LKRhash is a hashtable that scales to multiple processors and millions of items. LKRhash was invented at Microsoft in 1997 by Paul Larson, Murali Krishnan, and George Reilly, and has been used in many Microsoft products. George will discuss the techniques that give LKRhash its performance, including linear hashing, cache-friendly data structures, and fine-grained locking.
More: http://nwcpp.org/june-2012.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
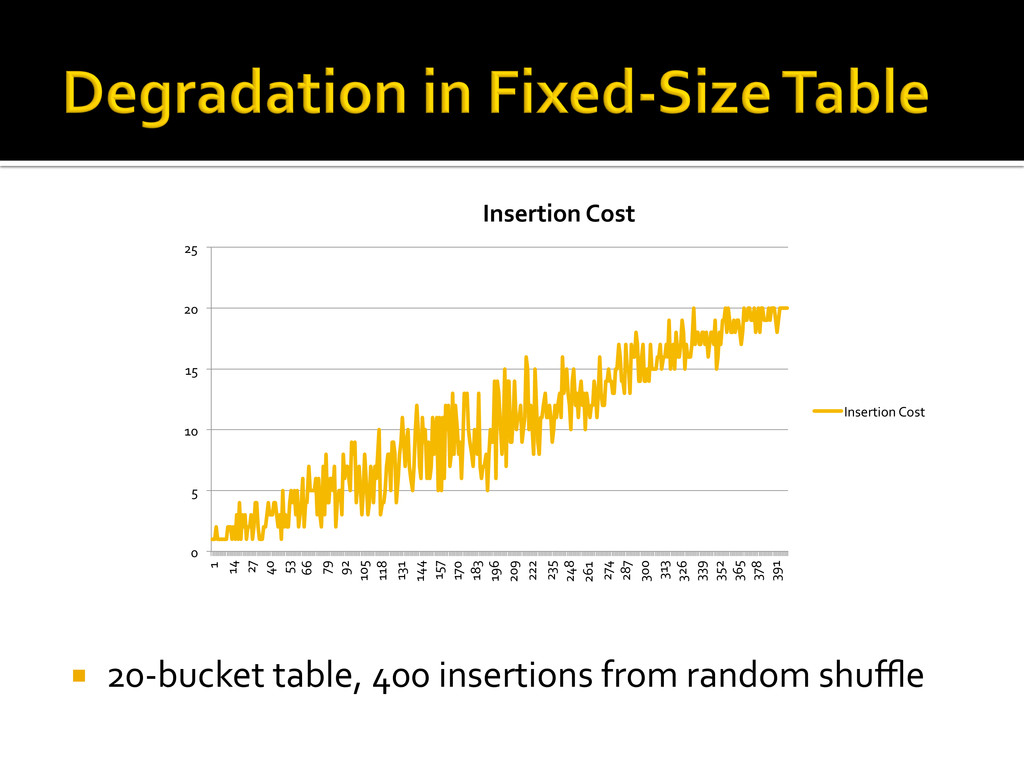{kind=link}
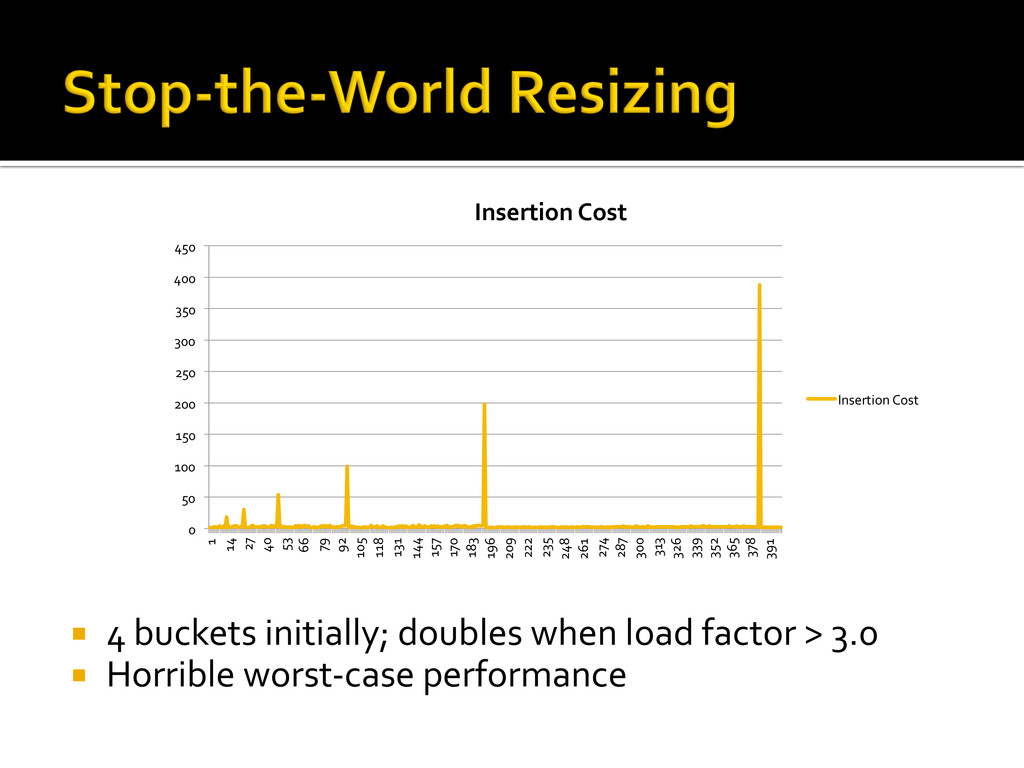{kind=link}
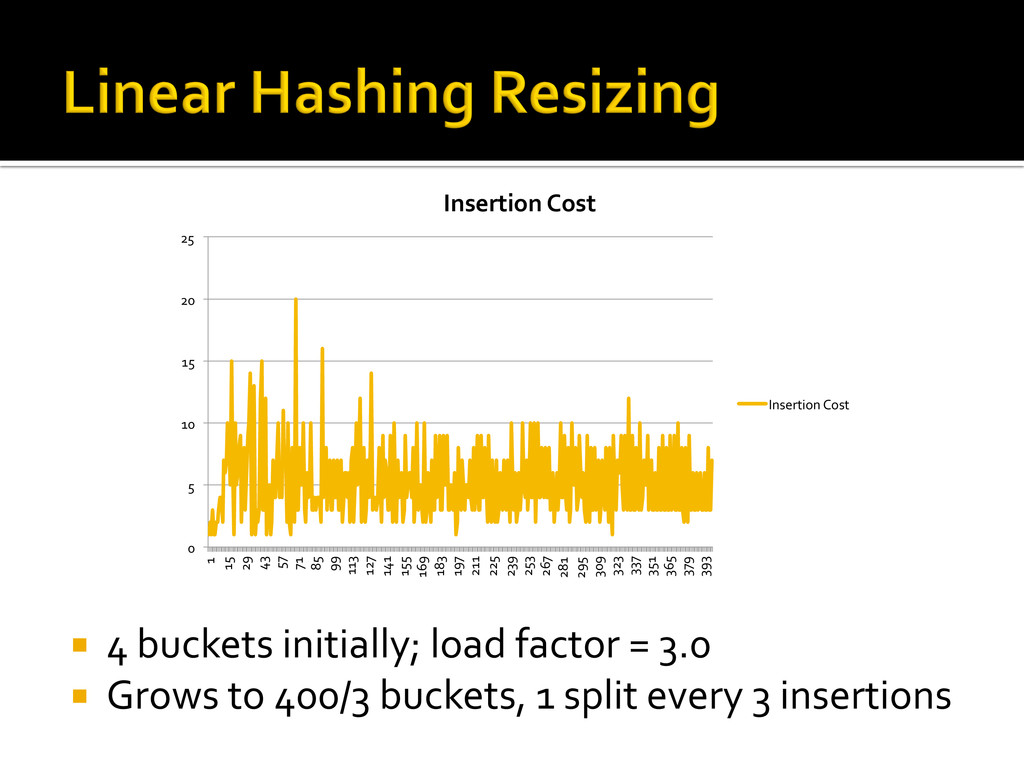{kind=link}
{kind=link}
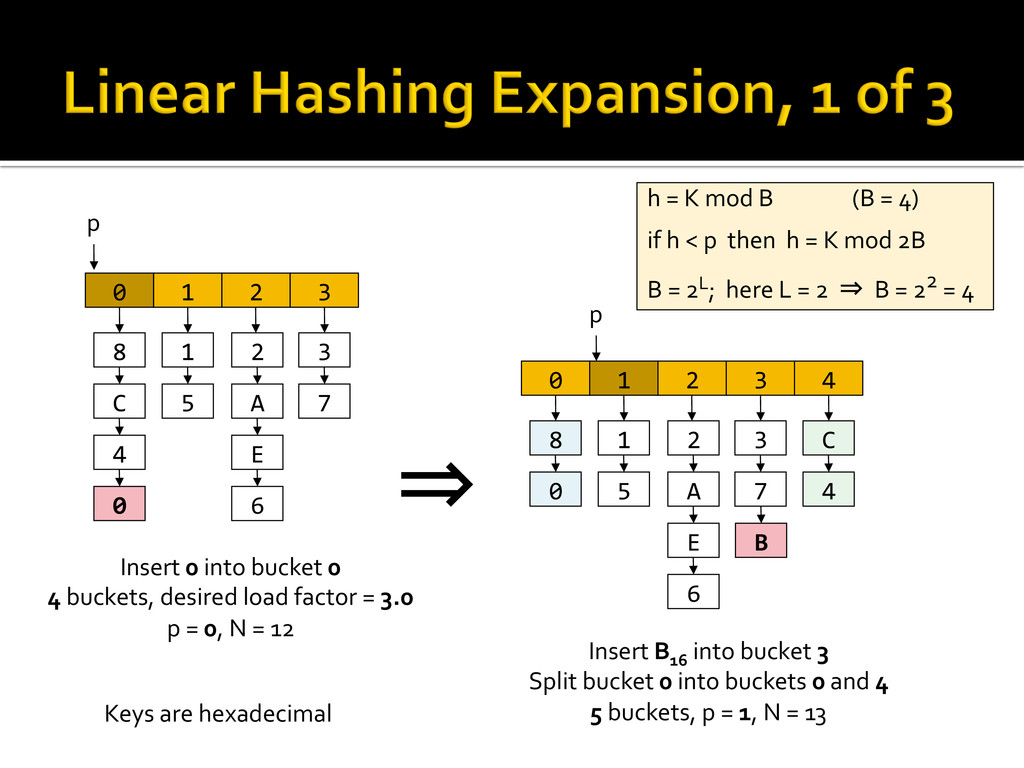{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
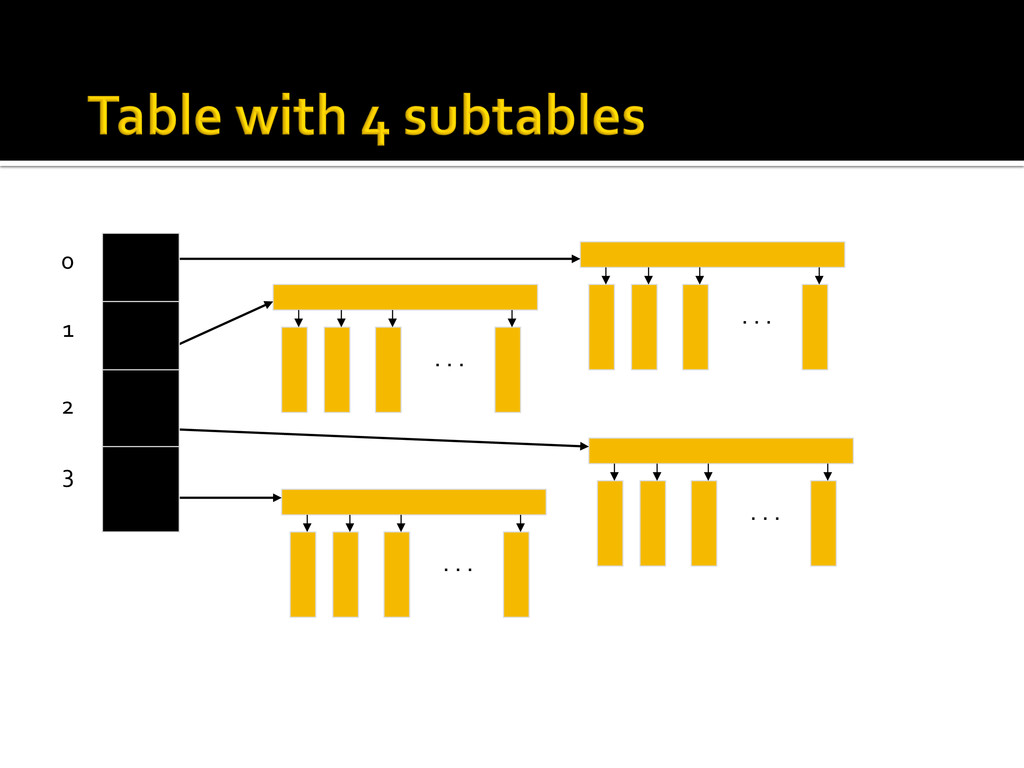{kind=link}
{kind=link}
{kind=link}
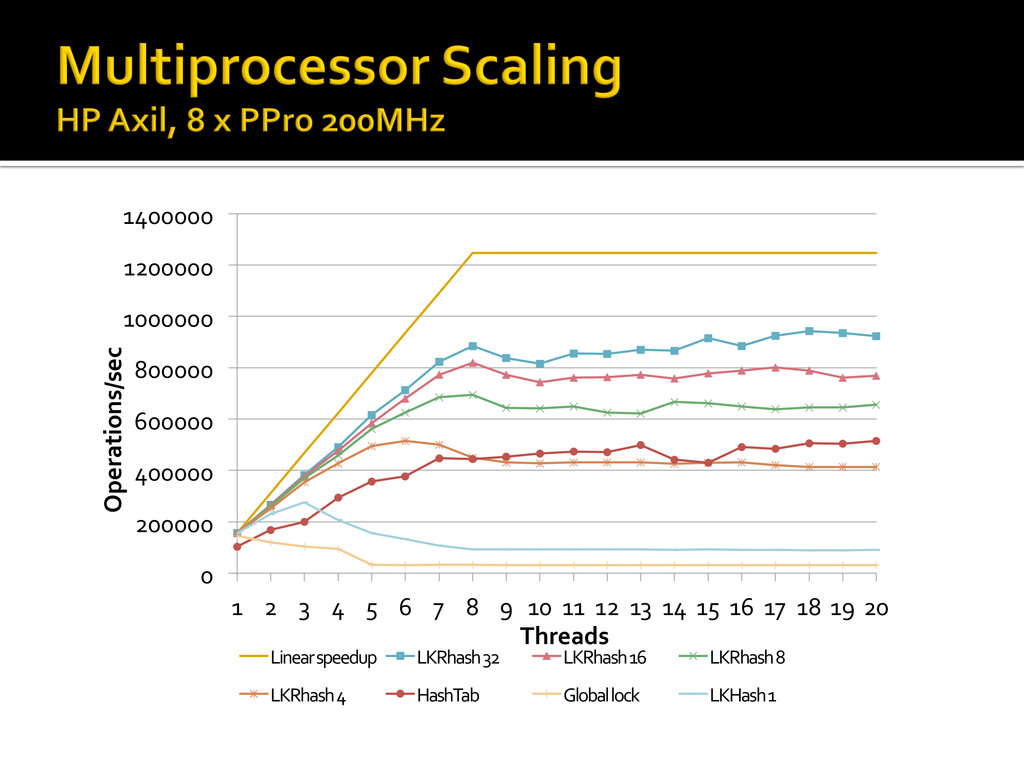{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}