Abstract
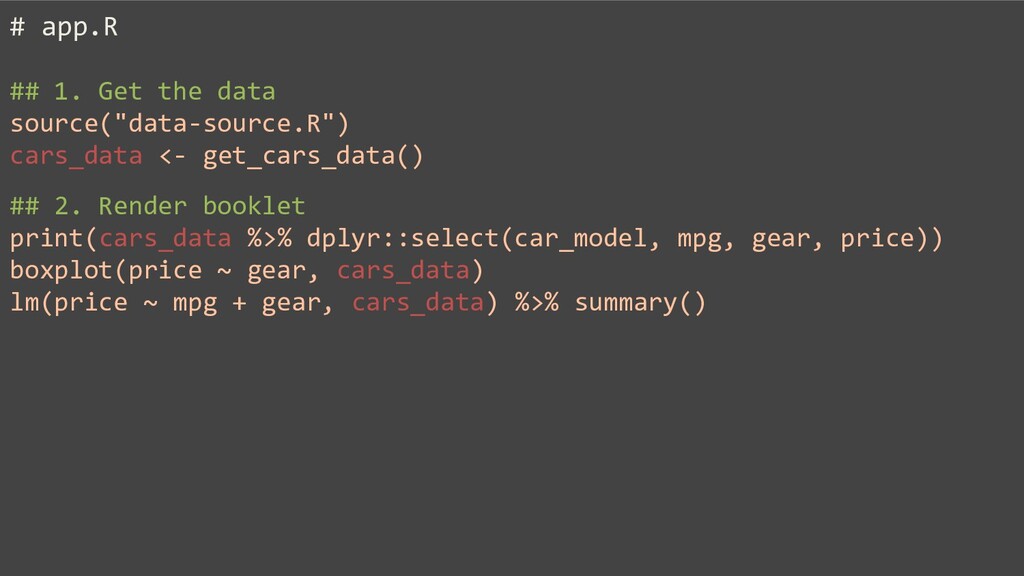
Data science projects in commercial companies often experience a challenge arising from evolving data sources. As the project progresses, new signals and information sources are added incrementally. In practice, when the data source changes, it creates a need to change the application source code.
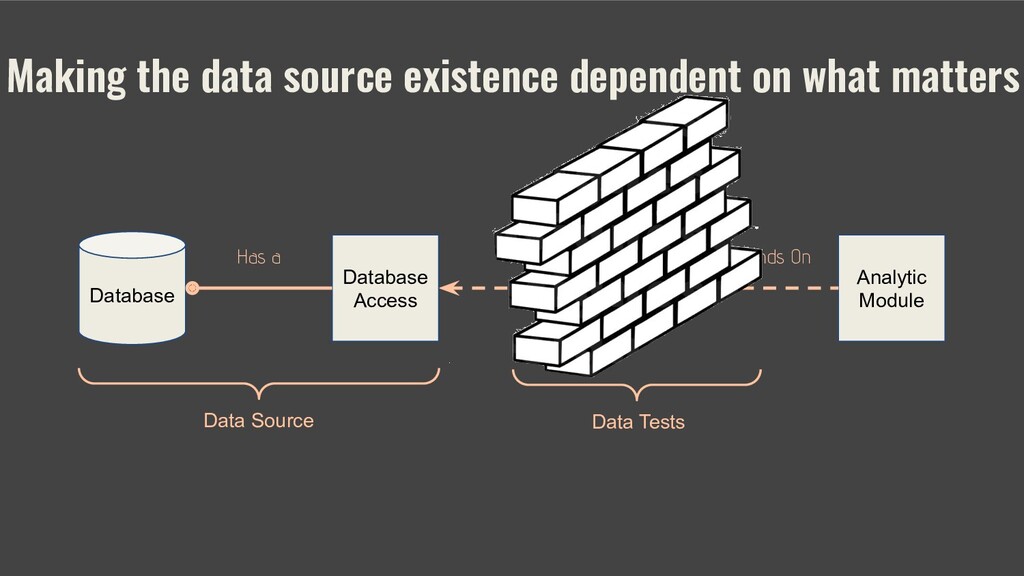
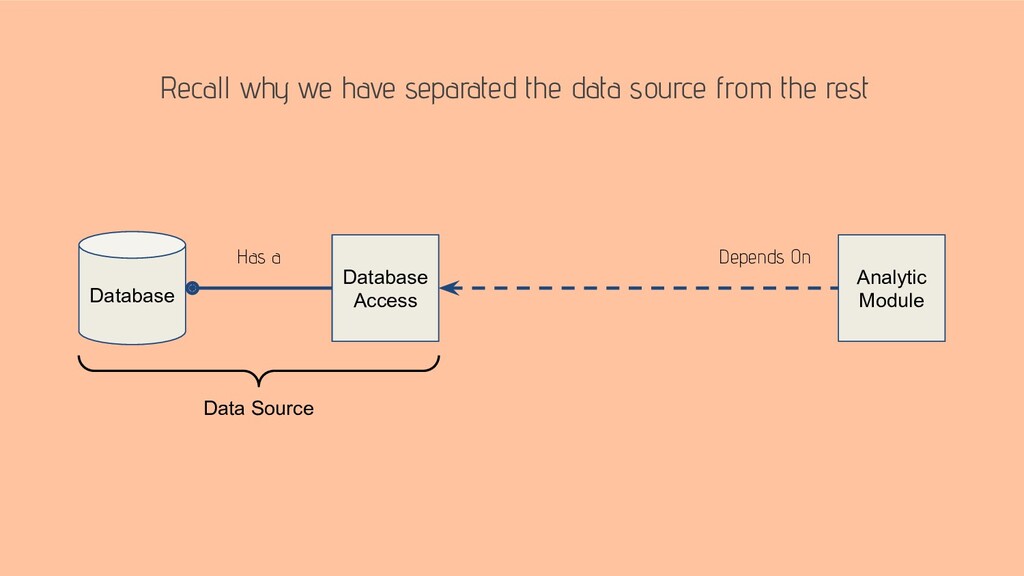
With no design up front, some application modules, such as a dashboard or a machine learning model, unwittingly become dependent on the data source. In this case, accommodating the evolving data source is not simply a matter of changing the code related to the data source. Rather, preserving the rest of the existing application in a working condition involves further code changes in distant elements of the application.
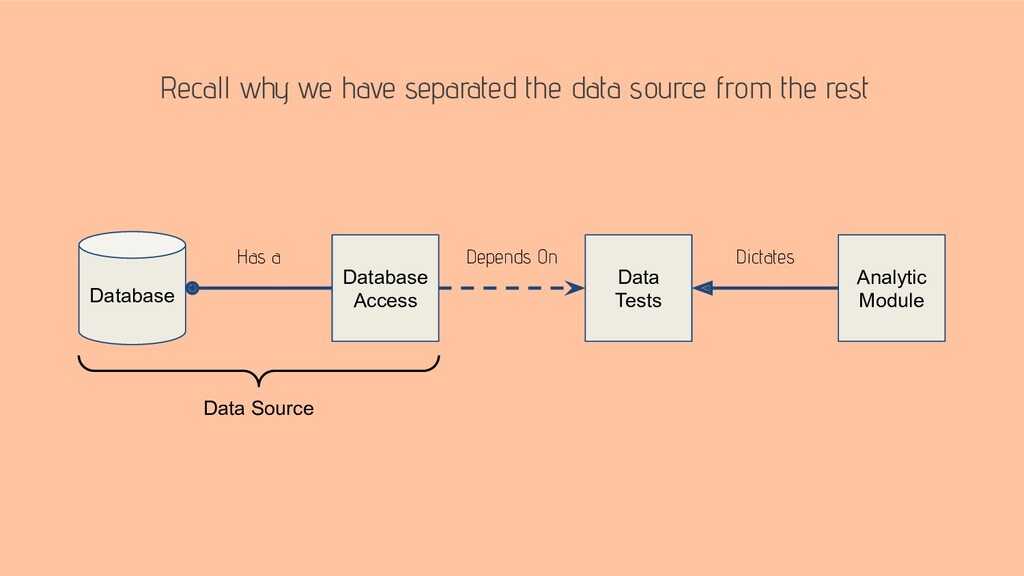
An alternative way of dealing with evolving data sources is to introduce a small design up front. Such design lets programmers manage the source code dependencies throughout the project life-cycle.
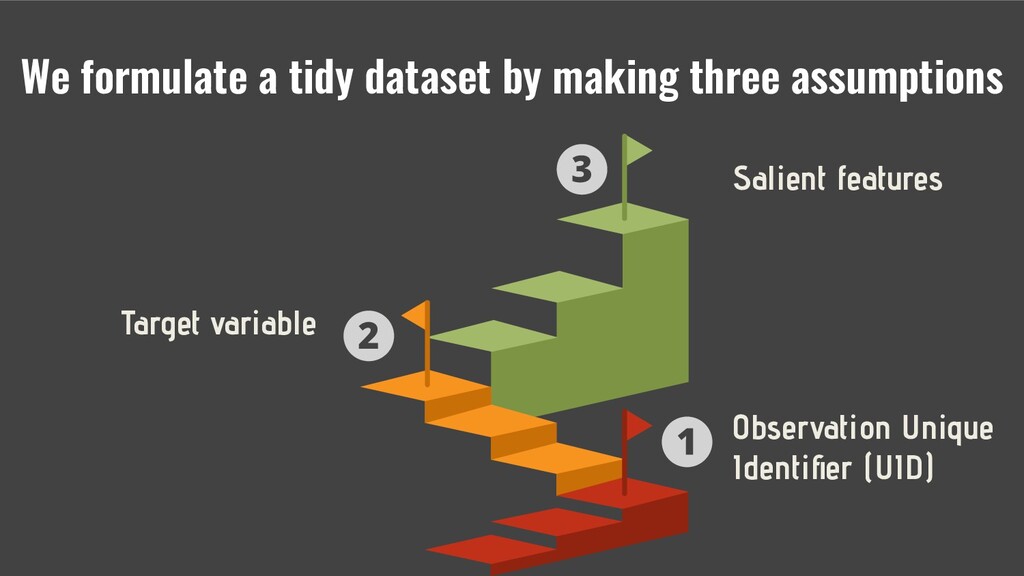
This talk suggests a design that (1) separates data sources from analytic applications and (2) restricts analytic applications from knowing about the data sources.
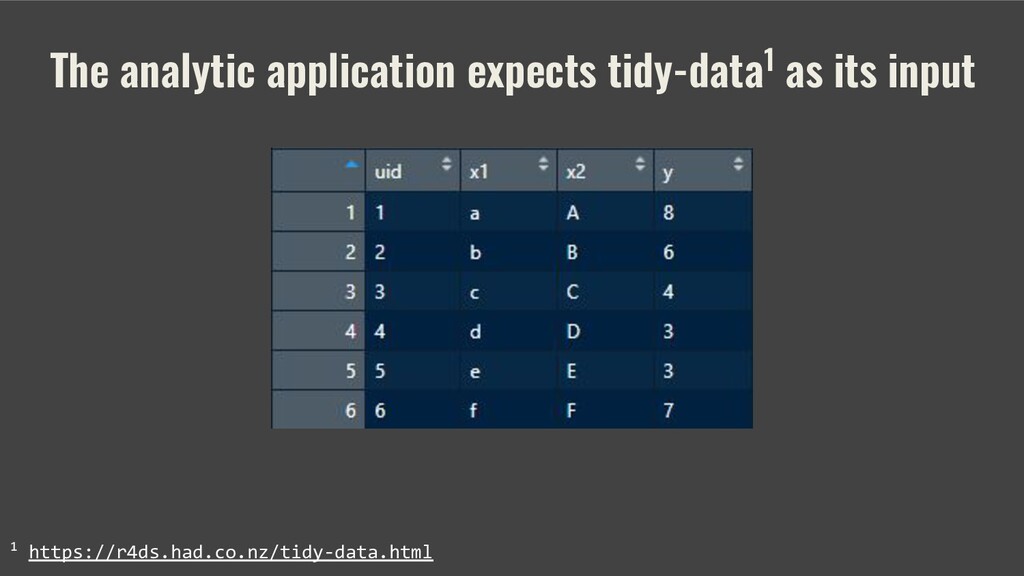
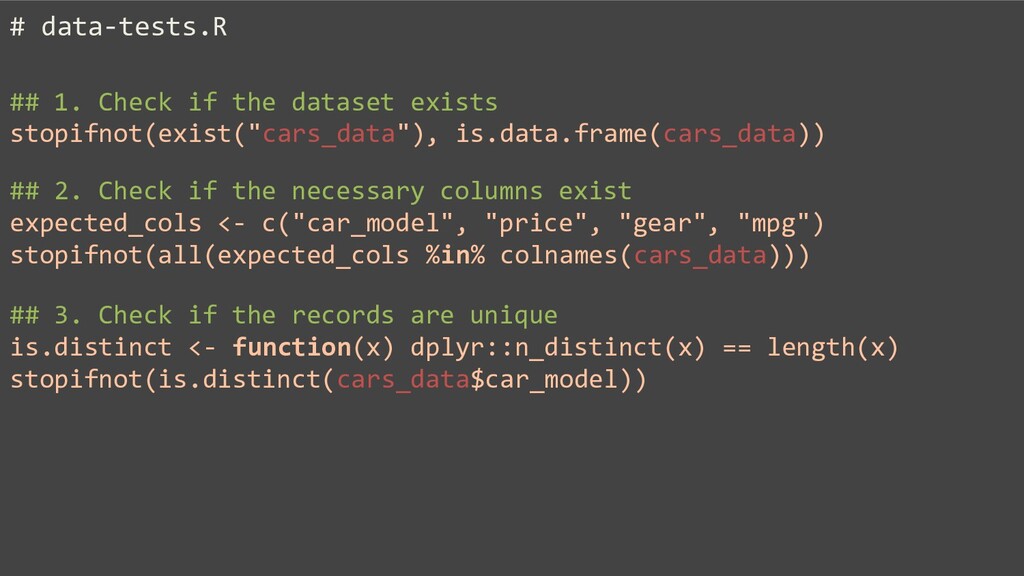
While the evolving data sources challenge is programming language agnostic, this talk demonstrates an implementation of the suggested design in R.
The takeaway of this talk is a design of a system, where data sources are plugins to the system’s analytic modules.
---
This presentation was given at satRday Auckland, February 2020.
See event details at https://auckland2020.satrdays.org/#portfolioModal7
{kind=link}
{kind=link}
![Insert 500 hundred lines here ggplot(Tog3[-c(1,28),], aes(Date,Rec2All, colour = isChina))+](https://files.speakerdeck.com/presentations/2bb90a1bae3b4cb381937fc92d4eeee1/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}