Apresentação do artigo "A Modularity Maximization Algorithm for Community Detection in Social Networks with Low Time Complexity " para o seminário da disciplina de Tópicos Avançados em Inteligência Artificial - CIn / UFPE.
Autores do artigo:
Mohsen Arab - Department of Computer Science IASBS Zanjan, Iran
Mohsen Afsharchi - Department of Computer Engineering University of Zanjan Zanjan, Iran
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
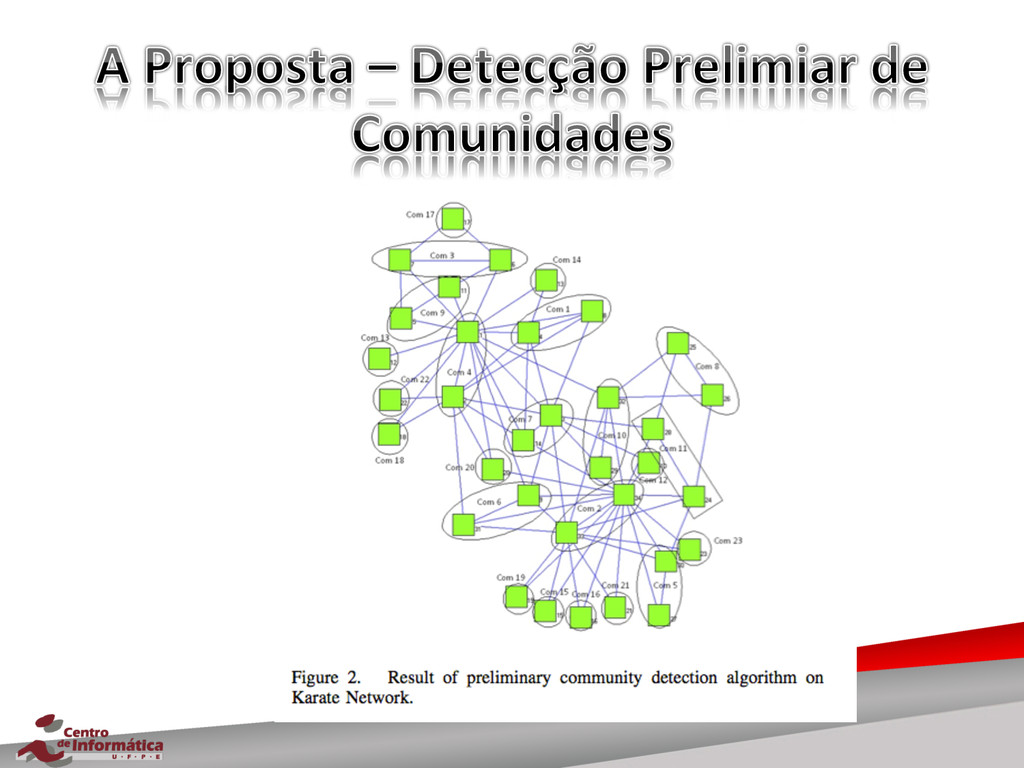{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
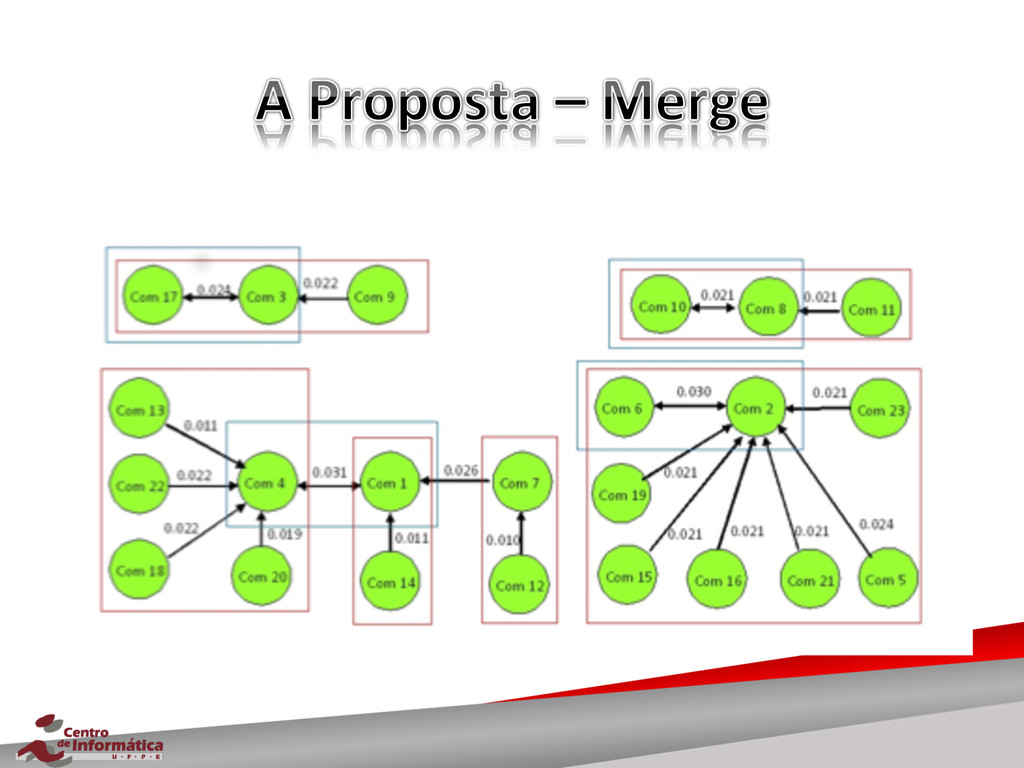{kind=link}
{kind=link}
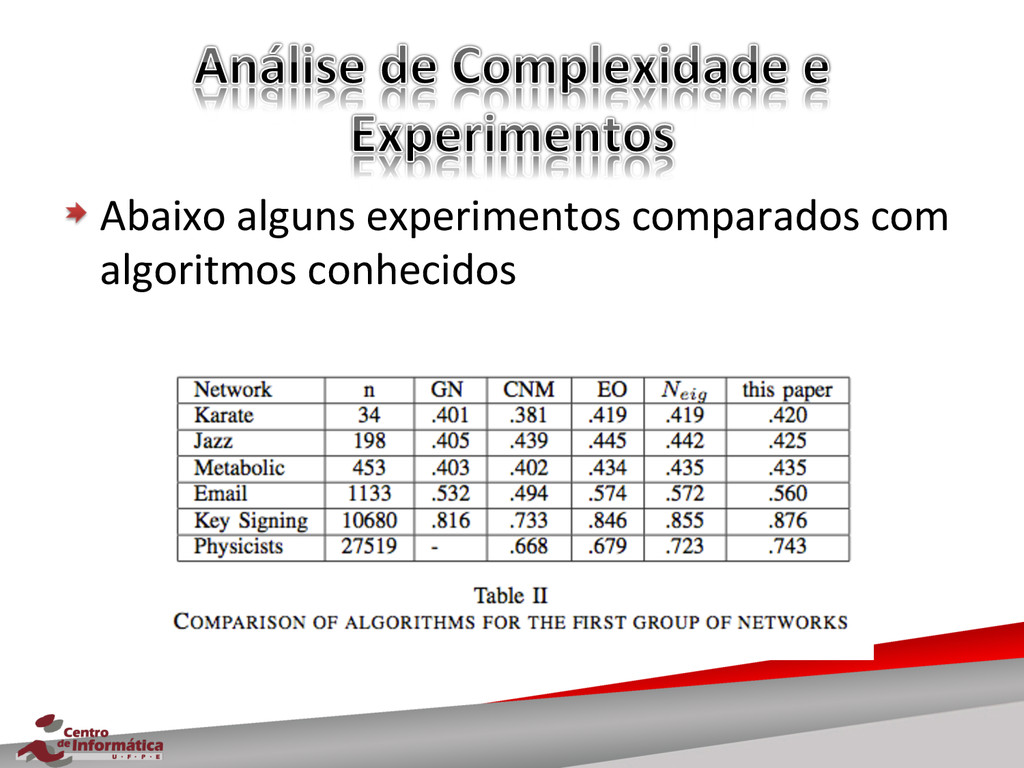{kind=link}
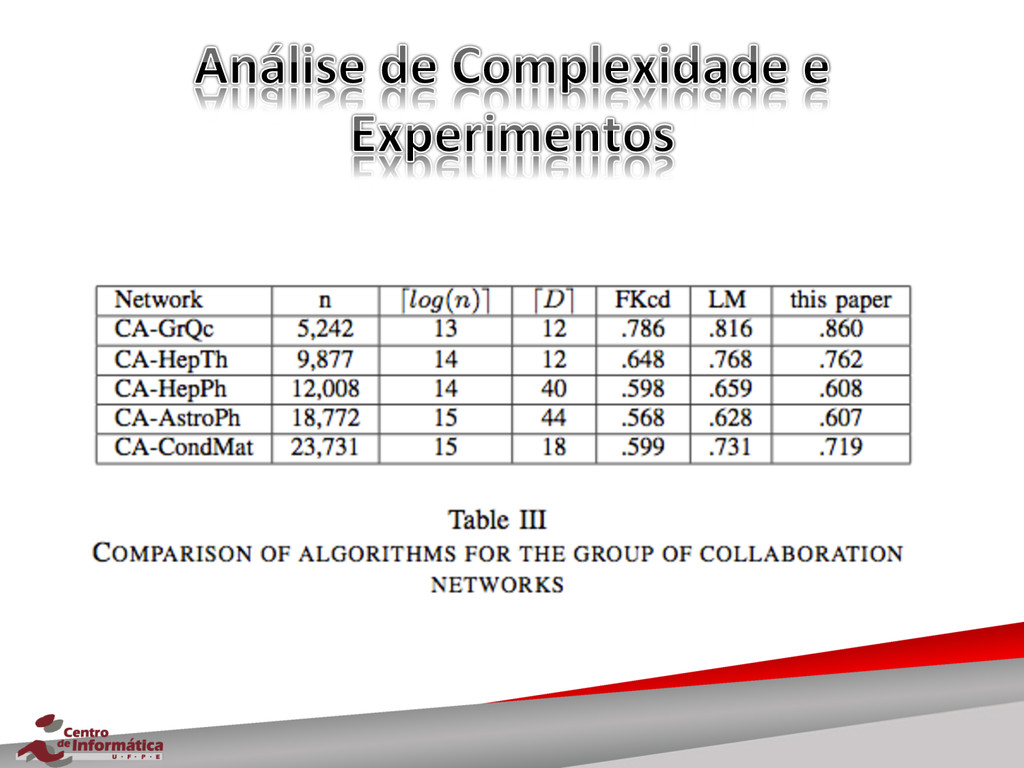{kind=link}
{kind=link}