As more and more businesses need to process data from diverse sources to eventually support decision making, designing data-driven applications has become increasingly important. This talk gives an overview of how to build data flow solutions using Golang. The first part covers conceptual building blocks of a lean data architecture and highlights basic techniques for processing data. We'll then show the evolution of a data pipeline starting by connecting simple CLI tools, move to generators with goroutines and channels, and close with more advanced examples leveraging stream processing tooling.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
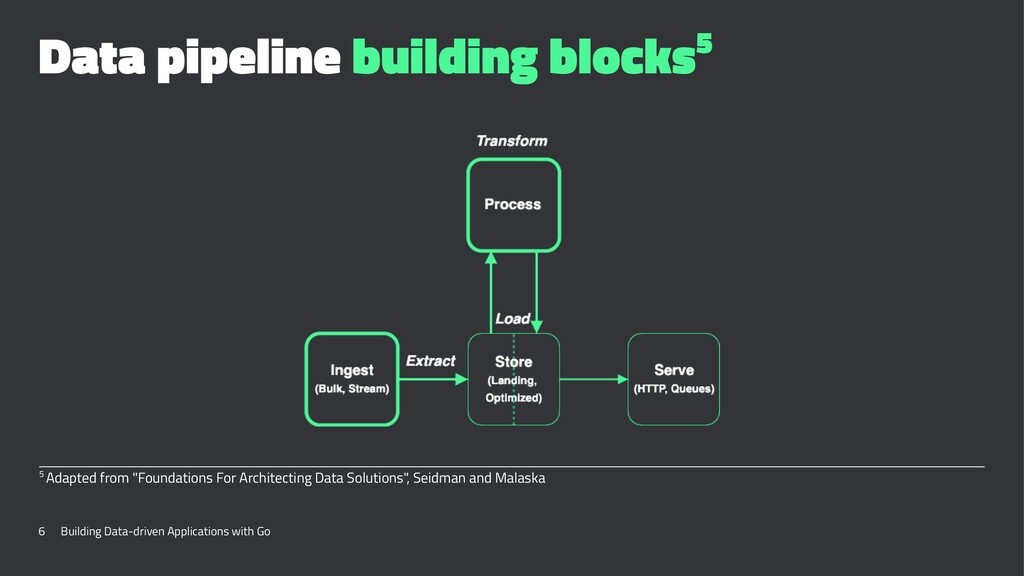{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
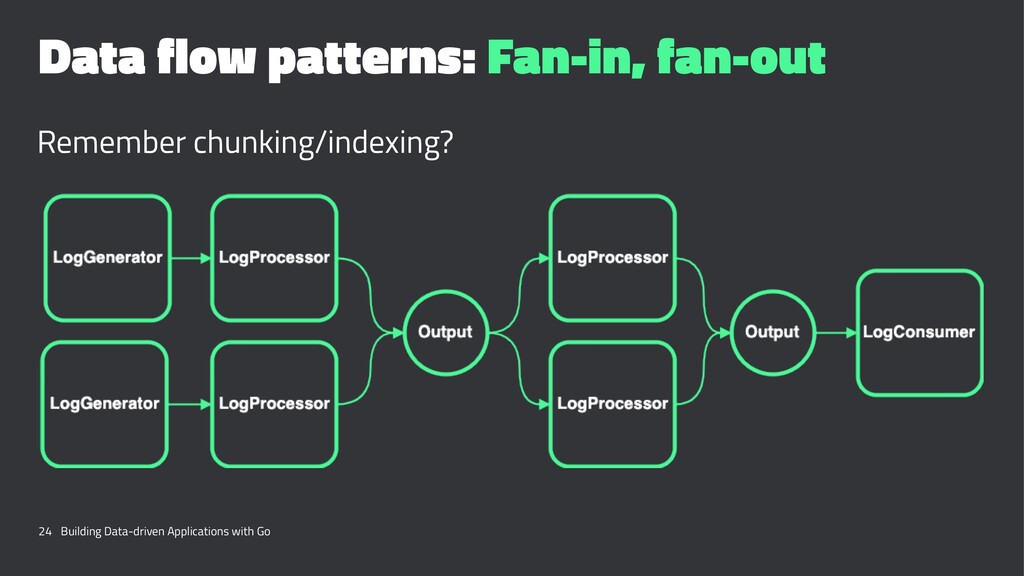{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
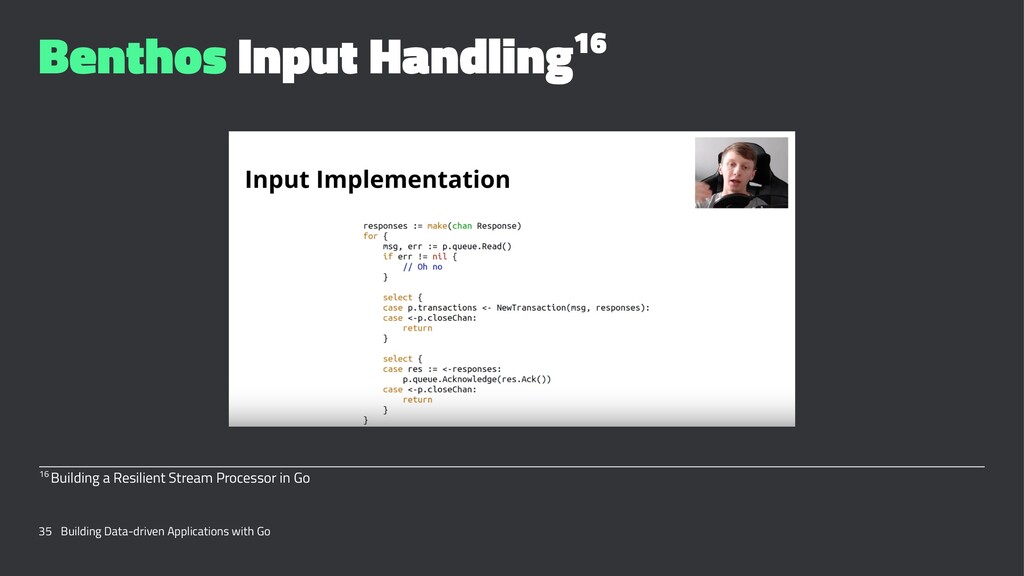{kind=link}
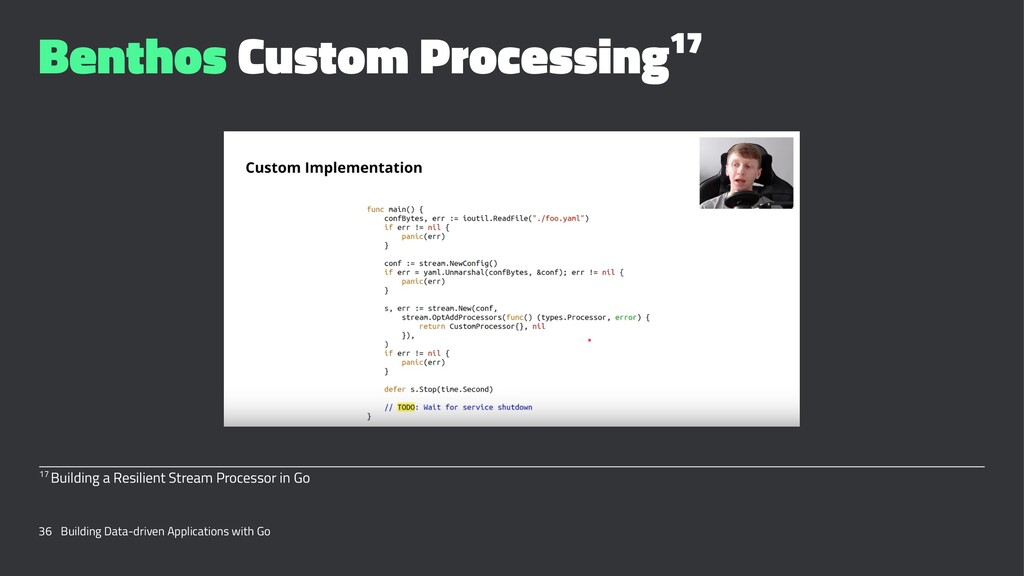{kind=link}
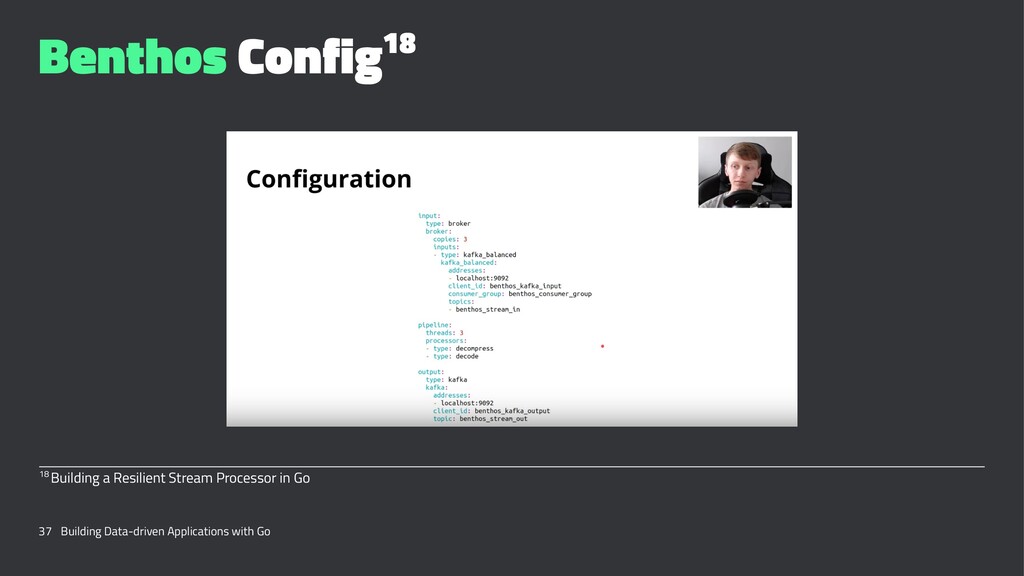{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}