At the beginning of every research effort, researchers in empirical software
engineering have to go through the processes of extracting data from raw
data sources and transforming them to what their tools expect as inputs.
This step is time consuming and error prone, while the produced artifacts
(code, intermediate datasets) are usually not of scientific value. In the
recent years, Apache Spark has emerged as a solid foundation for data
science and has taken the big data analytics domain by storm. We believe
that the primitives exposed by Apache Spark can help software engineering
researchers create and share reproducible, high-performance data analysis
pipelines.
In our presentation, given as a ICSE 2018 technical briefing, we discuss how researchers can profit from Apache Spark, through a hands-on case study.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
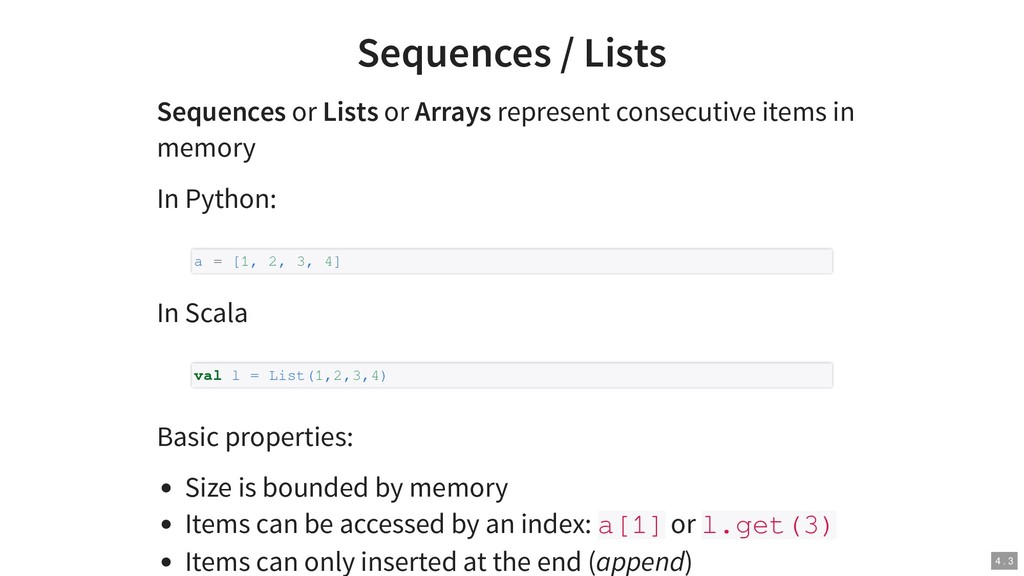{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Important higher-order functions map(xs: [A], f: A => B) :](https://files.speakerdeck.com/presentations/845a7da19b28426b9c96530dfacaa56f/slide_17.jpg){kind=link}
![Aux higher-order functions groupBy(xs: [A], f: A => K): Map[K,](https://files.speakerdeck.com/presentations/845a7da19b28426b9c96530dfacaa56f/slide_18.jpg){kind=link}
![foldL and foldR foldL(xs: [A], f: (B, A) => B,](https://files.speakerdeck.com/presentations/845a7da19b28426b9c96530dfacaa56f/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Common actions on RDD[A] collect: Return all elements of an](https://files.speakerdeck.com/presentations/845a7da19b28426b9c96530dfacaa56f/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
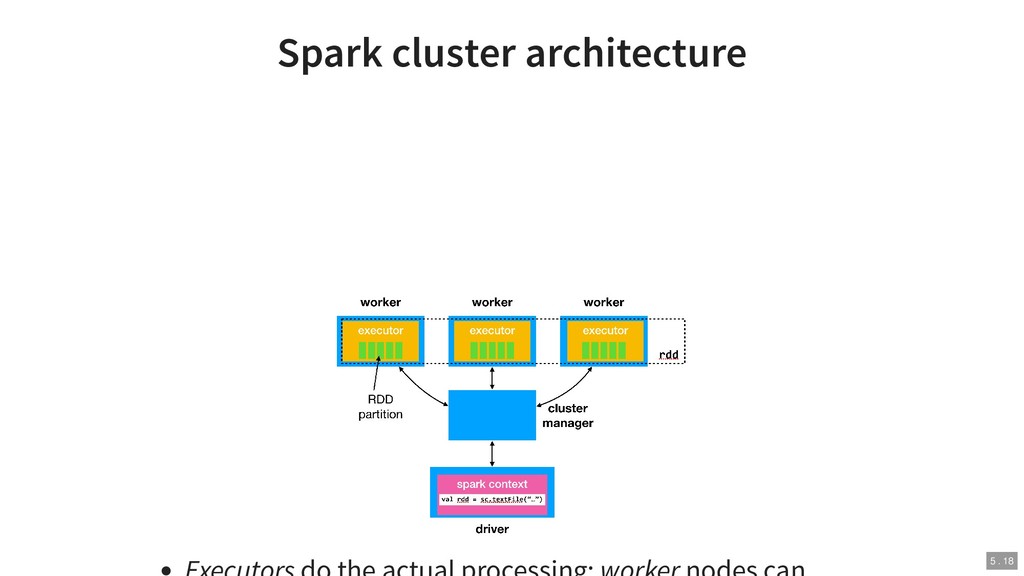{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
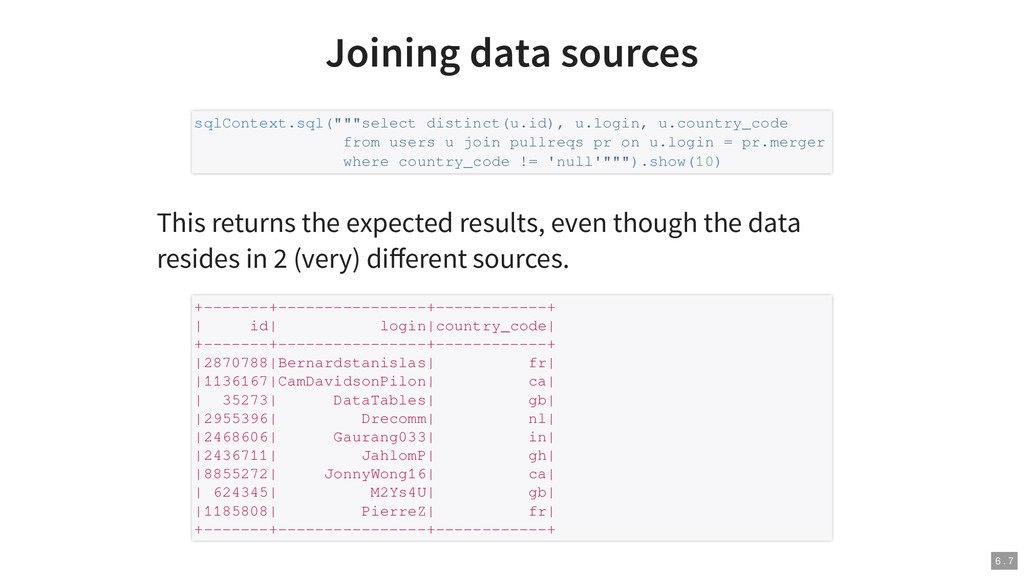{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}