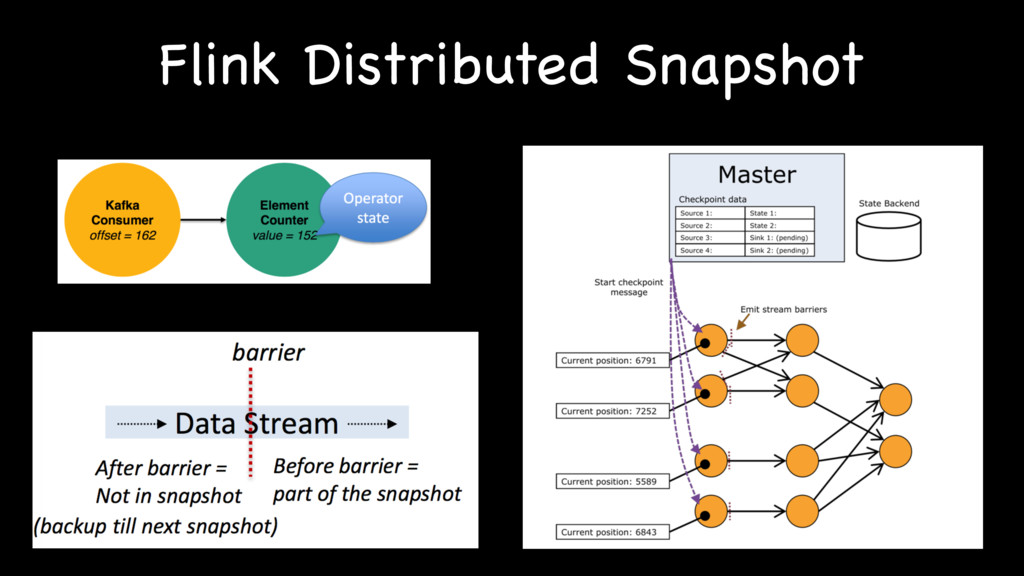{kind=link}
{kind=link}
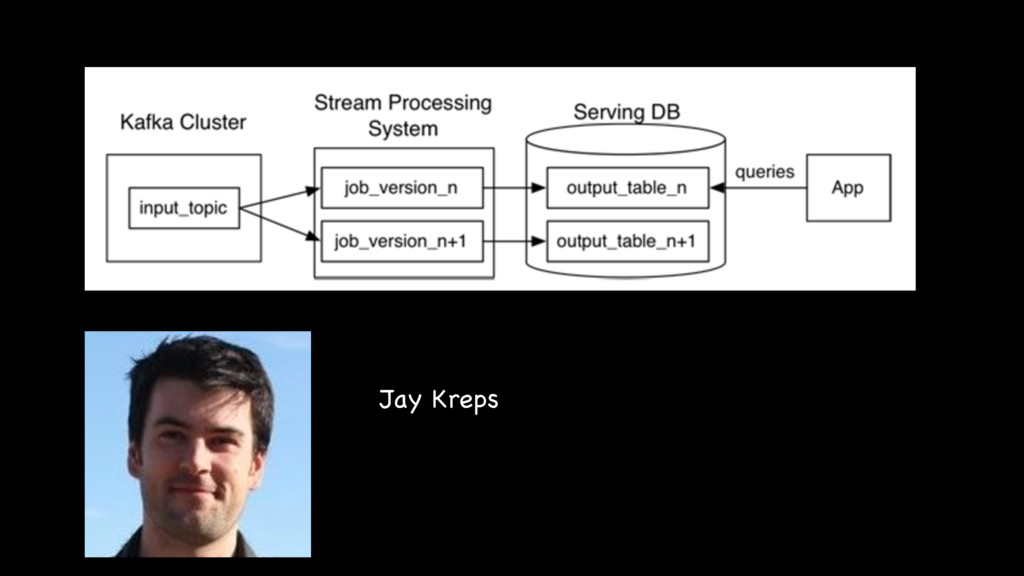{kind=link}
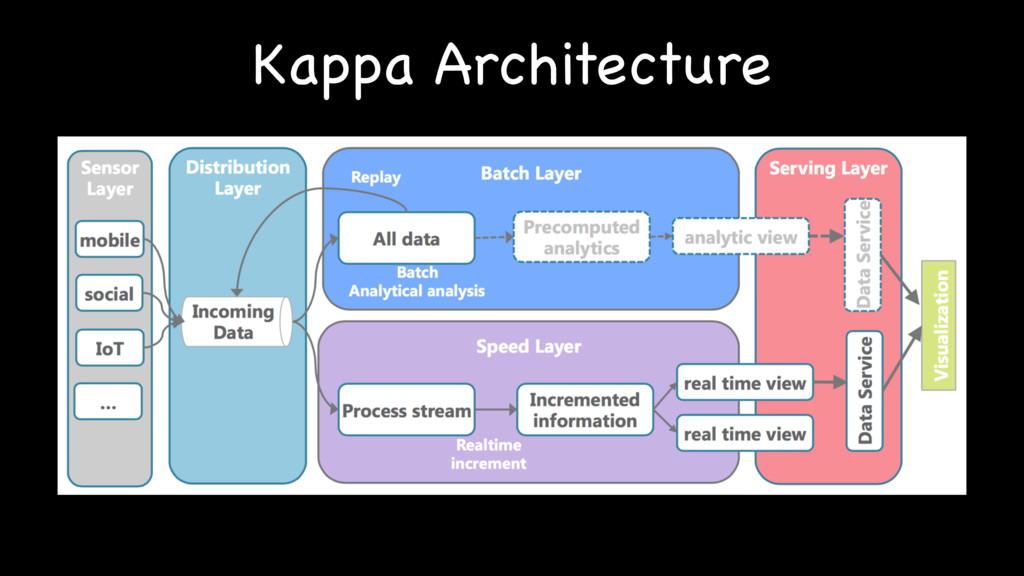{kind=link}