2018) • 時間遷移を⽤いないので NoisyTV ProblemはOK. • ランダムノイズはエンコードできないので摂動問題は OK. • Self-Supervised Exploration via Disagreement (D. Pathak et al 2019) • 複数のForward Dynamicsモデルによる、予測の分散が報酬
intelligence Version 0.9.2, 2022- 06-27”, https://openreview.net/pdf?id=BZ5a1r-kVsf • 細川頼直, ”機巧図彙”, 須原屋市兵衛, 1796. https://dl.ndl.go.jp/pid/2607731 • Richard S. Sutton and Andrew G. Barto, ”Reinforcement Learning: An Introduction”, p.75, The MIT Press, 2018. • Introducing ChatGPT, https://openai.com/blog/chatgpt • GesonAnko et al, “VRChat 上における好奇⼼ベースの⾃律機械知能の実装”, バーチャル 学会2023, 2023. https://doi.org/10.57460/vconf.2023.0_81 • John Schulman et al, “Proximal Policy Optimization Algorithms”, arXiv, 2017. https://arxiv.org/abs/1707.06347 • Diederik P Kingma and Max Welling, “Auto-Encoding Variational Bayes”, arXiv, 2013. https://arxiv.org/abs/1312.6114 • Tri Dao and Albert Gu, “Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality”, arXiv, 2024. https://arxiv.org/abs/2405.21060
intrinsic motivation? A typology of computational approaches.” • M. G. Bellemare et al, (2016) “Unifying Count-Based Exploration and Intrinsic Motivation” • D. Pathak et al, (2017) “Curiosity-driven Exploration by Self-supervised Prediction” • Y. Burda et al, (2018) “Large-Scale Study of Curiosity-Driven Learning” • Y. Burda et al, (2018) “EXPLORATION BY RANDOM NETWORK DISTILLATION” • D. Pathak et al, (2019) “Self-Supervised Exploration via Disagreement”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
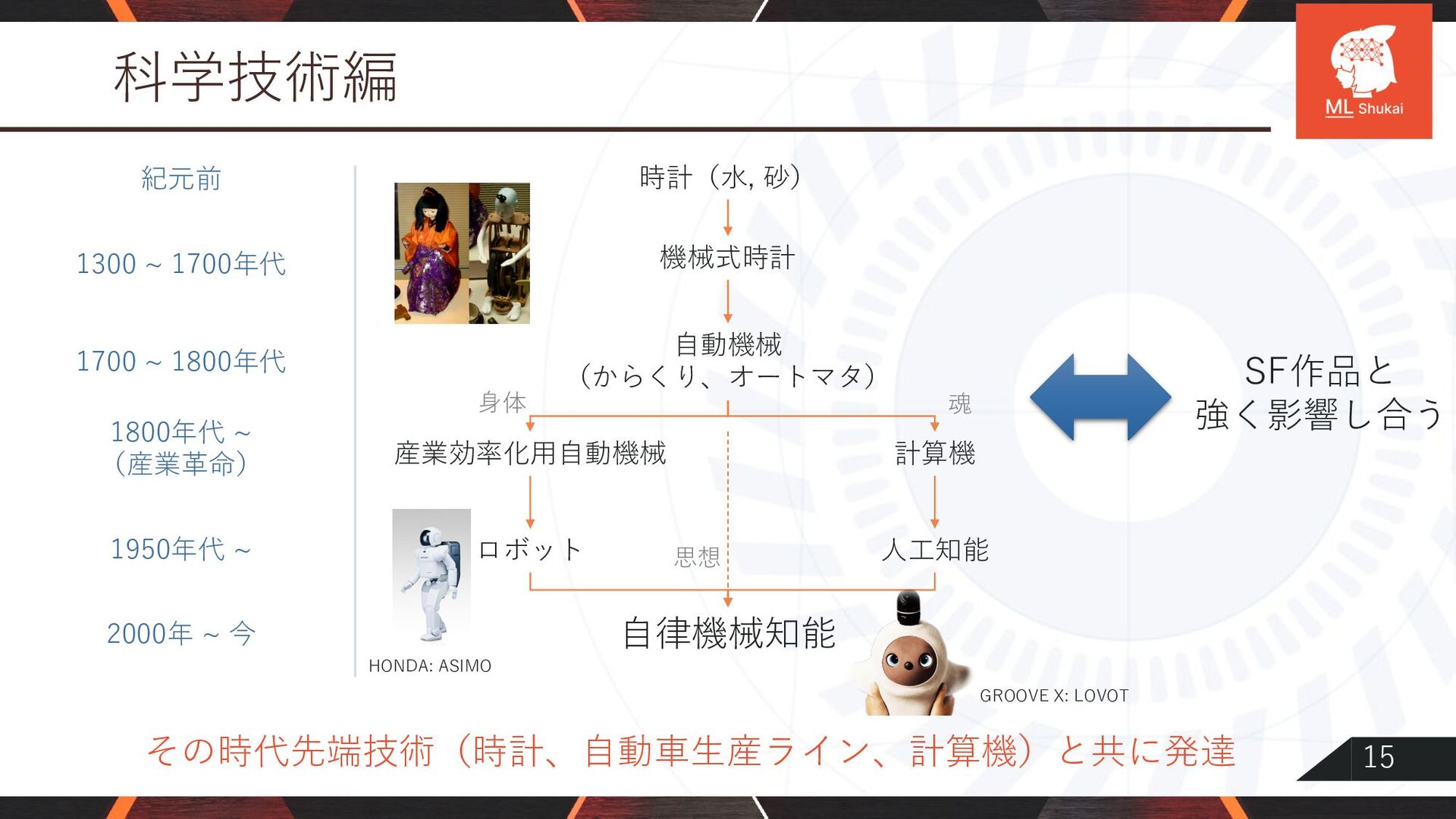
![7 ⽬的や⽬標について 2つの定め⽅ 1. ⾏動⼿続き・ルールの記述により暗黙的に定める • からくり⼈形[細川, 1796]といった、ハードウェア機構レベルの⾏動⽣成計画 2. 累積報酬和(収益)の最⼤化と定める。](https://files.speakerdeck.com/presentations/dfa84e31657a4629bb35e266796637ef/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![10 ⾃律機械知能ではない例 • ChatGPT [OpenAI, 2022] 単体 • ⾃律性 •](https://files.speakerdeck.com/presentations/dfa84e31657a4629bb35e266796637ef/slide_10.jpg){kind=link}
{kind=link}
![12 ⾃律機械知能の例 • ぱみきゅー [Geson+, 2023] • ⾃律性 • 系](https://files.speakerdeck.com/presentations/dfa84e31657a4629bb35e266796637ef/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
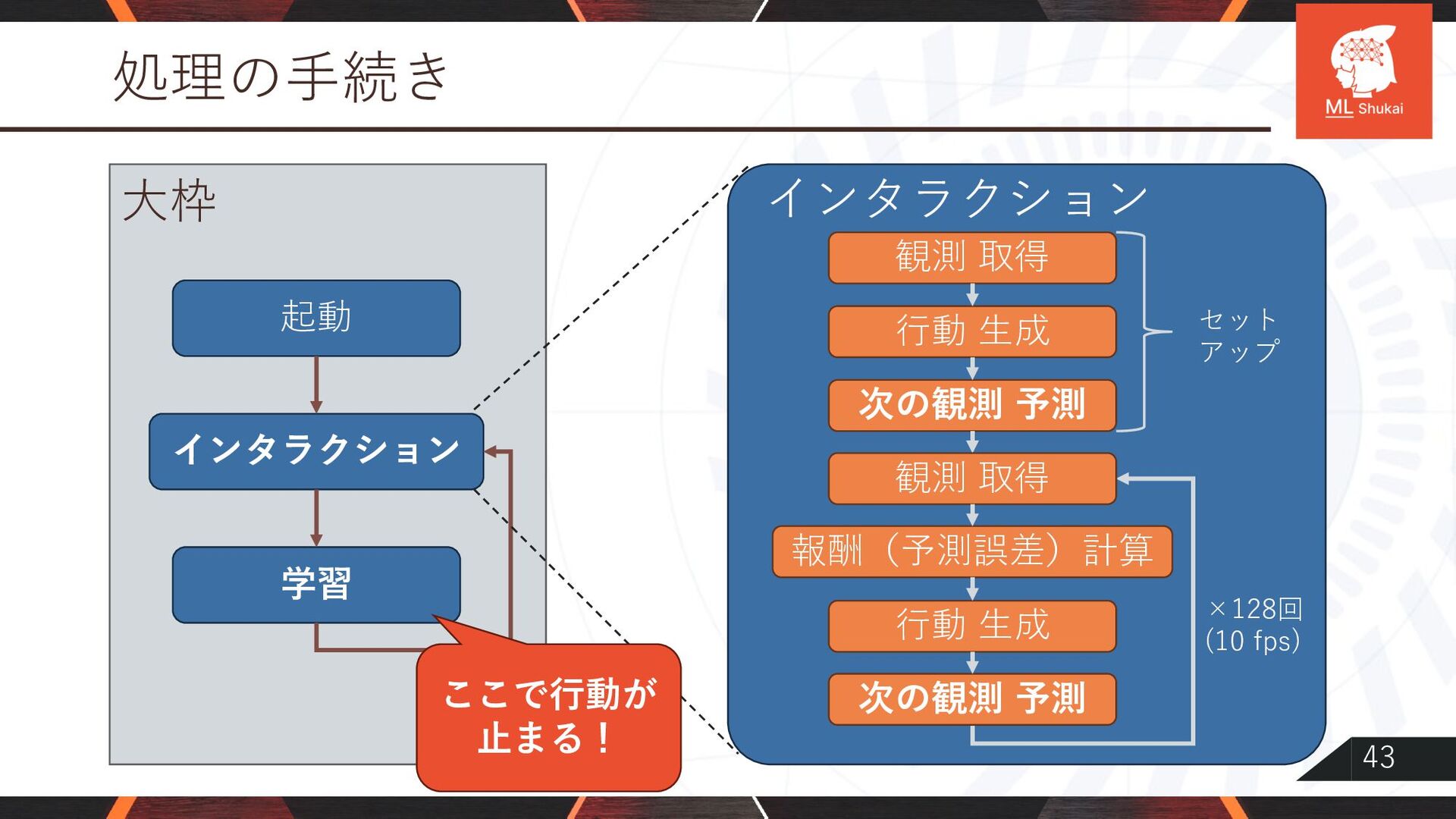{kind=link}
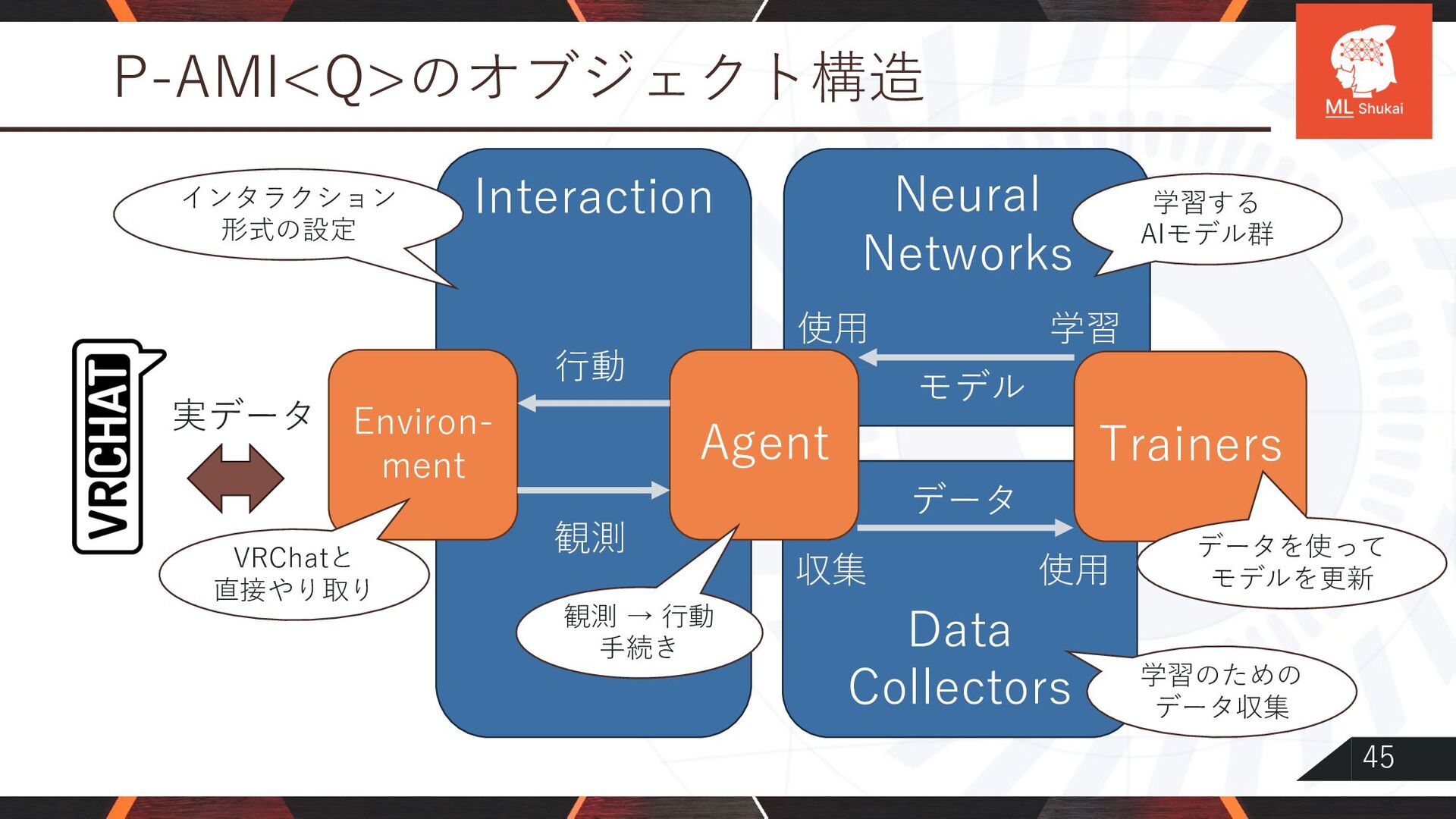
{kind=link}
{kind=link}
{kind=link}
{kind=link}
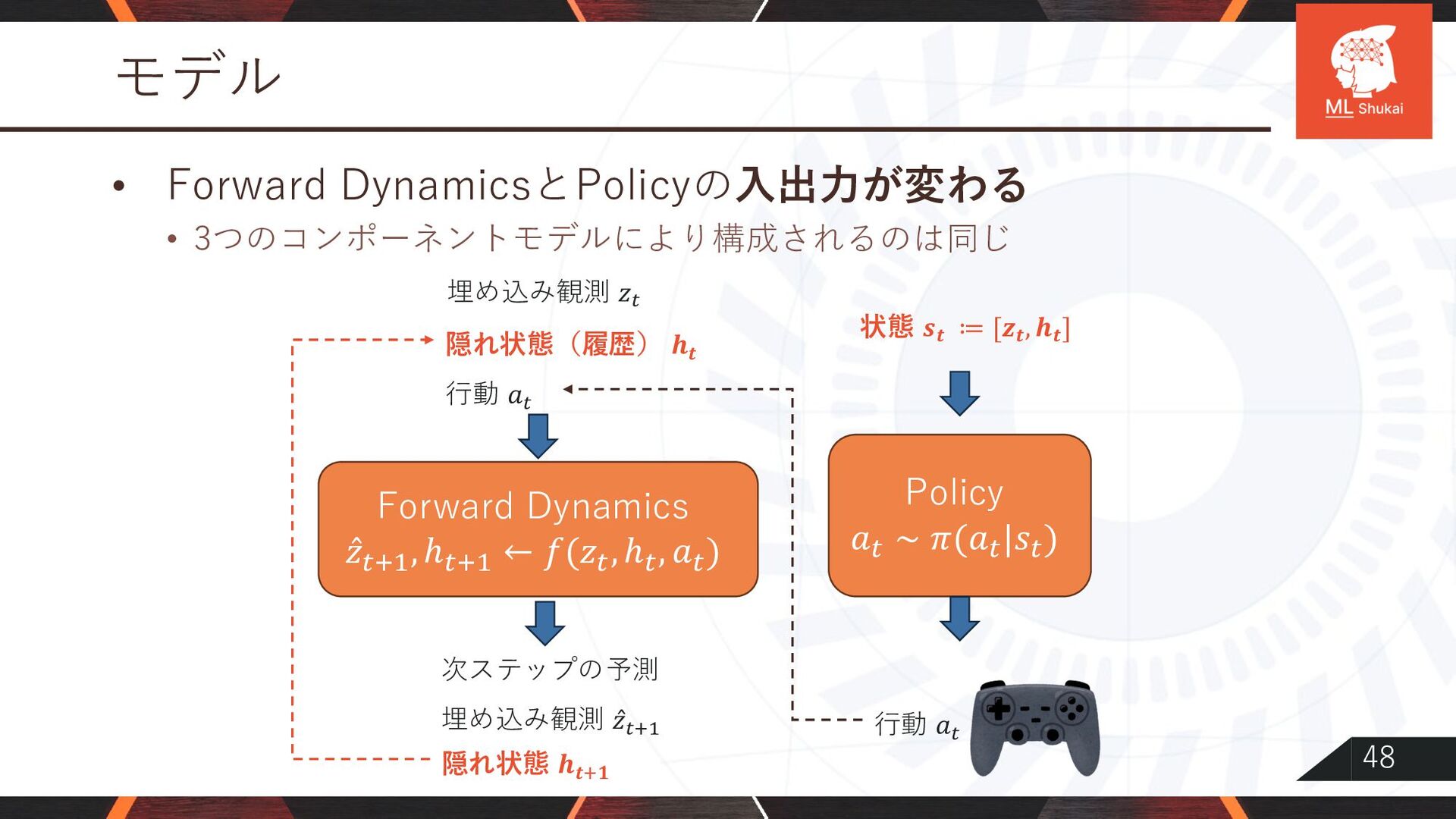{kind=link}
{kind=link}
![50 Observation Encoder • Variational Auto Encoder (VAE) [D.P.Kingma+, 2013]](https://files.speakerdeck.com/presentations/dfa84e31657a4629bb35e266796637ef/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
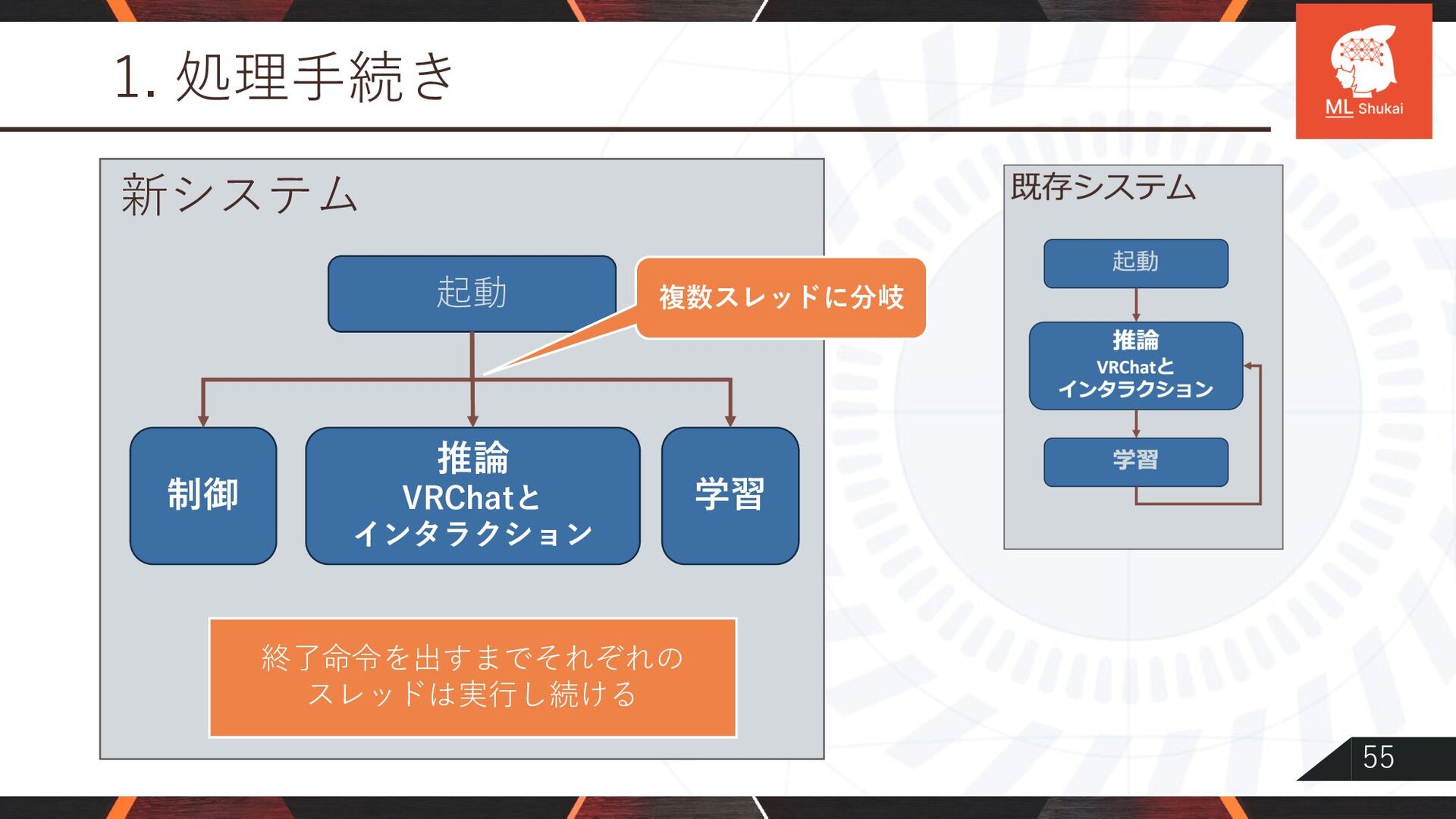{kind=link}
{kind=link}
{kind=link}
{kind=link}
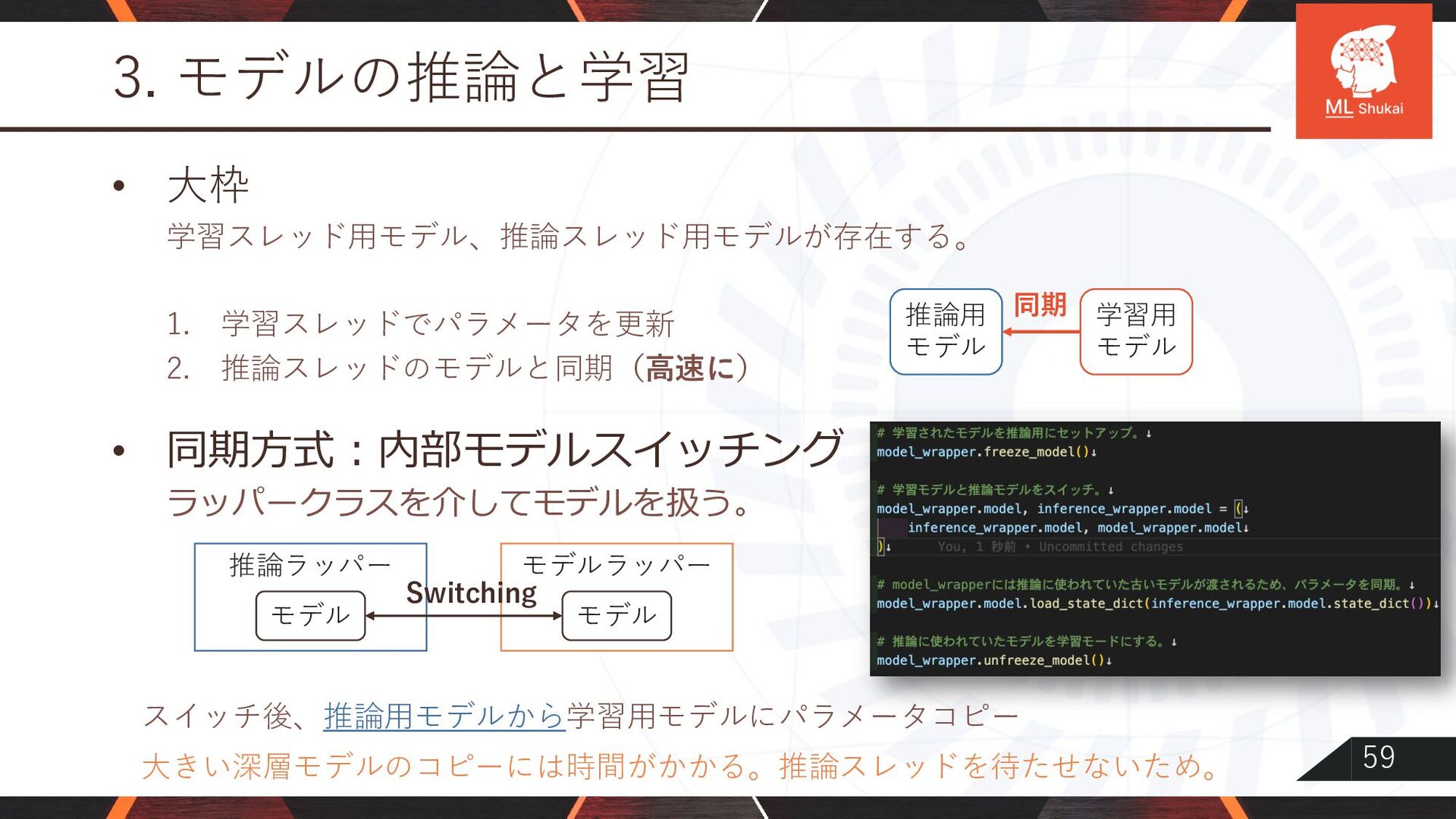{kind=link}
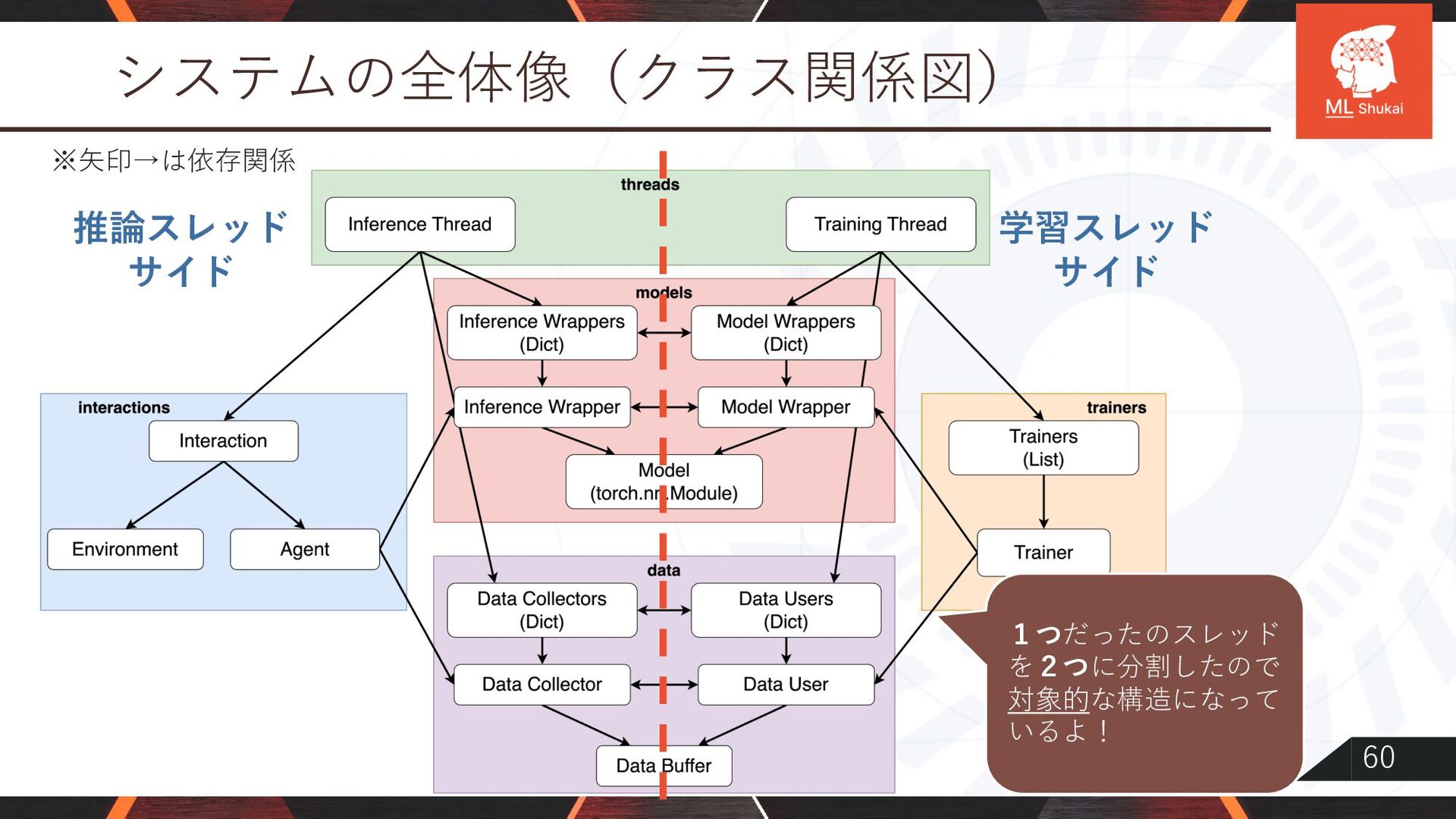{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}