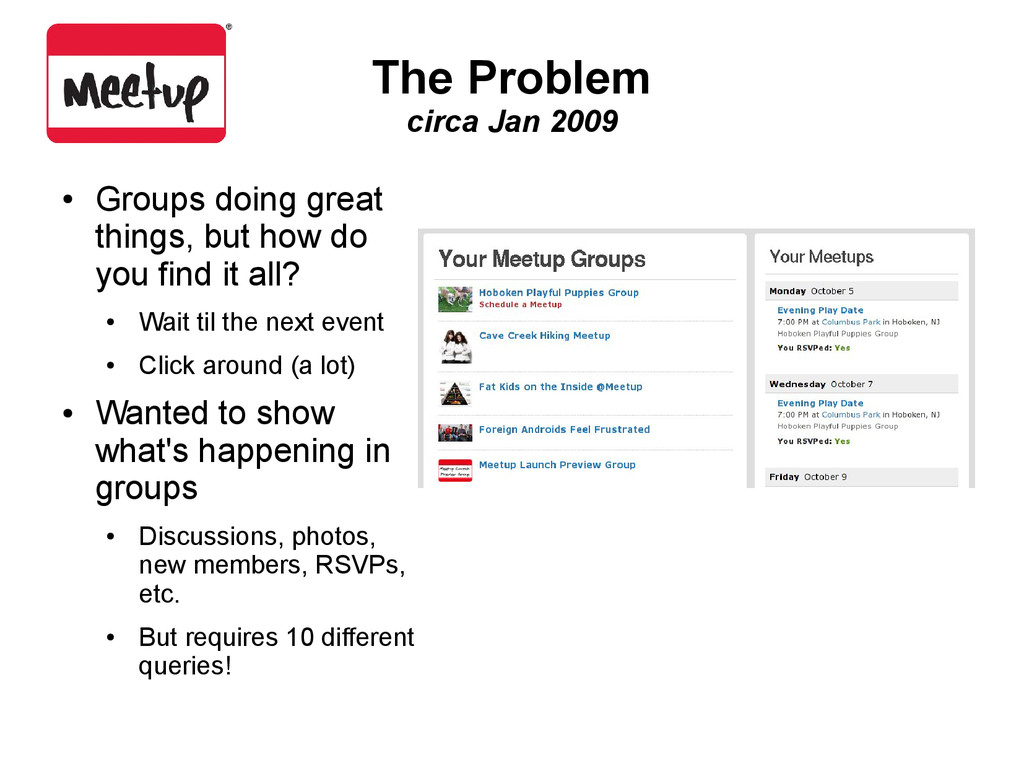
but how do you find it all? • Wait til the next event • Click around (a lot) • Wanted to show what's happening in groups • Discussions, photos, new members, RSVPs, etc. • But requires 10 different queries!
querying a separate table – already wasn't scaling at the group level • Query efficiency • Activity occurs at group level • Members can be in hundreds of groups • For member home page we need activity from all groups ordered by most recent – N subqueries by group ID merged back by descending timestamp
a common table (with different fields for different types of activity) • Duplicate entity data (or we're still doing N queries) • Start to lose a lot of the benefits of RDBMS • Query efficiency still a problem • Single system scaling limit • Something new • the Cloud – Google App Engine – Amazon SimpleDB • Hadoop/HBase • CouchDB • MongoDB • Voldemort • Cassandra
Data model • Semi-structured data in HBase (easily handles multiple types in same table) • Time-series ordered • Scaling is built in (just add more servers) • But extra indexing is DIY • Very active developer community • Established, mature project (in relative terms!) • Matches our own toolset (java/linux based)
(automatic partitioning) • Column-oriented • Semi-structured (columns can be added just by inserting) • Built-in versioning • Not an RDBMS • No joins • No SQL • Data usually not normalized • Transactions & built-in secondary indexes available (as contrib) but immature • Need to think differently about how you structure data • Denormalize your data where necessary • Structure data & row keys around common access
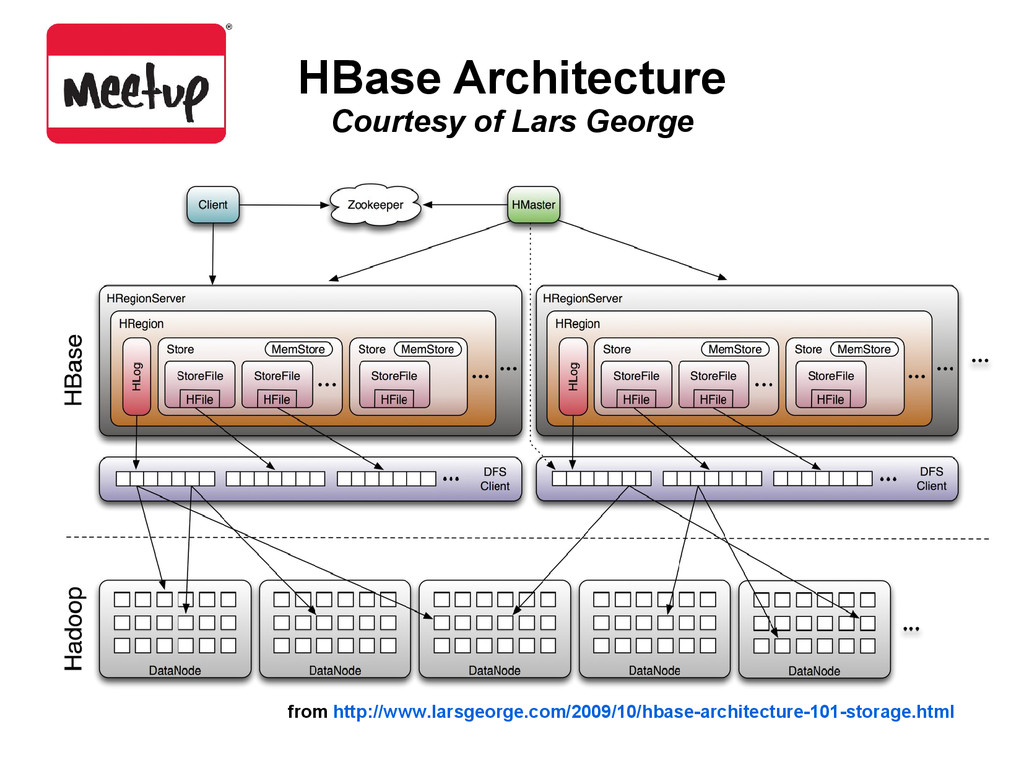
by row [start key, end key) – Store, 1 per family • 1+ Store Files (Hfile format on HDFS) • (table, rowkey, family, column, timestamp) = value • Everything is byte[] • Rows are ordered sequentially by key • Special tables: -ROOT-, .META. • Tell clients where to find user data
by rowkey only • Sequential reads (Scans) • starting row key • where you stop is as important as where you start – ending row key (optional) – server-side filter (optional) • Writes (Puts) • No insert vs. update distinction
stores activity data for all types • keyed by group and descending timestamp – ch<chapterID>-ts<Long.MAX_VALUE–timestamp>-<type>-<entityID> • each row only contains data for that type Row Key info: content: ch1261585-ts9223... item_type = chapter_greeting target_greeting = 8104438 greeting = “Hi, Gary” ch1261585-ts9223... item_type = new_discussion target_forum = 847743 target_thread = 7369603 title = “Improvements” body = “When a discussion is created...” • MemberFeedIndex: index of FeedItem rows from all of a member's groups • one row per member (keyed by member ID) • columns store refs to FeedItem row keys for that member's groups • TTL of 2 months expires old index values Row Key item: 4679998 ch176399-ts9223370788400750807-mem-10044424 = new_member ch1261585-ts9223370787431124807-ptag-8525047 = photo_tag ...
page feed • lookup member record in MemberFeedIndex by ID • grab the X most recent columns & values – use a time range for paging (older pages start with an earlier start time) • get each row from FeedItem using (column key as row key) – N gets, where N is number of items to display • populate some basic info about members and aggregate the results – still query MySQL for core entity info (member, group, event)
find rows by column values • tried “tableindexed” contrib (0.19 release), high CPU usage & contention on scans • decided to update to 0.20 release for other performance improvements • built secondary indexing into app layer • Separate table per indexed column • FeedItem info:actor_member indexed by FeedItem-by_actor_member • Index table rows keyed by column value and descending timestamp – <column value>-<Long.MAX_VALUE–timestamp>-<orig row key> • Zero pad numeric values (or big-endian representation) for correct byte ordering
on annotations public class EntityService<T> { public T get(String rowKey) throws HBaseException {…} public void save(T entity) throws HBaseException {…} public void saveAll(List<T> entities) throws HBaseException {…} public void delete(String rowKey) throws HBaseException {…} public Query<T> query() throws MappingException {…} } easily extended for specific needs Almost all HBase interaction through service instances.
discussion FeedItemService service = new FeedItemService(DiscussionItem.class); Query query = service.query() .using( Criteria.eq("threadId", threadId) ); List items = query.execute(); Find all greetings from a given member FeedItemService service = new FeedItemService(GreetingItem.class); Query query = service.query() .using( Criteria.eq("memberId", memberId) ) .where( Criteria.eq(“type”, FeedItem.ItemType.CHAPTER_GREETING) ); List items = query.execute(); Simple Query API uses mappings and secondary index tables
index record HTable mfiTable = HUtil.getTable("MemberFeedIndex"); Get get = new Get( Bytes.toBytes(String.valueOf(memberId)) ); get.addFamily( Bytes.toBytes("item") ); Result r = mfiTable.get(get); FeedItemService service = new FeedItemService(); Set<IndexKey> sortedKeys = sortKeys(r); List<FeedItem> items = new ArrayList<FeedItem>(); // for each index col get the entity record for (IndexKey key : sortedKeys) { FeedItem item = service.get(key.getKey()); if (item != null) items.add(item); } // populate member and chapter info … Get latest activity from all a member's groups using MemberFeedIndex
• Product targeting 3 of our highest traffic pages, simulating load is hard • Started with load scripts • Moved to testing with live traffic – Use AJAX calls to simulate requests – Selective enable for X% of traffic • Launched data collection/write traffic first – Allowed tweaking configuration before impacting user experience
/ Concurrency issues • Updated to 0.20 release for performance gains across the board • Replaced “tableindexed” usage with application level secondary indexing • “Hot regions” - profile page hits small table every page load • Force split table to distribute across multiple servers • “Newest” region still handling high load – changed index keying to <value % 100>-<value>-<timestamp> for even distribution • I/O Heavy load / MemberFeedIndex table growing • Lowered MemberFeedIndex time-to-live to 2 months • Enabled LZO compression
Cluster handling ~2.5k – 3k request/sec • 50+% still write traffic • ~17% of page views hit HBase (for reads) • Expanding to 30% of page views in coming months • Meetup.Beeno now open-source on Github: • http://github.com/ghelmling/meetup.beeno • Next up • Continue tweaking • Site analytics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}