神奈川大学「実践的データサイエンス演習」(2025年度)の第08回講義資料です。CRISP-DM、EDA と実験の位置づけ、Jupyter Notebook の長所と限界、実験コードを再現性・追跡性・再利用性の観点からどう改善していくかを扱います。
演習やサンプルコードは以下のページからダウンロード可能です。
https://github.com/HidetoshiKawaguchi/practical-data-scientist-lecture/tree/main/2025/08-experiment-management
2025年度講義資料一覧
・06 ITベンダーにおけるデータサイエンティスト
https://speakerdeck.com/hidetoshikawaguchi/shi-jian-de-detasaiensuyan-xi-itbendaniokerudetasaienteisuto-at-shen-nai-chuan-da-xue-2025nian-du
・07 ドキュメント・コミュニケーション
https://speakerdeck.com/hidetoshikawaguchi/shi-jian-de-detasaiensuyan-xi-dokiyumentokomiyunikesiyon-at-shen-nai-chuan-da-xue-2025nian-du
・08 分析・実験・検証の実践的管理方法
https://speakerdeck.com/hidetoshikawaguchi/shi-jian-de-detasaiensuyan-xi-fen-xi-shi-yan-jian-zheng-noshi-jian-de-guan-li-fang-fa-at-shen-nai-chuan-da-xue-2025nian-du
・09 データサイエンティストの開発技術
https://speakerdeck.com/hidetoshikawaguchi/shi-jian-de-detasaiensuyan-xi-detasaienteisutonokai-fa-ji-shu-at-shen-nai-chuan-da-xue-2025nian-du
※ 01-05や10以降は、別の講師の方が担当しております。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
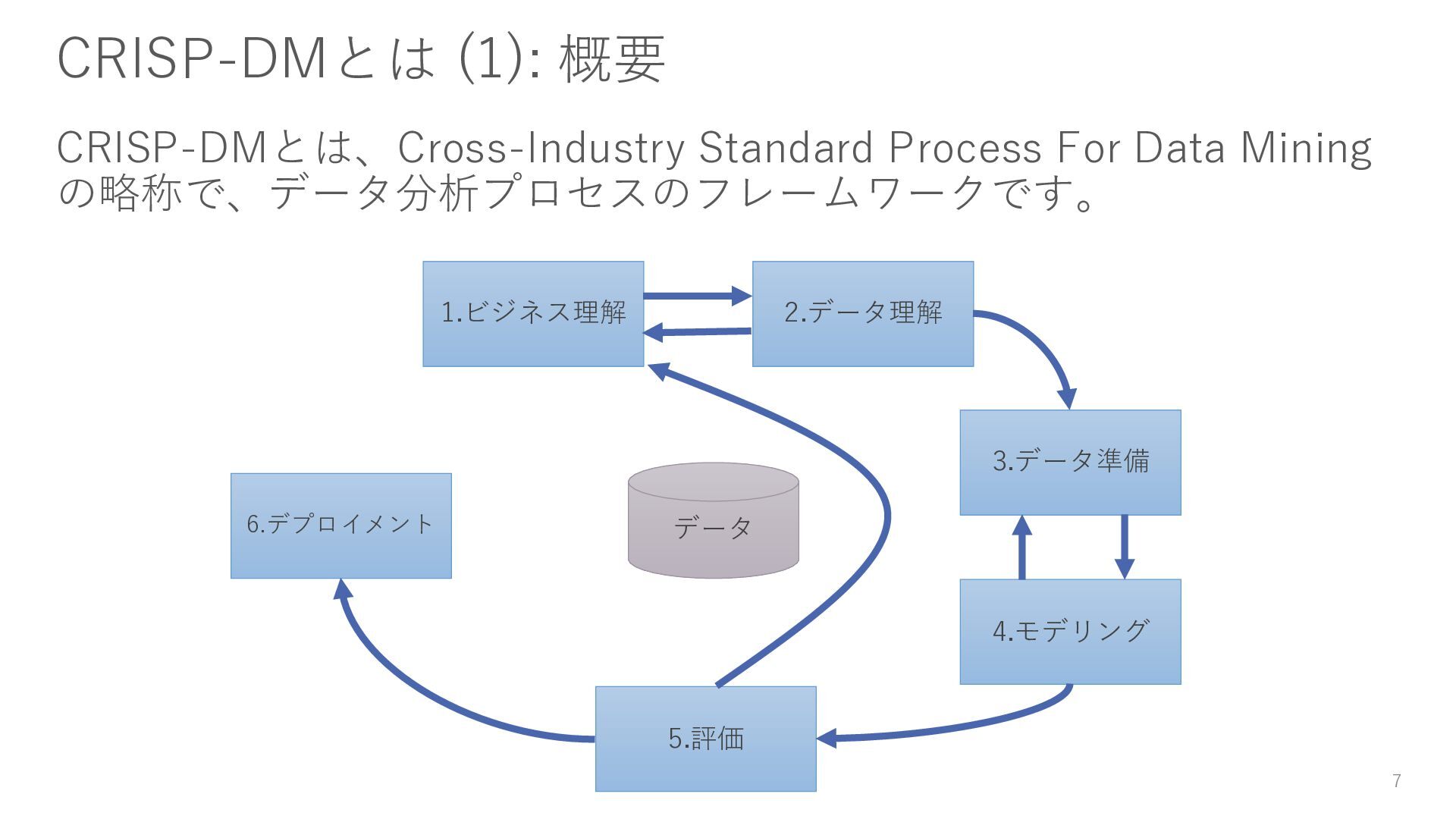{kind=link}
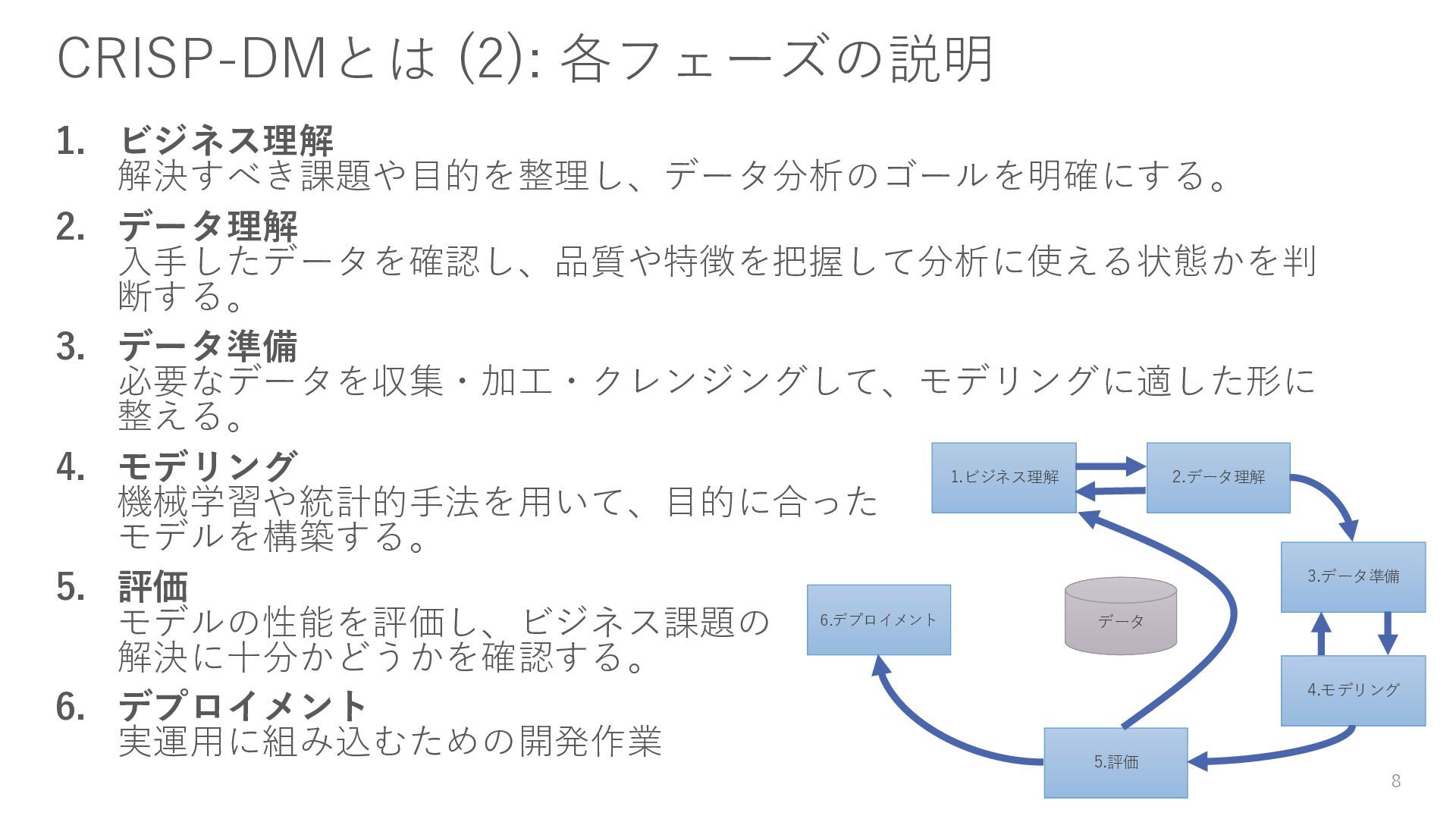{kind=link}
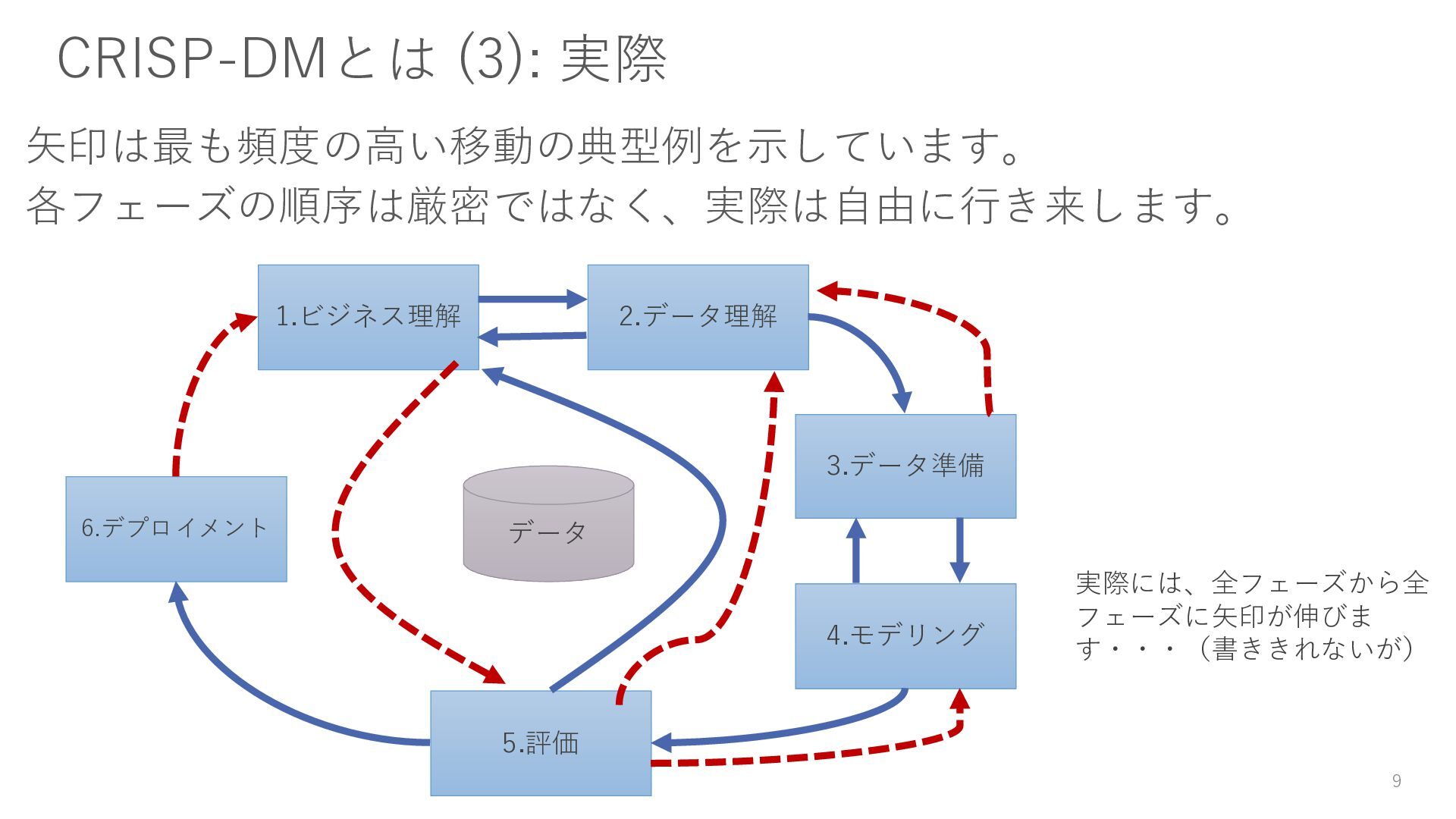{kind=link}
{kind=link}
![[参考] データエンジニアの役割 最近はデータエンジニアという役割も登場します。データエンジニア は、3.データ準備までを円滑に行えるようにデータ基盤を整えること が仕事です。 実は、実務においてそもそもデータが取り出しやすい形になっている ことはかなり少ないです。 • いろいろなシステム(データベース)が社内に乱立 •](https://files.speakerdeck.com/presentations/6d26ff336d02477082088f5a3d5ece8b/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
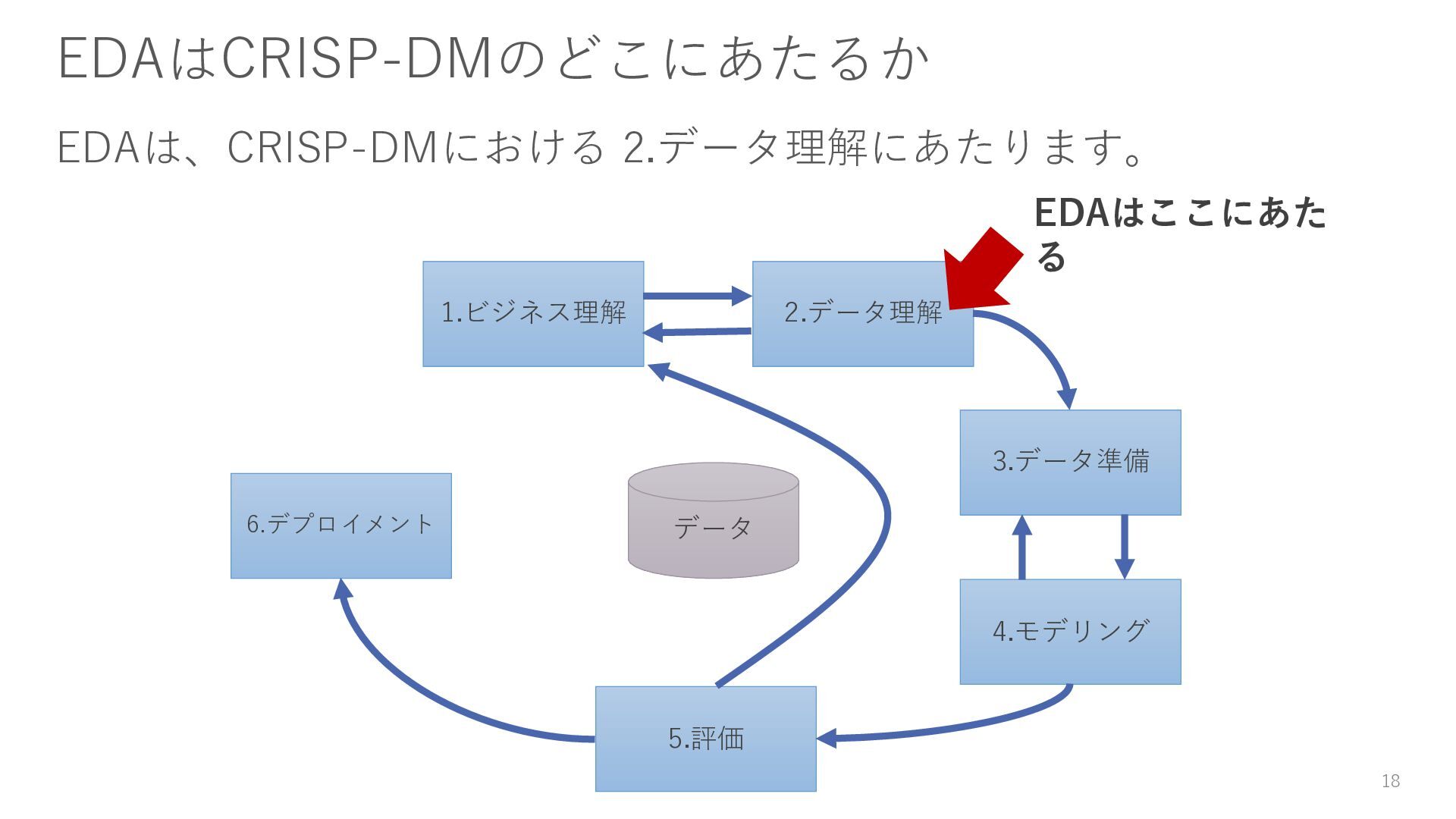{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}