Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
非同期AMI Sys ロードマップ to Milestone 2
Search
Geson Anko
March 19, 2024
58
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
非同期AMI Sys ロードマップ to Milestone 2
Geson Anko
March 19, 2024
More Decks by Geson Anko
See All by Geson Anko
2025年12月3日.人類には激kawaiiネコミミメイドロボが必要である
gesonanko
0
53
ML集会 2025年10月15日 LTのはじめかた
gesonanko
0
68
【RSJ2025】PAMIQ Core: リアルタイム継続学習のための⾮同期推論・学習フレームワーク
gesonanko
0
990
Pythonクラス基礎
gesonanko
1
140
自律機械知能基礎論 2024
gesonanko
0
50
2024年5月18日 XRMTGエンジニア飲み集会LT
gesonanko
0
50
AMI System基礎 2025
gesonanko
1
110
2025年1月10日 エンジニア集会 誰かと開発するために
gesonanko
0
120
2024年3月27日 ML集会 非同期AMI基盤システムα
gesonanko
0
82
Featured
See All Featured
We Have a Design System, Now What?
morganepeng
55
8.2k
Six Lessons from altMBA
skipperchong
29
4.3k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Facilitating Awesome Meetings
lara
57
7k
The Spectacular Lies of Maps
axbom
PRO
1
860
Bash Introduction
62gerente
615
220k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
The Curious Case for Waylosing
cassininazir
1
430
Exploring anti-patterns in Rails
aemeredith
3
440
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Transcript
ロードマップ to Milestone 2 2024/03/20 Geson Anko
1 ⽬的・⽬標 • 以上の課題より、推論と学習を⾮同期に並⾏して⾏う システムが必須。 • ⽬標 • ⾮同期更新システムが実装され、推論(ロールアウト、インタラ クション)処理と学習処理が並⾏して⾏われることによって、
AMIが常時動作していること。 • ⾮同期システムを新たに作成し、そこに既存のモデルを移⾏する。 • さらに、今まで不可能だったモデルの⼤規模化の試運転までやっ てみたい。
2 ロードマップ • ステップ1 ⾮同期システムが動作する。 • 推論スレッド:モデルの推論をしつつ、データ収集 • 学習スレッド:集められたデータでパラメータ更新、同期 •
メインスレッド:終了、⼀時停⽌、再開ができる モデル • ランダムな⼊⼒を与えて、AutoEncoderを学習してみる(構想) • AutoEncoderは Encoderのみしか推論では使わない → 簡単に実装できて実際の動作形式に近い ✅ ୡ ✅ ✅ ✅
3 ロードマップ • ステップ2 既存の深層モデルが引き継がれる 現状P-AMI<Q>に使われているモデル群を移⾏する。 • Observation Encoder: VAE
• Forward Dynamics: SConv • Policy: PPO • Hydraによる設定ファイルからの起動✅ ✅
4 スケージューリング 1/21 2/4 2/18 3/3 3/17 3/27 ⾮同期システム 既存モデル引き継ぎ
モデル規模拡⼤ 最終報告・振り返り ΠϚ ίί なぜ遅れたか? • メンバー全員が2~3週間 まともに 動けない期間が発⽣(病気、卒研、引越し) • マイルストーン 2のHydraまでやった。(システムの起動のために) • 3つのマイルストーンのうち、最初が⼀番⼤変だったから。(実は全体の6~7割くらい進んでいる)
5 To Do
6 To Do: マイルストーンステップ2 • 既存実装の引き継ぎ • Environment (Sensor, Actuator)
• Models • Data Buffers • Agent • Trainers • システムの状態セーブ・ロード機能 • モデルパラメータ、オブジェクトの状態情報 • 学習記録の可視化 • TensorBoard, MLFlowなど
7 Environment (Sensor & Actuator) • I/O • ⼊⼒:3 x
84 x 84のRGB画像 OBSでキャプチャして OpenCVで読み取り • 出⼒:OSCで操作 前後左右の移動、⽔平回転 ジャンプ、ラン • 作るもの • OpenCVImageSensor • VRChatOSCDiscreteActuator OBS OpenCV VRChat OSC API Ubuntu Linux Python 観測 ⾏動
8 Models • Observation Encoder 𝜙 𝑜! → 𝑧! ✅
• マイルストーン1で作ったVAEを使う。 • Forward Dynamics 𝑓 𝑧! , ℎ! , 𝑎! → 𝑧!"# , ℎ!"# • MyxyさんのSConv を引継ぐ。 • 隠れ状態は⼊出⼒上で明⽰的に扱う。 • Primitive AMIでは存在した 𝑎!"# は使わない。 • Policy 𝜋 𝑜! → 𝑎! • PPOを引継ぐ。PolicyValueCommonNet. • Policyは 5次元の離散⾏動を返す。
9 Data Buffers • Random Image Buffer (for VAE) ✅
• 観測画像をランダムに集める。 • 既に実装済。Random Data Bufferを特殊化するか? (わかりやすさのために) • Time Series Dynamics Buffer (for Forward Dynamics) • 時系列を維持して 観測、隠れ状態、⾏動 𝑜!, ℎ!, 𝑎! を集める。 • Time Series Trajectory Buffer (for PPO Policy) • 時系列を維持して、PPOの学習に必要なデータを集める。
10 Agent (Curiosity Image PPO Agent) • インタラクション処理 • 観測を処理、⾏動を返す
• 学習データをBufferに渡す。 • PrimitiveAMIのものを引継 • ただし 前ステップの情報を保持する 時は Agentの属性に付ける。 StepData は DataBufferのためのオ ブジェクト。 • Reward 計算モジュール • 報酬の計算⽅法を内部構造から分離 3/19のmyxyさんとの議論より。 観測 取得 ⾏動 ⽣成 次の観測 予測 報酬(予測誤差)計算 インタラクション 10 fps 観測 取得 次の観測 予測 ⾏動 ⽣成 セット アップ
11 Trainers • Image VAE Trainer ✅ • 既に実装済 •
学習記録処理を実装する • Forward Dynamics Trainer • Primitive AMIのLitモジュールから引継。 • PPO Policy Trainer • Primitive AMIのLitモジュールから引継。
12 システムの状態セーブ・ロード • セーブするもの • モデルパラメータ • オプティマイザなどの Trainer の状態
• Agent, Environmentなどの状態 • 特に Forward Dynamicsの 隠れ状態を忘れずに • Data Bufferの保持データ • 保存⽅法 • ⼀つのディレクトリに、階層に分けて保存。 • リスタート • python launch.py checkpoint=<path/to/checkpoint> YYYY-MM-DD_hh-mm-ss/ ├── models/ │ ├── image_encoder.pth │ └── ... ├── data/ │ └── ... ├── trainers/ │ └── ... └── interaction/ ├── agent/ │ └── ... └── environment/ └── ... 想定される Checkpointの構造
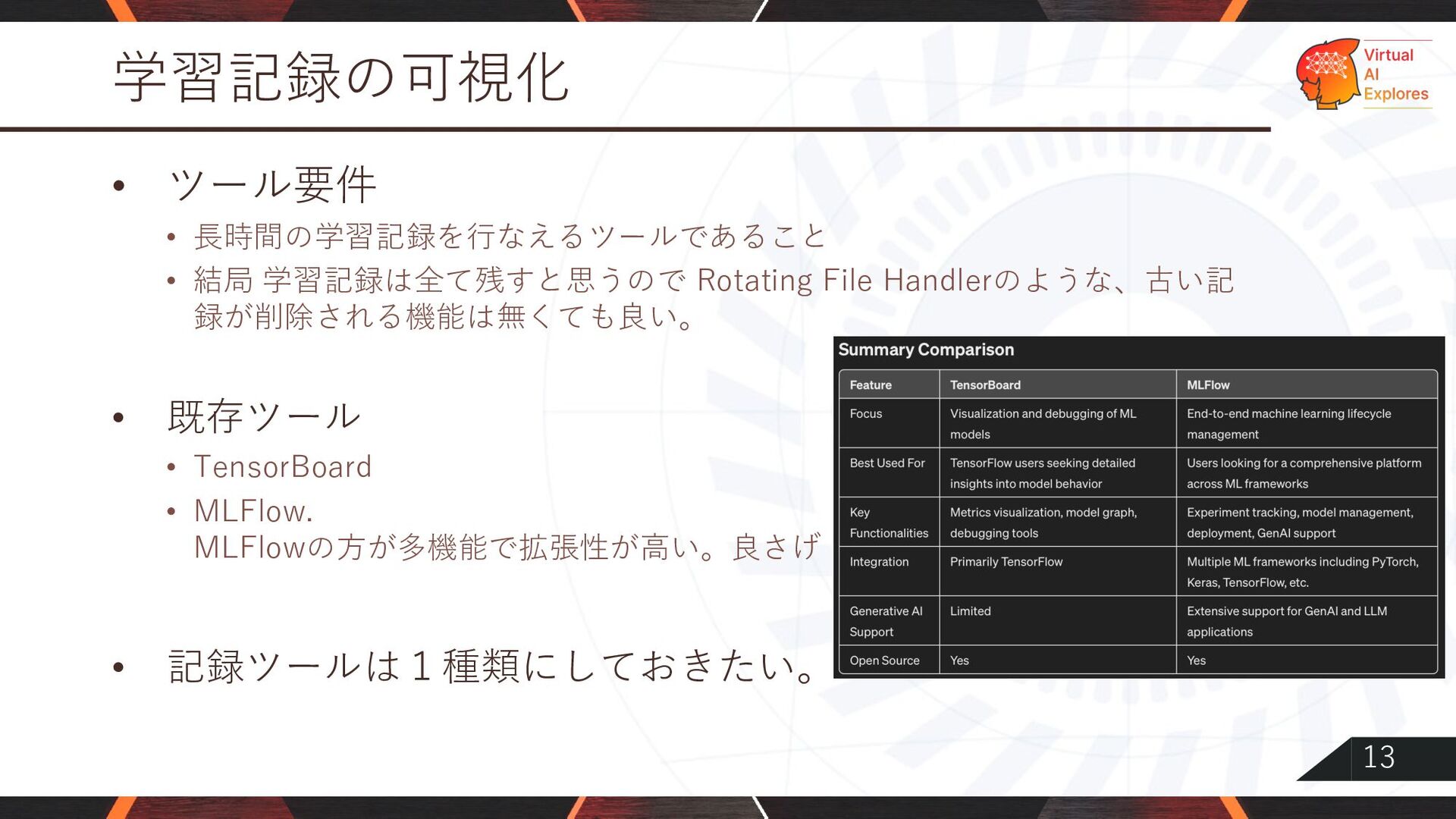
13 学習記録の可視化 • ツール要件 • ⻑時間の学習記録を⾏なえるツールであること • 結局 学習記録は全て残すと思うので Rotating
File Handlerのような、古い記 録が削除される機能は無くても良い。 • 既存ツール • TensorBoard • MLFlow. MLFlowの⽅が多機能で拡張性が⾼い。良さげ • 記録ツールは1種類にしておきたい。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}