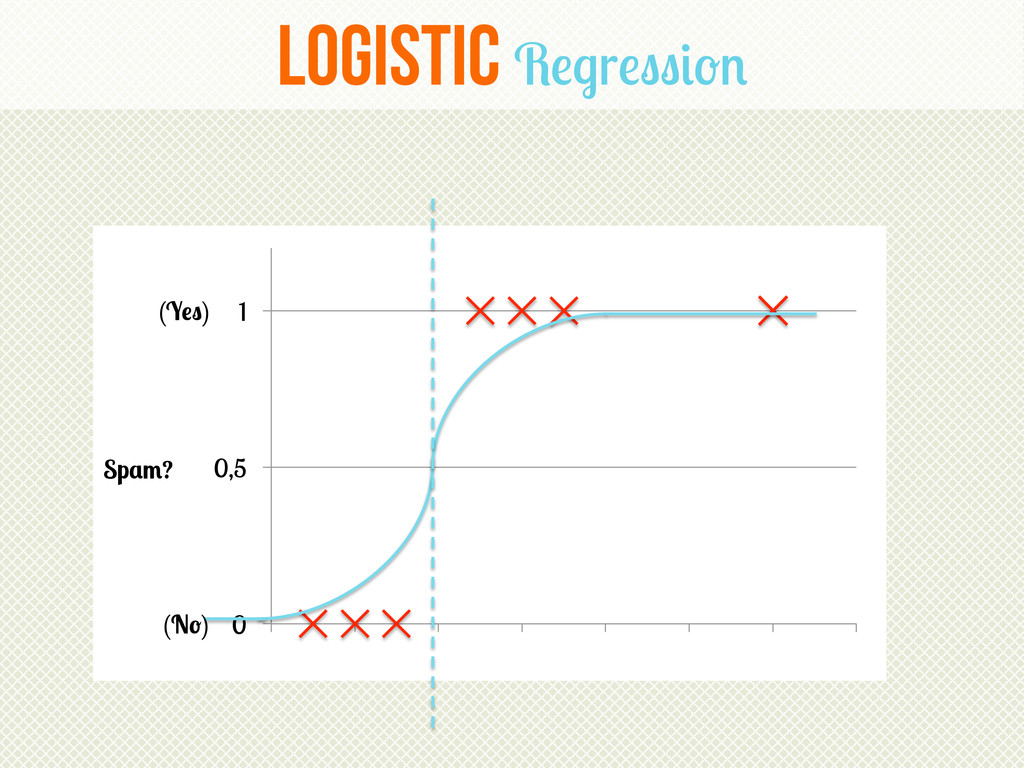
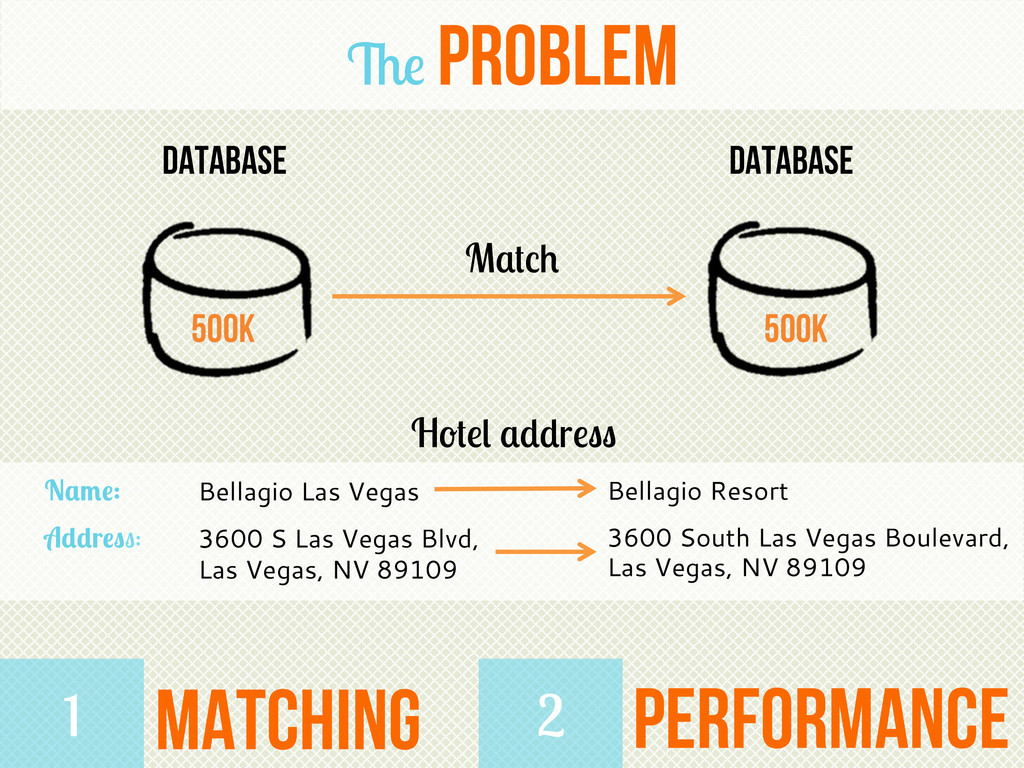
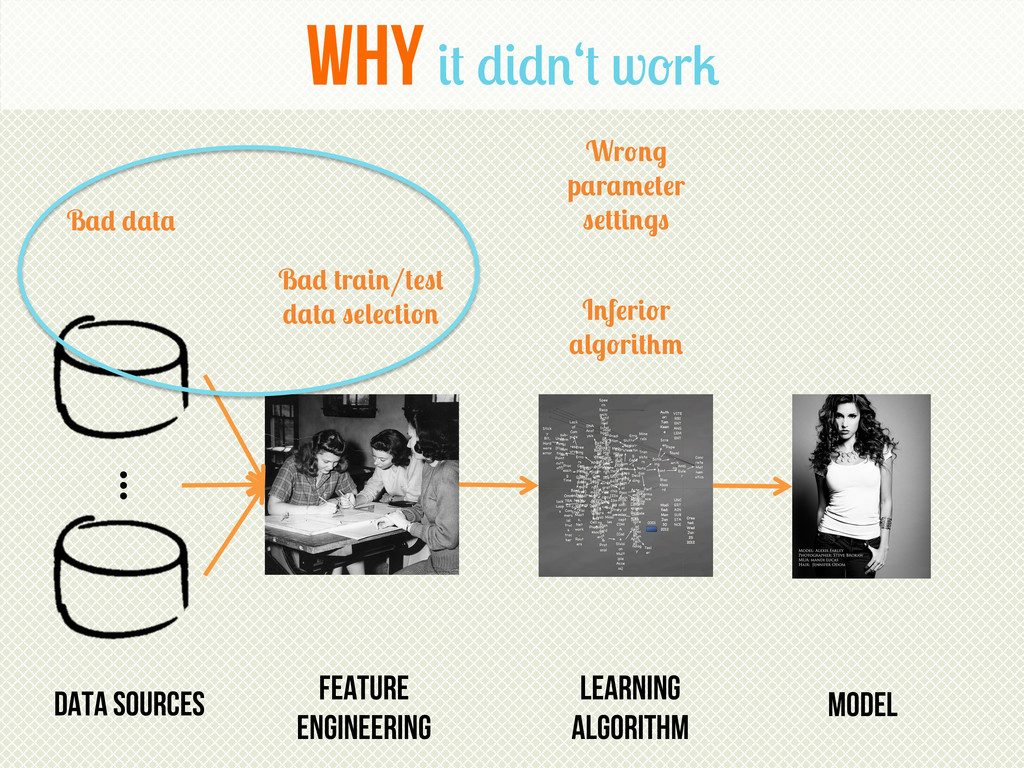
The presentation will at first provide a basic introduction to the field of Machine Learning and its core concepts and procedures. Thereafter, we the natural evolution of parametric algorithms will be shown – from linear regression to logistic regression and, if time allows, linear SVM. Finally, a real life use case from TrustYou dealing with Record Linkage is presented.
{kind=link}
{kind=link}
{kind=link}
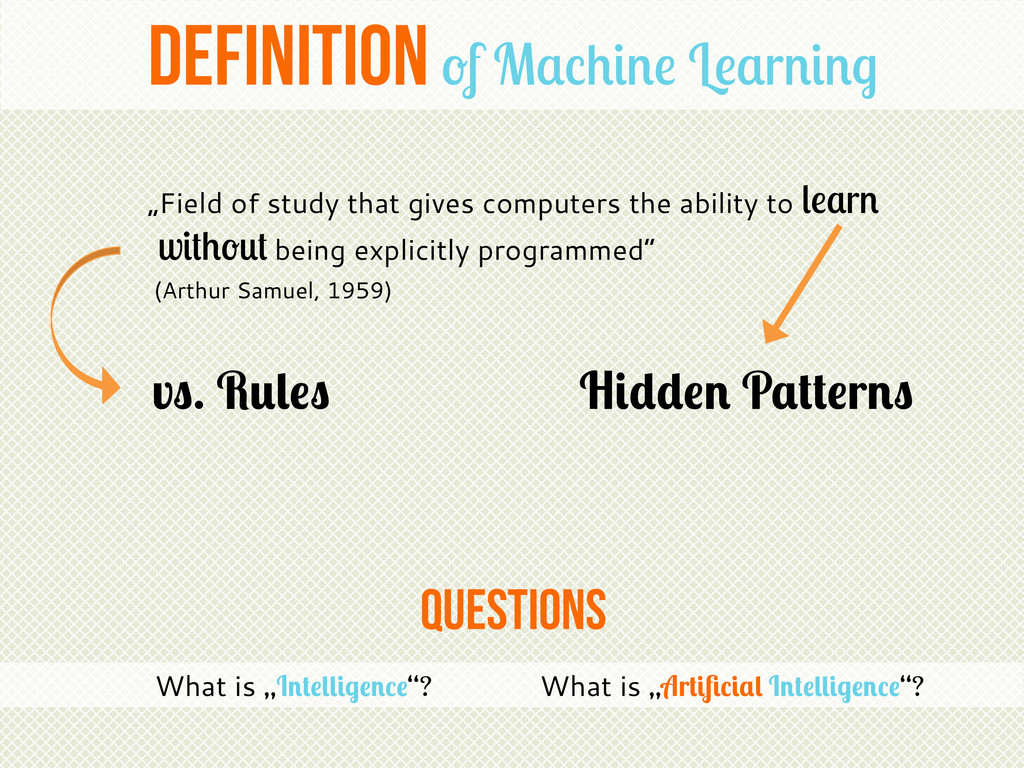{kind=link}
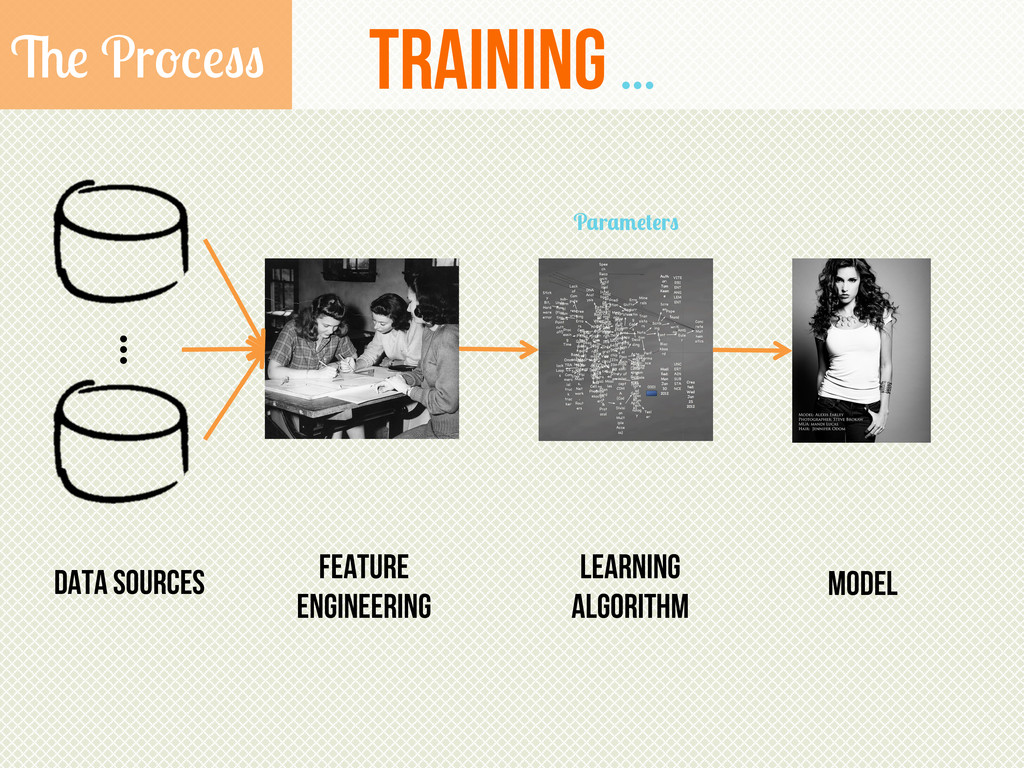{kind=link}
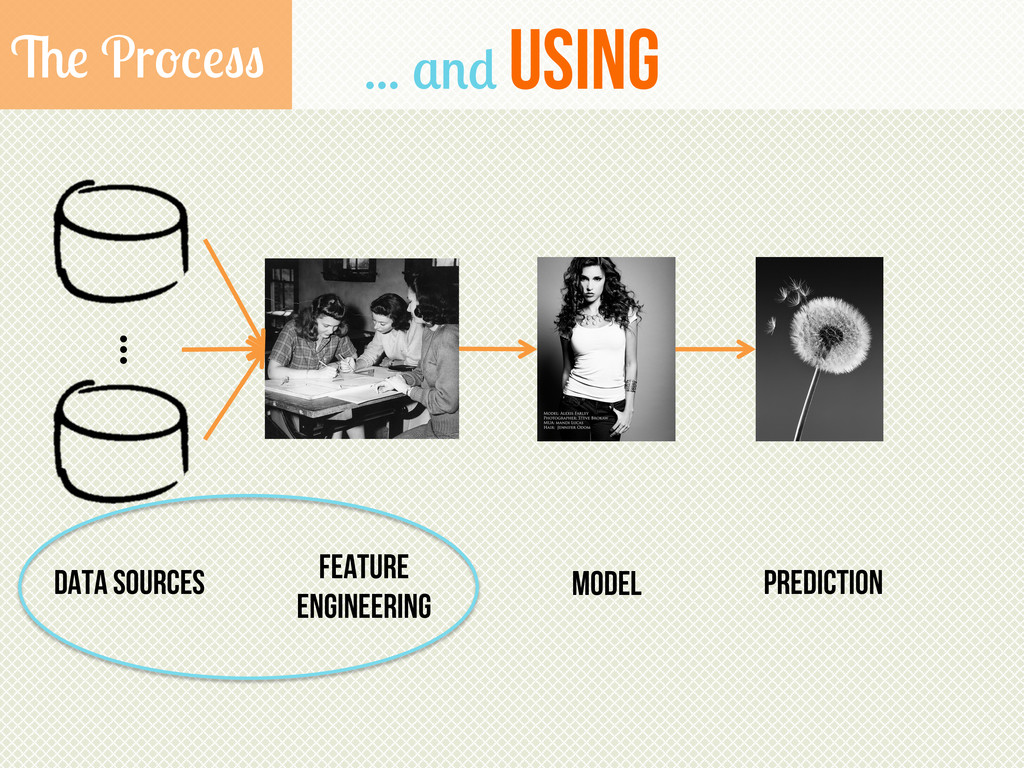{kind=link}
{kind=link}
{kind=link}
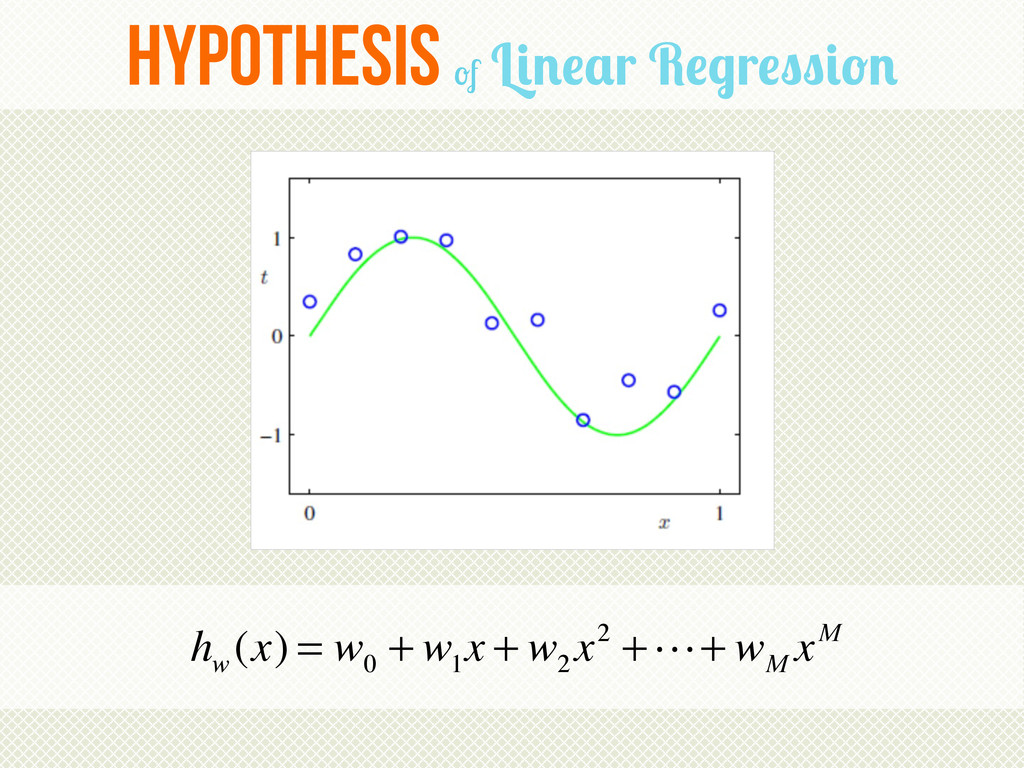{kind=link}
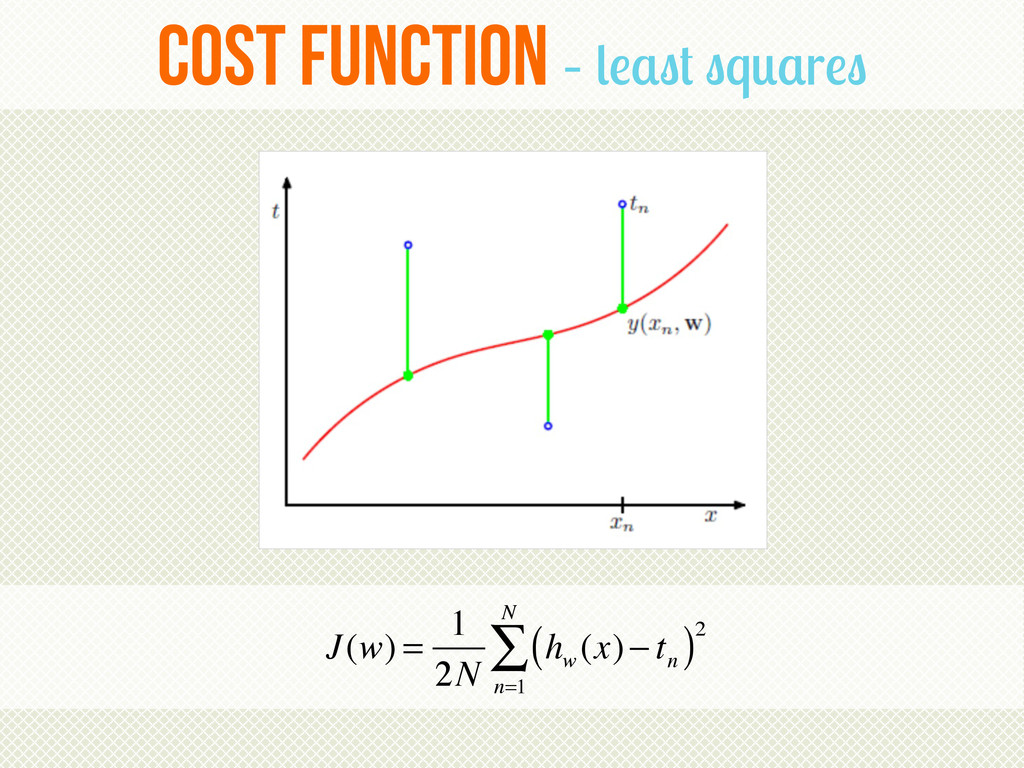{kind=link}
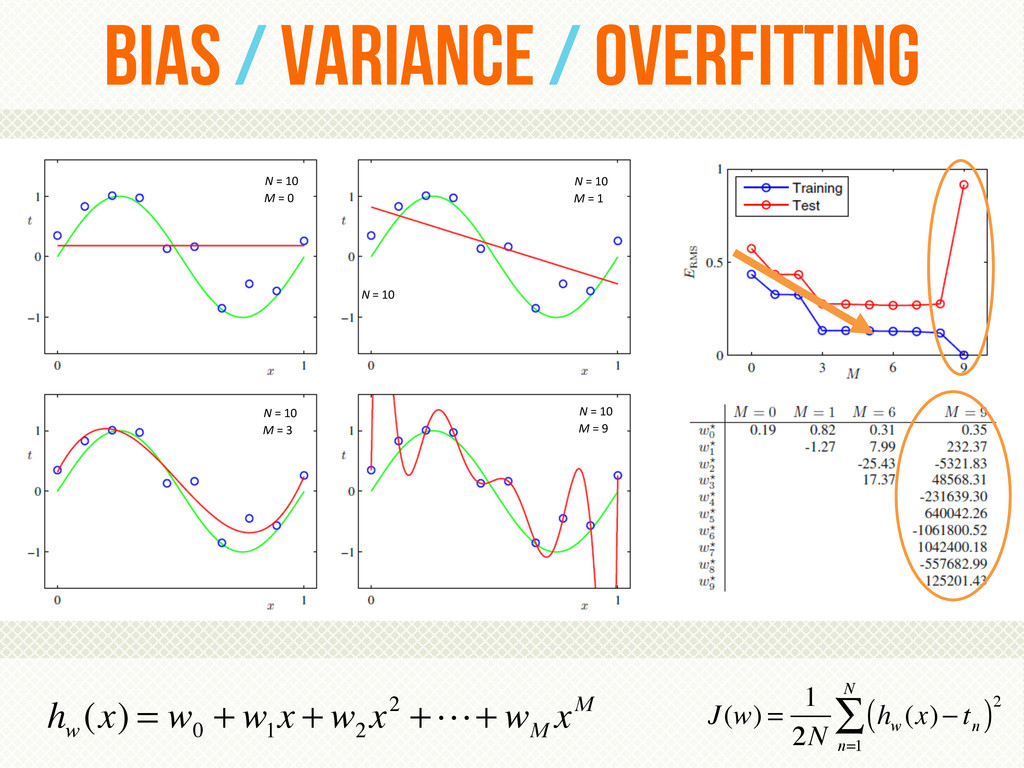{kind=link}
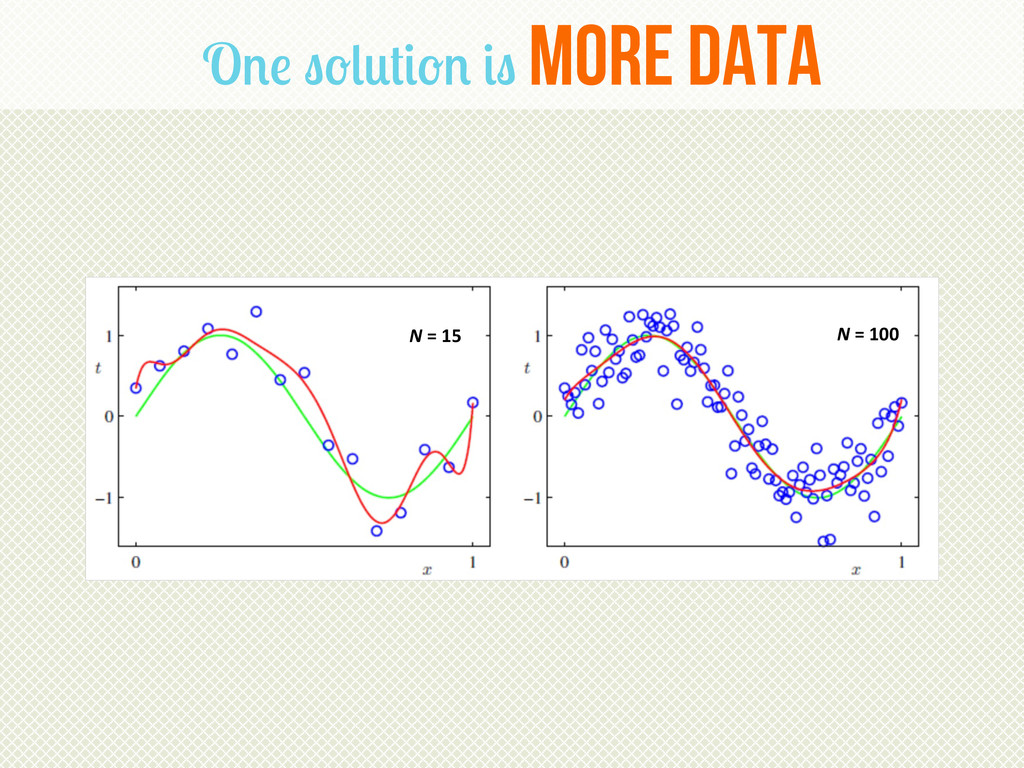{kind=link}
{kind=link}
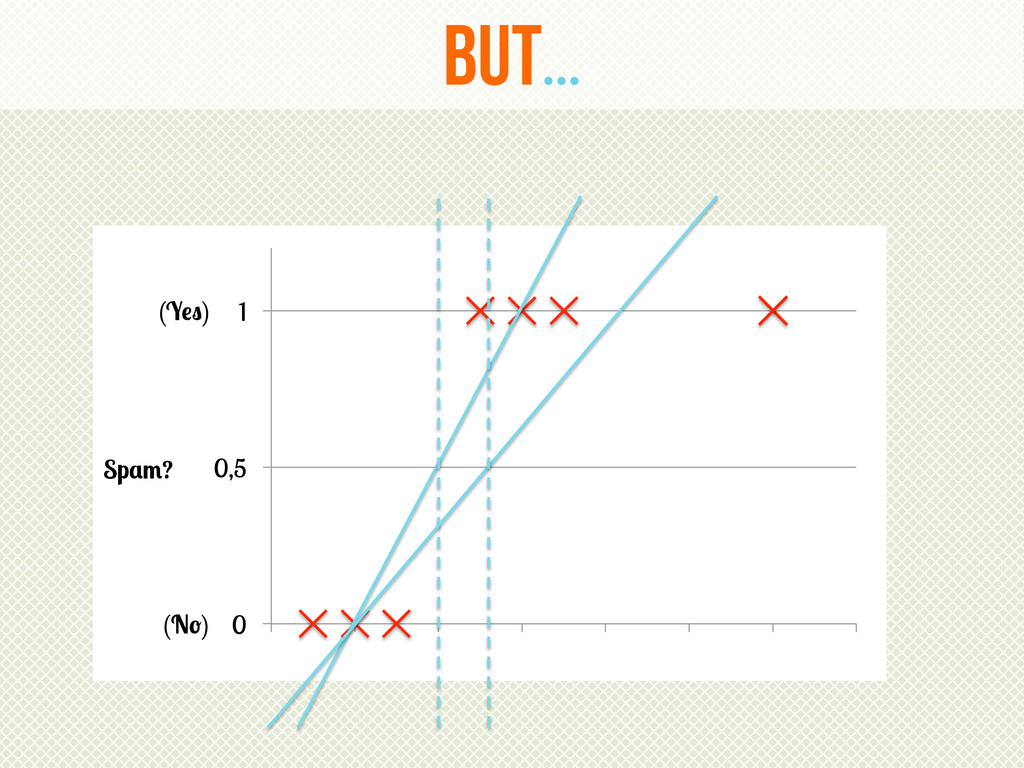{kind=link}
{kind=link}
{kind=link}
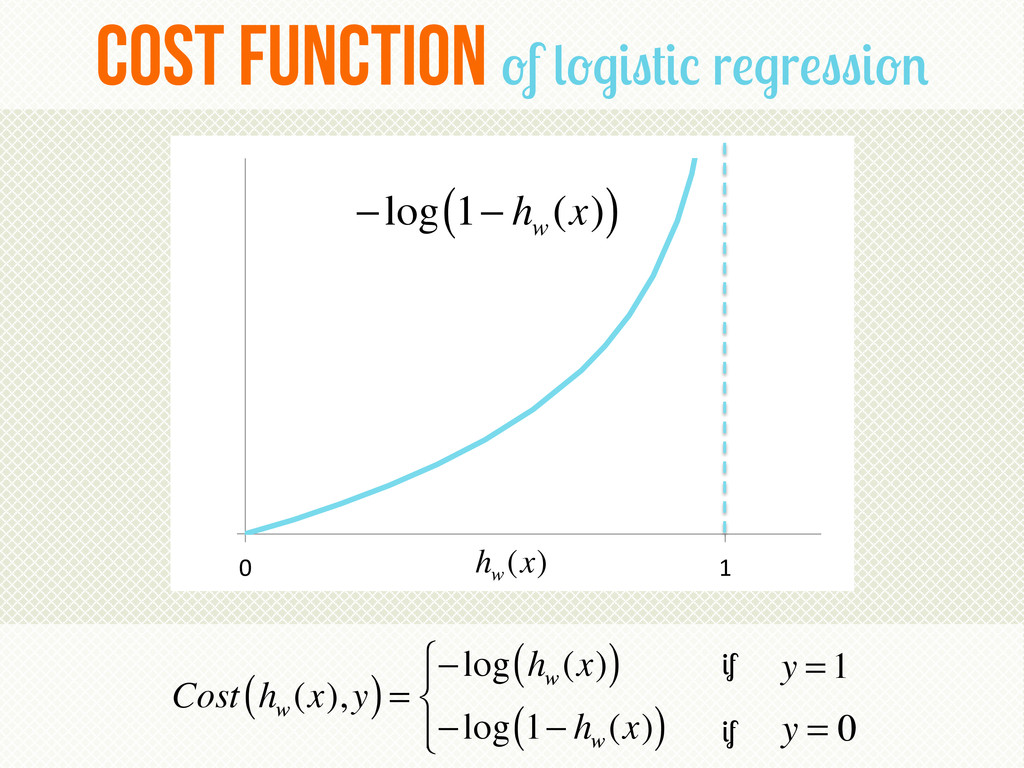{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}