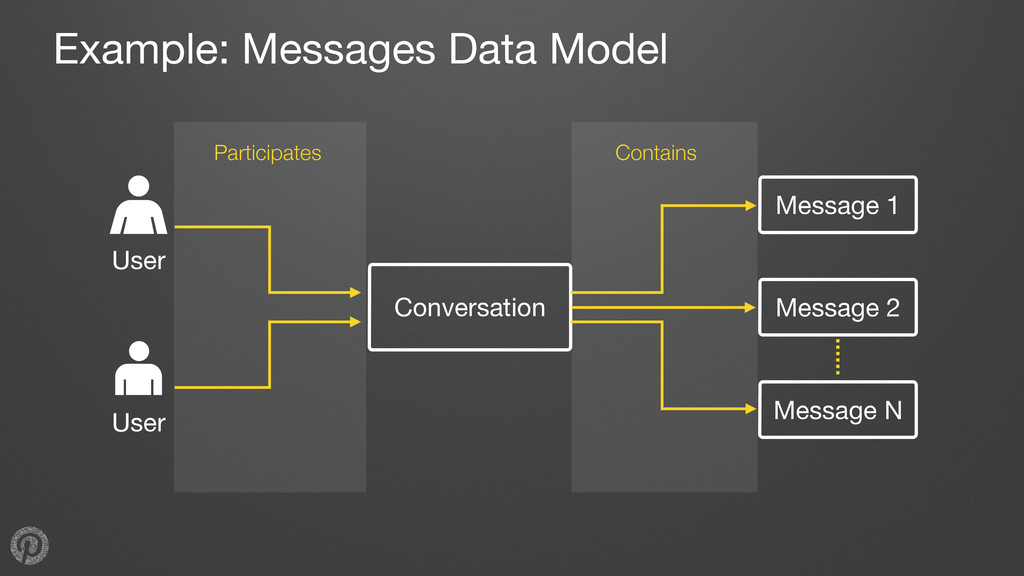
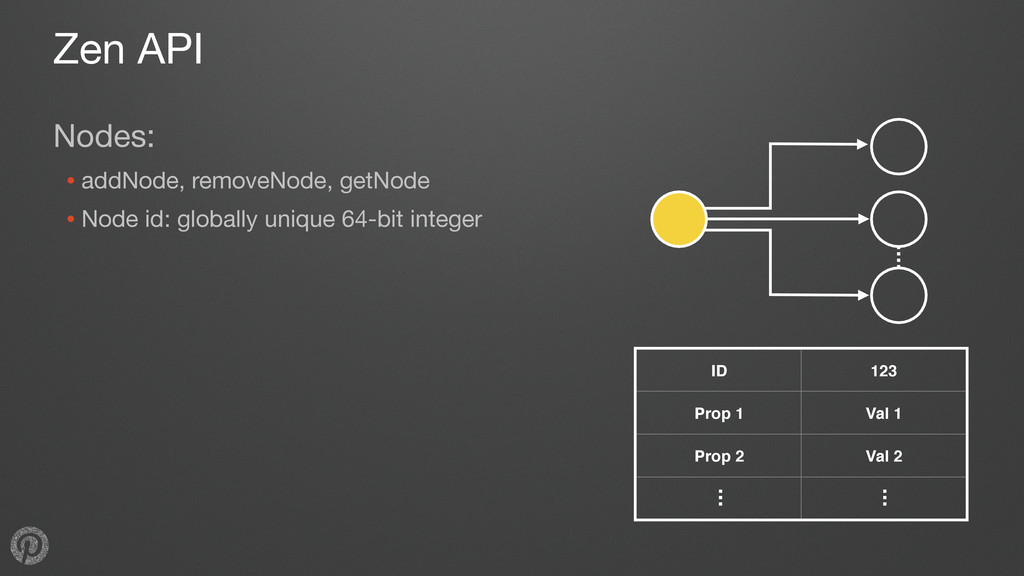
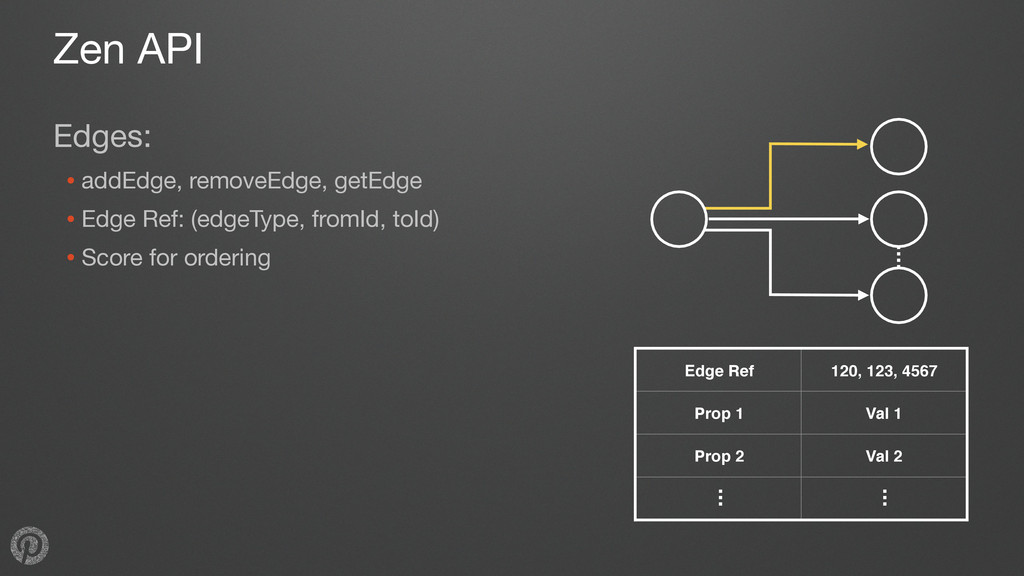
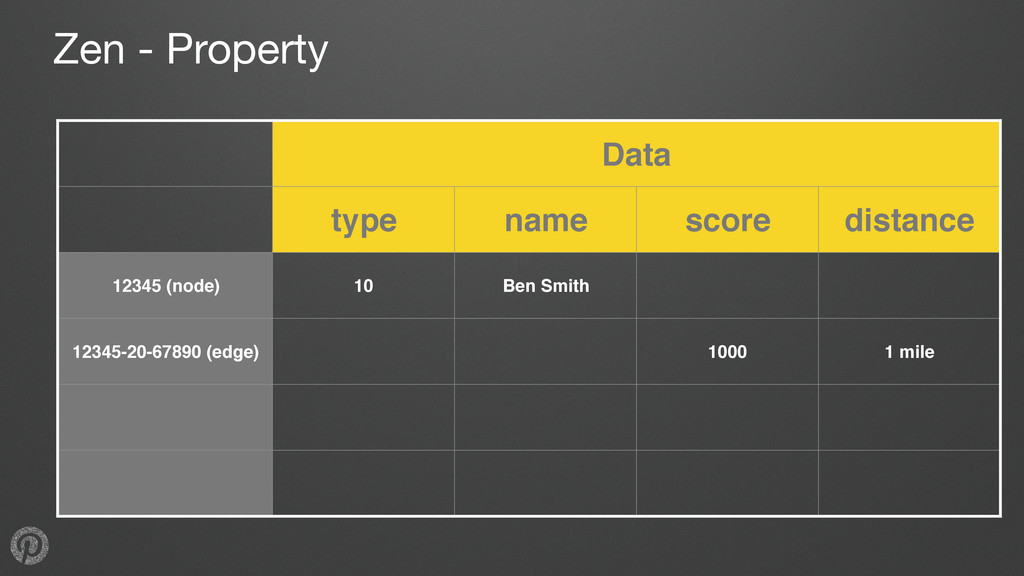
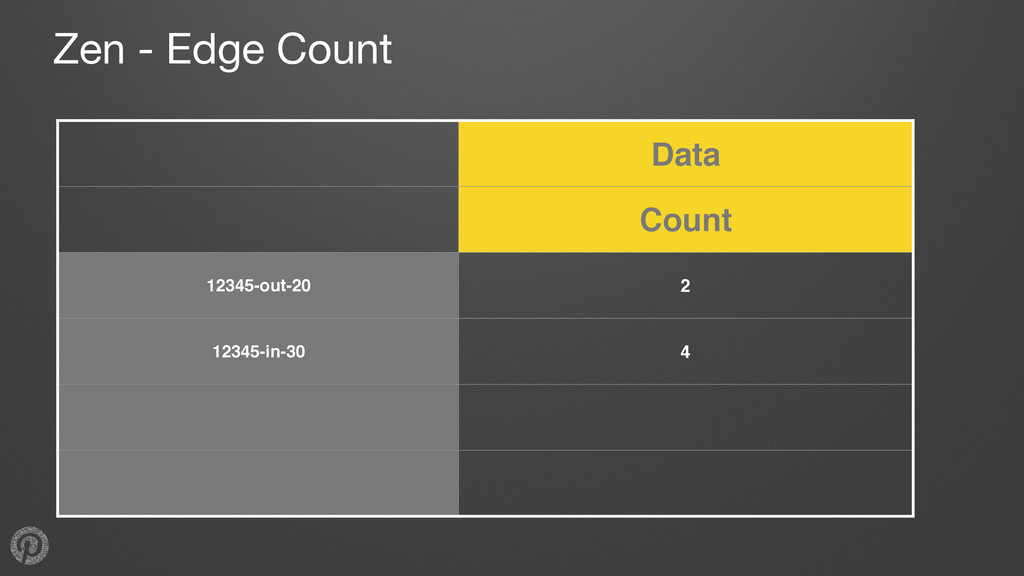
nodes, edges represent relationships •Typical needs: • retrieve data for a node or edge • get all outgoing edges from a node • get all incoming edges from a node • count incoming or outgoing edges for a node
interest graph and other upcoming features ! Numbers: • ~10 clusters • 100,000+ requests per second at peak • Over 5 million HBase operations per second
row and properties 2. CAS create the unique index if any 3. Create non-unique index if any 4. Create edge score index for outgoing direction 5. Create edge score index for incoming direction 6. Increment edge count for outgoing direction 7. Increment edge count for incoming direction
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}