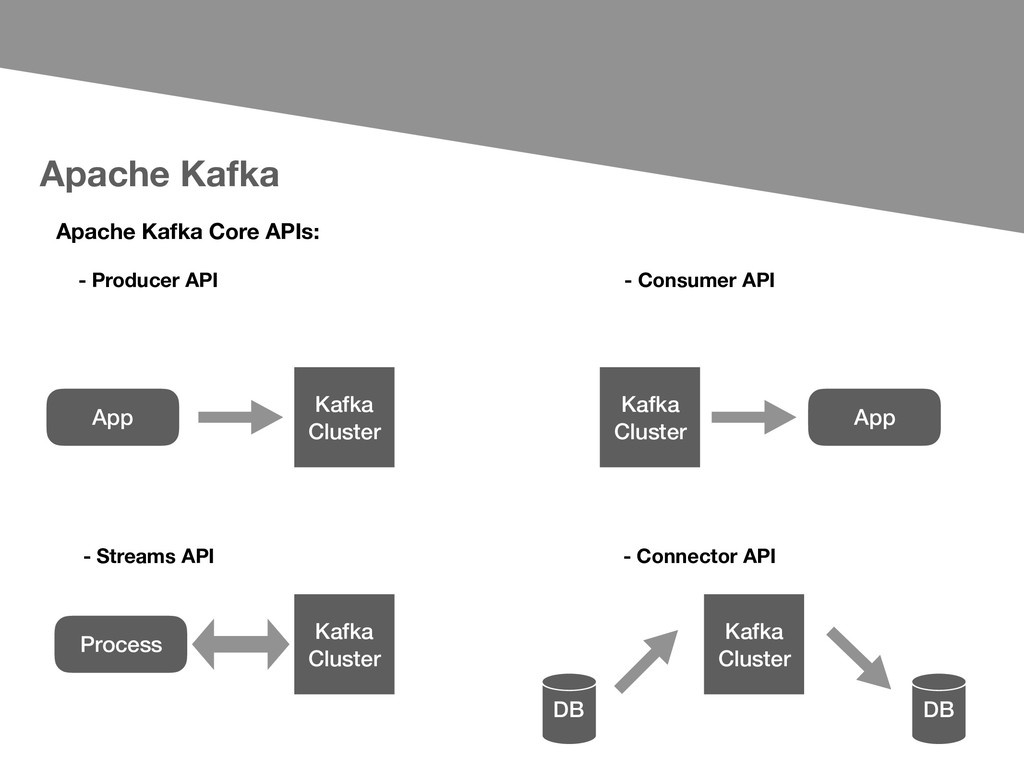
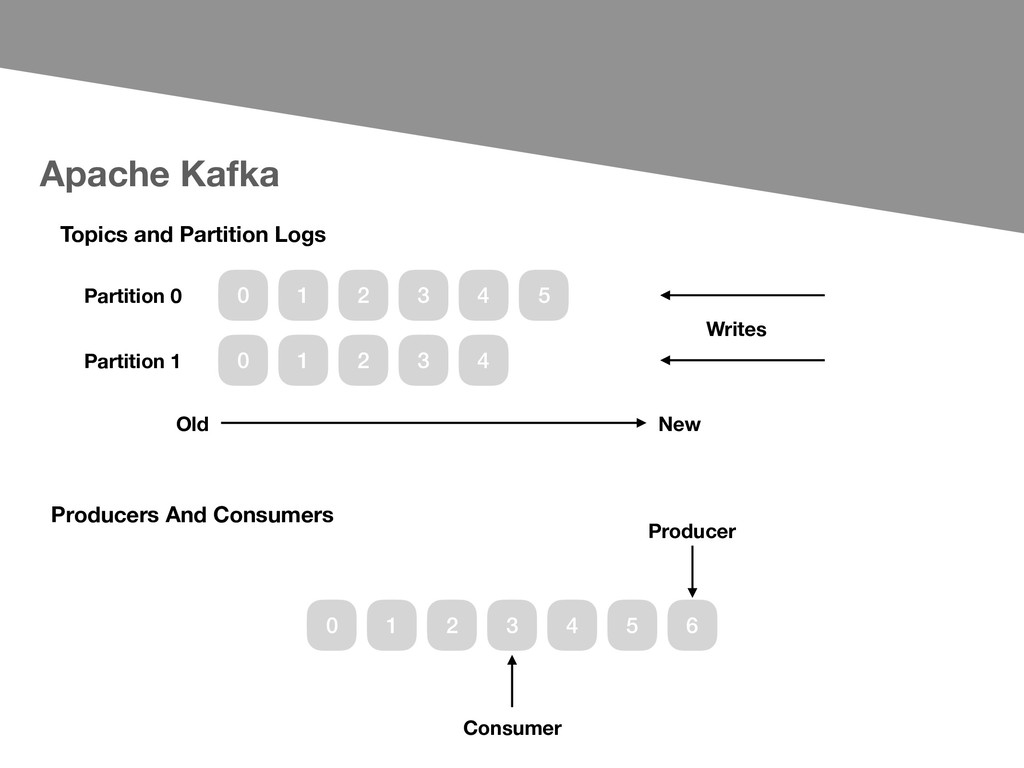
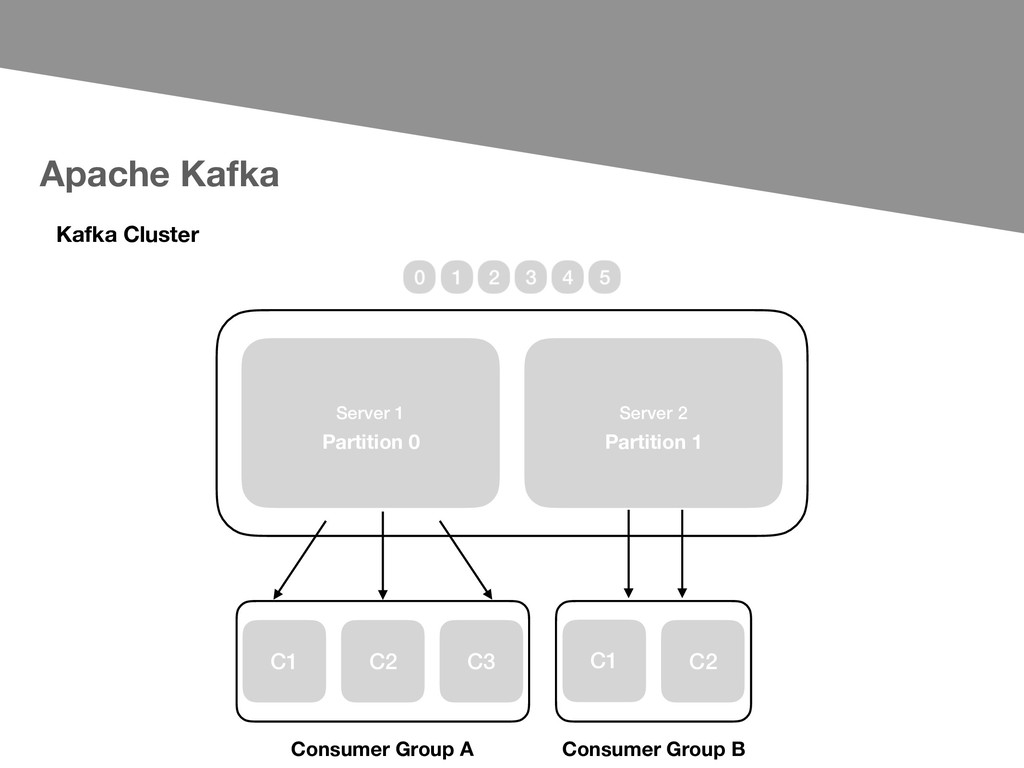
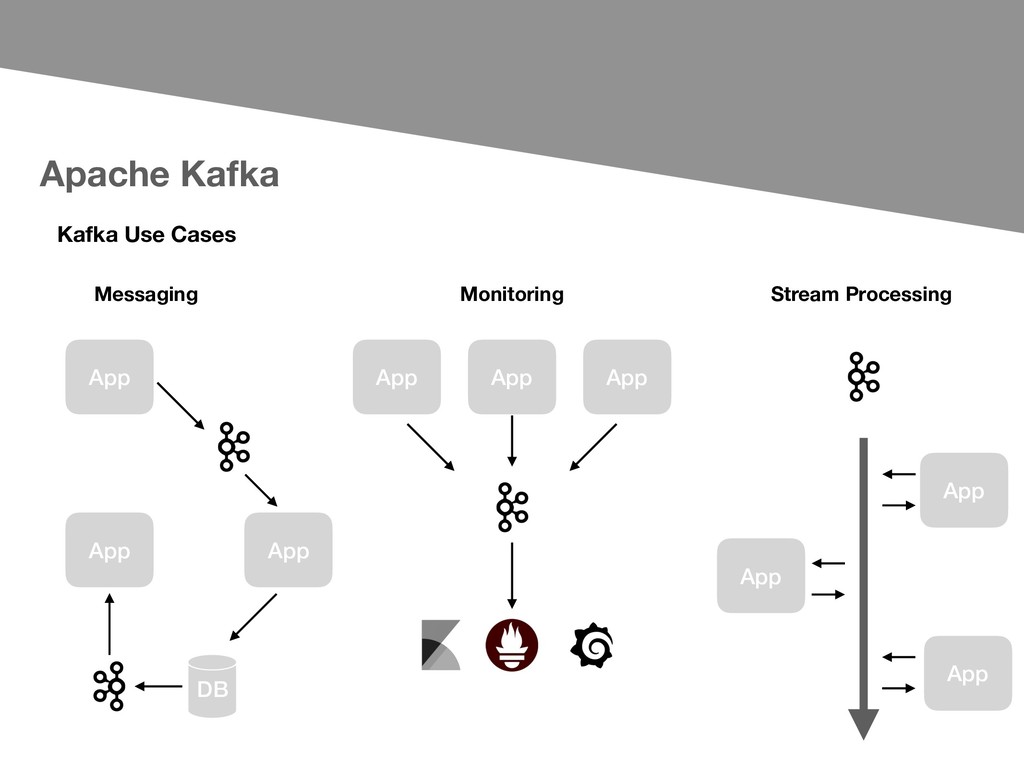
- Publish and subscribe to streams of records - Store streams of records - Process streams of records as they occur. Important concepts about Apache Kafka: - Kafka is run as a cluster on one or more servers - Each record consists of a key, a value, and a timestamp. - The Kafka cluster stores streams of records in categories called topics.
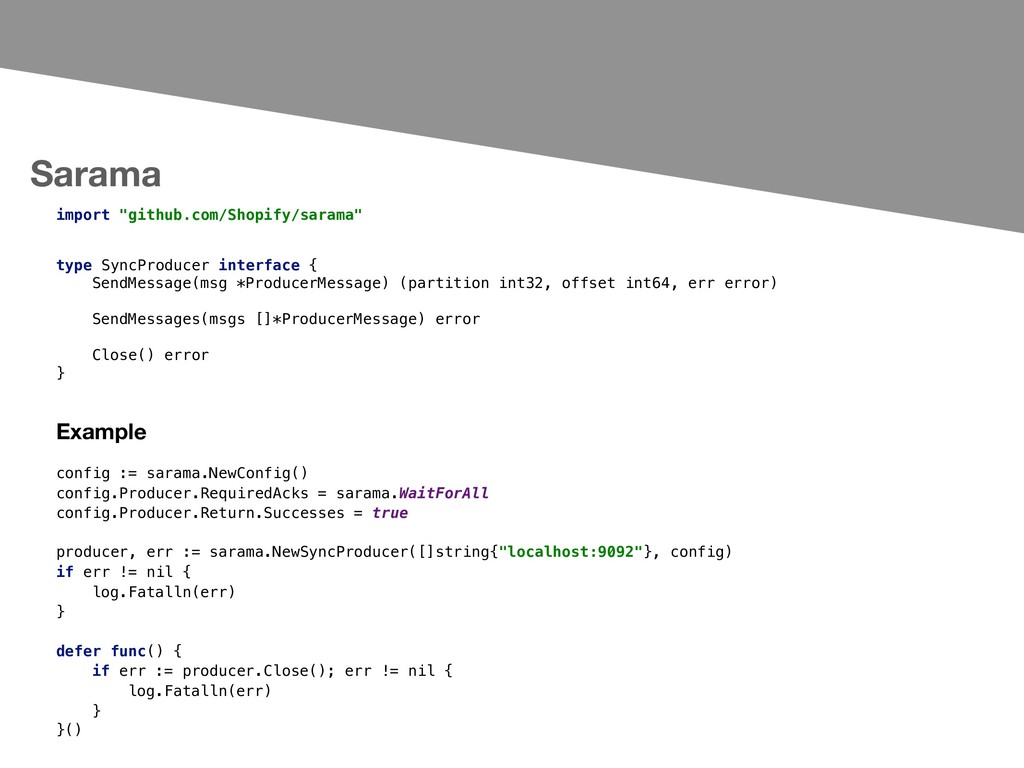
dealing with Apache Kafka (versions 0.8 and later). The package includes: - High-level API for easily producing and consuming messages. - Low-level API for controlling bytes on the wire when the high-level API is insufficient. - Sync and Async messages producers. - Kafka messages consumer.
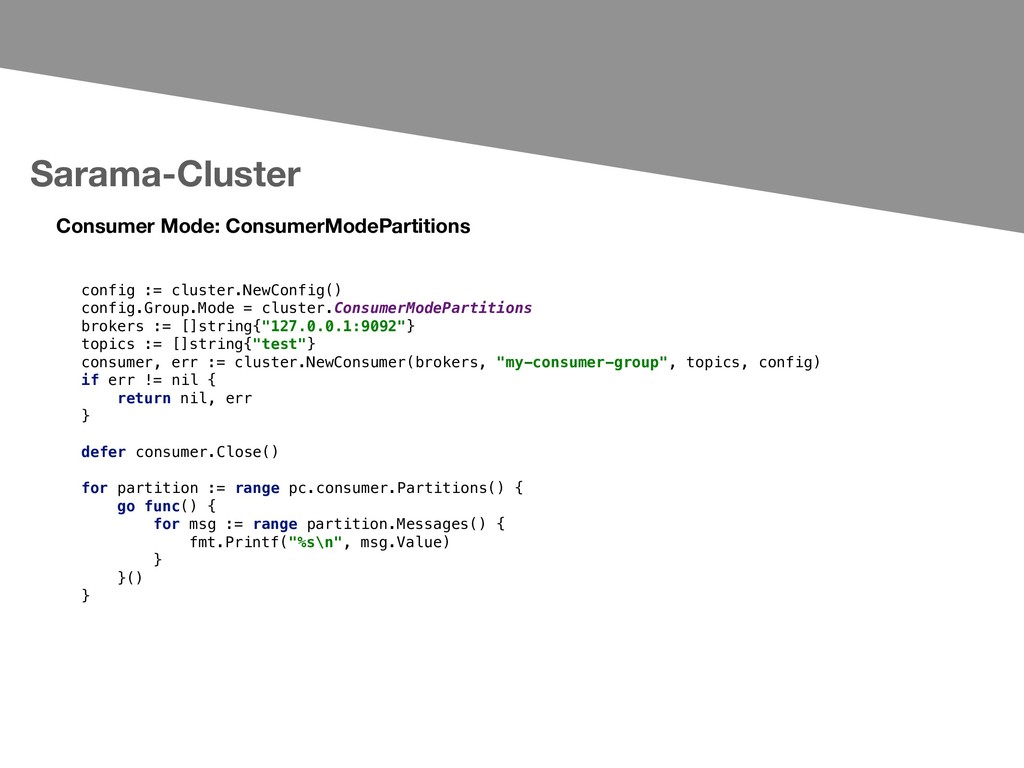
to consume topics across from multiple, balanced nodes. The package includes: - High-level API for consuming messages from multiple topics through a multiplexed channel. - High-level API for consuming messages from multiple topics through individual partitions. - Extends sarama.Config with Group specific namespace(e.g: creating consumers with topic whitelists.
struct { Type NotificationType Claimed map[string][]int32 Released map[string][]int32 Current map[string][]int32 } Notification Types: RebalanceStart RebalanceOK RebalanceError config.Consumer.Return.Errors = true func (pc *partitionedConsumer) run() { for partition := range pc.consumer.Partitions() { go func() { for not := range consumer.consumer.Notifications() { fmt.Printf("cluster status: %v", not) } }() go func() { for err := range partition.Errors() { fmt.Printf("%s\n", err) } }() } }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}