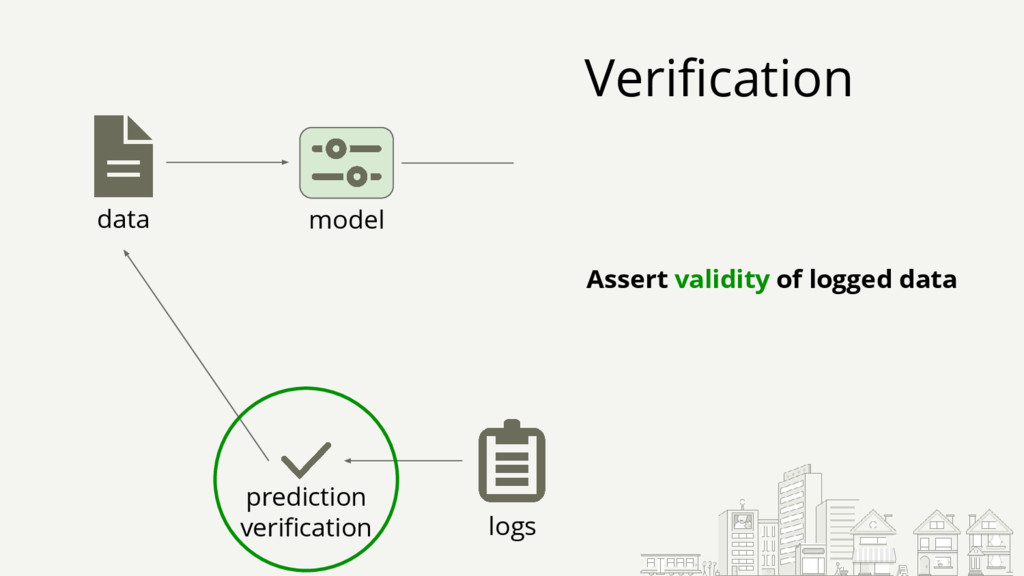
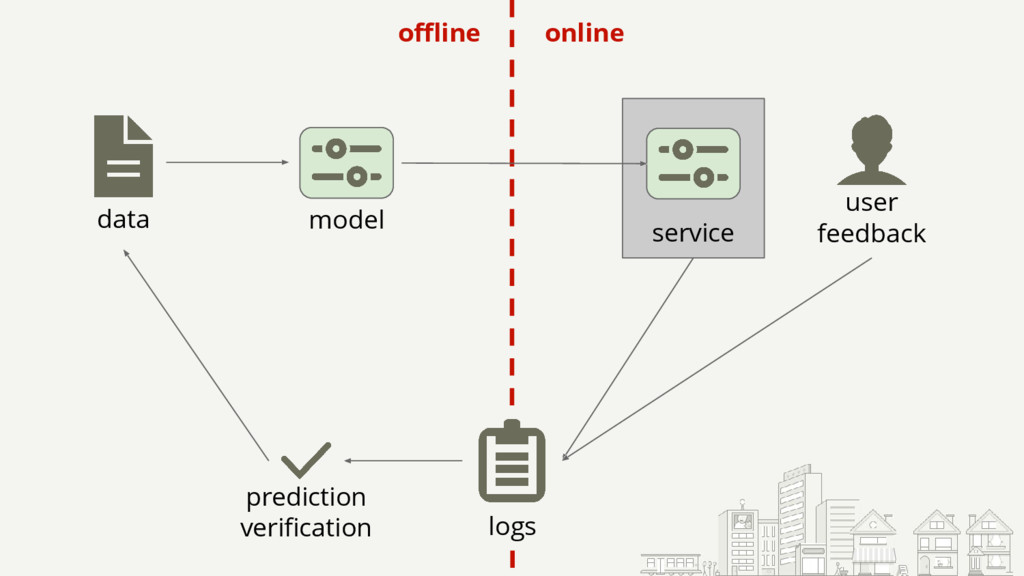
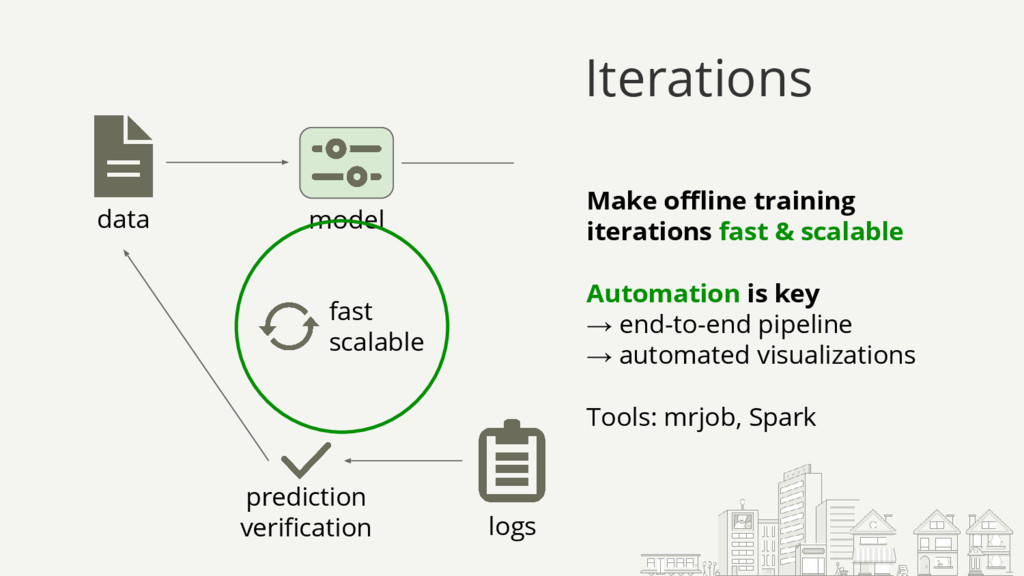
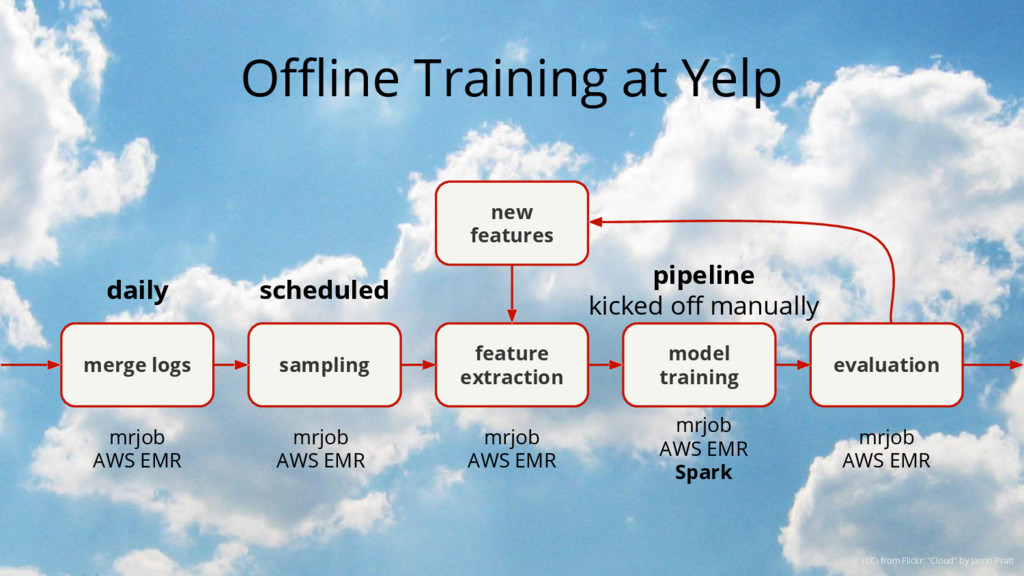
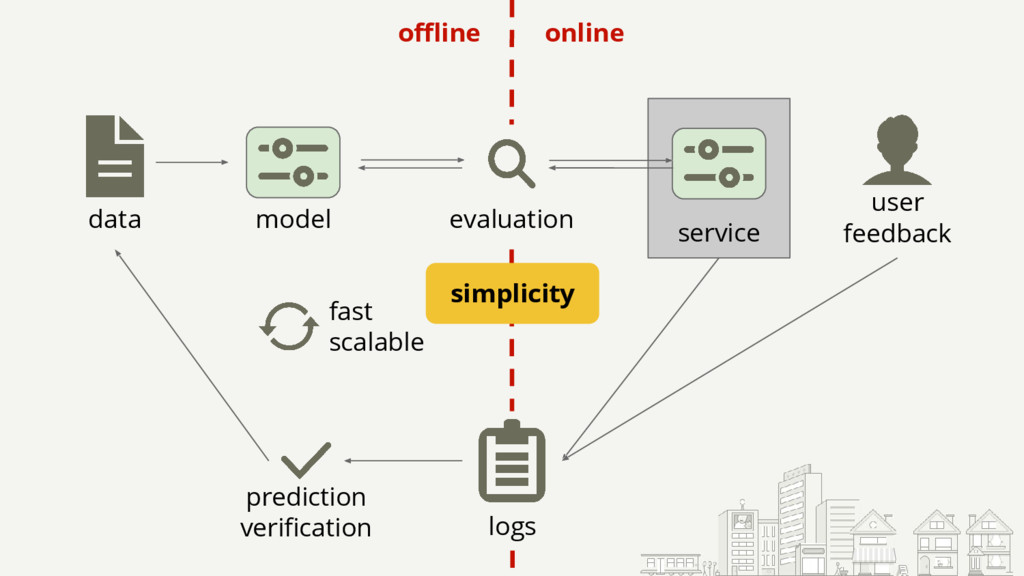
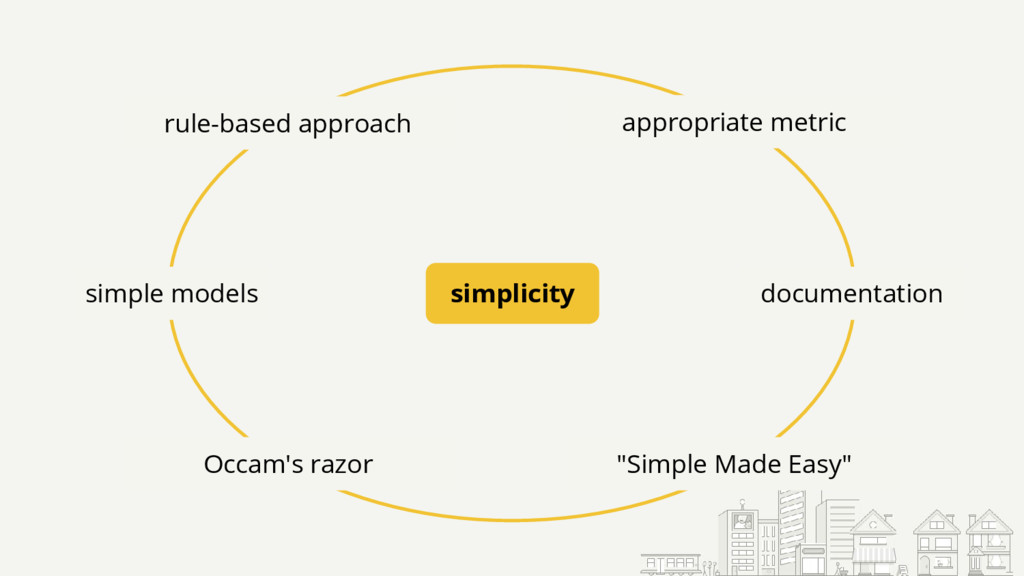
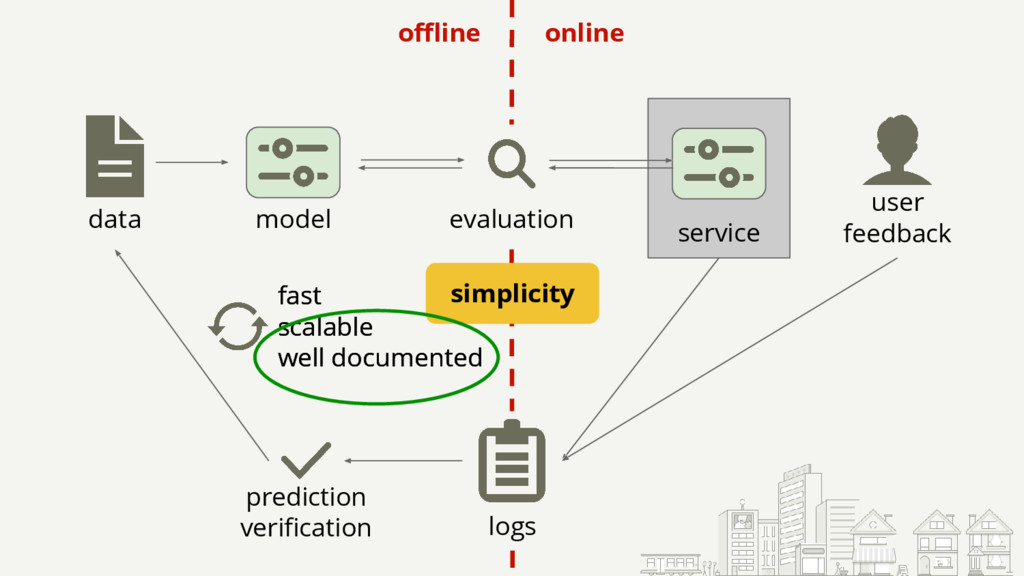
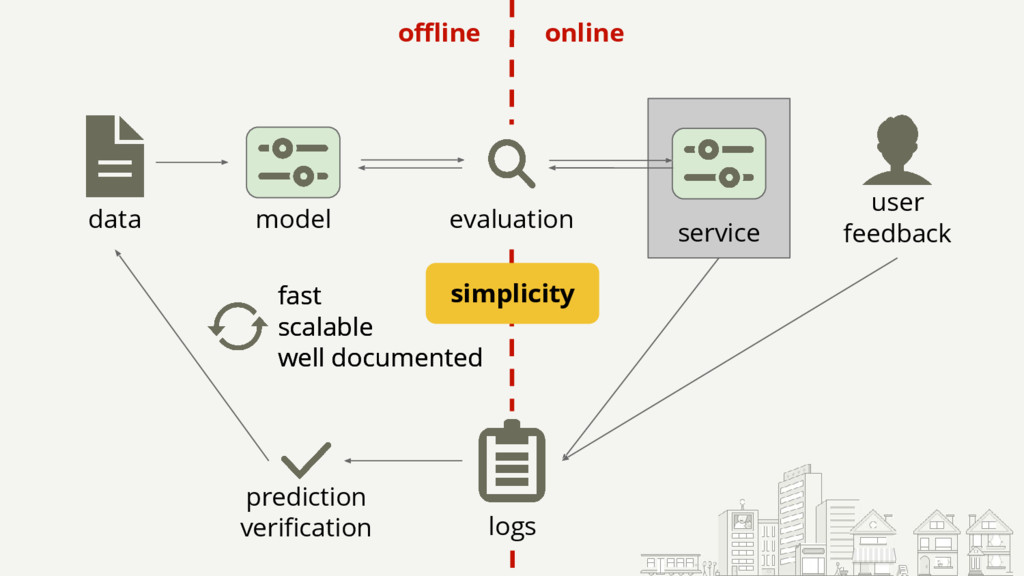
Starting with a basic setup for click-through rate (CTR) prediction, we will step by step improve on it by incorporating the lessons we've learned from operating and scaling such a mission-critical system. The presented lessons will be related to infrastructure, model comprehension, and specifics like how to deal with thresholds. They should be applicable to most ML models used in production.
Link to video: https://youtu.be/zbAuoFUdjAI
![Florian Hartl [email protected] Large Scale CTR Prediction Lessons Learned](https://files.speakerdeck.com/presentations/59cfcdff23b14ef181c5838444e6f18c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
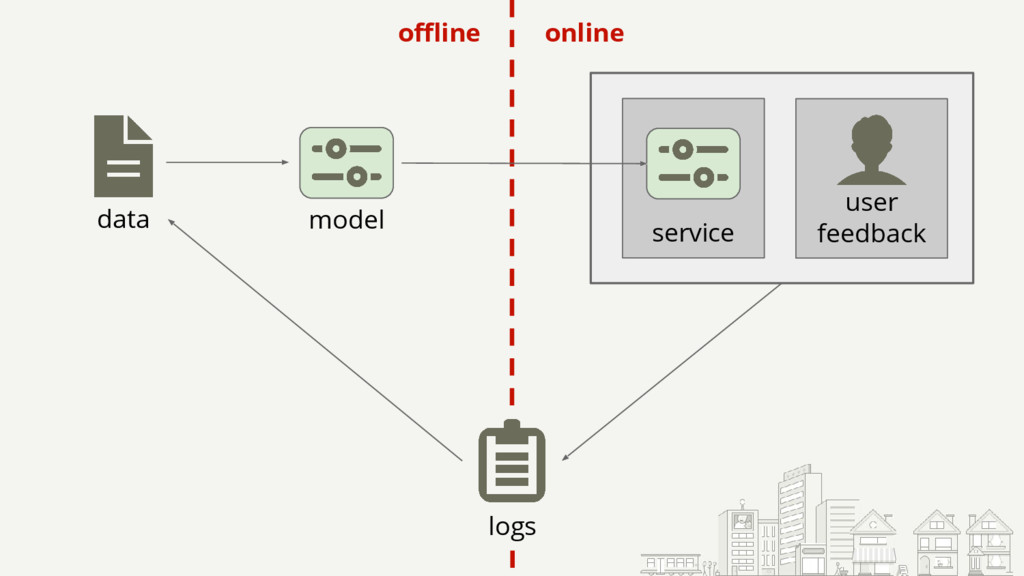{kind=link}
{kind=link}
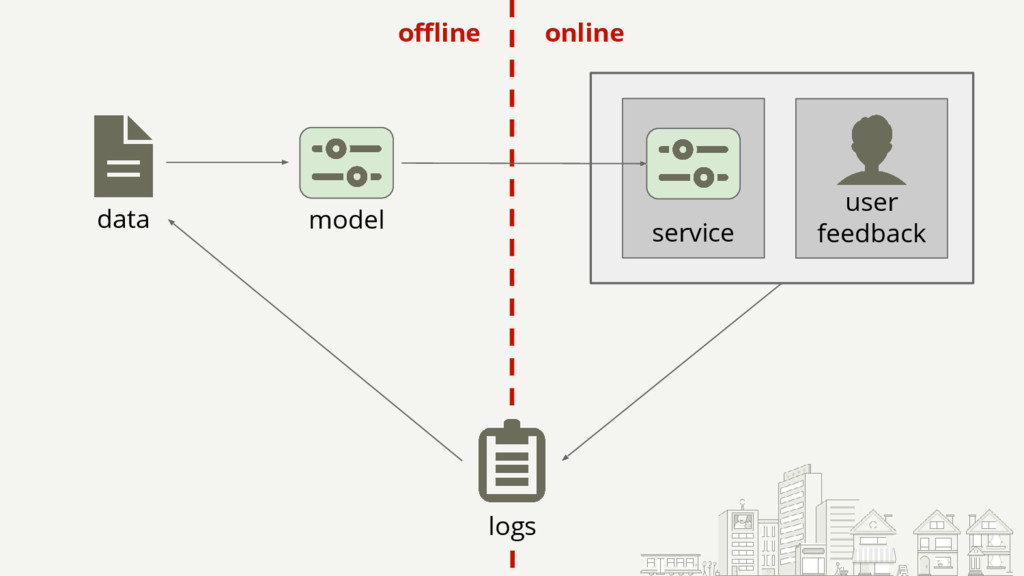{kind=link}
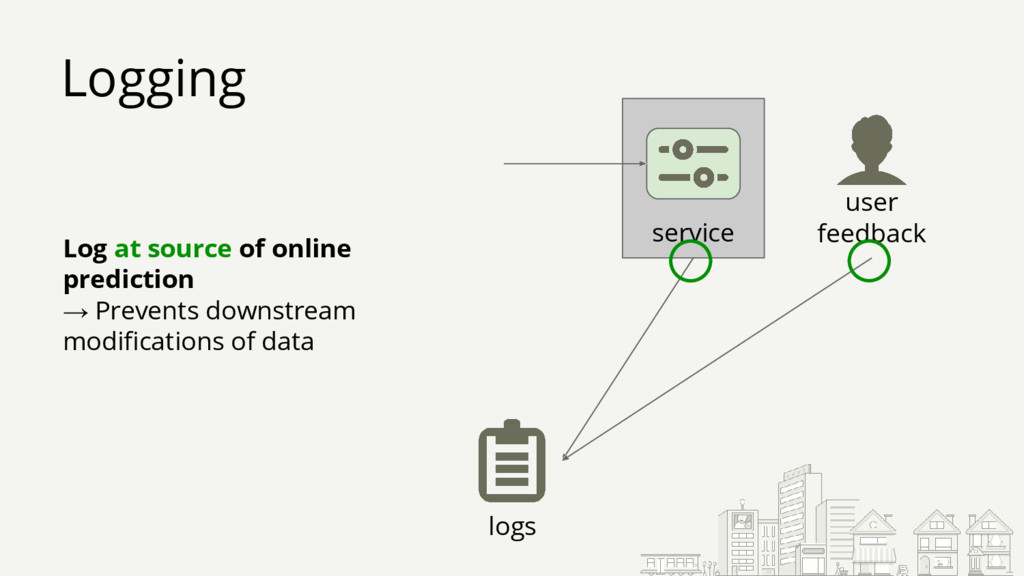{kind=link}
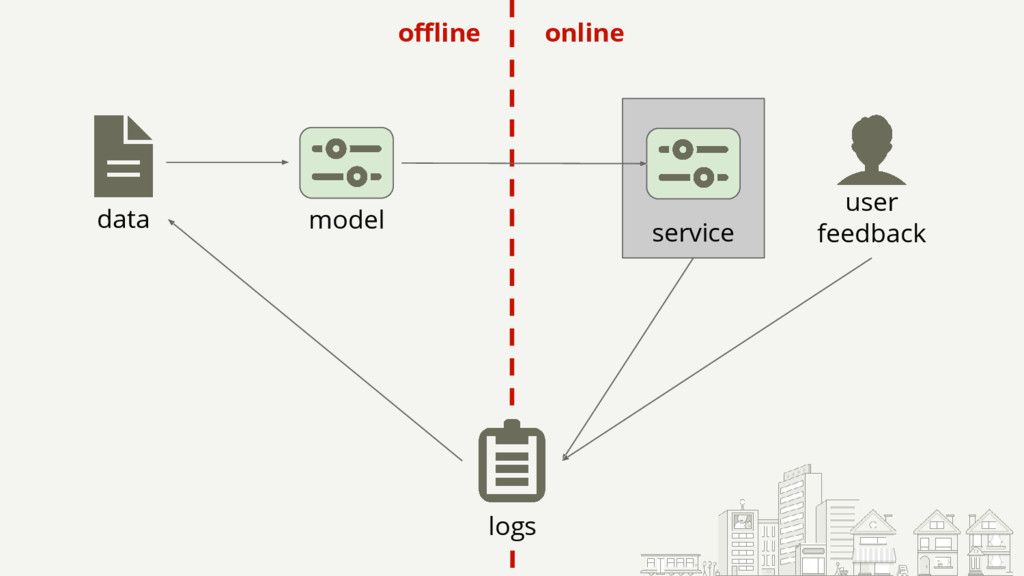{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
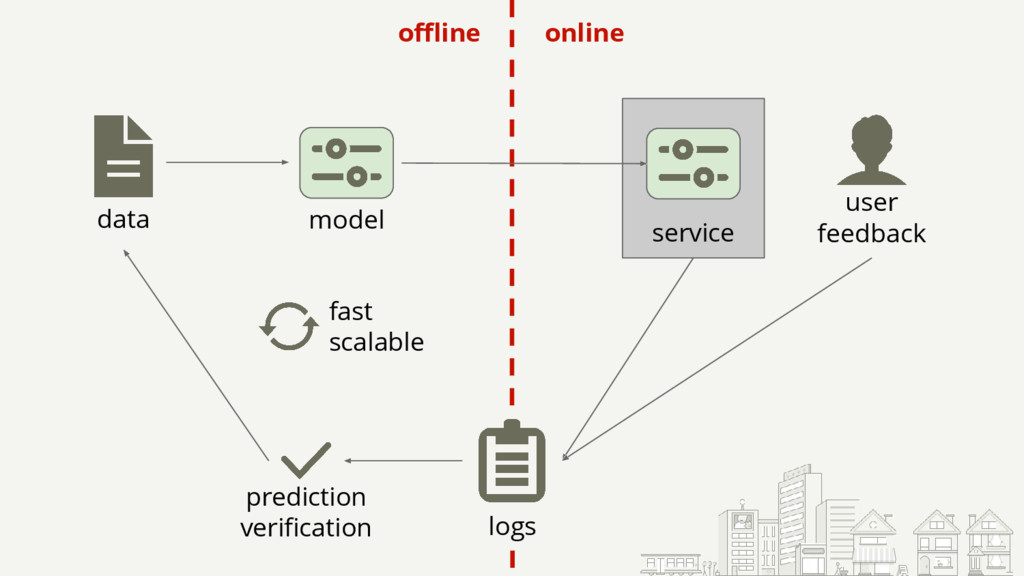{kind=link}
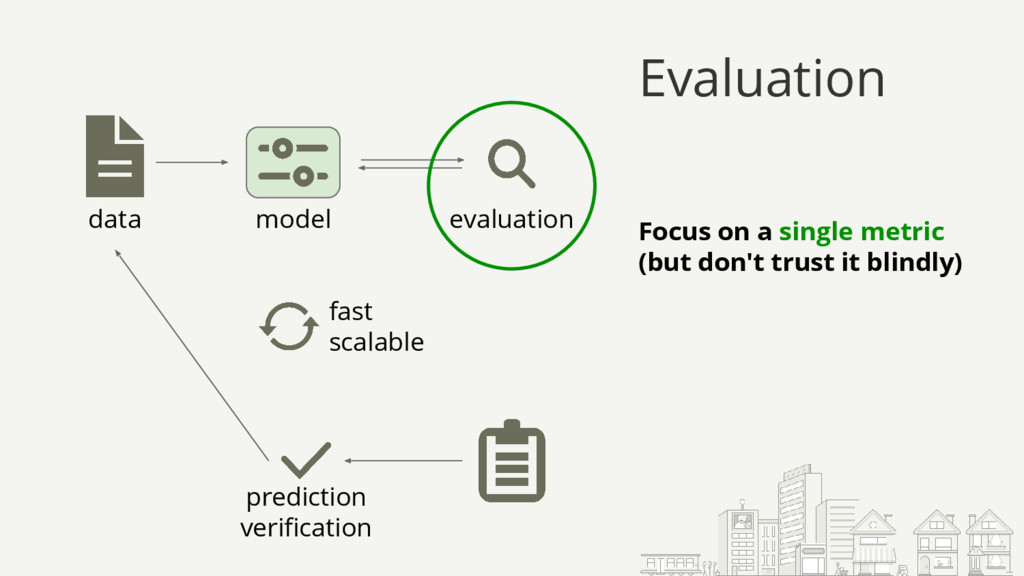{kind=link}
{kind=link}
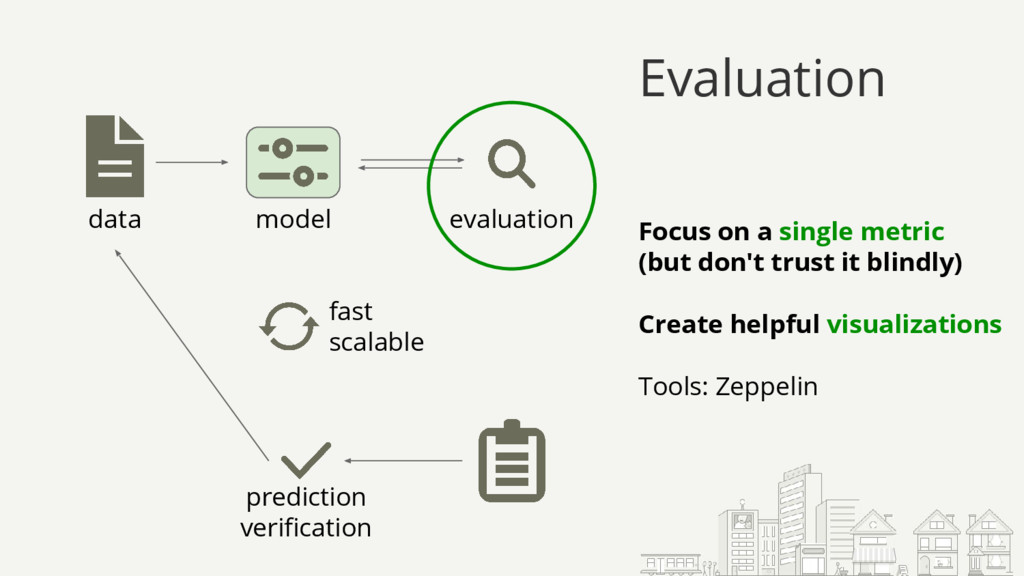{kind=link}
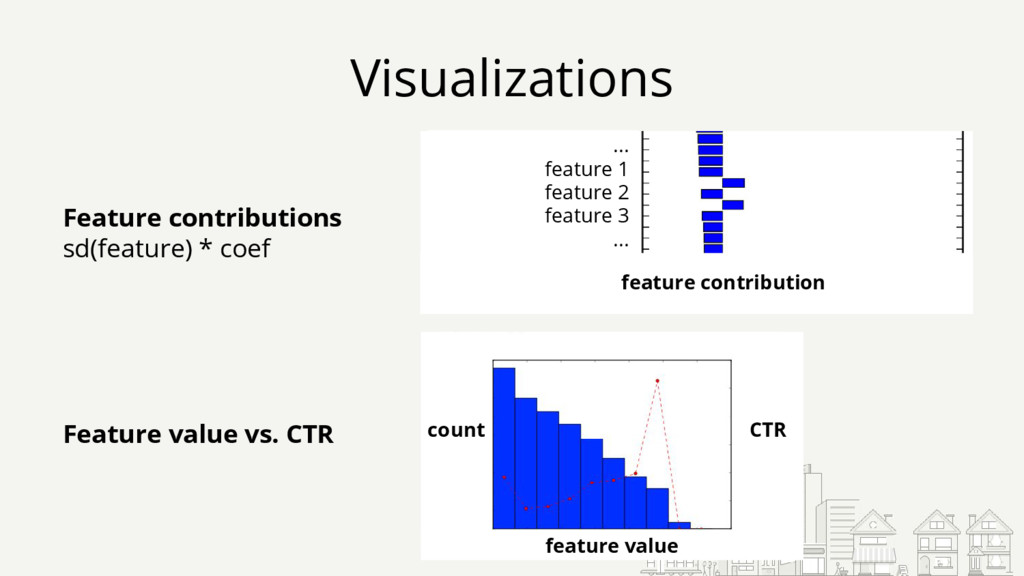{kind=link}
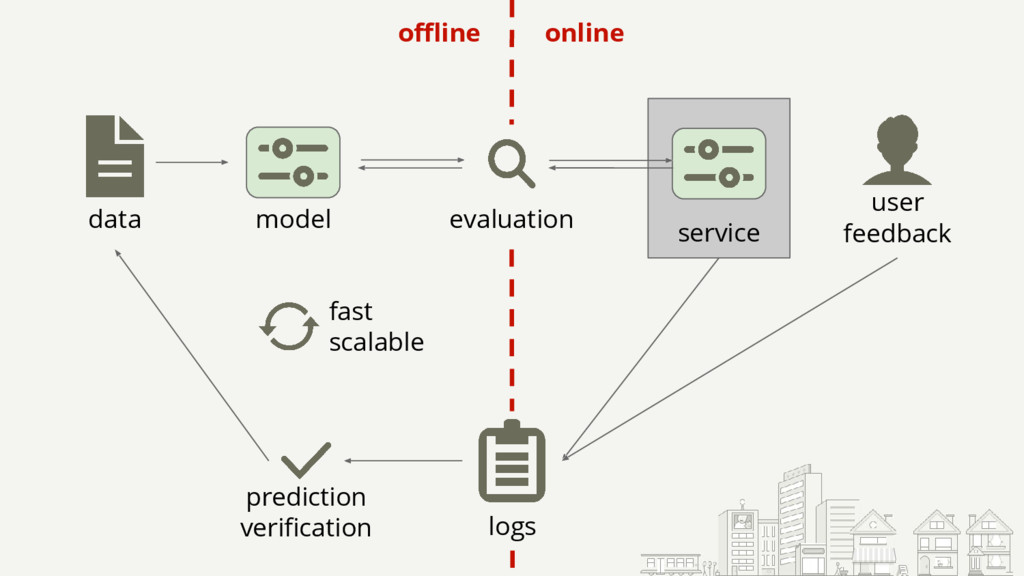{kind=link}
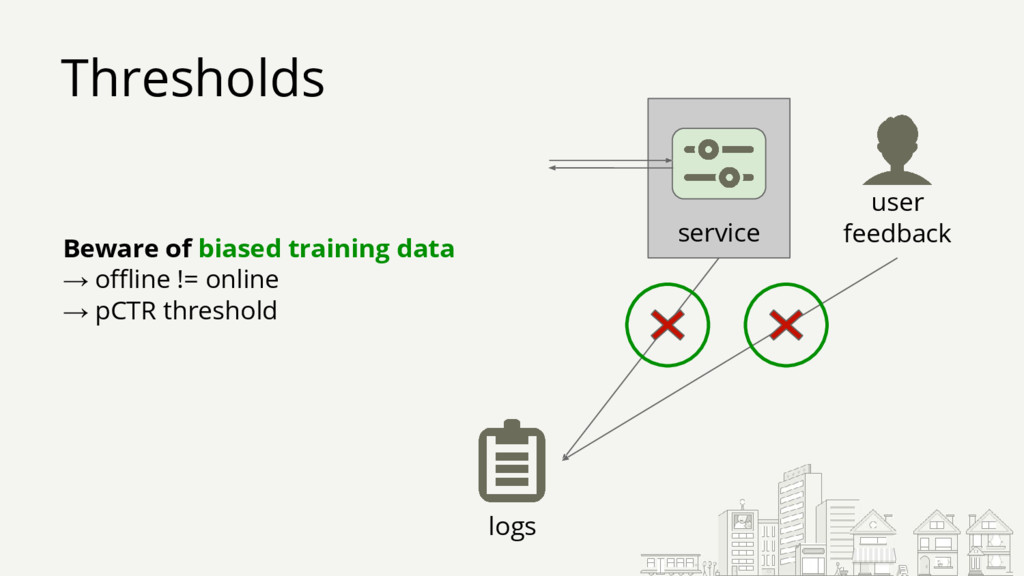{kind=link}
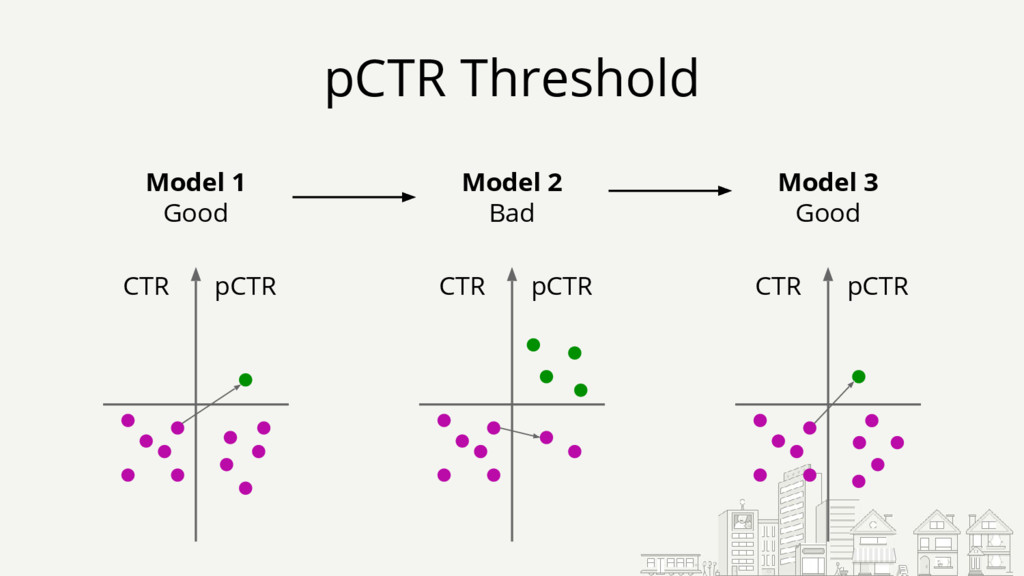{kind=link}
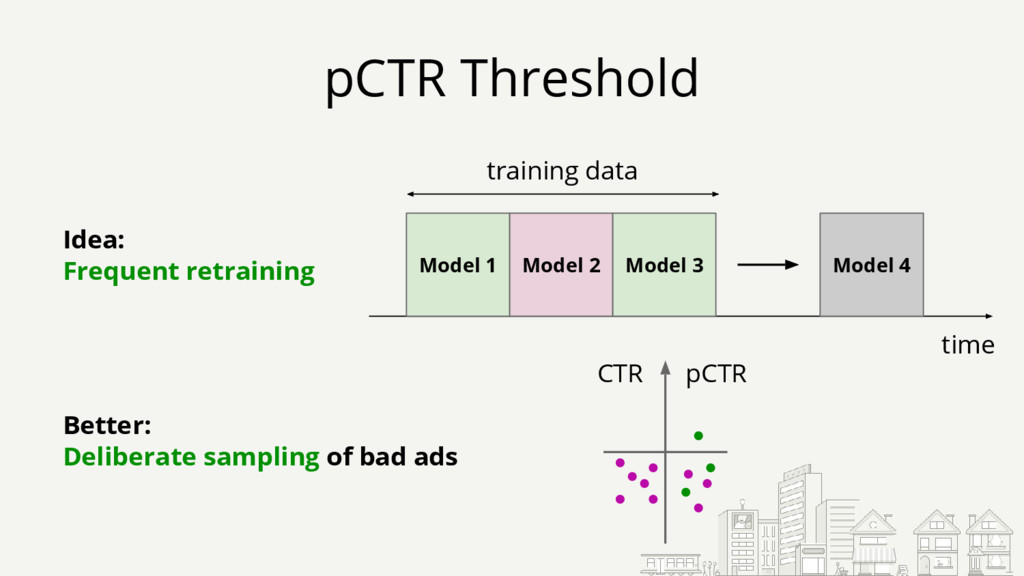{kind=link}
{kind=link}
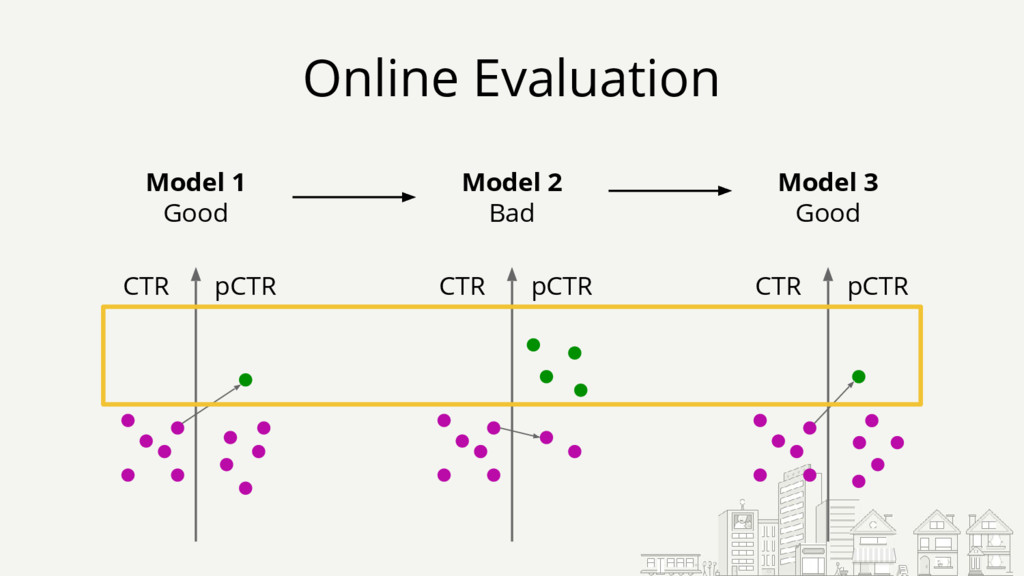{kind=link}
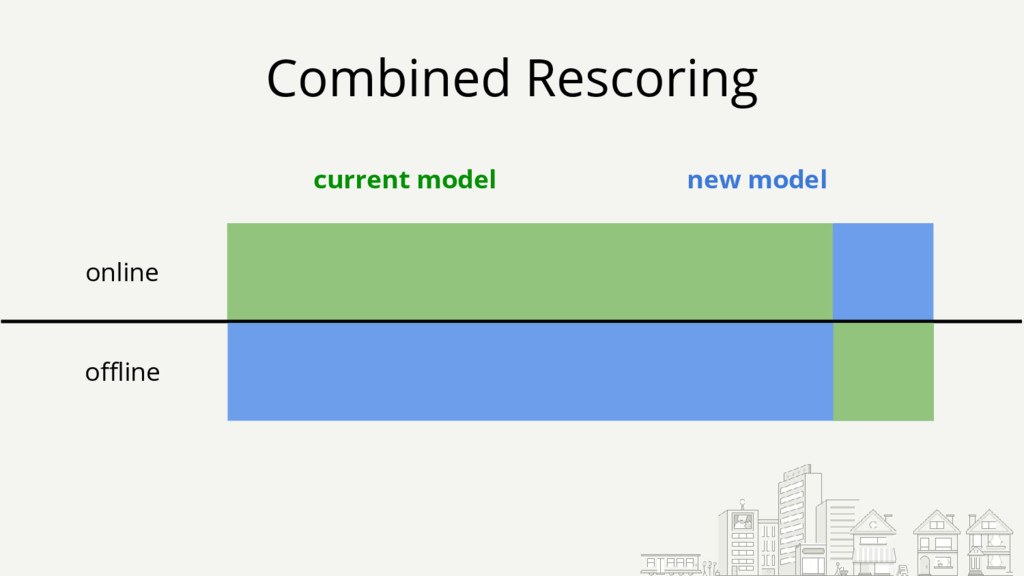{kind=link}
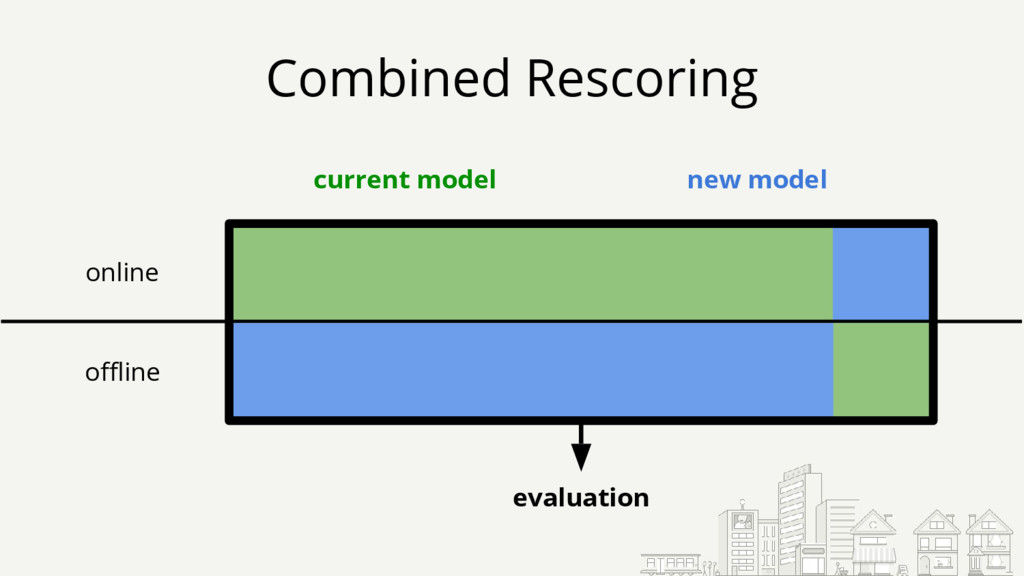{kind=link}
{kind=link}
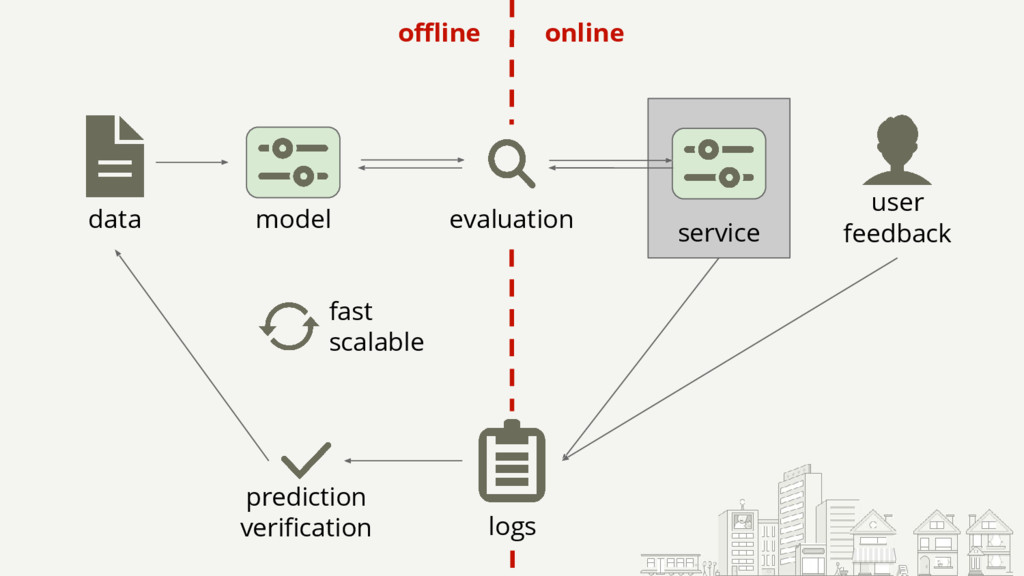{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}