Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データエンジニアリング 4年前と変わったこと、 4年前と変わらないこと
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Sotaro Tanaka
July 18, 2025
Technology
1k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データエンジニアリング 4年前と変わったこと、 4年前と変わらないこと
Sotaro Tanaka
July 18, 2025
More Decks by Sotaro Tanaka
See All by Sotaro Tanaka
ABEMAはなぜセマンティックレイヤーに挑戦しているのか?
tanakarian
0
1.4k
データ基盤の○層構造を独り歩きさせない データモデリング設計 Data Ops Night #1
tanakarian
3
5.9k
dbtを活用したデータ基盤の 論理・物理設計の現在地と振り返り / data warehouse logic design by using dbt
tanakarian
8
16k
データ分析基盤の障害を未然に防ぐためのチェックリスト / checklist for preventing incidents of data management system
tanakarian
1
14k
データの価値を失わないためのData Reliability
tanakarian
7
12k
building-evolutionary-data-warehouse
tanakarian
2
11k
Other Decks in Technology
See All in Technology
文字起こし基盤の信頼性
abnoumaru
0
150
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
700
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
1.3k
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
180
カメラ×AIで挑む「ホワイト物流」― 車両管理、自動化の壁と突破口【SORACOM Discovery 2026】
soracom
PRO
0
140
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
210
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
210
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
170
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
15
5.9k
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
460
Jitera Company Deck
jitera
0
620
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
30
17k
Featured
See All Featured
Crafting Experiences
bethany
1
230
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
780
Building AI with AI
inesmontani
PRO
1
1.1k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Design in an AI World
tapps
1
270
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
A Soul's Torment
seathinner
6
3.1k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Transcript
AbemaTV, Inc. All Rights Reserved 1 データエンジニアリング 4年前と変わったこと、 4年前と変わらないこと 2025/07/18
#DES 株式会社AbemaTV Sotaro Tanaka @__sotaron__
AbemaTV, Inc. All Rights Reserved Sotaro Tanaka 株式会社AbemaTV Development HQ
Data div. Data Enabling Team Mgr • 2023/04~ ABEMAでデータマネジメント • Data Management & BI • Data Engineering • Hobby: 🏂 / 🎮 / ⚽ / 小倉唯さん 2 Profile X(旧Twitter) @__sotaron__
AbemaTV, Inc. All Rights Reserved 3 ABEMAのご紹介
AbemaTV, Inc. All Rights Reserved 4 ※ 投資家向け資料 より
AbemaTV, Inc. All Rights Reserved ABEMA 紹介 5 複数デバイス対応・多彩なチャンネルラインナップ
AbemaTV, Inc. All Rights Reserved 今日お話すること 6 4年前、DES#11でdbtを活用したデータセット設計やモデリングについて、お話しました。 4年経ち、データエンジニアを取り巻く技術は大きく変わったものもあれば、変わらないものあります。 その中で、私個人が特に重要と思う「変わったこと・変わらないこと」についてお話しようと思います。
※ LTなので、網羅的な話題よりも、私自身が主観的に言及したい点や自身の考えについて話します。 ※ テキスト多めです。
AbemaTV, Inc. All Rights Reserved 7 4年前に話したこと
AbemaTV, Inc. All Rights Reserved 4年前はこんな話をしました
AbemaTV, Inc. All Rights Reserved 9 4年前と変わったこと
AbemaTV, Inc. All Rights Reserved 10 生成AI!!
AbemaTV, Inc. All Rights Reserved 11 とにかく 生成AI!!
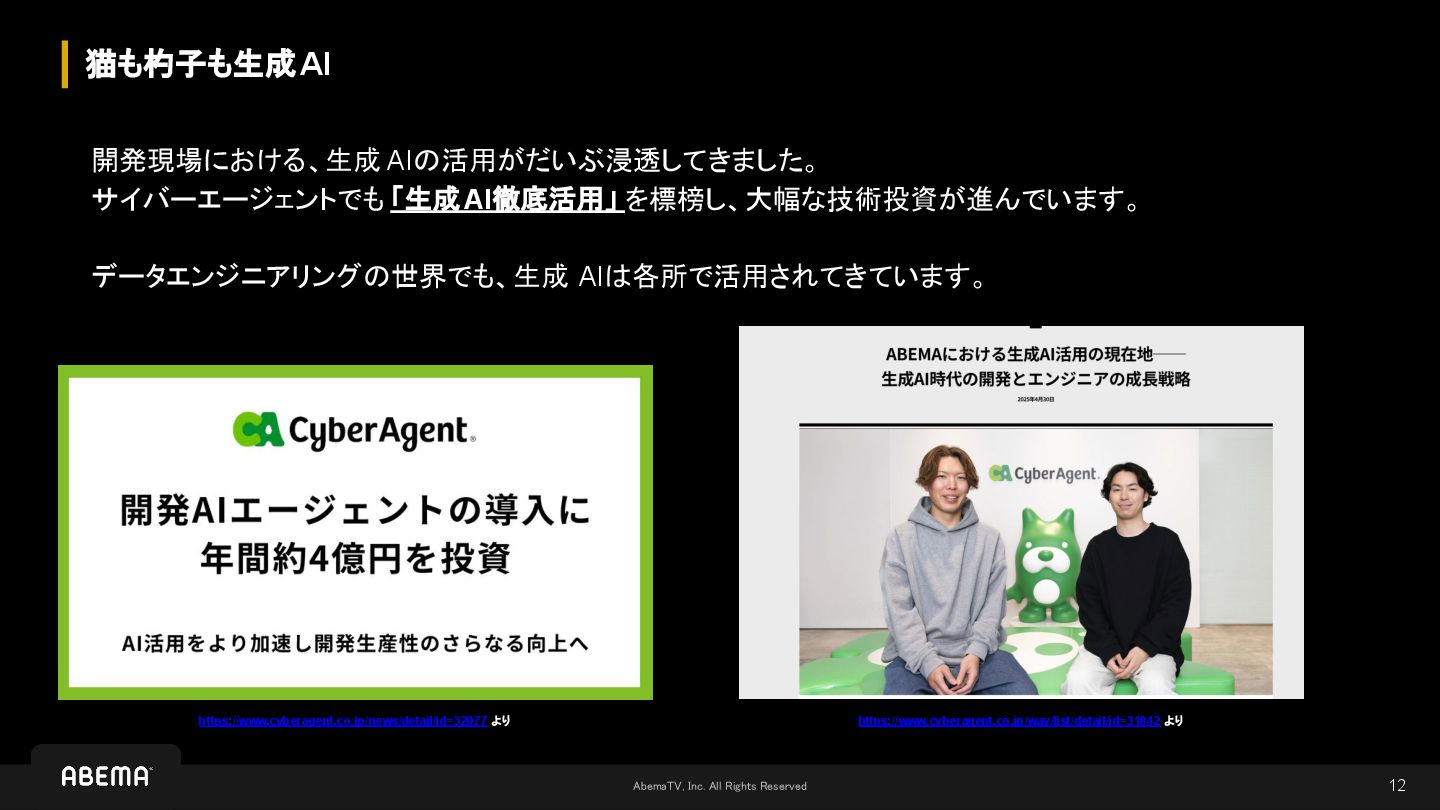
AbemaTV, Inc. All Rights Reserved 猫も杓子も生成AI 12 開発現場における、生成 AIの活用がだいぶ浸透してきました。 サイバーエージェントでも
「生成AI徹底活用」 を標榜し、大幅な技術投資が進んでいます。 データエンジニアリングの世界でも、生成 AIは各所で活用されてきています。 https://www.cyberagent.co.jp/news/detail/id=32077 より https://www.cyberagent.co.jp/way/list/detail/id=31842 より
AbemaTV, Inc. All Rights Reserved 生成AIで変わる「前提」 13 生成AIの活用浸透により、以前ほど気にする必要がなくなったこと • 重厚長大な
SQLクエリを書く、保守するコスト • 似たようなクエリ、テーブルを量産するコスト ◦ ガバナンスの問題は定義共通化したセマンティックレイヤー等でカバーする前提で • 分析者のメンタルモデルを強く意識して設計されたデータセットのレイヤリング などなど
AbemaTV, Inc. All Rights Reserved 14 生成AI「前提」での データ基盤を考えていく時代に
AbemaTV, Inc. All Rights Reserved 15 4年前と変わらないこと
AbemaTV, Inc. All Rights Reserved 4年前と変わらない「大事なこと」 16 4年前から変わらず、むしろ生成 AI時代にこそ、より重要そうなこと。 •
とりあえず分析、活用したいデータが全部データレイクにあること • 全部データレイクにある上でのアクセスコントロールと難読化 ◦ 各生成AIツールから、共通アカウントを使ってデータ読み出しとか最悪 • データセットのレイヤとルール • セマンティックとデータ品質 • ログ/マスタ設計とデータ仕様ドキュメント(無から有を生み出すところ) 最初2つは自明なので、他 3つについて、少し話します。
AbemaTV, Inc. All Rights Reserved データセットのレイヤとルール 17 分析者や活用者のメンタルモデルを意識した過度なレイヤリングは必要なくなりましたが、 以下のようなことを考慮した処理ルールと、その前後のデータセットのレイヤ分けはより一層重要に。 •
ある権限ロールの人たちに開放するデータセットに施すべき難読化処理 • 入力値の値域の制限、異常値の除去 • 汎用共通処理 → この処理ルールとデータセットのレイヤを CursorやClaude Codeに開発ガイドラインとして 渡せば、分析や活用 readyなテーブル群を作ってもらえます。
AbemaTV, Inc. All Rights Reserved セマンティックとデータ品質 18 ABEMAは来年で10周年、そんな10年ものプロダクトともなると • 空の定義(
NULL、undefined、n/a、””)のブレなど、ドキュメント化しないと理解できないデータモ デル • 多態・多義なカラムや歴史的に情報量が変化しているカラム みたいなデータがいっぱいあります。皆さんはどうですか? このようなデータが存在する状態で、「とりあえず生成 AIだ!text2sqlやってみよう!」とか 上手くいくわけがありません。 これらのデータ特性を考慮した人間による事前処理や、事前処理の指示ドキュメントが必要です。
AbemaTV, Inc. All Rights Reserved セマンティックとデータ品質 19 指標の定義については、生成 AIに勝手に定義されても困ります。 ABEMAの例で考えてみると、ユーザーが「みた」ことをどう定義・表現するのか。
重要シーンをみたこと?みた時間が一定以上だったら? 遠藤航選手のプレミア初ゴールシーン ここから重要シーン 14分36秒視聴
AbemaTV, Inc. All Rights Reserved 補足:「視聴」の指標化は難しい 20 ABEMAのコアドメインである「視聴」の指標化は、特にデータモデリングの腕が試されます。 以下のようなことを考えたモデル化が必要。 一つの単純な指標では表現しきれない「視聴」という概念の捉え難さ。
視聴形態 コンテンツジャンル ユーザーステータス テレビ / ビデオ / ライブという複数の視聴形態 スポーツとアニメでは、「見た」として捉えるべき ユーザー行動が異なるのでは?など ユーザーの課金ステータスによっては、 広告再生時点まで視聴しているかどうか、が重要など
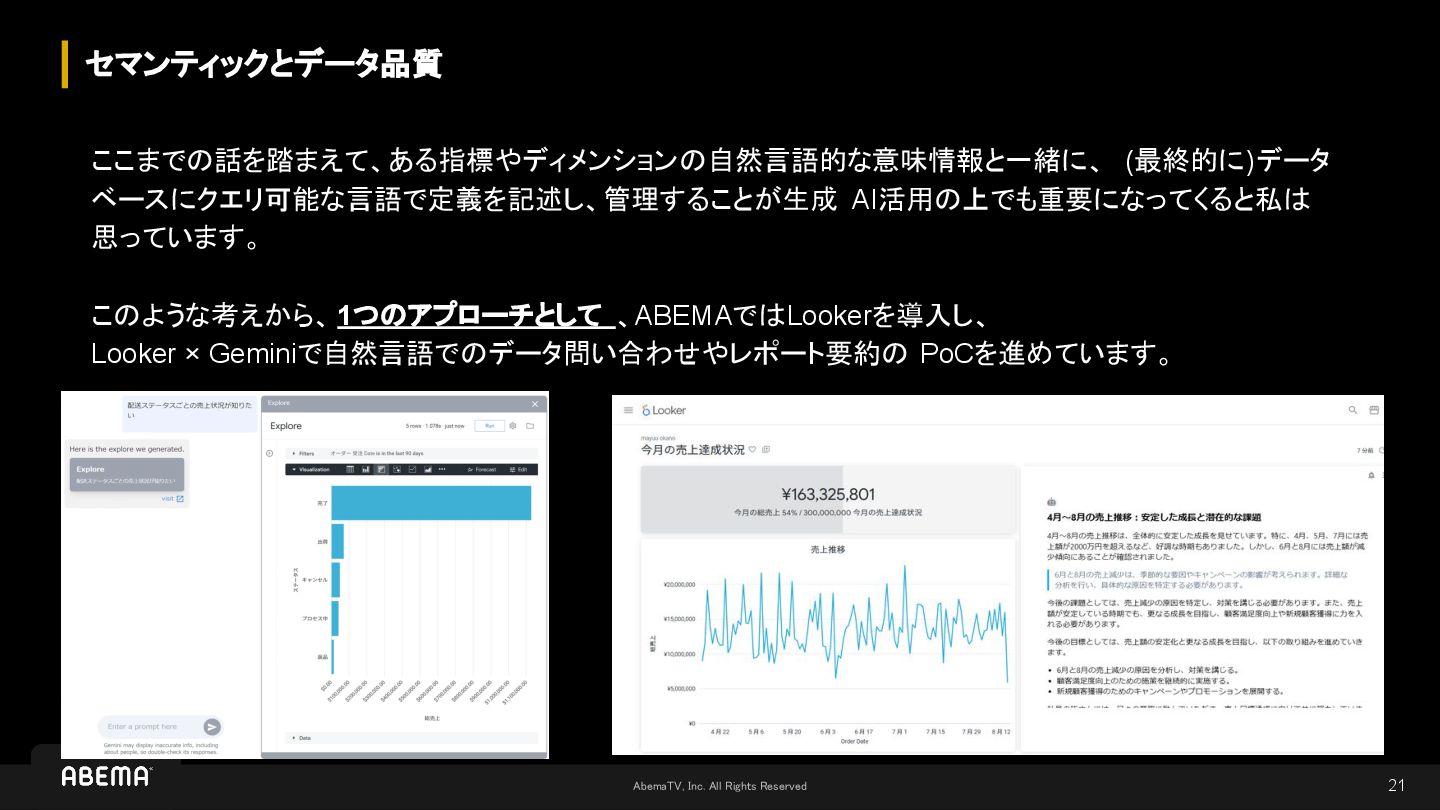
AbemaTV, Inc. All Rights Reserved セマンティックとデータ品質 21 ここまでの話を踏まえて、ある指標やディメンションの自然言語的な意味情報と一緒に、 (最終的に)データ ベースにクエリ可能な言語で定義を記述し、管理することが生成
AI活用の上でも重要になってくると私は 思っています。 このような考えから、 1つのアプローチとして 、ABEMAではLookerを導入し、 Looker × Geminiで自然言語でのデータ問い合わせやレポート要約の PoCを進めています。
AbemaTV, Inc. All Rights Reserved ログ/マスタ設計とデータ仕様ドキュメント 22 先述のように生成AIによるデータ集計や分析の支援、効率化を進める上で、ソースデータの品質は その成果を大きく左右すると考えています。 この「無から有を生み出す」最初のプロセスにおいて、
高い品質を維持しやすいデータモデル・型を設計することや仕様ドキュメントをしっかり書き残しておくこ とが今まで以上に重要になってきていると感じます。 結局、大事なことは4年前とあまり変わっていないような気がしますね。
AbemaTV, Inc. All Rights Reserved 結論 23 • 「猫も杓子も生成 AI」な時代でも結局、データ整備とドキュメント整備が大事
• データエンジニアは泥臭くがんばっていきましょう
AbemaTV, Inc. All Rights Reserved 『ABEMA』では 一緒に挑戦する仲間を募集中です! ✔オンラインでカジュアル面談実施中 ✔今すぐ転職を考えていなくてもOK!(興味ある方ぜひ声かけてください) 応募はこちら👉
カジュアル面談は こちらから👉
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}