Presented at Hadoop Summit San Jose 2013
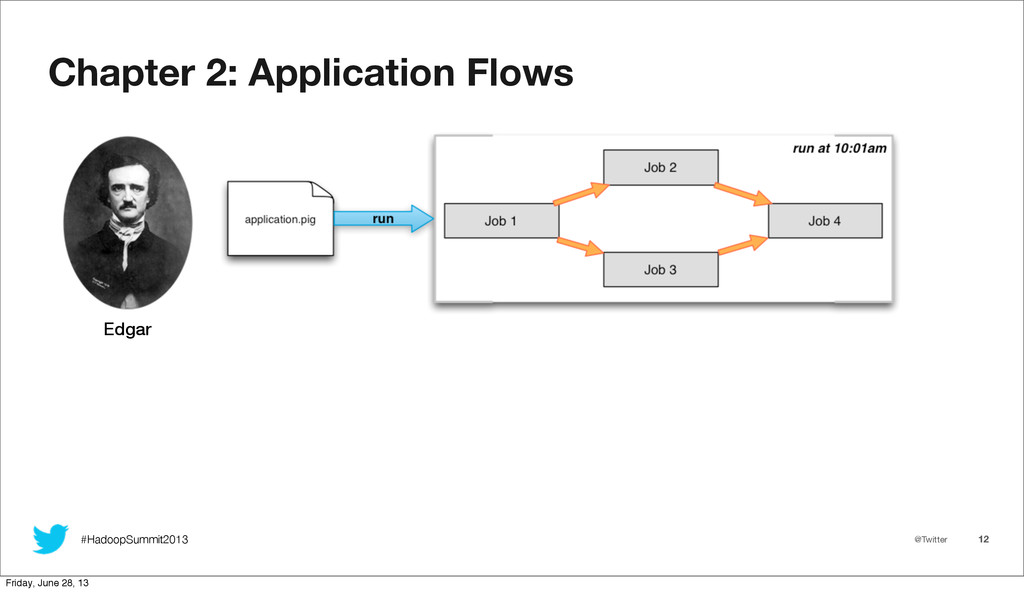
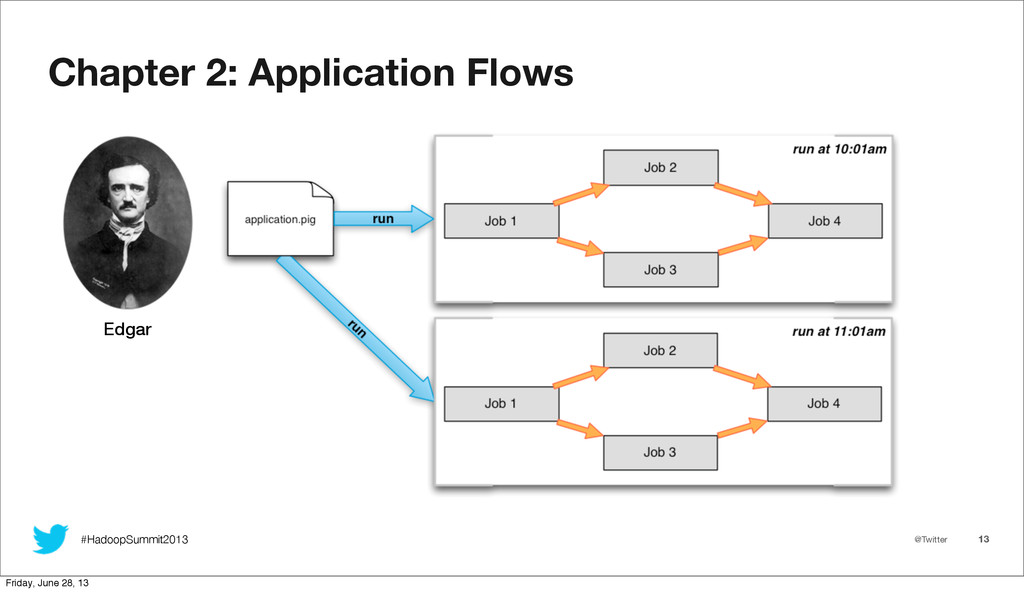
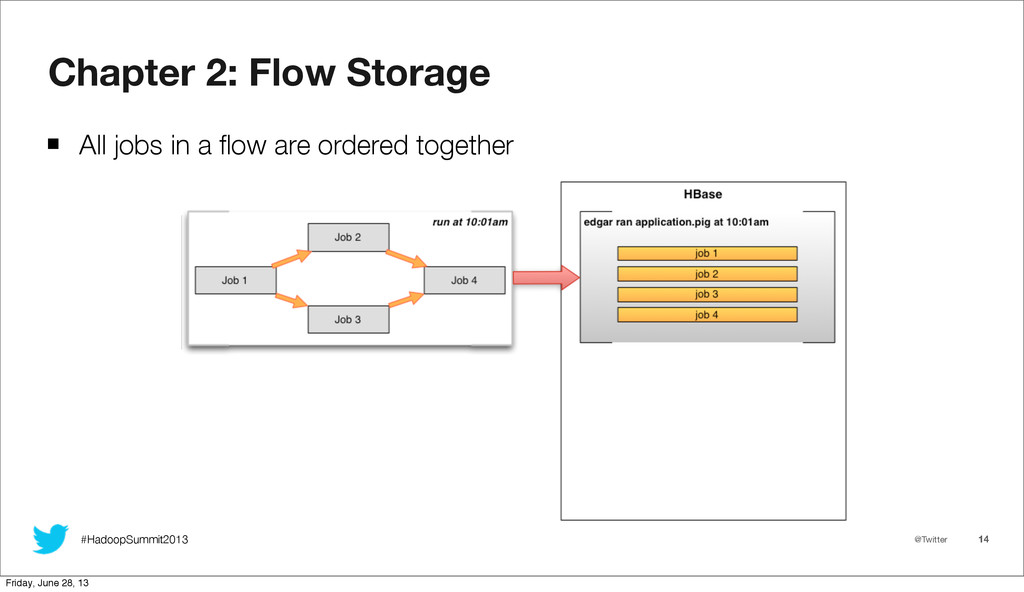
As Twitter's use of mapreduce rapidly expands, tracking usage on our clusters grows correspondingly more difficult. With an ever increasing job load, and a reliance on higher level abstractions such as Pig and Scalding, the utility of existing tools for viewing job history decreases rapidly, and extracting insights becomes a challenge. At Twitter, we created hRaven to fill this gap. hRaven archives the full history and metrics from all mapreduce jobs on our clusters, and strings together each job from a Pig or Scalding script execution into a combined flow. From this archive, we can easily derive aggregate resource utilization by user, pool, or application. While the historical trending of an individual application allows us to perform runtime optimization of resource scheduling. We will cover how hRaven provides a rich historical archive of mapreduce job execution, and how the data is structured into higher level flows representing the job sequence for frameworks such as Pig, Scalding, and Hive. We will then explore how we mine hRaven data to account for Hadoop resource utilization, to optimize runtime scheduling, and to identify common anti-patterns in user jobs. Finally, we will look at the end user experience, including Ambrose integration for flow visualization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}