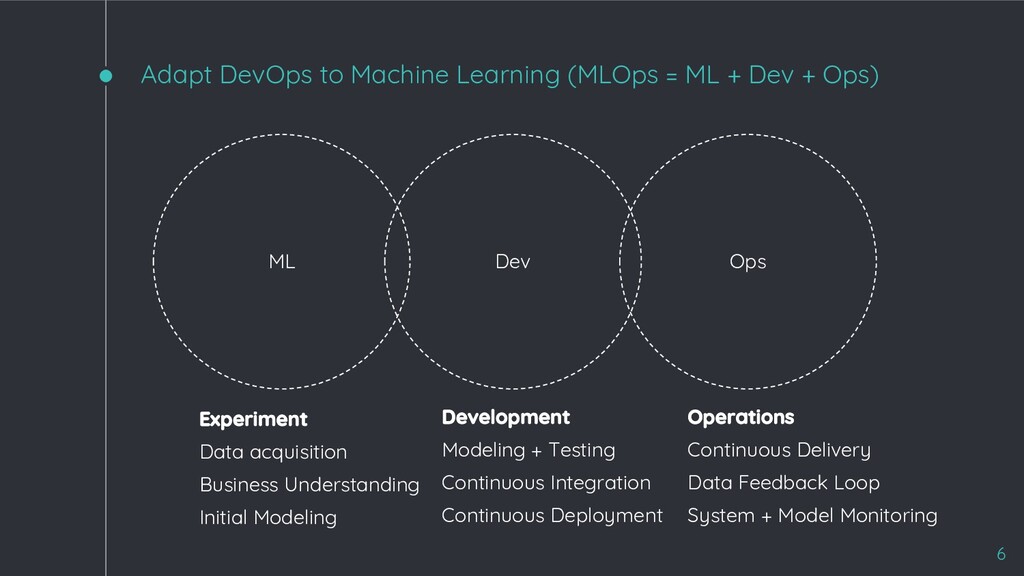
+ Ops) Dev ML Ops 6 Experiment Data acquisition Business Understanding Initial Modeling Development Modeling + Testing Continuous Integration Continuous Deployment Operations Continuous Delivery Data Feedback Loop System + Model Monitoring
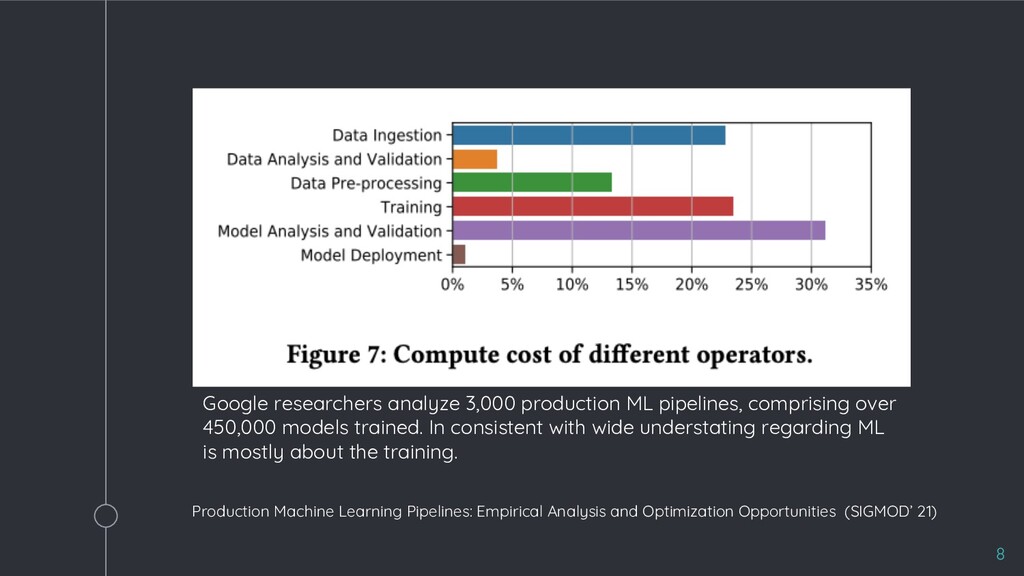
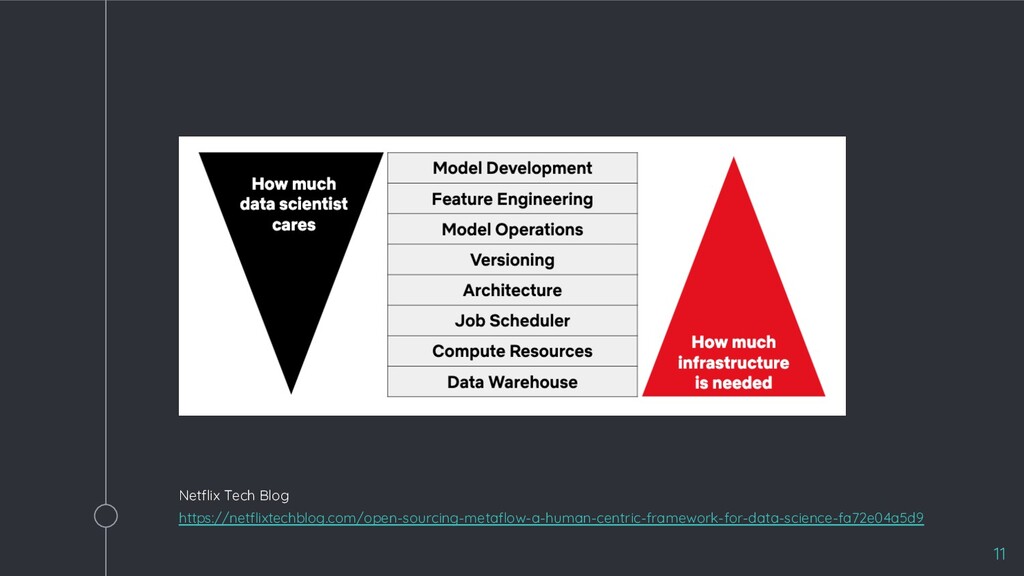
450,000 models trained. In consistent with wide understating regarding ML is mostly about the training. Production Machine Learning Pipelines: Empirical Analysis and Optimization Opportunities (SIGMOD’ 21)
The difference between performance during training and performance during serving ◦ Model Drift Ø The performance of a model deployed to production deteriorates on new, unseen data or the underlying assumptions about the data change 9
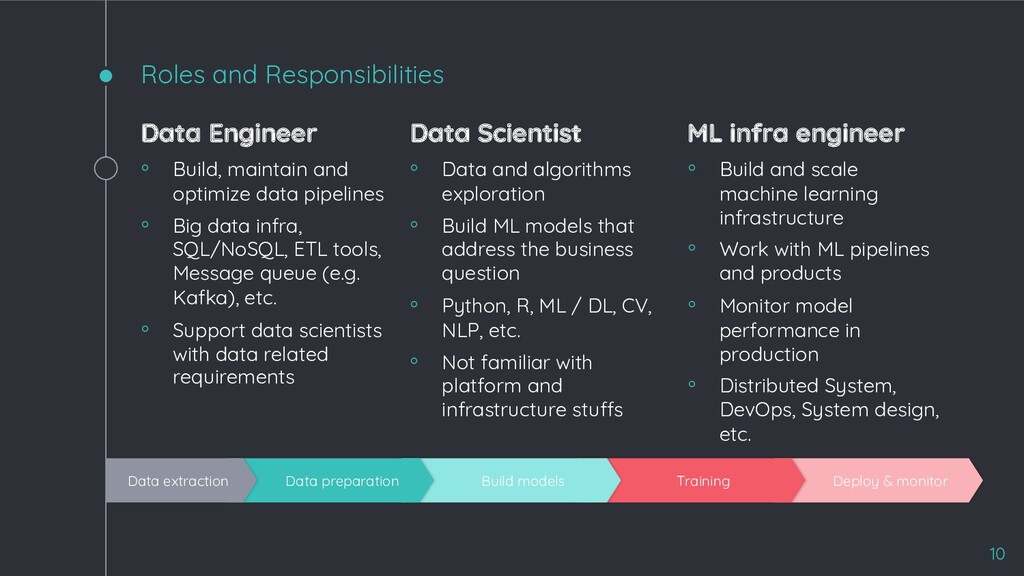
data pipelines ◦ Big data infra, SQL/NoSQL, ETL tools, Message queue (e.g. Kafka), etc. ◦ Support data scientists with data related requirements Data Scientist ◦ Data and algorithms exploration ◦ Build ML models that address the business question ◦ Python, R, ML / DL, CV, NLP, etc. ◦ Not familiar with platform and infrastructure stuffs ML infra engineer ◦ Build and scale machine learning infrastructure ◦ Work with ML pipelines and products ◦ Monitor model performance in production ◦ Distributed System, DevOps, System design, etc. 10 Deploy & monitor Training Build models Data preparation Data extraction
and analysis Ø Experiment using sampled dataset with notebooks or full dataset to get best results. ◦ Reproducible experiment Ø Record parameters, code and metrics of experiment Ø Dependency management, coding once, run everywhere ◦ Model management Ø Automated model packaging and delivery for easy deployment to production Ø Visibility into the performance of models 13
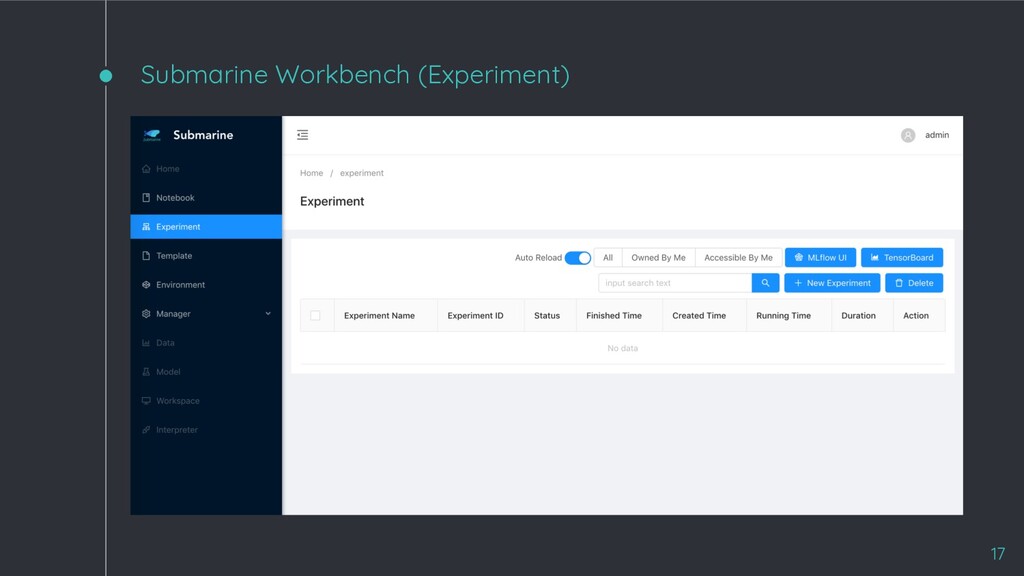
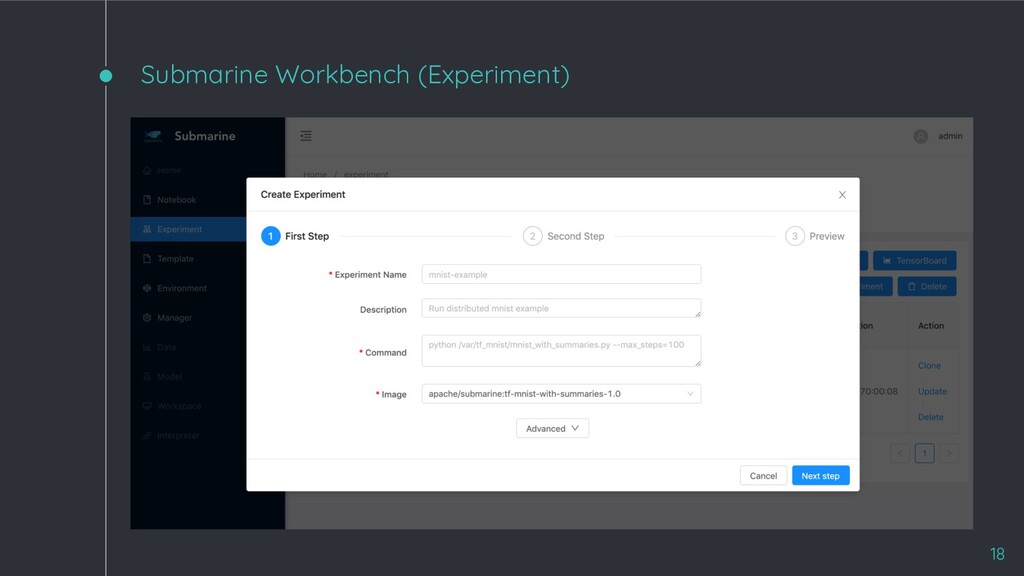
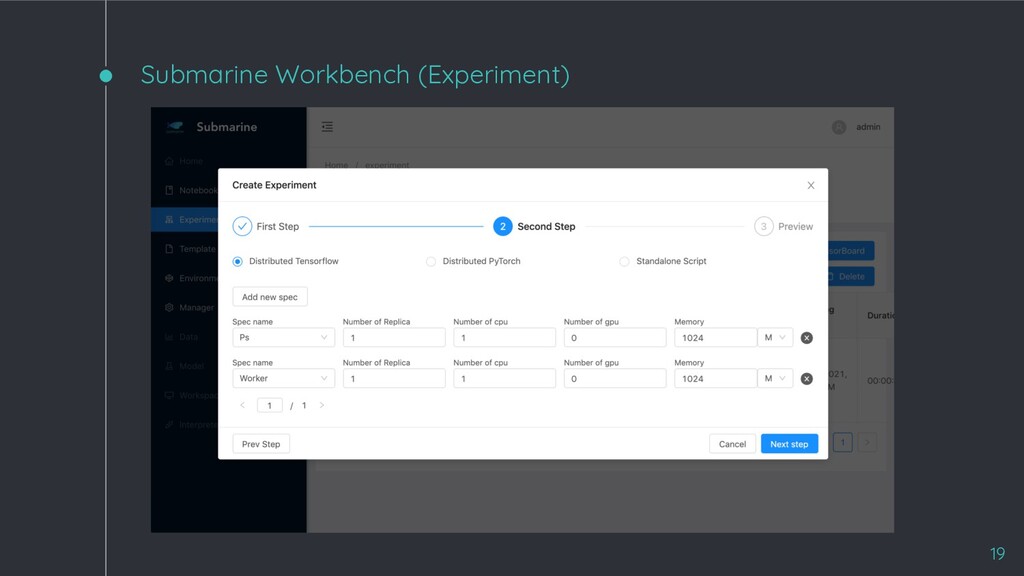
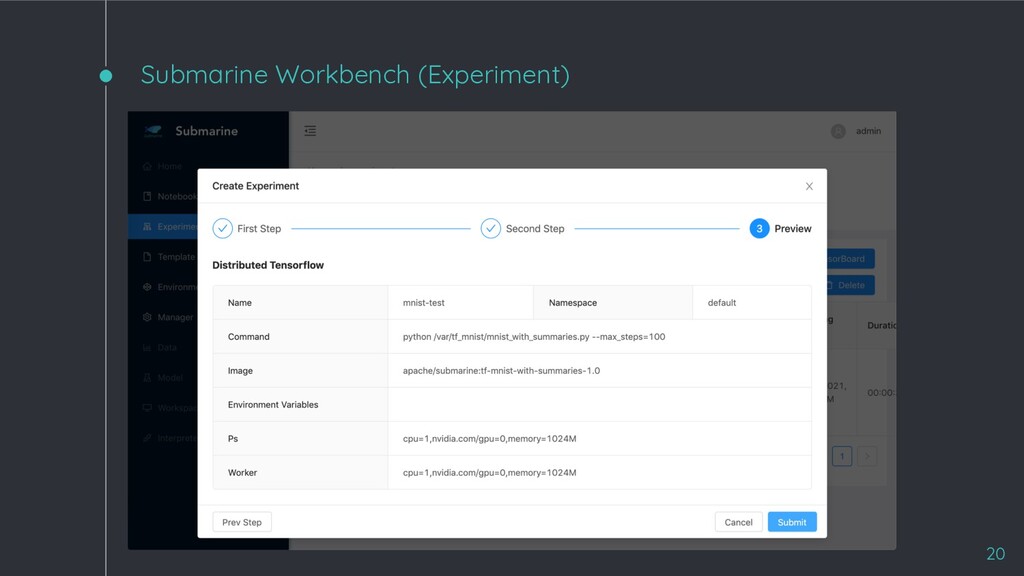
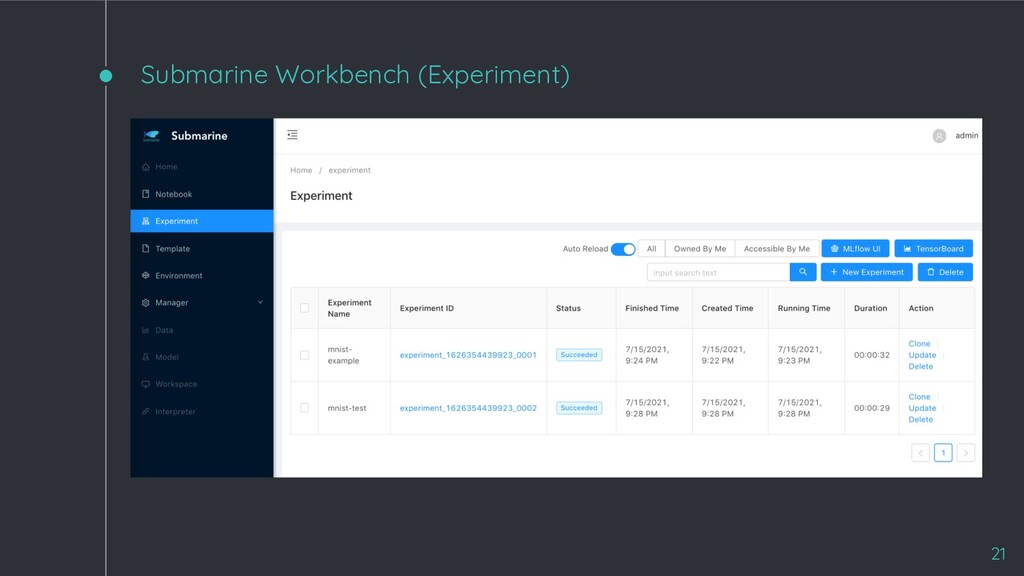
◦ Data scientists can create end-to-end ML workflows that cover each stage in ML model lifecycle. ◦ Easy for data scientists to manage versions of experiment and dependencies of environment. ◦ Support popular machine learning frameworks including PyTorch and TensorFlow. ◦ Run and track distributed training experiments via ease-to-use UI. ◦ Support Kubernetes/Hadoop YARN and many compute resources (e.g. CPU and GPU) 15
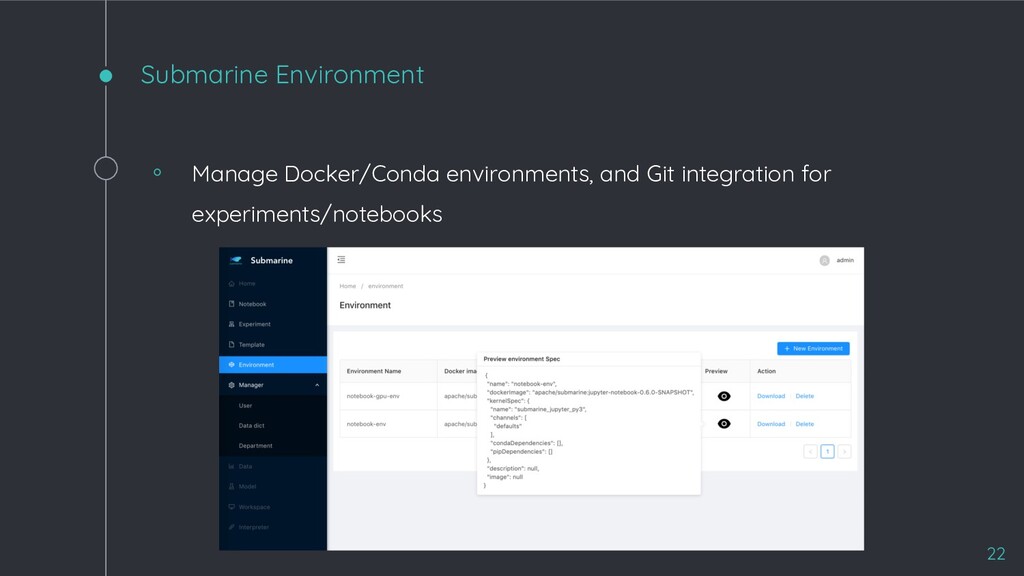
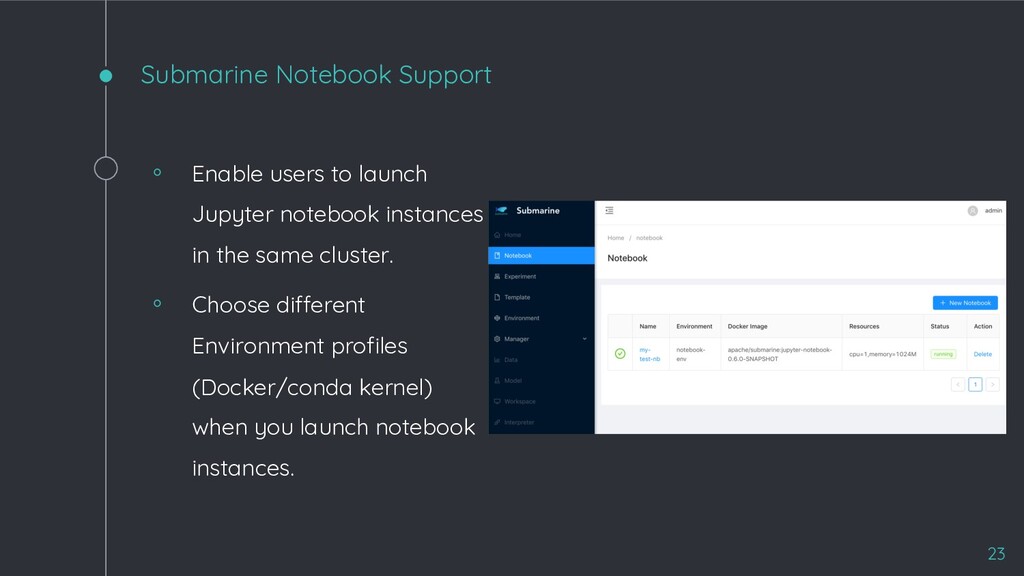
which enables users to run TensorFlow/PyTorch experiments from notebook. Environment Users can save different environment profile that define a set of libraries and a Docker image to run an experiment or a notebook instance. Notebook Enable users launch their own Jupyter Notebook instances in the same cluster. Easy Install Just one simple command to install Submarine on an existing K8s cluster with Helm. Model management Integrating with MLflow for tracking experiments and model registry. (coming soon) Web UI Submarine workbench provide a Data-Scientist-friendly UI to make data scientists have a good user experience. 16
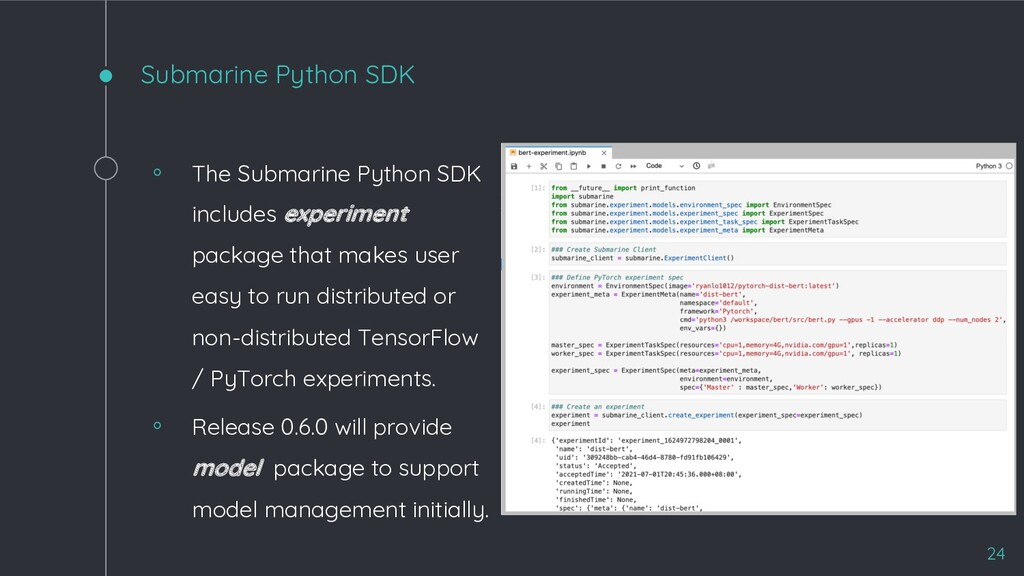
package that makes user easy to run distributed or non-distributed TensorFlow / PyTorch experiments. ◦ Release 0.6.0 will provide model package to support model management initially. 24
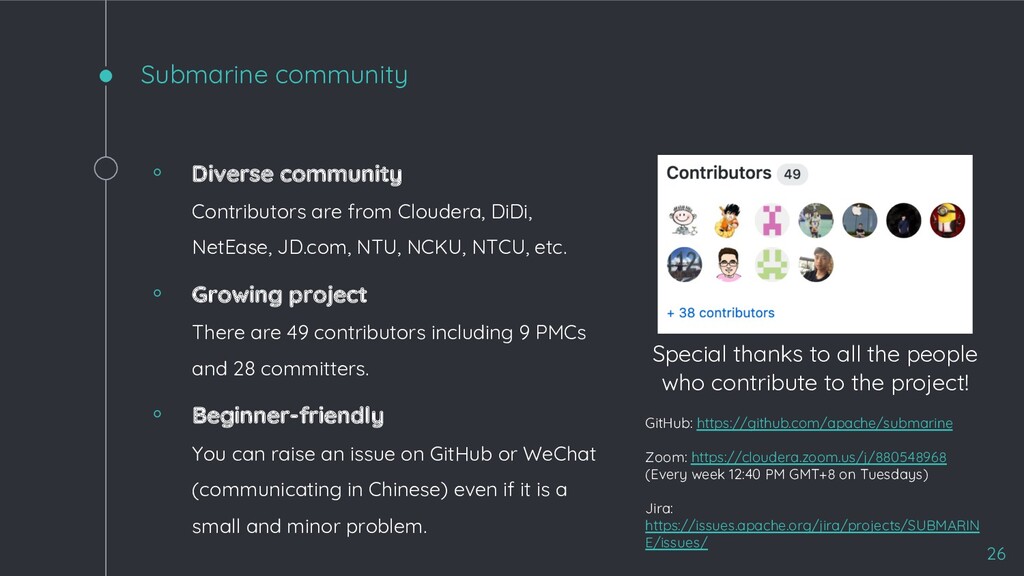
NetEase, JD.com, NTU, NCKU, NTCU, etc. ◦ Growing project There are 49 contributors including 9 PMCs and 28 committers. ◦ Beginner-friendly You can raise an issue on GitHub or WeChat (communicating in Chinese) even if it is a small and minor problem. 26 Special thanks to all the people who contribute to the project! GitHub: https://github.com/apache/submarine Zoom: https://cloudera.zoom.us/j/880548968 (Every week 12:40 PM GMT+8 on Tuesdays) Jira: https://issues.apache.org/jira/projects/SUBMARIN E/issues/
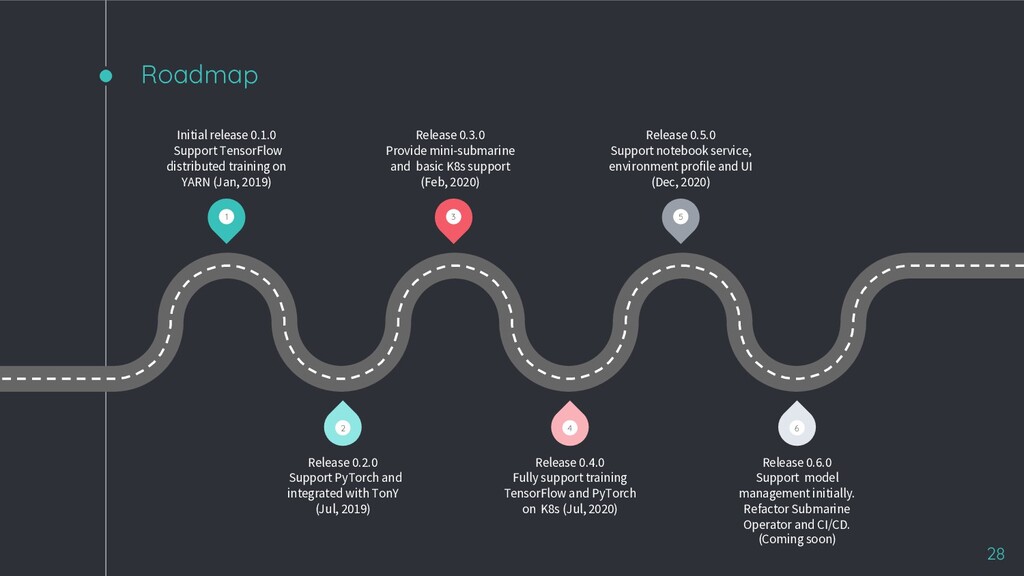
0.1.0 Support TensorFlow distributed training on YARN (Jan, 2019) Release 0.3.0 Provide mini-submarine and basic K8s support (Feb, 2020) Release 0.5.0 Support notebook service, environment profile and UI (Dec, 2020) Release 0.2.0 Support PyTorch and integrated with TonY (Jul, 2019) Release 0.4.0 Fully support training TensorFlow and PyTorch on K8s (Jul, 2020) Release 0.6.0 Support model management initially. Refactor Submarine Operator and CI/CD. (Coming soon)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}