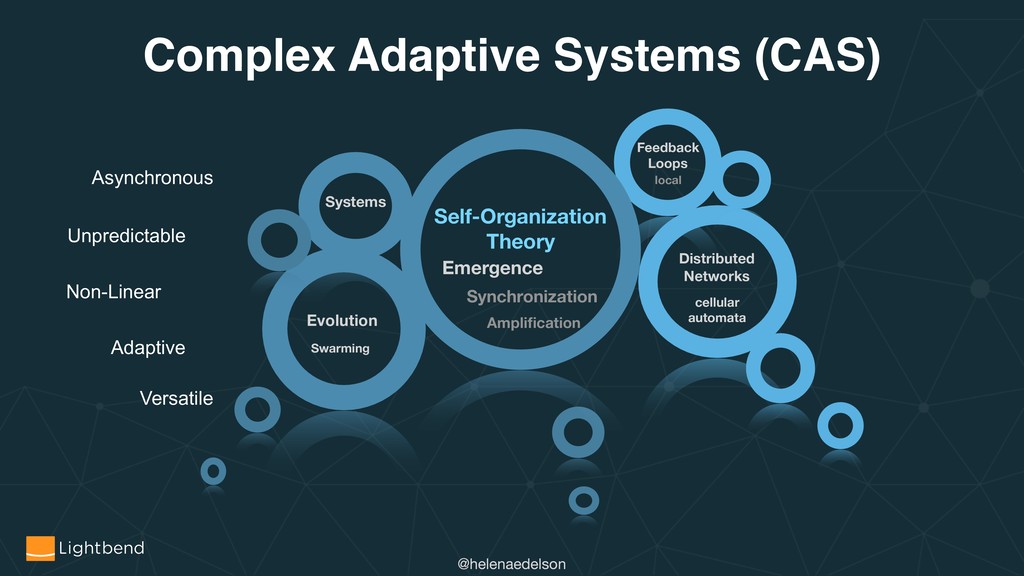
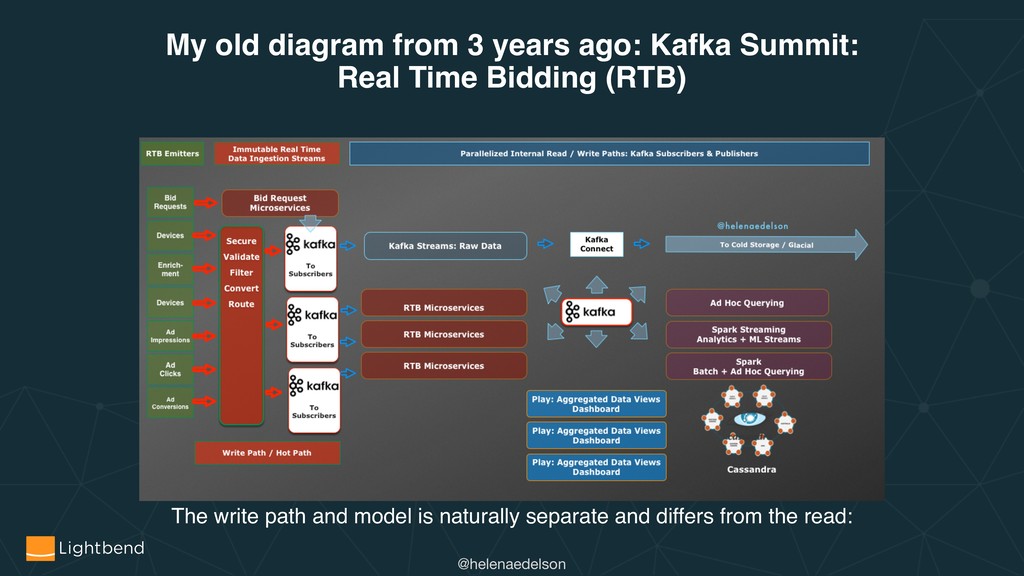
Data stream processing platforms and microservices platform infrastructure and strategies are converging. As we edge towards larger, more complex and decoupled systems, combined with the continual growth of the global information graph, our frontiers of unsolved challenges grow equally as fast. Central challenges for distributed systems include persistence strategies across DCs, zones or regions, network partitions, data optimization, system stability in all phases.
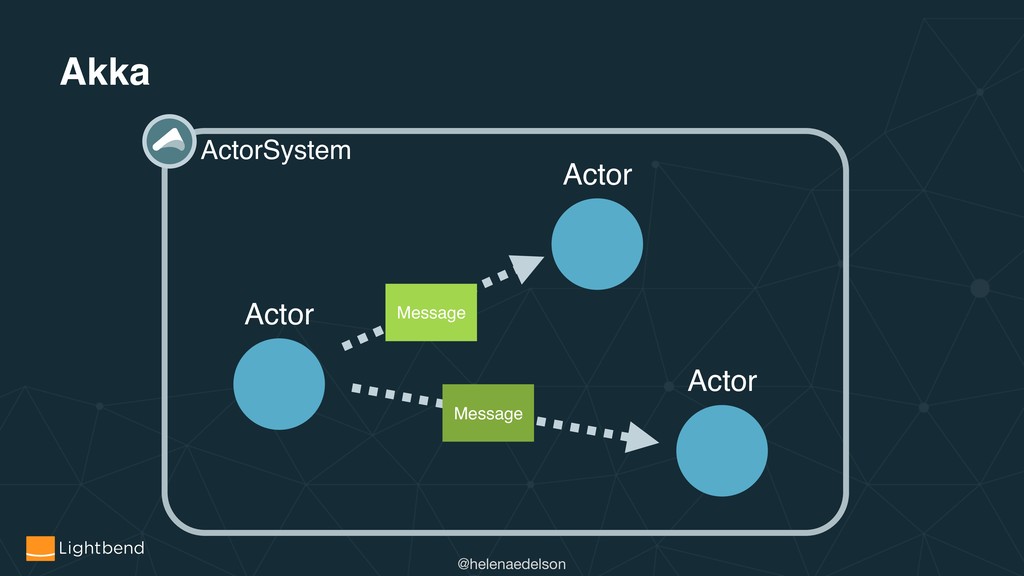
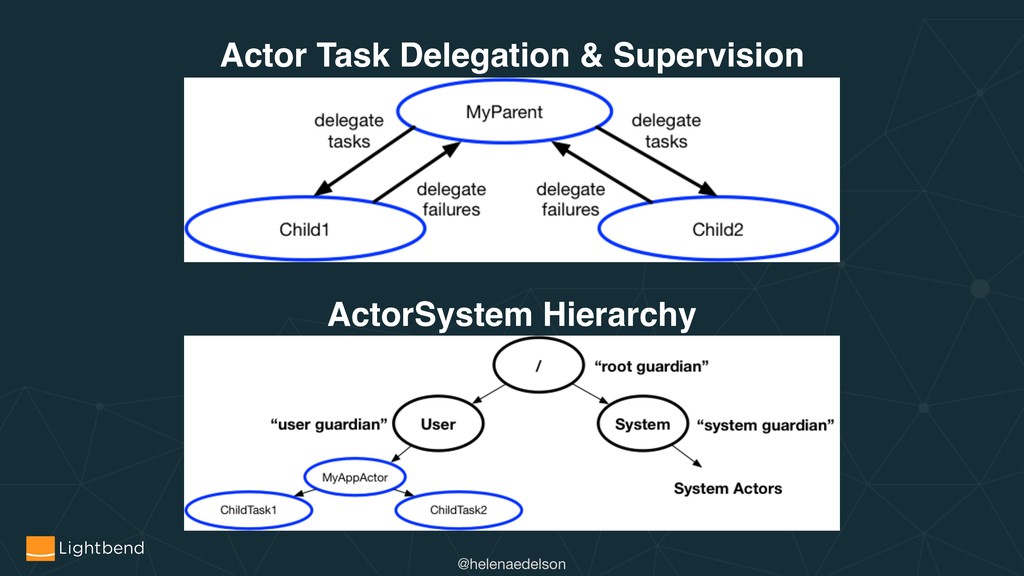
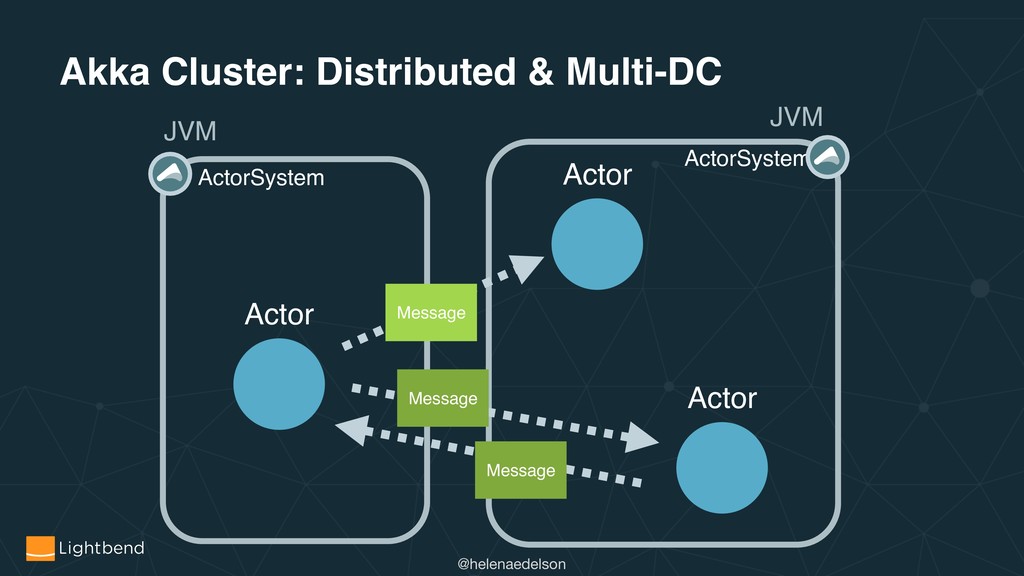
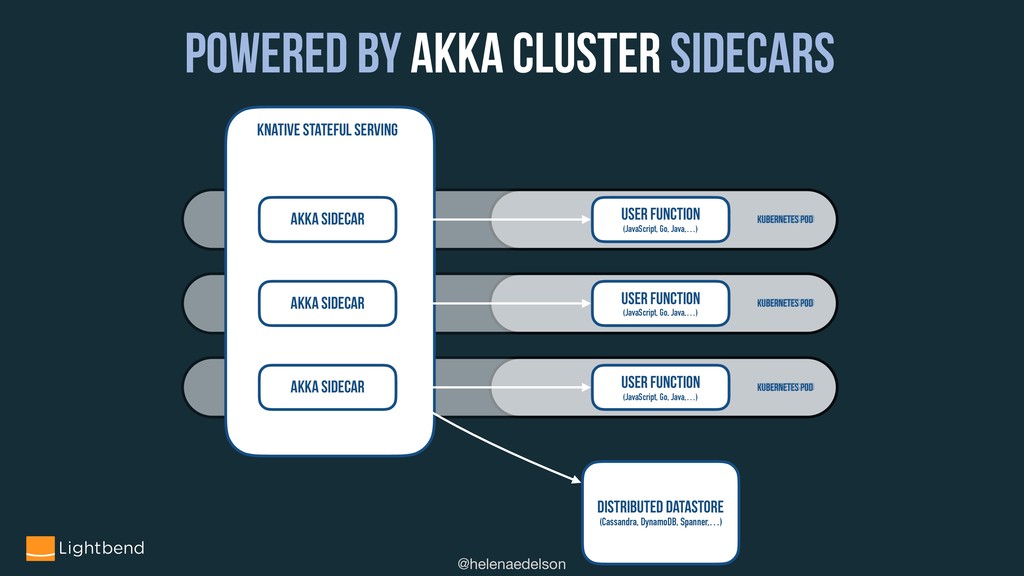
How does leveraging CRDTs and Event Sourcing address several core distributed systems challenges? What are useful strategies and patterns involved in the design, deployment, and running of stateful and stateless applications for the cloud, for example with Kubernetes. Combined with code samples, we will see how Akka Cluster, Multi-DC Persistence, Split Brain, Sharding and Distributed Data can help solve these problems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@helenaedelson [api] [api] [worker, backend] [worker] [worker] Cluster Roles](https://files.speakerdeck.com/presentations/94942411af03421facdee38c6c76afea/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
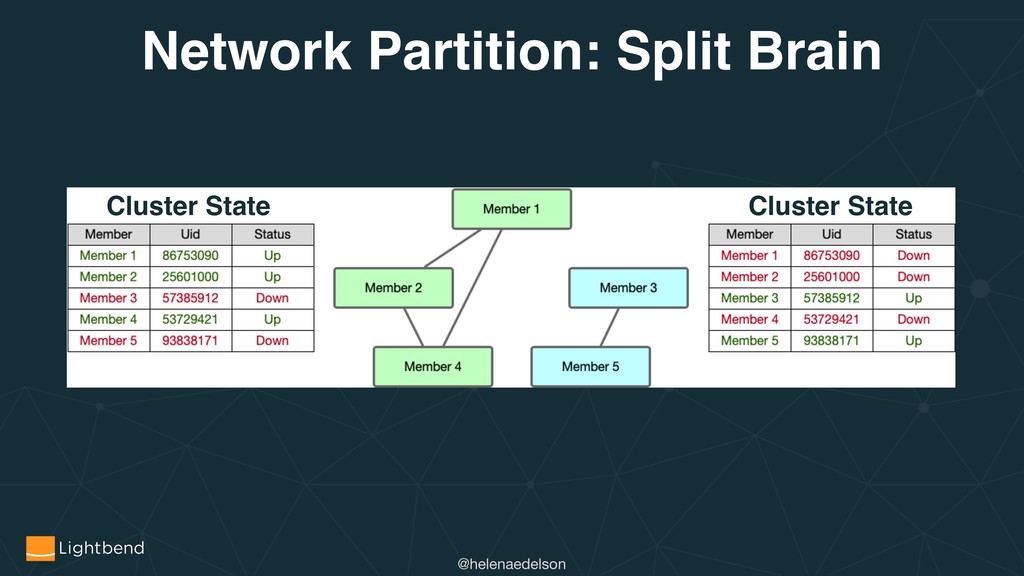{kind=link}
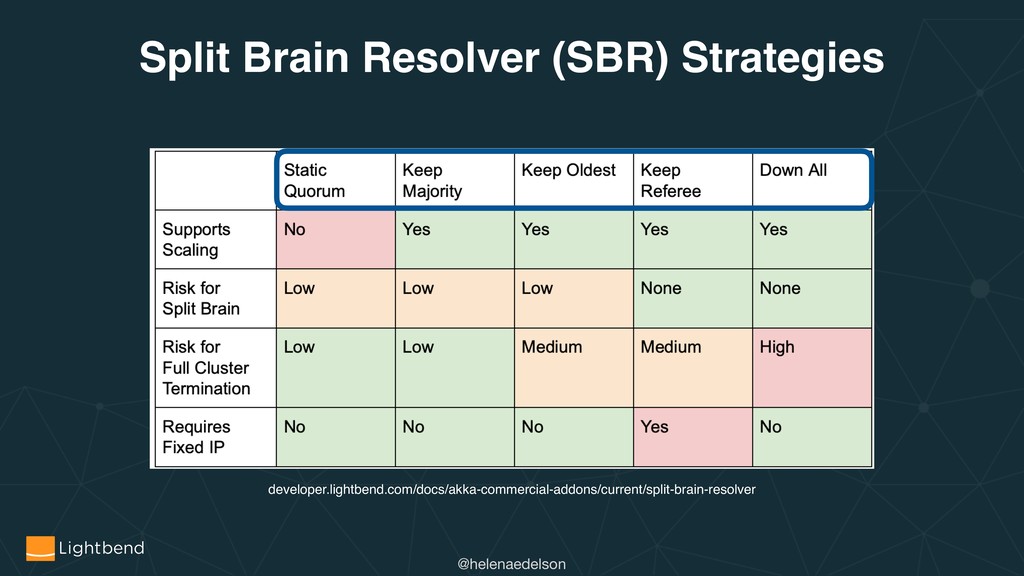{kind=link}
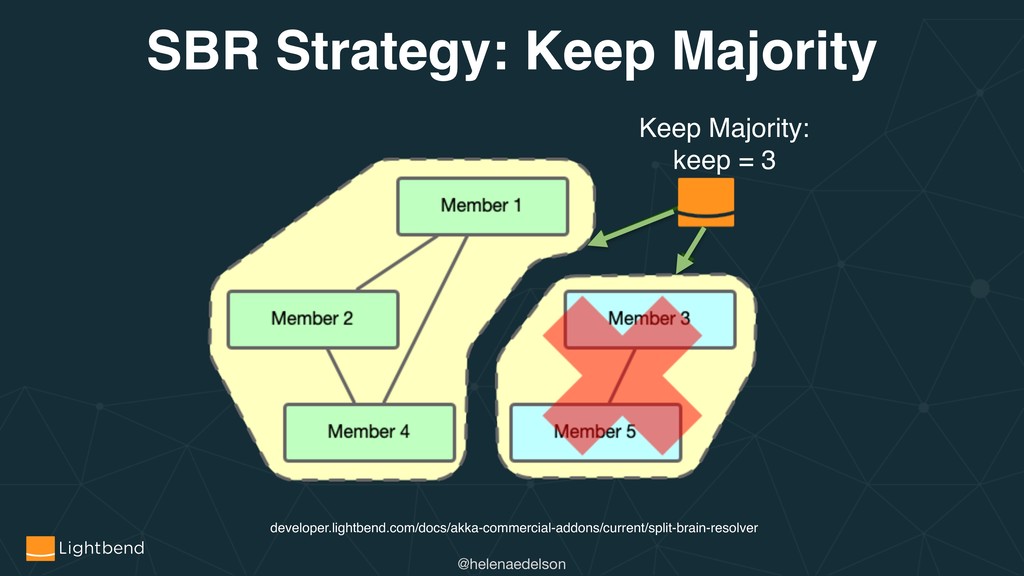{kind=link}
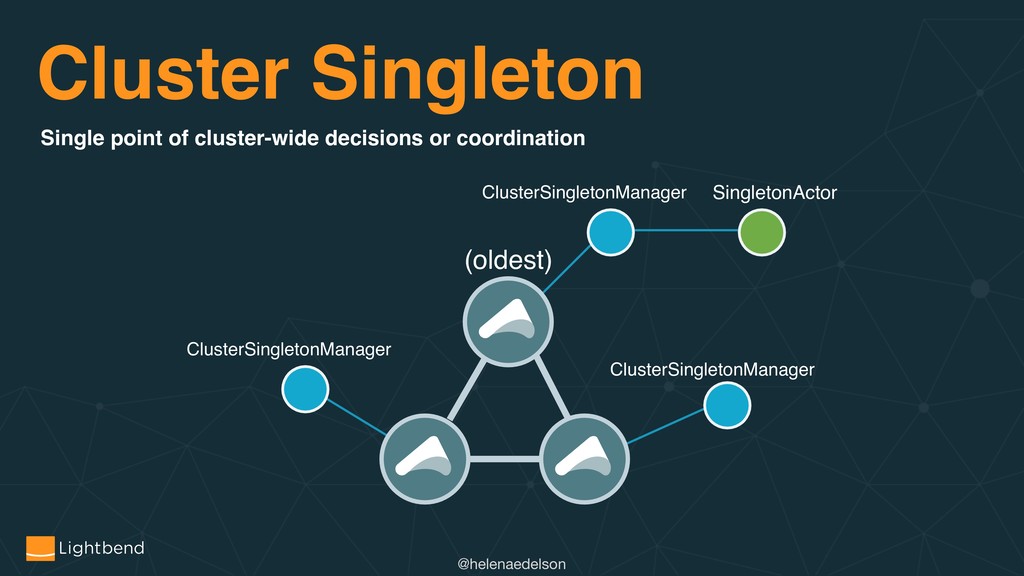{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
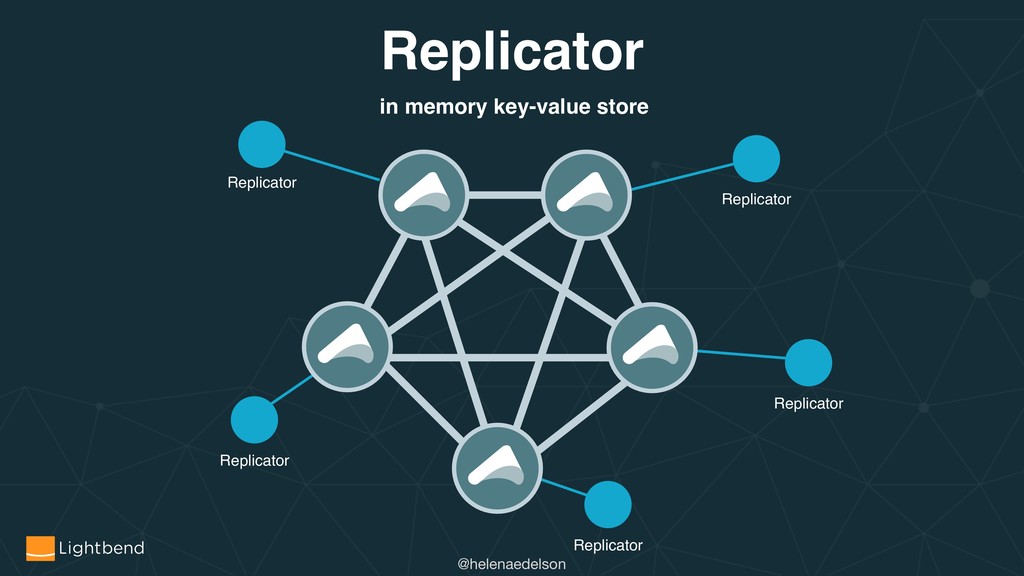{kind=link}
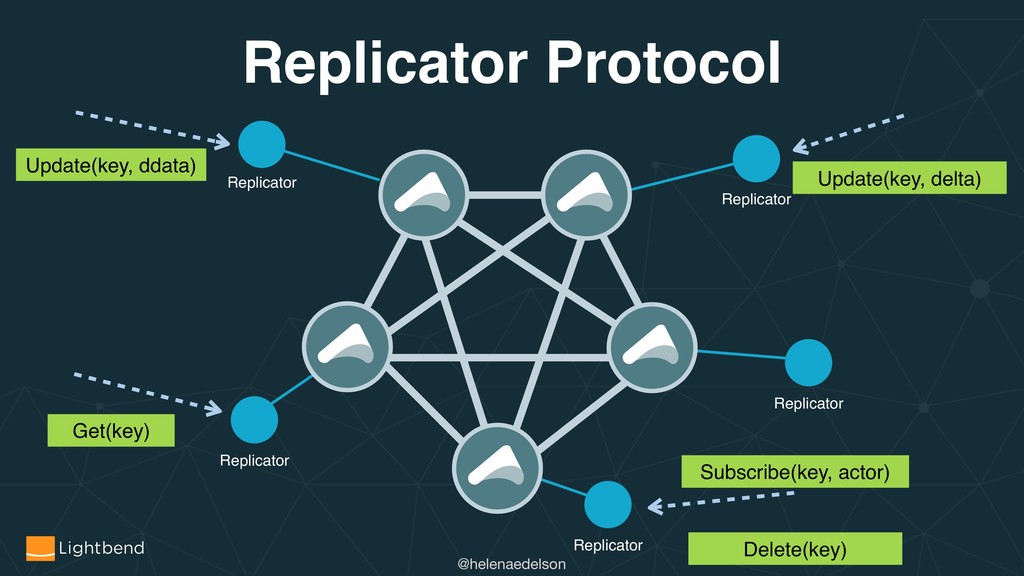{kind=link}
{kind=link}
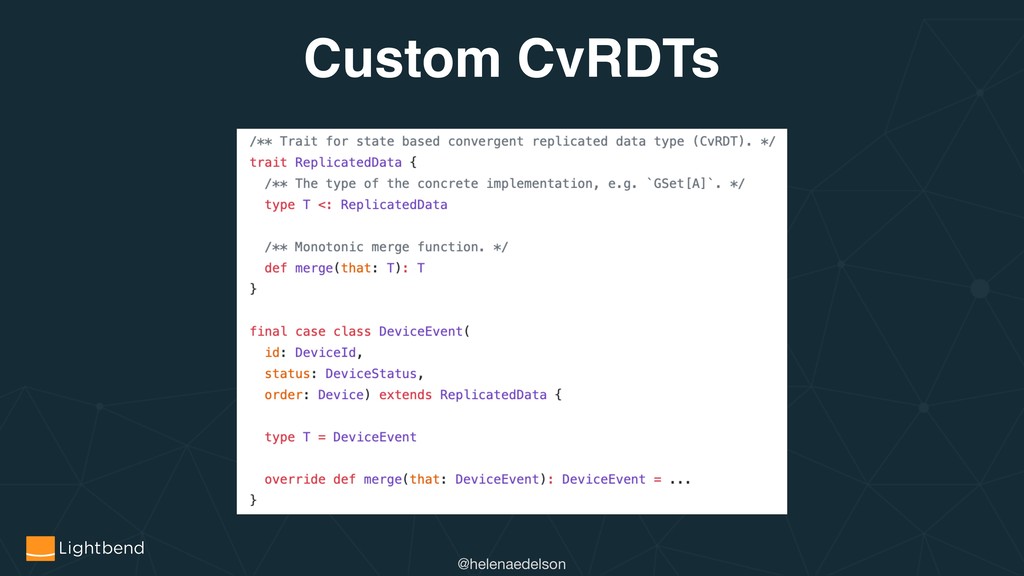{kind=link}
{kind=link}
{kind=link}
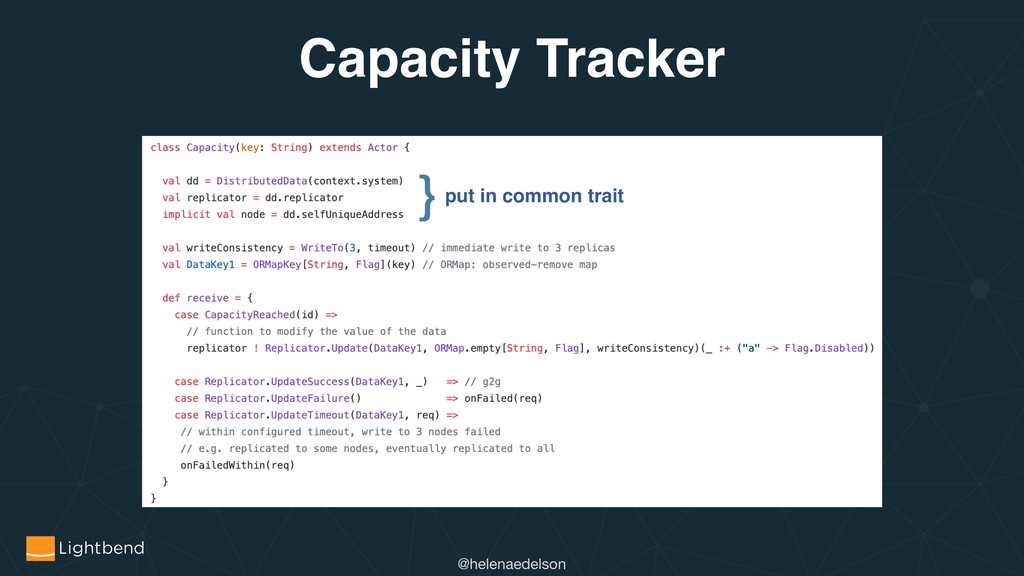{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}