Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
JOAI2026 講評
Search
pao
April 15, 2026
400
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
JOAI2026 講評
第2回日本人工知能オリンピック講評会 & 日本代表解法紹介 にて発表したJOAI2026の講評資料です。
pao
April 15, 2026
More Decks by pao
See All by pao
いろんなものと両立する Kaggleの向き合い方
go5paopao
3
2.6k
データサイエンティストとは何か論争にAI(gpt-2)で終止符を打とうとした話
go5paopao
0
260
短期間コンペの戦い方
go5paopao
13
14k
atmaCup#9 1st place solution
go5paopao
6
3.8k
DSB2019 10th Solutionの一部とShakeについて
go5paopao
2
810
Kaggle Malware competition 2th→1485th solution
go5paopao
2
9.8k
Featured
See All Featured
Designing for Performance
lara
611
70k
Scaling GitHub
holman
464
140k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Prompt Engineering for Job Search
mfonobong
0
380
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
The browser strikes back
jonoalderson
0
1.4k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Bash Introduction
62gerente
615
220k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Transcript
第2回日本人工知能オリンピック JOAI2026 講評
JOAI2026講評 ⿇雀AI開発をきっかけに機械学習の道へ。前職では 画像認識アプリやユーザプロファイリングに従事。 2020年にABEJA⼊社後、データサイエンティスト として多様なプロジェクト‧データサイエンス組織 のマネジメントをした後に、専⾨職として2024年 にプリンシパルデータサイエンティストに就任。 Kaggle Competitions Grandmaster。Kaggle
Days World ChampionshipやatmaCupをはじめとした国 内コンペで複数回優勝経験あり。 ⾃⼰紹介 JOAI委員会理事 服部 響
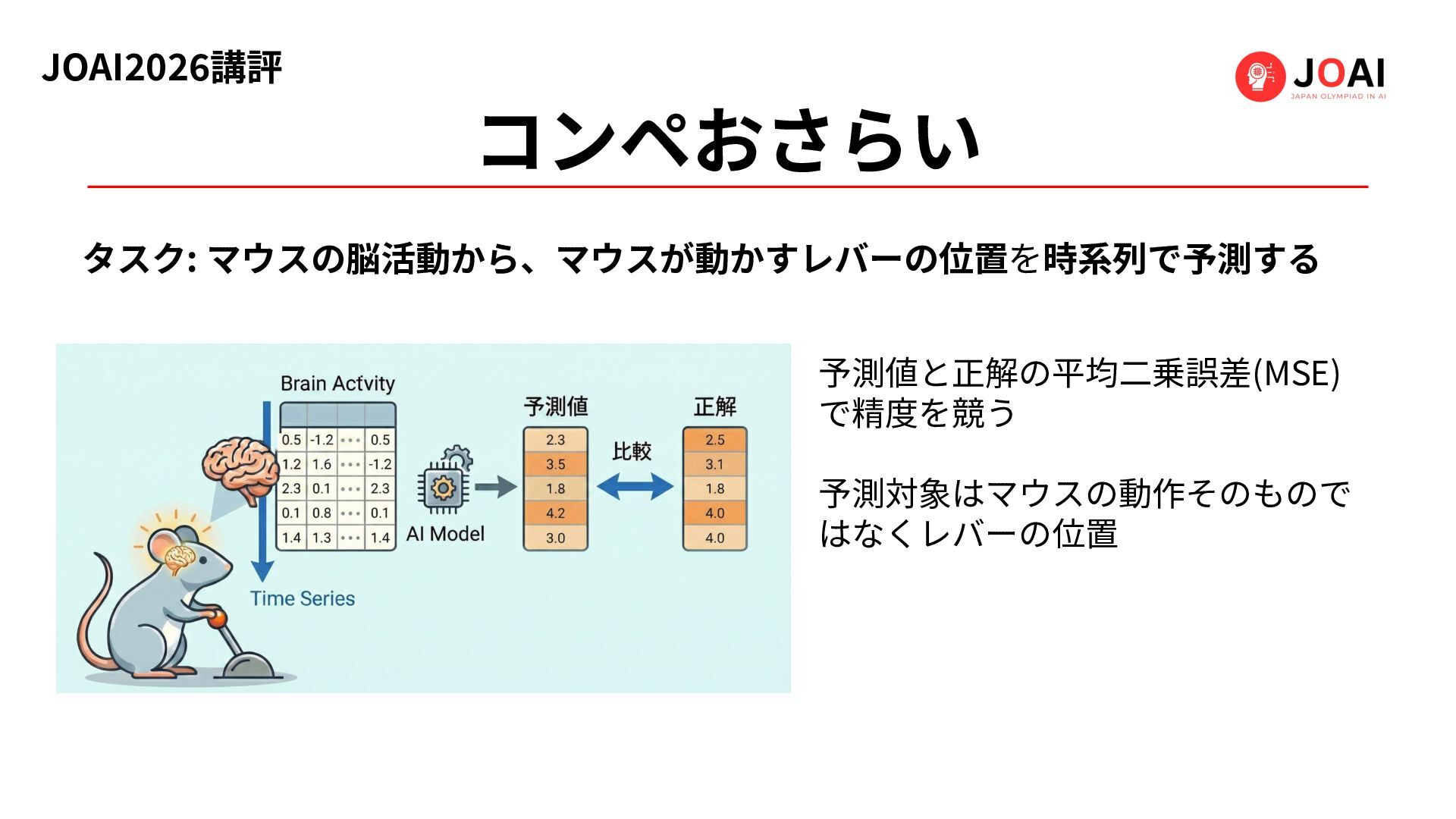
JOAI2026講評 コンペおさらい タスク: マウスの脳活動から、マウスが動かすレバーの位置を時系列で予測する 予測値と正解の平均⼆乗誤差(MSE) で精度を競う 予測対象はマウスの動作そのもので はなくレバーの位置
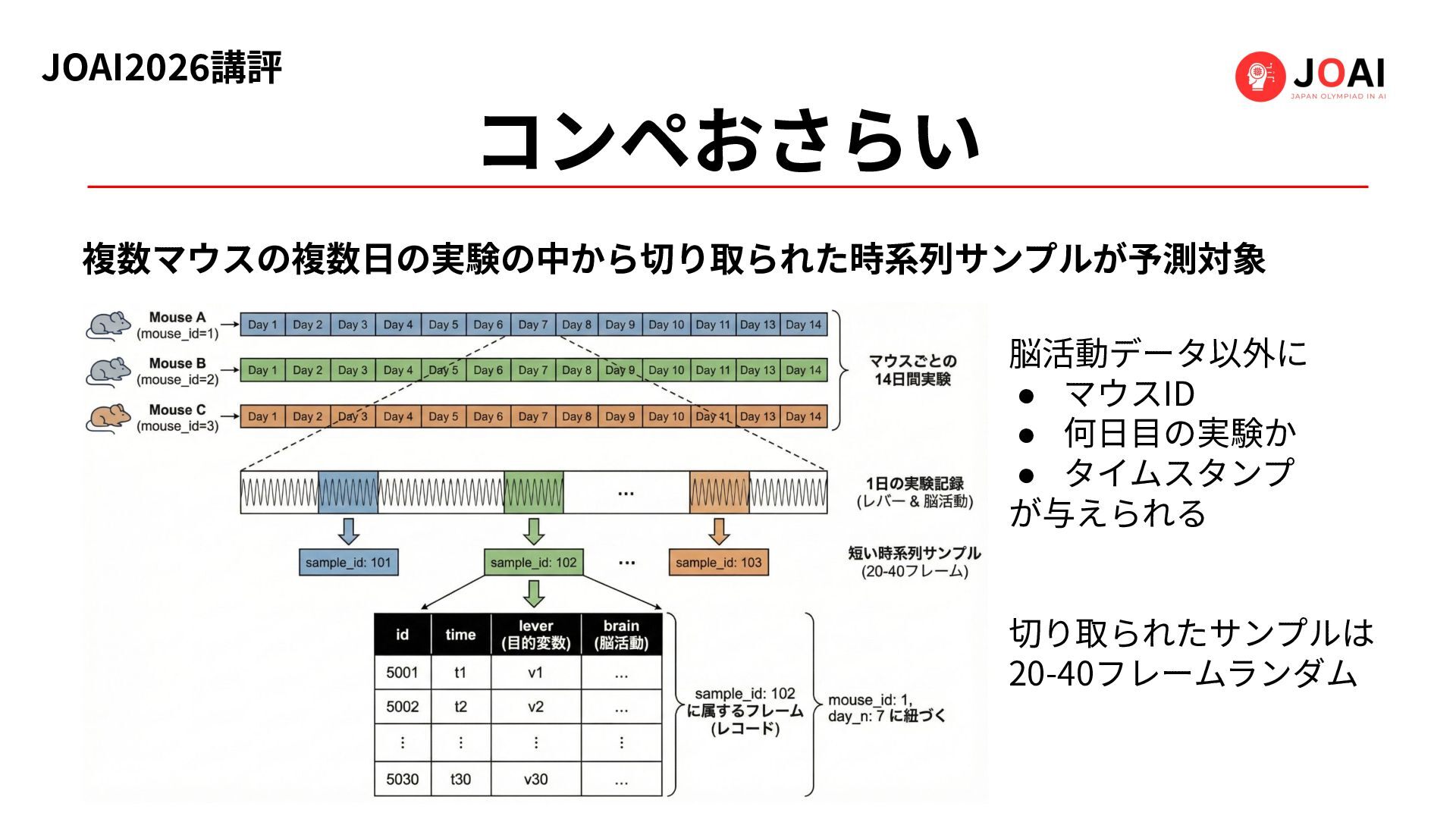
コンペおさらい 複数マウスの複数⽇の実験の中から切り取られた時系列サンプルが予測対象 脳活動データ以外に • マウスID • 何⽇⽬の実験か • タイムスタンプ が与えられる
切り取られたサンプルは 20-40フレームランダム JOAI2026講評
コンペおさらい 脳活動: 広域カルシウムイメージング 脳の左右それぞれ 対称的な22の領域の活動数値 データ(合計44個)が特徴量 後半でこちらのデータセット構築の論⽂を 発表された中江先⽣からの講評もあります!! JOAI2026講評
コンペおさらい • 脳活動を元にした時系列データ • 予測対象は動きそのものではなく、動かす対象(レバー)の位置 • 脳活動は広域カルシウムイメージングという⼿法 • 回帰問題 •
マウスや⽇付の情報がある • 切り取られた系列データの⻑さは20-40でランダム JOAI2026講評
時系列データの重要性 機械学習/AIの領域では時系列データ(及び系列データ)は頻出 • 需要予測 • 動画解析 • レコメンド(購⼊履歴など) • Physical
AI / ロボティクス領域 • 化学系(アミノ酸配列など) • ⾃然⾔語処理(LLMなど) などなど 今後の応⽤も効くものでありJOAIでも早めにやりたかった JOAI2026講評
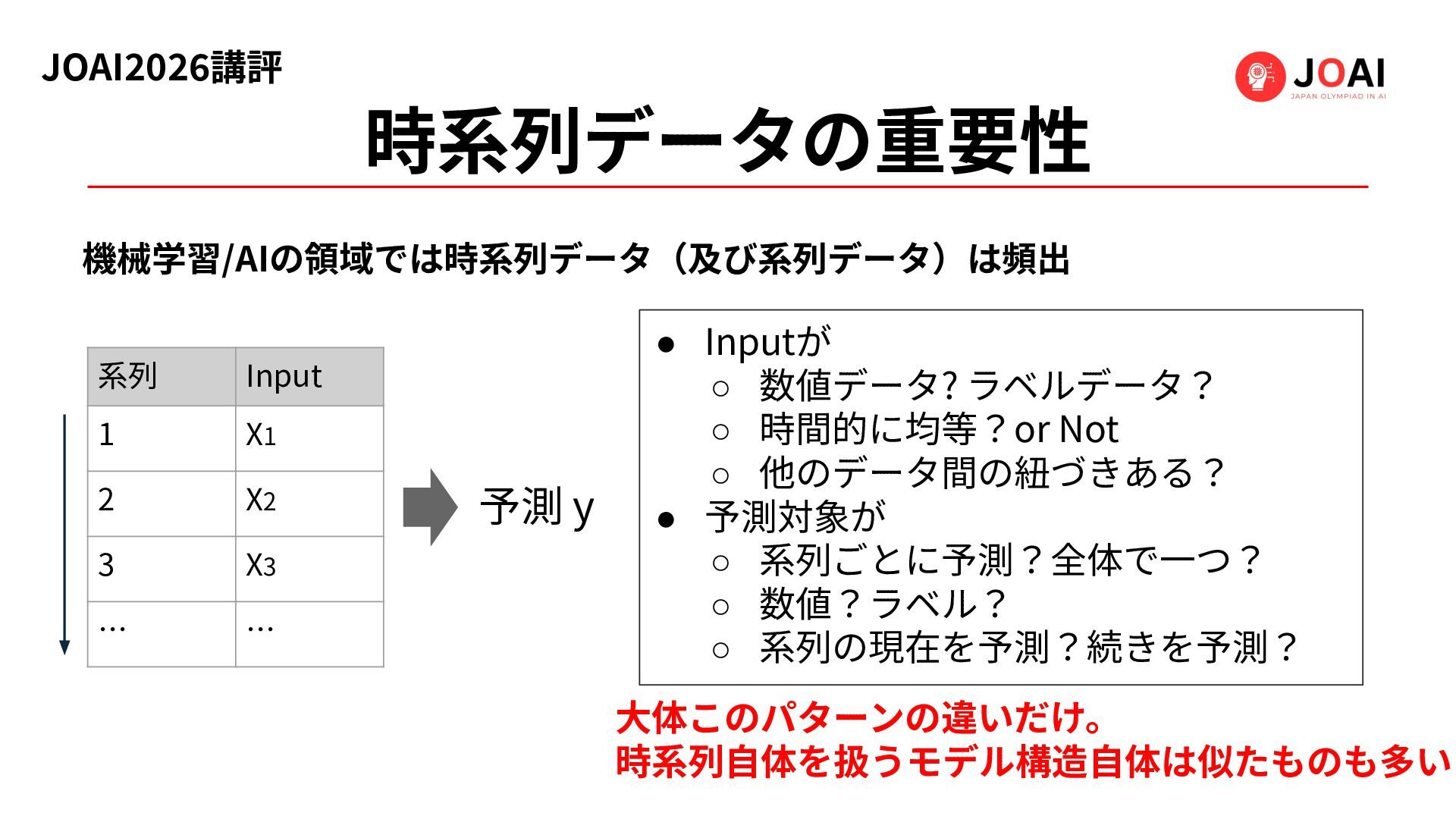
時系列データの重要性 機械学習/AIの領域では時系列データ(及び系列データ)は頻出 系列 Input 1 X1 2 X2 3 X3
… … 予測 y • Inputが ◦ 数値データ? ラベルデータ? ◦ 時間的に均等?or Not ◦ 他のデータ間の紐づきある? • 予測対象が ◦ 系列ごとに予測?全体で⼀つ? ◦ 数値?ラベル? ◦ 系列の現在を予測?続きを予測? ⼤体このパターンの違いだけ。 時系列⾃体を扱うモデル構造⾃体は似たものも多い JOAI2026講評
時系列データの重要性 機械学習/AIの領域では時系列データ(及び系列データ)は頻出 • Inputが ◦ 数値データ? ラベルデータ? →数値データ ◦ 時間的に均等?or
Not →均等 ◦ 他のデータ間の紐づきある? →マウスや⽇付で紐づく • 予測対象が ◦ 系列ごとに予測?全体で⼀つ? →系列ごとに予測 ◦ 数値?ラベル? →数値予測 ◦ 系列の現在を予測?続きを予測?→現在を予測 それぞれが違うパターンだとどうなるか?そこを考えるだけでも応⽤が効く JOAI2026講評
コンペでの狙い • データの件数について ➢ サンプルID単位でも学習できる程度の件数かつ、全体としても必要な 計算資源(GPU)が抑えられるように調整。(Public/Privateの順位が変 動も考慮) ➢ サンプル⻑が固定だと時系列以外の解き⽅にもなるためランダムに •
モデル周りの狙い ➢ 件数的に、勾配ブースティングと様々な深層学習モデル(GRU, LSTM, CNN, Transformer等)を試す価値のあるものにしたかった ➢ アンサンブルや複数アーキテクチャの組み合わせにも意味を持たせた かった JOAI2026講評
コンペでの狙い • Train/TestのSplitについて ➢ 期間を考えてあえてシンプルに、mouse_id/⽇付含めランダムにSplit ➢ 後半の⽇付をtest、mouse_idでtrain/testに分割などをするとより難 易度が上がる • ⽬的変数の設定
➢ データ上はマウス実験の様々なデータがあったが、シンプルにレバー の位置とした ➢ ここを複雑にすると論⽂読解の必要性などハードルが上がってしまう ➢ 脳活動はマウスの動きと連動するものなのに対して、レバーは動きそ のものではなく外部環境の状態。ここに⼯夫の余地を残した JOAI2026講評
コンペでの狙い • mouse_id/day_nの付与 ➢ マウス毎の脳活動の特徴や、⽇付間での変化などが考えられる。 ➢ それらを、どう予測に組み込むか? ➢ 単純なモデリングではなくデータの傾向に合わせた対策を必要とした •
脳活動データ(ここは結果論) ➢ メジャーな脳波計測の⼿法だと、専⽤の事前学習モデルや解析⼿法が 確⽴していて調査⼒勝負になってしまう ➢ 今回のデータだと、未知のデータでの分析を扱う経験になる JOAI2026講評
上位解法の傾向(全体傾向) • ニューラルネットワーク中⼼の時系列対応モデル ➢ 双⽅向GRU/LSTMやTCNなどが多かった ➢ Transformerは少なめ • 時間の差分特徴量 •
脳の左右対称領域に関する特徴量 • マウス個体差の吸収(Embedding, 正規化) • 多様なモデルのアンサンブル / スタッキング ➢ モデルの条件を⼀部変更しながら多様性を確保 ➢ アンサンブルにはLightGBMなど決定⽊系モデルも JOAI2026講評
ポイント:モデル • 今回はBiGRU/BiLSTMやTCNなどが強かった。 • モデル⾃体は新しいものでもなく、数年前から変わっていないものが多い • データ毎の特徴‧件数にかなり依存する ➢ 類似の時系列コンペでも強いモデルは毎回変わっている •
上位陣は多様なモデルを試して強いモデルにたどり着いている • 過去のKaggleコンペなども参考になる データからどんなモデル‧アーキテクチャがあり得るのか? を洗い出して⾊々試してみることが⼤事 JOAI2026講評
ポイント:時系列での差分 • 予測対象はレバーの位置 → マウスがレバーを動かす⾏動をすると変化する • 脳活動の特徴量⾃体の絶対値よりも相対値(変化)が⼤事ではないか? ➢ 活動量が増えて動作が⾏われる /
動作をした結果活動量が増える • さらに、マウスの動作に直接連動するのはレバーの位置そのものではなく、 レバーの位置変化ではないか? ➢ ✕: 脳活動が活発→レバーの位置が⼩さい ➢ ◯: 脳活動が活発→レバーの位置変化がありそう 変化量(系列での差分)を特徴量にしたり、 レバーの変化量⾃体を予測することが効くのではないか?という仮説が⽴てられる JOAI2026講評
まとめ・感想 • JOAI2026は時系列データとして王道な側⾯もありつつ、⼀部⼯夫余 地のあるコンペ • コンペ設計の狙いもいくつか公開 • 上位の全体的な傾向もまとめ ➢ 詳細は個別の解法紹介をお楽しみに
感想 • AIコーディングの進化により実装速度が全体的に⾼く感じた • にしても1週間ちょっとの短い期間でスコアが伸びすぎて驚いた • 今後もAI/機械学習を学ぶきっかけになったり、参考になると嬉しい JOAI2026講評
第2回日本人工知能オリンピック JOAI2026 講評
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}